
Esta página enumera un conjunto de guías y herramientas conocidas que resuelven problemas en el dominio del texto con TensorFlow Hub. Es un punto de partida para cualquiera que quiera resolver problemas típicos de ML utilizando componentes de ML previamente entrenados en lugar de empezar desde cero.
Clasificación
Cuando queremos predecir una clase para un ejemplo determinado, por ejemplo sentimiento , toxicidad , categoría de artículo o cualquier otra característica.

Los tutoriales a continuación resuelven la misma tarea desde diferentes perspectivas y utilizando diferentes herramientas.
Keras
Clasificación de texto con Keras : ejemplo para crear un clasificador de sentimientos de IMDB con Keras y TensorFlow Datasets.
Estimador
Clasificación de texto : ejemplo para crear un clasificador de opiniones de IMDB con Estimator. Contiene múltiples consejos de mejora y una sección de comparación de módulos.
BERT
Predicción del sentimiento de reseña de películas con BERT en TF Hub : muestra cómo utilizar un módulo BERT para la clasificación. Incluye el uso de la biblioteca bert para tokenización y preprocesamiento.
Kaggle
Clasificación IMDB en Kaggle : muestra cómo interactuar fácilmente con una competencia de Kaggle desde un Colab, incluida la descarga de datos y el envío de los resultados.
| Estimador | Keras | TF2 | Conjuntos de datos TF | BERT | API de Kaggle | |
|---|---|---|---|---|---|---|
| Clasificación de texto | ||||||
| Clasificación de textos con Keras | ||||||
| Predecir el sentimiento de crítica de películas con BERT en TF Hub | ||||||
| Clasificación IMDB en Kaggle |
Tarea bengalí con incrustaciones FastText
TensorFlow Hub no ofrece actualmente un módulo en todos los idiomas. El siguiente tutorial muestra cómo aprovechar TensorFlow Hub para una experimentación rápida y un desarrollo de aprendizaje automático modular.
Clasificador de artículos en bengalí : demuestra cómo crear una incrustación de texto reutilizable de TensorFlow Hub y utilizarla para entrenar un clasificador de Keras para el conjunto de datos de artículos en bengalí BARD .
Similitud semántica
Cuando queremos saber qué oraciones se correlacionan entre sí en una configuración de disparo cero (sin ejemplos de entrenamiento).
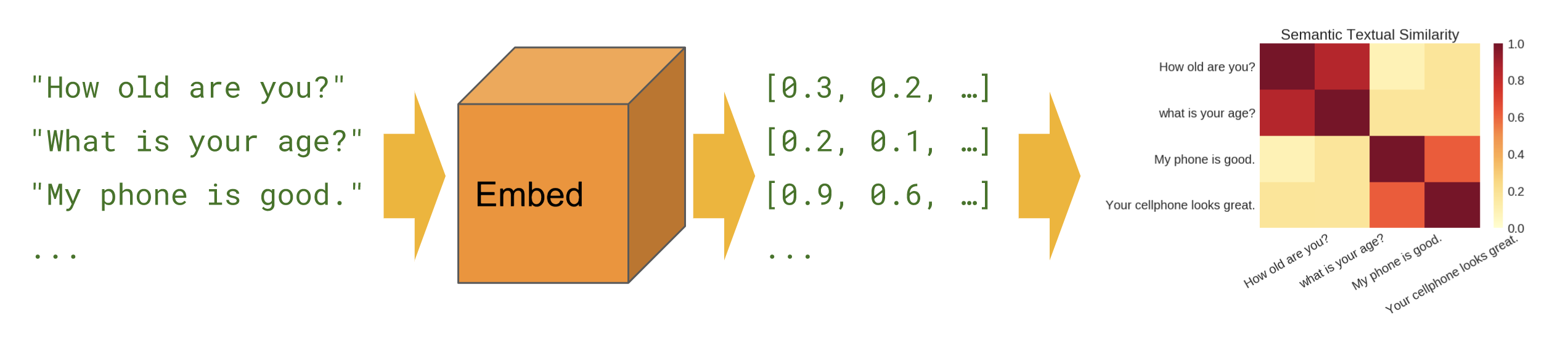
Básico
Similitud semántica : muestra cómo utilizar el módulo codificador de oraciones para calcular la similitud de oraciones.
multilingüe
Similitud semántica entre idiomas : muestra cómo utilizar uno de los codificadores de oraciones entre idiomas para calcular la similitud de oraciones entre idiomas.
Recuperación semántica
Recuperación semántica : muestra cómo utilizar el codificador de oraciones de preguntas y respuestas para indexar una colección de documentos para su recuperación en función de la similitud semántica.
Entrada de frase
Similitud semántica con el codificador universal lite : muestra cómo usar módulos de codificador de oraciones que aceptan identificadores de SentencePiece en la entrada en lugar de texto.
Creación de módulos
En lugar de utilizar únicamente módulos en tfhub.dev , existen formas de crear módulos propios. Esta puede ser una herramienta útil para mejorar la modularidad de la base de código de ML y para compartirlo más.
Envolver incrustaciones previamente entrenadas existentes
Exportador de módulos de incrustación de texto : una herramienta para empaquetar una incrustación previamente entrenada existente en un módulo. Muestra cómo incluir operaciones de preprocesamiento de texto en el módulo. Esto permite crear un módulo de incrustación de oraciones a partir de incrustaciones de tokens.
Exportador de módulo de incrustación de texto v2 : igual que el anterior, pero compatible con TensorFlow 2 y ejecución entusiasta.