
Stosowanie wyspecjalizowanych procesorów, takich jak GPU, NPU lub DSP do obsługi sprzętu przyspieszenie może znacznie poprawić wydajność wnioskowania (nawet 10 razy szybciej) wnioskowania w niektórych przypadkach) i wrażeń użytkowników Androida z obsługą systemów uczących się. aplikacji. Jednak ze względu na różnorodność sprzętu i sterowników użytkownicy mogą wybrać optymalną konfigurację akceleracji sprzętowej dla każdego użytkownika, może być trudnym zadaniem. Ponadto włączenie niewłaściwej konfiguracji urządzenie może pogorszyć wrażenia użytkownika z powodu dużego opóźnienia. W rzadkich przypadkach w przypadku błędów w czasie działania, a także problemów z dokładnością spowodowanych brakiem zgodności sprzętu.
Acceleration Service na Androida to interfejs API, który pomaga wybrać
optymalnej konfiguracji akceleracji sprzętowej dla danego urządzenia użytkownika
.tflite, minimalizując jednocześnie ryzyko błędów w czasie działania i problemów z dokładnością.
Usługa Acceleration Program ocenia różne konfiguracje przyspieszenia u użytkownika urządzeń, korzystając z wewnętrznych testów porównawczych wnioskowania za pomocą LiteRT. model atrybucji. Trwa to zazwyczaj kilka sekund, w zależności od model atrybucji. Przed wywnioskowaniem testów porównawczych możesz przeprowadzić testy porównawcze raz na każdym urządzeniu użytkownika. zapisz wynik w pamięci podręcznej i użyj go podczas wnioskowania. Te testy porównawcze są poza procesem; co minimalizuje ryzyko awarii w aplikacji.
Udostępnij model, próbki danych i oczekiwane wyniki (dane wejściowe „złote” danych wyjściowych), a usługa Acceleration Program uruchomi wewnętrzne wnioskowanie TFLite testów porównawczych, aby przedstawić zalecenia dotyczące sprzętu.
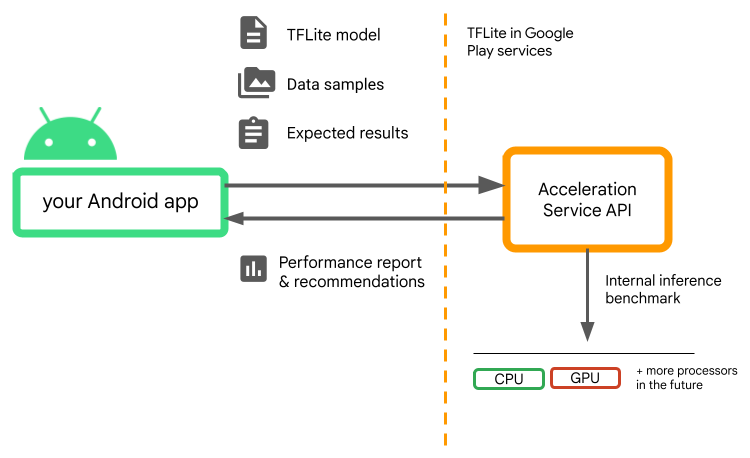
Usługa Acceleration jest częścią niestandardowego stosu ML Androida i współpracuje z LiteRT w Usługach Google Play.
Dodaj zależności do projektu
Dodaj te zależności do pliku build.gradle aplikacji:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.0.0-beta01"
Interfejs Acceleration Service API współpracuje z LiteRT w Google Play Usługi. Jeśli nie używasz jeszcze środowiska wykonawczego LiteRT udostępnianego w Usługach Google Play, Trzeba zaktualizować swoje dependencies.
Jak korzystać z interfejsu Acceleration Service API
Aby korzystać z usługi Acceleration, najpierw utwórz konfigurację przyspieszenia
który chcesz ocenić dla swojego modelu (np.GPU z trybem OpenGL). Następnie utwórz
konfiguracji weryfikacji za pomocą modelu, przykładowych danych i oczekiwanych
danych wyjściowych modelu. Na koniec wywołaj validateConfig(), przekazując zarówno swoje
konfiguracji przyspieszania
i walidacji.

Utwórz konfiguracje przyspieszenia
Konfiguracje przyspieszenia reprezentują konfiguracje sprzętowe które są przekształcane w delegatów w czasie wykonywania. Usługa Acceleration będzie następnie używała tych konfiguracji wewnętrznie aby wnioskować o testy.
Obecnie usługa przyspieszenia umożliwia ocenę GPU konfiguracje (przekonwertowane na przekazywanie dostępu do GPU w czasie wykonywania) z GpuAccelerationConfig i wnioskowanie dotyczące procesora (z CpuAccelerationConfig). Pracujemy nad tym, aby więcej przedstawicieli mogli korzystać z innego sprzętu w przyszłości.
Konfiguracja przyspieszenia GPU
Utwórz konfigurację przyspieszenia GPU w następujący sposób:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
Musisz określić, czy Twój model korzysta z kwantyzacji z
setEnableQuantizedInference()
Konfiguracja przyspieszenia procesora
Utwórz przyspieszenie procesora w następujący sposób:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Użyj
setNumThreads()
do definiowania liczby wątków, które mają być używane do oceny procesora
wnioskowania.
Utwórz konfiguracje weryfikacji
Konfiguracje weryfikacji pozwalają określić sposób przyspieszania działania Usługa do oceny wniosków. Możesz ich używać, by zaliczyć:
- próbek danych wejściowych,
- oczekiwane wyniki,
- logikę walidacji dokładności.
Pamiętaj o dostarczeniu próbek danych wejściowych, w przypadku których spodziewasz się wysokiej skuteczności swojego modelu (są to tzw. „złote” próbki).
Utwórz
ValidationConfig
z
CustomValidationConfig.Builder
w następujący sposób:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Określ liczbę złotych próbek za pomocą
setBatchSize()
Przekaż dane ze złotych próbek za pomocą
setGoldenInputs()
Podaj oczekiwane dane wyjściowe przekazywane z danymi wejściowymi
setGoldenOutputs()
Maksymalny czas wnioskowania możesz określić za pomocą funkcji setInferenceTimeoutMillis()
(domyślnie 5000 ms). Jeśli wnioskowanie trwa dłużej niż zdefiniowany czas,
konfiguracja zostanie odrzucona.
Opcjonalnie możesz też utworzyć niestandardowy AccuracyValidator.
w następujący sposób:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Zdefiniuj logikę weryfikacji, która sprawdzi się w Twoim przypadku użycia.
Pamiętaj, że jeśli dane weryfikacyjne są już osadzone w modelu, możesz użyć
EmbeddedValidationConfig
Wygeneruj wyniki weryfikacji
Złote dane wyjściowe są opcjonalne. Jeśli podasz złote dane wejściowe,
Usługa Acceleration może wewnętrznie generować złote dane wyjściowe. Możesz też
określić konfigurację przyspieszenia używaną do wygenerowania tych złotych wyników
dzwoni do: setGoldenConfig():
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Zweryfikuj konfigurację przyspieszenia
Po utworzeniu konfiguracji przyspieszenia i konfiguracji walidacji może je ocenić dla Twojego modelu.
Sprawdź, czy środowisko wykonawcze LiteRT z Usługami Google Play jest prawidłowo i że delegowany GPU jest dostępny dla urządzenia przez uruchomienie polecenia:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Utwórz instancję AccelerationService
, dzwoniąc pod numer AccelerationService.create().
Następnie możesz zweryfikować konfigurację przyspieszenia swojego modelu, wywołując
validateConfig():
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
Możesz również zweryfikować wiele konfiguracji, wywołując
validateConfigs()
i przekazywanie obiektu Iterable<AccelerationConfig> jako parametru.
validateConfig()zwraca
Task<ValidatedAccelerationConfigResult>
z Usług Google Play
Task API, który umożliwia
asynchronicznych zadań.
Aby uzyskać wynik wywołania weryfikacyjnego, dodaj
addOnSuccessListener().
oddzwanianie.
Użyj zweryfikowanej konfiguracji w tłumaczeniu
Po sprawdzeniu, czy usługa ValidatedAccelerationConfigResult zwróciła
wywołanie zwrotne jest prawidłowe, możesz ustawić zweryfikowaną konfigurację jako konfigurację przyspieszenia
za tłumacza dzwoniącego pod numer interpreterOptions.setAccelerationConfig().
Buforowanie konfiguracji
Optymalna konfiguracja przyspieszenia dla Twojego modelu prawdopodobnie nie zmieni się
urządzenia. Po uzyskaniu satysfakcjonującej konfiguracji przyspieszenia możesz
powinien zapisać go na urządzeniu i pozwolić aplikacji na jego pobranie oraz użycie
utwórz InterpreterOptions podczas następujących sesji, a nie
przeprowadzanie kolejnej weryfikacji. Metody serialize() i deserialize() w
ValidatedAccelerationConfigResult wykonują proces przechowywania i pobierania
.
Przykładowa aplikacja
Aby sprawdzić integrację in-situ z usługą Acceleration, obejrzyj przykładowej aplikacji.
Ograniczenia
Usługa Acceleration ma obecnie takie ograniczenia:
- Obecnie obsługiwane są tylko konfiguracje przyspieszenia CPU i GPU.
- Obsługuje LiteRT tylko w Usługach Google Play i nie można użyj go, jeśli korzystasz z pakietu w wersji LiteRT.
- Pakiet Acceleration Service SDK obsługuje tylko interfejs API na poziomie 22 lub wyższym.
Zastrzeżenia
Zapoznaj się uważnie z tymi zastrzeżeniami, zwłaszcza jeśli planujesz , aby używać tego pakietu SDK w środowisku produkcyjnym:
Przed zamknięciem Beta i opublikowaniem stabilnej wersji interfejsu Acceleration Service API, opublikujemy nowy pakiet SDK, który może różnice w stosunku do obecnej wersji beta. Aby nadal korzystać z w usłudze Acceleration, musisz przejść na ten nowy pakiet SDK i przesłać aktualizować ją w odpowiednim czasie. Jeśli tego nie zrobisz, mogą wystąpić awarie, pakiet SDK w wersji beta może nie być zgodny z Usługami Google Play po za jakiś czas.
Nie ma gwarancji, że konkretna funkcja programu Acceleration Interfejs API usługi lub cały interfejs API staną się ogólnie dostępne. it mogą pozostawać w wersji beta na czas nieokreślony, zostać wyłączone lub być połączone z innymi w pakiety przeznaczone dla konkretnych odbiorców. Niektóre z interfejsem Acceleration Service API lub za pomocą całego interfejsu API, staną się ogólnie dostępne, ale nie ma ustalonego harmonogramu to osiągnąć.
Warunki i prywatność
Warunki korzystania z usługi
Korzystanie z interfejsów API usługi Acceleration podlega Warunkom korzystania z interfejsów API Google
Usługa.
Dodatkowo interfejsy Acceleration Service API są obecnie w wersji beta
Korzystając z niego, przyjmujesz do wiadomości potencjalne problemy opisane
zastrzeżeń powyżej i przyjmuje do wiadomości, że usługa Acceleration może nie
zawsze wykonywać zgodnie z harmonogramem.
Prywatność
Gdy korzystasz z interfejsów Acceleration Service API, przetwarzanie danych wejściowych (np.
(obrazy, filmy czy tekst), odbywa się w całości na urządzeniu, a usługa Acceleration
nie wysyła tych danych na serwery Google. Dzięki temu można używać
naszych interfejsów API
do przetwarzania danych wejściowych, które nie powinny opuszczać urządzenia.
Interfejsy API usługi Acceleration mogą od czasu do czasu kontaktować się z serwerami Google w
aby otrzymywać poprawki błędów, zaktualizowane modele i akcelerator sprzętowy
informacje o zgodności. Interfejsy Acceleration Service API wysyłają też dane o
wydajności i wykorzystania interfejsów API w aplikacji. Google używa
te dane do pomiaru wydajności, debugowania, utrzymywania i ulepszania interfejsów API,
oraz wykrywania nadużyć lub nadużyć, jak opisano szczegółowo w
Polityce prywatności Google
Zasady.
Ponosisz odpowiedzialność za informowanie użytkowników o swojej aplikacji o przetwarzaniu danych przez Google
danych z usługi Acceleration Program zgodnie z obowiązującymi przepisami.
Gromadzone przez nas dane obejmują:
- informacje o urządzeniu (takie jak producent, model, wersja systemu operacyjnego i kompilacja). dostępnych akceleratorów sprzętowych ML (GPU i DSP). Służy do diagnostyki i do analizy wykorzystania.
- Informacje o aplikacji (nazwa pakietu / identyfikator pakietu, wersja aplikacji). Używane do diagnostyką i analityką użytkowania.
- Konfiguracja interfejsu API (np. format i rozdzielczość obrazu). Używane do diagnostyką i analityką użytkowania.
- Typ zdarzenia (np. zainicjowanie, pobranie modelu, aktualizacja, uruchomienie, wykrycie). Służy do diagnostyki i analizy użytkowania.
- Kody błędów. Służy do diagnostyki.
- Dane o skuteczności – Służy do diagnostyki.
- identyfikatory dla poszczególnych instalacji, które nie umożliwiają jednoznacznej identyfikacji użytkownika lub na urządzeniu fizycznym. Służy do obsługi zdalnej konfiguracji i użytkowania Analytics.
- Adresy IP nadawców żądań sieciowych. Używany do konfiguracji zdalnej i diagnostykę. Zebrane adresy IP są przechowywane tymczasowo.
Pomoc techniczna i komentarze
Za pomocą narzędzia TensorFlow Issue Tracker możesz przesłać opinię i uzyskać pomoc. Problemy i prośby o pomoc należy zgłaszać za pomocą szablon problemu za LiteRT w Usługach Google Play.