
A veces pueden ocurrir eventos catastróficos que involucran NaN durante un programa de TensorFlow, lo que paraliza los procesos de entrenamiento del modelo. La causa fundamental de tales eventos suele ser oscura, especialmente en el caso de modelos de tamaño y complejidad no triviales. Para facilitar la depuración de este tipo de errores de modelo, TensorBoard 2.3+ (junto con TensorFlow 2.3+) proporciona un panel especializado llamado Debugger V2. Aquí demostramos cómo utilizar esta herramienta solucionando un error real que involucra NaN en una red neuronal escrita en TensorFlow.
Las técnicas ilustradas en este tutorial son aplicables a otros tipos de actividades de depuración, como la inspección de formas tensoriales en tiempo de ejecución en programas complejos. Este tutorial se centra en los NaN debido a su frecuencia de aparición relativamente alta.
Observando el error
El código fuente del programa TF2 que depuraremos está disponible en GitHub . El programa de ejemplo también está empaquetado en el paquete pip de tensorflow (versión 2.3+) y puede ser invocado mediante:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Este programa TF2 crea una percepción multicapa (MLP) y la entrena para reconocer imágenes MNIST . Este ejemplo utiliza intencionalmente la API de bajo nivel de TF2 para definir construcciones de capas personalizadas, funciones de pérdida y bucles de entrenamiento, porque la probabilidad de errores de NaN es mayor cuando usamos esta API más flexible pero más propensa a errores que cuando usamos la más sencilla. API de alto nivel fáciles de usar pero ligeramente menos flexibles, como tf.keras .
El programa imprime una prueba de precisión después de cada paso del entrenamiento. Podemos ver en la consola que la precisión de la prueba se estanca en un nivel cercano al azar (~0,1) después del primer paso. Ciertamente no es así como se espera que se comporte el entrenamiento del modelo: esperamos que la precisión se acerque gradualmente a 1,0 (100%) a medida que aumenta el paso.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Una suposición fundamentada es que este problema se debe a una inestabilidad numérica, como NaN o infinito. Sin embargo, ¿cómo confirmamos que este es realmente el caso y cómo encontramos la operación (op) de TensorFlow responsable de generar la inestabilidad numérica? Para responder a estas preguntas, instrumentemos el programa con errores con Debugger V2.
Instrumentación del código TensorFlow con Debugger V2
tf.debugging.experimental.enable_dump_debug_info() es el punto de entrada API de Debugger V2. Instrumenta un programa TF2 con una sola línea de código. Por ejemplo, agregar la siguiente línea cerca del comienzo del programa hará que la información de depuración se escriba en el directorio de registro (logdir) en /tmp/tfdbg2_logdir. La información de depuración cubre varios aspectos del tiempo de ejecución de TensorFlow. En TF2, incluye el historial completo de ejecución ansiosa, la construcción de gráficos realizada por @tf.function , la ejecución de los gráficos, los valores tensoriales generados por los eventos de ejecución, así como la ubicación del código (rastros de la pila de Python) de esos eventos. . La riqueza de la información de depuración permite a los usuarios centrarse en errores poco conocidos.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
El argumento tensor_debug_mode controla qué información extrae Debugger V2 de cada tensor ansioso o en el gráfico. “FULL_HEALTH” es un modo que captura la siguiente información sobre cada tensor de tipo flotante (por ejemplo, el comúnmente visto float32 y el menos común bfloat16 dtype):
- Tipo D
- Rango
- Número total de elementos
- Un desglose de los elementos de tipo flotante en las siguientes categorías: finito negativo (
-), cero (0), finito positivo (+), infinito negativo (-∞), infinito positivo (+∞) yNaN.
El modo "FULL_HEALTH" es adecuado para depurar errores que involucran NaN e infinito. Consulte a continuación otros tensor_debug_mode compatibles.
El argumento circular_buffer_size controla cuántos eventos tensoriales se guardan en el logdir. El valor predeterminado es 1000, lo que hace que solo se guarden en el disco los últimos 1000 tensores antes del final del programa TF2 instrumentado. Este comportamiento predeterminado reduce la sobrecarga del depurador al sacrificar la integridad de los datos de depuración. Si se prefiere la integridad, como en este caso, podemos desactivar el búfer circular estableciendo el argumento en un valor negativo (por ejemplo, -1 aquí).
El ejemplo debug_mnist_v2 invoca enable_dump_debug_info() pasándole indicadores de línea de comandos. Para ejecutar nuestro problemático programa TF2 nuevamente con esta instrumentación de depuración habilitada, haga:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Inicio de la GUI del Debugger V2 en TensorBoard
Al ejecutar el programa con la instrumentación del depurador se crea un logdir en /tmp/tfdbg2_logdir. Podemos iniciar TensorBoard y apuntarlo al logdir con:
tensorboard --logdir /tmp/tfdbg2_logdir
En el navegador web, navegue hasta la página de TensorBoard en http://localhost:6006. El complemento "Debugger V2" estará inactivo de forma predeterminada, así que selecciónelo en el menú "Complementos inactivos" en la parte superior derecha. Una vez seleccionado, debería verse como el siguiente:
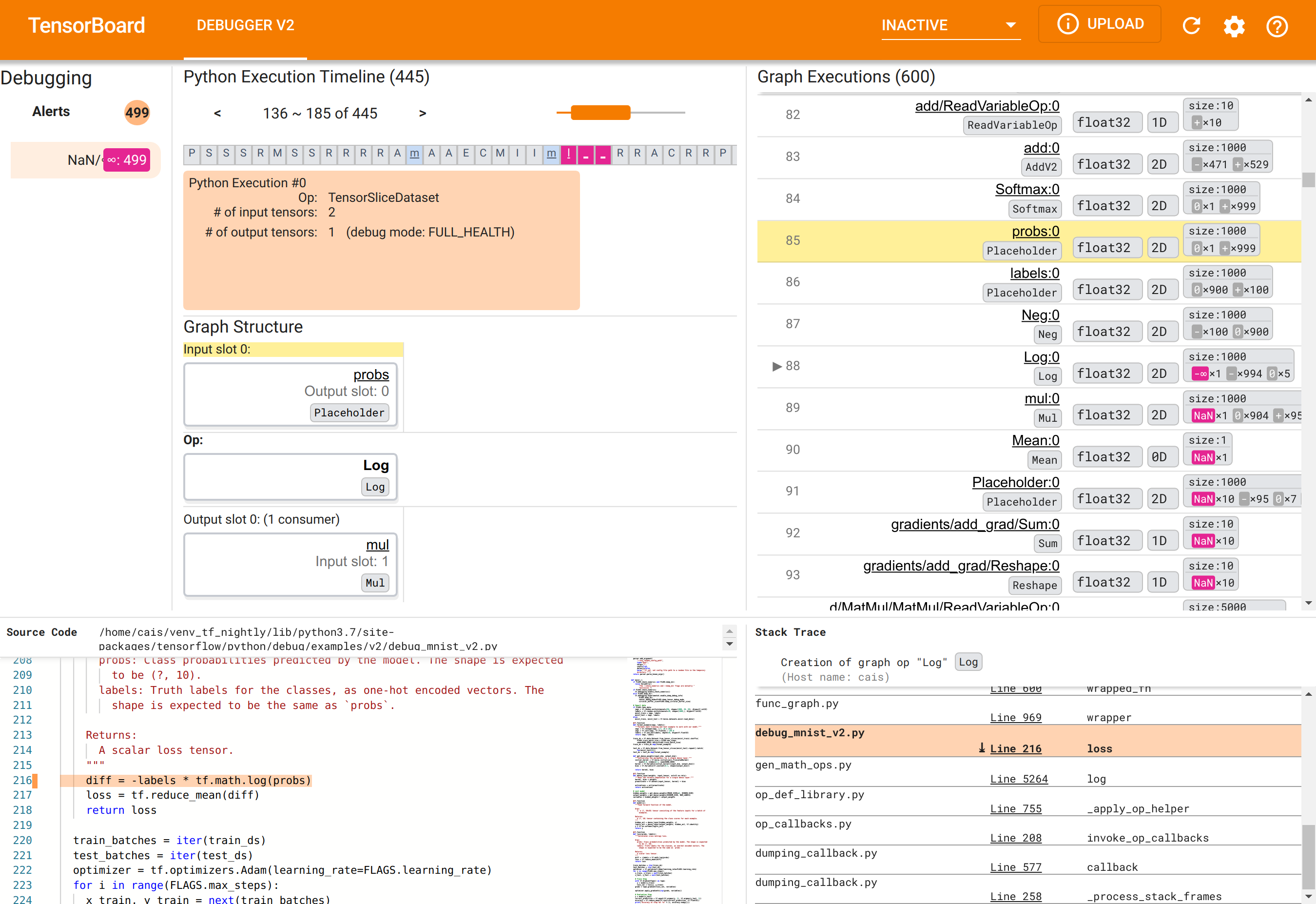
Uso de la GUI de Debugger V2 para encontrar la causa raíz de los NaN
La GUI de Debugger V2 en TensorBoard está organizada en seis secciones:
- Alertas : esta sección superior izquierda contiene una lista de eventos de "alerta" detectados por el depurador en los datos de depuración del programa TensorFlow instrumentado. Cada alerta indica una determinada anomalía que merece atención. En nuestro caso, esta sección destaca 499 eventos NaN/∞ con un color rojo rosado saliente. Esto confirma nuestra sospecha de que el modelo no aprende debido a la presencia de NaN y/o infinitos en sus valores tensoriales internos. Profundizaremos en estas alertas en breve.
- Línea de tiempo de ejecución de Python : esta es la mitad superior de la sección media superior. Presenta la historia completa de la ansiosa ejecución de operaciones y gráficos. Cada cuadro de la línea de tiempo está marcado por la letra inicial del nombre de la operación o del gráfico (por ejemplo, "T" para la operación "TensorSliceDataset", "m" para la
tf.function"modelo"). Podemos navegar en esta línea de tiempo usando los botones de navegación y la barra de desplazamiento sobre la línea de tiempo. - Ejecución de gráficos : ubicada en la esquina superior derecha de la GUI, esta sección será fundamental para nuestra tarea de depuración. Contiene un historial de todos los tensores de tipo flotante calculados dentro de gráficos (es decir, compilados por
@tf-functions). - La estructura del gráfico (mitad inferior de la sección central superior), el código fuente (sección inferior izquierda) y el seguimiento de la pila (sección inferior derecha) están inicialmente vacíos. Su contenido se completará cuando interactuemos con la GUI. Estas tres secciones también desempeñarán un papel importante en nuestra tarea de depuración.
Una vez que nos hemos centrado en la organización de la interfaz de usuario, sigamos los siguientes pasos para llegar al fondo de por qué aparecieron los NaN. Primero, haga clic en la alerta NaN/∞ en la sección Alertas. Esto desplaza automáticamente la lista de 600 tensores de gráficos en la sección Ejecución de gráficos y se centra en el #88, que es un tensor llamado Log:0 generado por una Log (logaritmo natural). Un color rojo rosado saliente resalta un elemento -∞ entre los 1000 elementos del tensor 2D float32. Este es el primer tensor en el historial de ejecución del programa TF2 que contenía NaN o infinito: los tensores calculados antes no contienen NaN o ∞; Muchos (de hecho, la mayoría) de los tensores calculados posteriormente contienen NaN. Podemos confirmar esto desplazándonos hacia arriba y hacia abajo en la lista de Ejecución de gráficos. Esta observación proporciona un fuerte indicio de que la operación Log es la fuente de la inestabilidad numérica en este programa TF2.
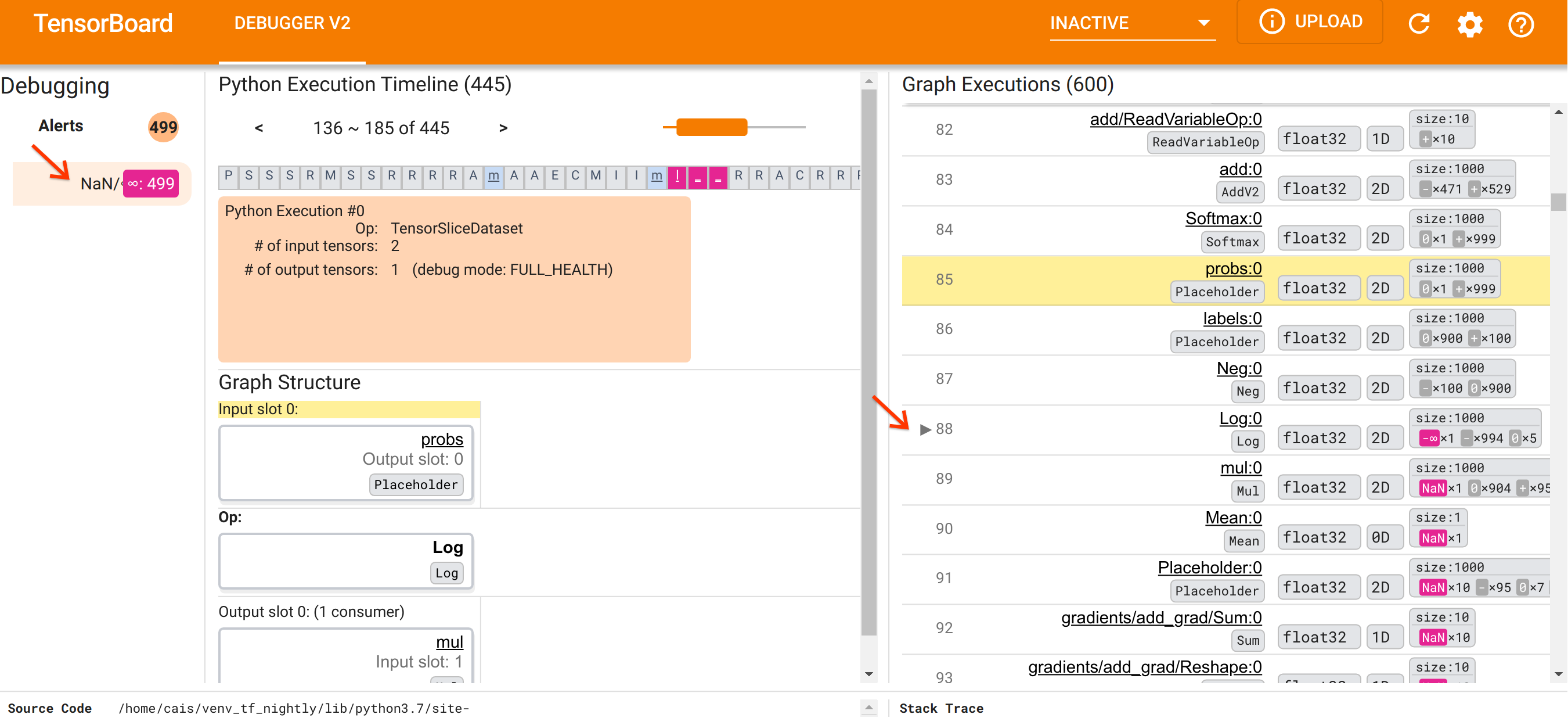
¿Por qué esta operación Log arroja un -∞? Responder a esa pregunta requiere examinar los aportes a la operación. Al hacer clic en el nombre del tensor ( Log:0 ), aparece una visualización simple pero informativa de la vecindad de la operación Log en su gráfico TensorFlow en la sección Estructura del gráfico. Tenga en cuenta la dirección de arriba a abajo del flujo de información. La operación en sí se muestra en negrita en el medio. Inmediatamente encima, podemos ver una operación de marcador de posición que proporciona la única entrada a la operación Log . ¿Dónde está el tensor generado por este marcador de posición probs en la lista de ejecución de gráficos? Al utilizar el color de fondo amarillo como ayuda visual, podemos ver que el tensor probs:0 está tres filas por encima del tensor Log:0 , es decir, en la fila 85.
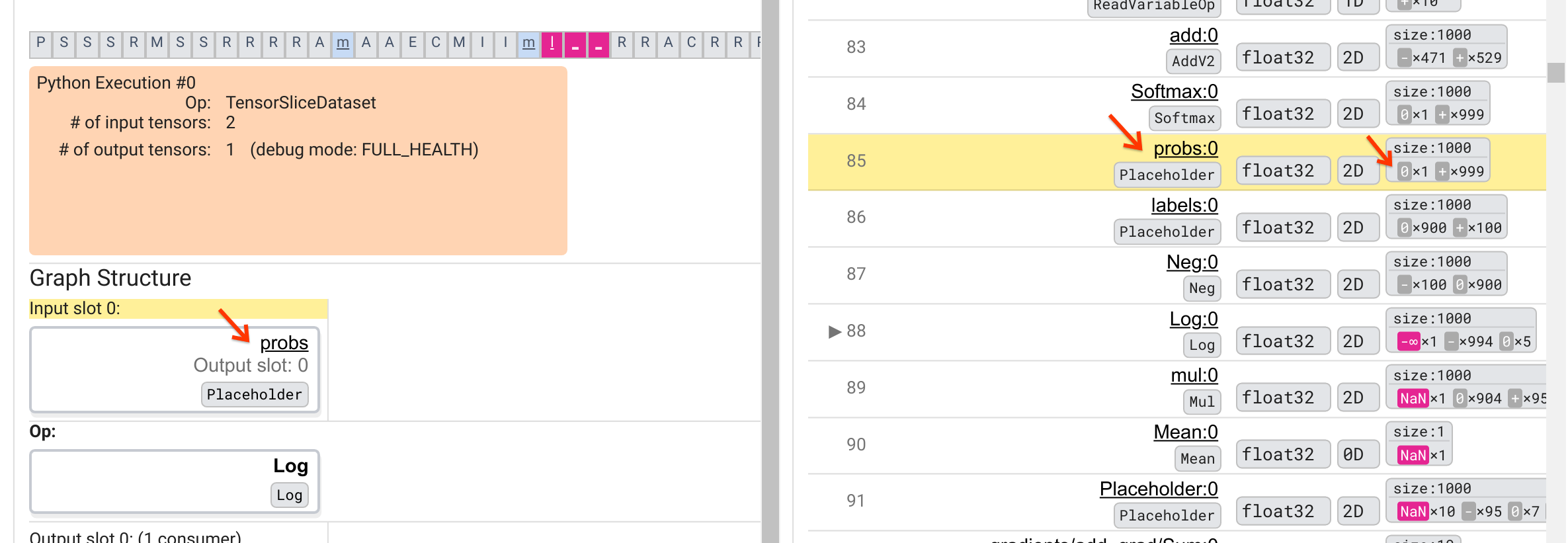
Una mirada más cuidadosa al desglose numérico del tensor probs:0 en la fila 85 revela por qué su consumidor Log:0 produce un -∞: Entre los 1000 elementos de probs:0 , un elemento tiene un valor de 0. El -∞ es resultado de calcular el logaritmo natural de 0! Si de alguna manera podemos asegurarnos de que la operación Log quede expuesta solo a entradas positivas, podremos evitar que ocurra NaN/∞. Esto se puede lograr aplicando recorte (por ejemplo, usando tf.clip_by_value() ) en el tensor probs del marcador de posición.
Estamos cada vez más cerca de resolver el error, pero aún no hemos terminado. Para aplicar la solución, necesitamos saber en qué parte del código fuente de Python se originó la operación Log y su entrada de marcador de posición. Debugger V2 proporciona soporte de primera clase para rastrear las operaciones gráficas y los eventos de ejecución hasta su origen. Cuando hicimos clic en el tensor Log:0 en Graph Executions, la sección Stack Trace se llenó con el seguimiento de pila original de la creación de la operación Log . El seguimiento de la pila es algo grande porque incluye muchos fotogramas del código interno de TensorFlow (por ejemplo, gen_math_ops.py y dumping_callback.py), que podemos ignorar con seguridad para la mayoría de las tareas de depuración. El marco de interés es la Línea 216 de debug_mnist_v2.py (es decir, el archivo Python que en realidad estamos intentando depurar). Al hacer clic en "Línea 216", aparece una vista de la línea de código correspondiente en la sección Código fuente.
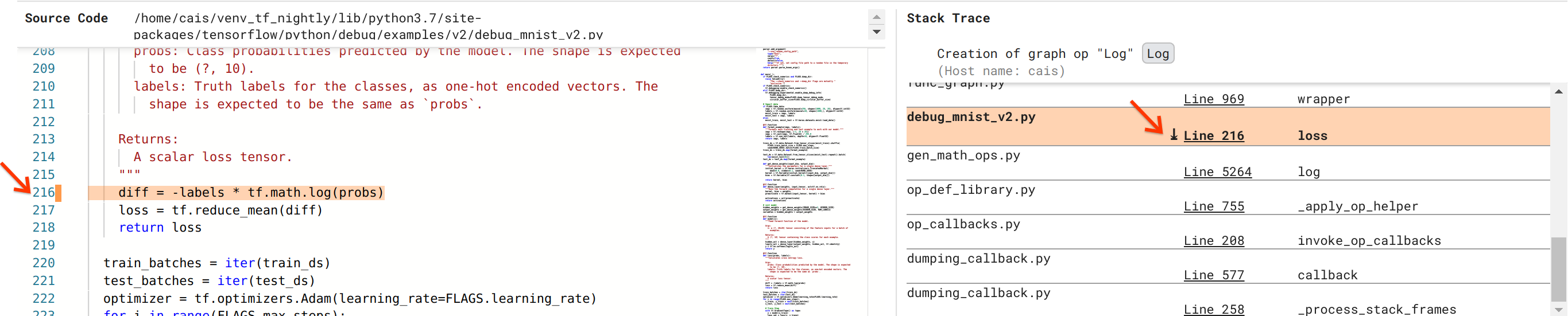
Esto finalmente nos lleva al código fuente que creó la operación Log problemática a partir de su entrada probs . Esta es nuestra función de pérdida de entropía cruzada categórica personalizada decorada con @tf.function y, por lo tanto, convertida en un gráfico de TensorFlow. Los probs de operación del marcador de posición corresponden al primer argumento de entrada de la función de pérdida. La operación Log se crea con la llamada API tf.math.log().
La solución de recorte de valores para este error se verá así:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Resolverá la inestabilidad numérica en este programa TF2 y hará que el MLP se entrene con éxito. Otro posible enfoque para solucionar la inestabilidad numérica es utilizar tf.keras.losses.CategoricalCrossentropy .
Esto concluye nuestro viaje desde la observación de un error del modelo TF2 hasta la idea de un cambio de código que corrija el error, con la ayuda de la herramienta Debugger V2, que proporciona visibilidad completa del historial de ejecución gráfica y entusiasta del programa TF2 instrumentado, incluidos los resúmenes numéricos. de valores tensoriales y asociación entre operaciones, tensores y su código fuente original.
Compatibilidad de hardware del Debugger V2
Debugger V2 admite hardware de entrenamiento convencional, incluidas CPU y GPU. También se admite el entrenamiento de múltiples GPU con tf.distributed.MirroredStrategy . El soporte para TPU aún está en una etapa inicial y requiere una llamada
tf.config.set_soft_device_placement(True)
antes de llamar enable_dump_debug_info() . También puede tener otras limitaciones en los TPU. Si tiene problemas al utilizar Debugger V2, informe los errores en nuestra página de problemas de GitHub .
Compatibilidad API del Debugger V2
Debugger V2 se implementa en un nivel relativamente bajo de la pila de software de TensorFlow y, por lo tanto, es compatible con tf.keras , tf.data y otras API creadas sobre los niveles inferiores de TensorFlow. Debugger V2 también es compatible con TF1, aunque la línea de tiempo de ejecución ansiosa estará vacía para los registros de depuración generados por los programas TF1.
Consejos de uso de API
Una pregunta frecuente sobre esta API de depuración es en qué parte del código de TensorFlow se debe insertar la llamada a enable_dump_debug_info() . Normalmente, se debe llamar a la API lo antes posible en su programa TF2, preferiblemente después de las líneas de importación de Python y antes de que comience la creación y ejecución del gráfico. Esto garantizará una cobertura total de todas las operaciones y gráficos que impulsan su modelo y su entrenamiento.
Los tensor_debug_modes actualmente admitidos son: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH y SHAPE . Varían en la cantidad de información extraída de cada tensor y la sobrecarga de rendimiento del programa depurado. Consulte la sección de argumentos de la documentación de enable_dump_debug_info() .
Gastos generales de rendimiento
La API de depuración introduce una sobrecarga de rendimiento en el programa TensorFlow instrumentado. La sobrecarga varía según tensor_debug_mode , tipo de hardware y naturaleza del programa TensorFlow instrumentado. Como punto de referencia, en una GPU, el modo NO_TENSOR agrega una sobrecarga del 15 % durante el entrenamiento de un modelo Transformer con un tamaño de lote 64. El porcentaje de sobrecarga para otros tensor_debug_modes es mayor: aproximadamente 50 % para CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH y SHAPE modos. En las CPU, la sobrecarga es ligeramente menor. En el caso de las TPU, los gastos generales son actualmente mayores.
Relación con otras API de depuración de TensorFlow
Tenga en cuenta que TensorFlow ofrece otras herramientas y API para la depuración. Puede explorar dichas API en el espacio de nombres tf.debugging.* en la página de documentos de API. Entre estas API, la más utilizada es tf.print() . ¿Cuándo se debe utilizar Debugger V2 y cuándo se debe utilizar tf.print() en su lugar? tf.print() es conveniente en caso de que
- sabemos exactamente qué tensores imprimir,
- sabemos exactamente en qué parte del código fuente insertar esas declaraciones
tf.print(), - el número de tales tensores no es demasiado grande.
Para otros casos (por ejemplo, examinar muchos valores tensoriales, examinar valores tensoriales generados por el código interno de TensorFlow y buscar el origen de la inestabilidad numérica como mostramos anteriormente), Debugger V2 proporciona una forma más rápida de depuración. Además, Debugger V2 proporciona un enfoque unificado para inspeccionar tensores gráficos y ansiosos. Además, proporciona información sobre la estructura del gráfico y las ubicaciones del código, que están más allá de la capacidad de tf.print() .
Otra API que se puede utilizar para depurar problemas relacionados con ∞ y NaN es tf.debugging.enable_check_numerics() . A diferencia de enable_dump_debug_info() , enable_check_numerics() no guarda información de depuración en el disco. En cambio, simplemente monitorea ∞ y NaN durante el tiempo de ejecución de TensorFlow y genera errores con la ubicación del código de origen tan pronto como cualquier operación genera valores numéricos tan incorrectos. Tiene una sobrecarga de rendimiento menor en comparación con enable_dump_debug_info() , pero no ofrece un seguimiento completo del historial de ejecución del programa y no viene con una interfaz gráfica de usuario como Debugger V2.