Im Folgenden wird die Semantik der Vorgänge beschrieben, die in der XlaBuilder-Benutzeroberfläche definiert sind. Normalerweise werden diese Vorgänge Eins-zu-Eins den in der RPC-Schnittstelle in xla_data.proto definierten Vorgängen zugeordnet.
Ein Hinweis zur Nomenklatur: Der allgemeine Datentyp XLA befasst sich mit einem n-dimensionalen Array, das Elemente eines einheitlichen Typs enthält (z. B. 32-Bit-Gleitkommazahl). In der gesamten Dokumentation wird Array verwendet, um ein Array mit beliebiger Dimension zu bezeichnen. Für spezielle Fälle gibt es spezifischere und bekanntere Namen. Ein Vektor ist beispielsweise ein eindimensionales Array und eine Matrix ein zweidimensionales Array.
AfterAll
Weitere Informationen finden Sie unter XlaBuilder::AfterAll.
„AfterAll“ nimmt eine variable Anzahl von Tokens entgegen und gibt ein einzelnes Token aus. Tokens sind primitive Typen, die zwischen Operationen mit Nebenwirkungen eingeschoben werden können, um die Reihenfolge zu erzwingen. AfterAll kann als Token-Join verwendet werden, um einen Vorgang nach einer Set-Operation anzuordnen.
AfterAll(operands)
| Argumente | Typ | Semantik |
|---|---|---|
operands |
XlaOp |
Variadische Anzahl von Tokens |
AllGather
Weitere Informationen finden Sie unter XlaBuilder::AllGather.
Führt eine Konkatenierung über Replikate hinweg aus.
AllGather(operand, all_gather_dim, shard_count, replica_group_ids,
channel_id)
| Argumente | Typ | Semantik |
|---|---|---|
operand
|
XlaOp
|
Array, das über Repliken hinweg verkettet werden soll |
all_gather_dim |
int64 |
Verkettungsdimension |
replica_groups
|
Vektor von Vektoren von
int64 |
Gruppen, zwischen denen die Koncatenate ausgeführt wird |
channel_id
|
Optional int64
|
Optionale Kanal-ID für die modulübergreifende Kommunikation |
replica_groupsist eine Liste von Replikagruppen, zwischen denen die Koncatenate ausgeführt wird. Die Replika-ID für das aktuelle Replikat kann mitReplicaIdabgerufen werden. Die Reihenfolge der Replicas in jeder Gruppe bestimmt die Reihenfolge, in der ihre Eingaben im Ergebnis enthalten sind.replica_groupsmuss entweder leer sein (in diesem Fall gehören alle Replikate zu einer einzigen Gruppe, sortiert von0bisN - 1) oder dieselbe Anzahl von Elementen wie die Anzahl der Replikate enthalten. Beispiel:replica_groups = {0, 2}, {1, 3}führt eine Koncatenate zwischen den Replikas0und2sowie1und3aus.shard_countist die Größe der einzelnen Replikationsgruppen. Wir benötigen dies in Fällen, in denenreplica_groupsleer ist.channel_idwird für die moduleübergreifende Kommunikation verwendet: Nurall-gather-Vorgänge mit demselbenchannel_idkönnen miteinander kommunizieren.
Die Ausgabeform ist die Eingabeform mit dem all_gather_dim, das shard_count-mal größer gemacht wurde. Wenn es beispielsweise zwei Replikate gibt und der Operand in den beiden Replikaten die Werte [1.0, 2.5] und [3.0, 5.25] hat, ist der Ausgabewert dieser Operation, bei der all_gather_dim = 0 ist, in beiden Replikaten [1.0, 2.5, 3.0,
5.25].
AllReduce
Weitere Informationen finden Sie unter XlaBuilder::AllReduce.
Führt eine benutzerdefinierte Berechnung über alle Replikate hinweg aus.
AllReduce(operand, computation, replica_group_ids, channel_id)
| Argumente | Typ | Semantik |
|---|---|---|
operand
|
XlaOp
|
Array oder ein nicht leeres Tupel von Arrays, das über Replikate hinweg reduziert werden soll |
computation |
XlaComputation |
Berechnung der Reduzierung |
replica_groups
|
Vektor von Vektoren von int64 |
Gruppen, zwischen denen die Rabatte gewährt werden |
channel_id
|
optional int64
|
Optionale Kanal-ID für die modulübergreifende Kommunikation |
- Wenn
operandein Tupel von Arrays ist, wird die All-Reduce-Operation auf jedes Element des Tupels angewendet. replica_groupsist eine Liste von Replikatgruppen, zwischen denen die Reduktion durchgeführt wird (Replikat-ID für das aktuelle Replikat kann mitReplicaIdabgerufen werden).replica_groupsmuss entweder leer sein (in diesem Fall gehören alle Replikate zu einer einzelnen Gruppe gehören) oder dieselbe Anzahl von Elementen wie die Anzahl der Replikate enthalten. Beispiel:replica_groups = {0, 2}, {1, 3}führt eine Reduzierung zwischen den Replicas0und2sowie1und3durch.channel_idwird für die moduleübergreifende Kommunikation verwendet: Nurall-reduce-Vorgänge mit demselbenchannel_idkönnen miteinander kommunizieren.
Die Ausgabeform ist mit der Eingabeform identisch. Wenn es beispielsweise zwei Repliken gibt und der Operand in den beiden Repliken jeweils den Wert [1.0, 2.5] und [3.0, 5.25] hat, ist der Ausgabewert dieser Operation und der Summenberechnung in beiden Repliken [4.0, 7.75]. Wenn die Eingabe ein Tupel ist, ist auch die Ausgabe ein Tupel.
Die Berechnung des Ergebnisses von AllReduce erfordert eine Eingabe von jedem Replikat. Wenn also ein Replikat einen AllReduce-Knoten öfter als ein anderes ausführt, wartet das bisherige Replikat für immer. Da die Replikate alle dasselbe Programm ausführen, gibt es dafür nicht viele Möglichkeiten. Es ist jedoch möglich, wenn die Bedingung einer Während-Schleife von Daten aus der Einspeisung abhängt und die eingespeisten Daten dazu führen, dass die while-Schleife mehr Male für ein Replikat iteriert als ein anderes.
AllToAll
Weitere Informationen finden Sie unter XlaBuilder::AllToAll.
AllToAll ist ein kollektiver Vorgang, bei dem Daten von allen Kernen an alle Kerne gesendet werden. Sie umfasst zwei Phasen:
- Die Streuphase. Auf jedem Kern wird der Operand entlang der
split_dimensionsinsplit_countBlöcke aufgeteilt und die Blöcke werden auf alle Kerne verteilt, z. B. wird der i-te Block an den i-ten Kern gesendet. - Die Phase des Sammelns. Jeder Kern verkettet die empfangenen Blöcke entlang der
concat_dimension.
Die teilnehmenden Kerne können so konfiguriert werden:
replica_groups: Jede Replikatgruppe enthält eine Liste der an der Berechnung beteiligten Replikat-IDs (die Replikat-ID für das aktuelle Replikat kann mitReplicaIdabgerufen werden). AllToAll wird innerhalb der Untergruppen in der angegebenen Reihenfolge angewendet.replica_groups = { {1,2,3}, {4,5,0} }bedeutet beispielsweise, dass eine AllToAll-Operation innerhalb der Replicas{1, 2, 3}und in der Sammelphase angewendet wird und die empfangenen Blöcke in der Reihenfolge 1, 2, 3 zusammengefügt werden. Dann wird ein weiteres AllToAll innerhalb der Replikate 4, 5, 0 angewendet und die Verkettungsreihenfolge ist ebenfalls 4, 5, 0. Wennreplica_groupsleer ist, gehören alle Replikatdateien derselben Gruppe an, in der Reihenfolge, in der sie erscheinen.
Voraussetzungen:
- Die Dimensionsgröße des Operanden auf der
split_dimensionist durchsplit_countteilbar. - Die Form des Operanden ist kein Tupel.
AllToAll(operand, split_dimension, concat_dimension, split_count,
replica_groups)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
n-dimensionales Eingabearray |
split_dimension
|
int64
|
Ein Wert im Intervall [0,
n), der die Dimension benennt, nach der der Operand geteilt wird. |
concat_dimension
|
int64
|
Ein Wert im Intervall [0,
n), der die Dimension angibt, entlang der die aufgeteilten Blöcke zusammengefügt werden |
split_count
|
int64
|
Die Anzahl der Kerne, die an diesem Vorgang teilnehmen. Wenn replica_groups leer ist, sollte dies die Anzahl der Replikat sein. Andernfalls sollte dies der Anzahl der Replikat in jeder Gruppe entsprechen. |
replica_groups
|
ReplicaGroup Vektor
|
Jede Gruppe enthält eine Liste von Replik-IDs. |
Unten sehen Sie ein Beispiel für Alltoall.
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(x, /*split_dimension=*/1, /*concat_dimension=*/0, /*split_count=*/4);
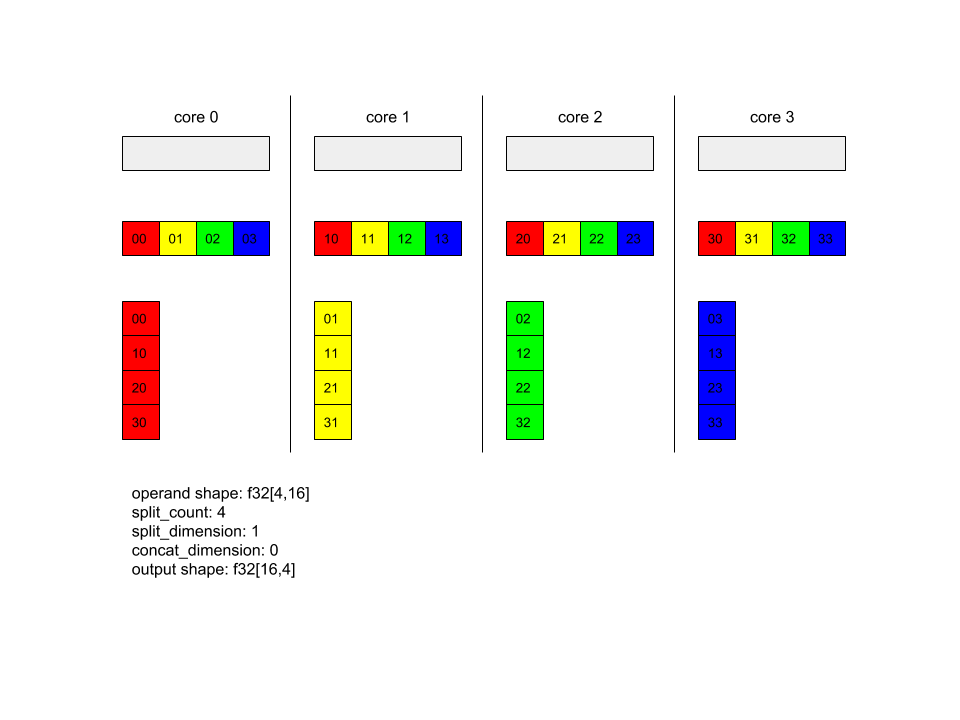
In diesem Beispiel nehmen 4 Kerne an der Alltoall-Operation teil. Auf jedem Kern wird der Operand entlang der Dimension 0 in vier Teile aufgeteilt, sodass jeder Teil die Form f32[4,4] hat. Die vier Teile werden auf alle Kerne verteilt. Anschließend verknüpft jeder Kern die empfangenen Teile entlang der Dimension 1 in der Reihenfolge von Kern 0 bis 4. Die Ausgabe jedes Kerns hat also die Form f32[16,4].
BatchNormGrad
Eine detaillierte Beschreibung des Algorithmus finden Sie auch unter XlaBuilder::BatchNormGrad und im ursprünglichen Batch-Normalisierungspapier.
Berechnet die Gradienten der Batchnormen.
BatchNormGrad(operand, scale, mean, variance, grad_output, epsilon, feature_index)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
N-dimensionales Array, das normalisiert werden soll (x) |
scale |
XlaOp |
1 dimensionales Array () |
mean |
XlaOp |
Eindimensionales Array () |
variance |
XlaOp |
Eindimensionales Array () |
grad_output |
XlaOp |
An BatchNormTraining () übergebene Farbverläufe |
epsilon |
float |
Epsilon-Wert () |
feature_index |
int64 |
Index der Featuredimension in operand |
Für jedes Element in der Dimensionskategorie (feature_index ist der Index für die Dimensionskategorie in operand) werden die Gradienten in Bezug auf operand, offset und scale für alle anderen Dimensionen berechnet. feature_index muss ein gültiger Index für die Featuredimension in operand sein.
Die drei Gradienten werden durch die folgenden Formeln definiert (vorausgesetzt, es wird ein 4-dimensionales Array als operand mit dem Index der Featuredimension l, der Batchgröße m und den räumlichen Größen w und h verwendet):
Die Eingaben mean und variance stellen Momentwerte für Batch- und räumliche Dimensionen dar.
Der Ausgabetyp ist ein Tupel mit drei Handles:
| Ausgaben | Typ | Semantik |
|---|---|---|
grad_operand
|
XlaOp
|
Gradient in Bezug auf die Eingabe operand () |
grad_scale
|
XlaOp
|
Gradient in Bezug auf die Eingabe scale () |
grad_offset
|
XlaOp
|
Farbverlauf in Bezug auf die Eingabe offset() |
BatchNormInference
Eine ausführliche Beschreibung des Algorithmus finden Sie auch unter XlaBuilder::BatchNormInference und im ursprünglichen Artikel zur Batchnormalisierung.
Normalisiert ein Array über Batch- und räumliche Dimensionen hinweg.
BatchNormInference(operand, scale, offset, mean, variance, epsilon, feature_index)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
n-dimensionales Array, das normalisiert werden soll |
scale |
XlaOp |
Eindimensionales Array |
offset |
XlaOp |
Eindimensionales Array |
mean |
XlaOp |
Eindimensionales Array |
variance |
XlaOp |
Eindimensionales Array |
epsilon |
float |
Epsilon-Wert |
feature_index |
int64 |
Index der Featuredimension in operand |
Für jedes Merkmal in der Merkmalsdimension (feature_index ist der Index für die Merkmalsdimension in operand) werden der Mittelwert und die Varianz für alle anderen Dimensionen berechnet. Anhand dieser Werte wird jedes Element in operand normalisiert. feature_index muss ein gültiger Index für die Dimensionseigenschaft in operand sein.
BatchNormInference entspricht dem Aufruf von BatchNormTraining, ohne dass mean und variance für jeden Batch berechnet werden. Stattdessen werden die Eingaben mean und variance als geschätzte Werte verwendet. Der Zweck dieser Operation besteht darin, die Latenz bei der Inferenz zu reduzieren. Daher der Name BatchNormInference.
Die Ausgabe ist ein n-dimensionales, normalisiertes Array mit derselben Form wie die Eingabeoperand.
BatchNormTraining
Eine ausführliche Beschreibung des Algorithmus finden Sie unter XlaBuilder::BatchNormTraining und the original batch normalization paper.
Normalisiert ein Array über Batch- und räumliche Dimensionen hinweg.
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
N-dimensionales Array, das normalisiert werden soll (x) |
scale |
XlaOp |
Eindimensionales Array () |
offset |
XlaOp |
Eindimensionales Array () |
epsilon |
float |
Epsilon-Wert () |
feature_index |
int64 |
Index der Featuredimension in operand |
Für jedes Merkmal in der Merkmalsdimension (feature_index ist der Index für die Merkmalsdimension in operand) werden der Mittelwert und die Varianz über alle anderen Dimensionen berechnet. Anhand dieser Werte wird jedes Element in operand normalisiert. feature_index muss ein gültiger Index für die Dimensionseigenschaft in operand sein.
Der Algorithmus funktioniert für jeden Batch in operand , der m Elemente mit w und h als Größe der räumlichen Dimensionen enthält, so (vorausgesetzt, operand ist ein vierdimensionales Array):
Hier wird die Batch-Mittelung für jedes Merkmal
lin der Merkmaldimension berechnet:Berechnet die Batchvarianz : $\sigma^2l=\frac{1}{mwh}\sum{i=1}^m\sum{j=1}^w\sum{k=1}^h (x_{ijkl} - \mu_l)^2$
Normalisiert, skaliert und verschiebt:
Der Epsilonwert, in der Regel eine kleine Zahl, wird hinzugefügt, um Divisionsfehler zu vermeiden.
Der Ausgabetyp ist ein Tupel aus drei XlaOps:
| Ausgaben | Typ | Semantik |
|---|---|---|
output
|
XlaOp
|
Ein n-dimensionales Array mit derselben Form wie die Eingabeoperand (y) |
batch_mean |
XlaOp |
1 dimensionales Array () |
batch_var |
XlaOp |
Eindimensionales Array () |
batch_mean und batch_var sind Momente, die mithilfe der oben genannten Formeln über die Batch- und räumlichen Dimensionen hinweg berechnet wurden.
BitcastConvertType
Weitere Informationen finden Sie unter XlaBuilder::BitcastConvertType.
Ähnlich wie bei einer tf.bitcast in TensorFlow wird eine elementweise Bitcast-Operation von einer Datenform in eine Zielform ausgeführt. Die Größe der Ein- und Ausgabe muss übereinstimmen: Beispielsweise werden s32-Elemente über eine Bitcast-Routine zu f32-Elementen und ein s32-Element wird zu vier s8-Elementen. Bitcast wird als Low-Level-Cast implementiert, sodass Maschinen mit unterschiedlichen Gleitkommadarstellungen unterschiedliche Ergebnisse liefern.
BitcastConvertType(operand, new_element_type)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array vom Typ T mit den Dimensionen D |
new_element_type |
PrimitiveType |
Typ U |
Die Abmessungen des Operanden und der Zielform müssen übereinstimmen, mit Ausnahme der letzten Dimension, die sich durch das Verhältnis der ursprünglichen Größe vor und nach der Umwandlung ändert.
Die Quell- und Zielelementtypen dürfen keine Tupel sein.
Bitcast-Konvertierung in einen primitiven Typ mit anderer Breite
Die BitcastConvert-HLO-Anweisung unterstützt den Fall, dass die Größe des Ausgabeelementtyps T' nicht der Größe des Eingabeelements T entspricht. Da der gesamte Vorgang konzeptionell ein Bitcast ist und die zugrunde liegenden Bytes nicht geändert werden, muss sich die Form des Ausgabeelements ändern. Für B = sizeof(T), B' =
sizeof(T') gibt es zwei mögliche Fälle.
Bei B > B' erhält die Ausgabeform zuerst eine neue kleinste Dimension mit der Größe B/B'. Beispiel:
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
Für effektive Skalare gilt dieselbe Regel:
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
Alternativ muss für B' > B die letzte logische Dimension der Eingabeform B'/B entsprechen. Diese Dimension wird bei der Umwandlung entfernt:
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
Beachten Sie, dass die Umwandlungen zwischen verschiedenen Bitbreiten nicht elementweise erfolgen.
Nachricht an alle
Weitere Informationen finden Sie unter XlaBuilder::Broadcast.
Fügen Sie einem Array Dimensionen hinzu, indem Sie die Daten im Array duplizieren.
Broadcast(operand, broadcast_sizes)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Das zu duplizierende Array |
broadcast_sizes |
ArraySlice<int64> |
Die Größe der neuen Dimensionen |
Die neuen Dimensionen werden links eingefügt. Wenn broadcast_sizes die Werte {a0, ..., aN} hat und die Operandenform die Dimensionen {b0, ..., bM}, hat die Ausgabeform die Dimensionen {a0, ..., aN, b0, ..., bM}.
Die neuen Abmessungen werden in Kopien des Operanden indexiert, d.h.
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
Wenn operand beispielsweise ein Skalar f32 mit dem Wert 2.0f und broadcast_sizes = {2, 3} ist, ist das Ergebnis ein Array mit der Form f32[2, 3] und allen Werten 2.0f.
BroadcastInDim
Weitere Informationen finden Sie unter XlaBuilder::BroadcastInDim.
Erweitert die Größe und den Rang eines Arrays, indem die Daten im Array dupliziert werden.
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Das Array, das dupliziert werden soll |
out_dim_size |
ArraySlice<int64> |
Die Größe der Abmessungen der Zielform |
broadcast_dimensions |
ArraySlice<int64> |
Welcher Dimension in der Zielform entspricht jede Dimension der Operandenform? |
Ähnlich wie „Broadcast“, aber es können überall Dimensionen hinzugefügt und vorhandene Dimensionen mit der Größe „1“ erweitert werden.
Die operand wird an die durch out_dim_size beschriebene Form gesendet.
Bei broadcast_dimensions werden die Dimensionen von operand den Dimensionen des Zieltyps zugeordnet. Das bedeutet, dass die i. Dimension des Operanden der i. Dimension des Ausgabetyps mit broadcast_dimension[i] zugeordnet wird. Die Dimensionen von operand müssen die Größe 1 haben oder der Größe der Dimension in der Ausgabeform entsprechen, der sie zugeordnet sind. Die verbleibenden Dimensionen werden mit Dimensionen der Größe 1 ausgefüllt. Bei der Übertragung mit degenerierten Dimensionen werden dann Daten entlang dieser degenerierten Dimensionen übertragen, um die Ausgabeform zu erreichen. Die Semantik wird auf der Übertragungsseite ausführlich beschrieben.
Anruf
Weitere Informationen finden Sie unter XlaBuilder::Call.
Ruft eine Berechnung mit den angegebenen Argumenten auf.
Call(computation, args...)
| Argumente | Typ | Semantik |
|---|---|---|
computation |
XlaComputation |
Berechnung vom Typ T_0, T_1, ..., T_{N-1} -> S mit N Parametern beliebigen Typs |
args |
Sequenz von N XlaOps |
N Argumente beliebigen Typs |
Die Arität und Typen von args müssen mit den Parametern der computation übereinstimmen. Es darf kein args vorhanden sein.
Cholesky
Weitere Informationen finden Sie unter XlaBuilder::Cholesky.
Berechnet die Cholesky-Zerlegung einer Gruppe symmetrischer (hermitescher) positiv definiter Matrizen.
Cholesky(a, lower)
| Argumente | Typ | Semantik |
|---|---|---|
a |
XlaOp |
ein Array mit Rang > 2 eines komplexen oder Gleitkommatyps. |
lower |
bool |
ob das obere oder untere Dreieck von a verwendet werden soll. |
Wenn lower true ist, werden die unteren dreieckigen Matrizen l so berechnet, dass . Wenn lower = false ist, werden obere Dreiecksmatrizen u berechnet, sodass.
Die Eingabedaten werden je nach Wert von lower nur aus dem unteren oder oberen Dreieck von a gelesen. Werte aus dem anderen Dreieck werden ignoriert. Die Ausgabedaten werden im selben Dreieck zurückgegeben. Die Werte im anderen Dreieck sind implementierungsspezifisch und können beliebig sein.
Wenn der Rang von a größer als 2 ist, wird a als Batch von Matrizen behandelt, wobei alle Dimensionen mit Ausnahme der zwei untergeordneten Dimensionen Batchdimensionen sind.
Wenn a nicht symmetrisch (Hermitian) und positiv definit ist, ist das Ergebnis implementierungsabhängig.
Klemme
Weitere Informationen finden Sie unter XlaBuilder::Clamp.
Fixiert einen Operanden innerhalb des Bereichs zwischen einem Mindest- und Höchstwert.
Clamp(min, operand, max)
| Argumente | Typ | Semantik |
|---|---|---|
min |
XlaOp |
Array vom Typ T |
operand |
XlaOp |
Array vom Typ T |
max |
XlaOp |
Array vom Typ T |
Gibt bei einem Operanden und Mindest- und Höchstwerten den Operanden zurück, wenn er sich im Bereich zwischen dem Mindest- und dem Höchstwert befindet. Andernfalls wird der Minimalwert zurückgegeben, wenn der Operand unter diesem Bereich liegt, oder den Maximalwert, wenn der Operand oberhalb dieses Bereichs liegt. Der Wert ist clamp(a, x, b) = min(max(a, x), b).
Alle drei Arrays müssen die gleiche Form haben. Alternativ können min und/oder max als eingeschränkte Form der Broadcasting-Funktion als Skalar vom Typ T verwendet werden.
Beispiel mit den Skalaren min und max:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
Minimieren
Weitere Informationen finden Sie unter XlaBuilder::Collapse und den Vorgang tf.reshape.
Die Dimensionen eines Arrays werden in eine Dimension zusammengefasst.
Collapse(operand, dimensions)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array vom Typ T |
dimensions |
int64 Vektor |
eine geordnete, aufeinanderfolgende Teilmenge der Dimensionen von T. |
Durch Zusammenführen wird die angegebene Teilmenge der Dimensionen des Operanden durch eine einzelne Dimension ersetzt. Die Eingabeargumente sind ein beliebiges Array vom Typ T und ein Kompilierungszeitkonstantenvektor von Dimensionsindexen. Die Dimensionsindizes müssen in der richtigen Reihenfolge (niedrigste bis höchste Dimensionsnummer) eine fortlaufende Teilmenge der Dimensionen von T sein. Daher sind {0, 1, 2}, {0, 1} oder {1, 2} gültige Dimensionsgruppen, {1, 0} oder {0, 2} jedoch nicht. Sie werden durch eine einzelne neue Dimension ersetzt, die an derselben Position in der Dimensionssequenz wie die ersetzten Dimensionen steht. Die Größe der neuen Dimension entspricht dem Produkt der ursprünglichen Dimensionsgrößen. Die niedrigste Dimensionsnummer in dimensions ist diejenige Dimension mit der geringsten Abweichung (die größte Hauptdimension) in der Schleifenverschachtelung, bei der diese Dimensionen minimiert werden. Die höchste Dimensionsnummer variiert am schnellsten (die größte kleinste). Wenn Sie eine allgemeinere Zusammenführungsreihenfolge benötigen, sehen Sie sich den Operator tf.reshape an.
Lassen Sie v z. B. ein Array mit 24 Elementen sein:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
CollectivePermute
Weitere Informationen finden Sie unter XlaBuilder::CollectivePermute.
CollectivePermute ist ein kollektiver Vorgang, bei dem Daten zwischen Replikas gesendet und empfangen werden.
CollectivePermute(operand, source_target_pairs)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
n-dimensionales Eingabearray |
source_target_pairs |
<int64, int64> Vektor |
Eine Liste von (source_Replikat-ID, Ziel-Replikat-ID)-Paaren. Für jedes Paar wird der Operand vom Quellreplikat an das Zielreplikat gesendet. |
Für source_target_pair gelten die folgenden Einschränkungen:
- Keines der Paare darf dieselbe Zielreplikat-ID und dieselbe Quellreplikat-ID haben.
- Wenn eine Replikat-ID in keinem Paar als Ziel festgelegt ist, ist die Ausgabe für dieses Replikat ein Tensor mit Nullen in derselben Form wie die Eingabe.
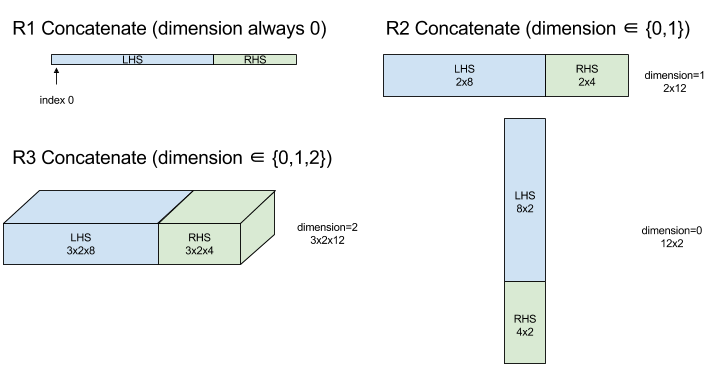
Verketten
Weitere Informationen finden Sie unter XlaBuilder::ConcatInDim.
Mit „Verketten“ wird ein Array aus mehreren Arrayoperanden gebildet. Das Array hat denselben Rang wie die einzelnen Operanden des Eingabearrays (die denselben Rang haben müssen) und enthält die Argumente in der Reihenfolge, in der sie angegeben wurden.
Concatenate(operands..., dimension)
| Argumente | Typ | Semantik |
|---|---|---|
operands |
Sequenz von N XlaOp |
N Arrays vom Typ T mit den Dimensionen [L0, L1, ...]. Es muss N >= 1 sein. |
dimension |
int64 |
Ein Wert im Intervall [0, N), der die Dimension angibt, die zwischen den operands zusammengefügt werden soll. |
Mit Ausnahme von dimension müssen alle Dimensionen gleich sein. Das liegt daran, dass XLA keine unvollständigen Arrays unterstützt. Werte mit Rang 0 können nicht verkettet werden, da die Dimension, entlang derer die Verkettung erfolgt, nicht benannt werden kann.
Eindimensionales Beispiel:
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
>>> {2, 3, 4, 5, 6, 7}
Zweidimensionales Beispiel:
let a = {
{1, 2},
{3, 4},
{5, 6},
};
let b = {
{7, 8},
};
Concat({a, b}, 0)
>>> {
{1, 2},
{3, 4},
{5, 6},
{7, 8},
}
Diagramm:
Bedingt
Weitere Informationen finden Sie unter XlaBuilder::Conditional.
Conditional(pred, true_operand, true_computation, false_operand,
false_computation)
| Argumente | Typ | Semantik |
|---|---|---|
pred |
XlaOp |
Skalar vom Typ PRED |
true_operand |
XlaOp |
Argument vom Typ |
true_computation |
XlaComputation |
Xla-Berechnung vom Typ |
false_operand |
XlaOp |
Argument des Typs |
false_computation |
XlaComputation |
Xla-Berechnung vom Typ |
Führt true_computation aus, wenn pred gleich true ist, und false_computation, wenn pred gleich false ist. Das Ergebnis wird zurückgegeben.
true_computation muss ein einzelnes Argument vom Typ annehmen und wird mit true_operand aufgerufen, das vom selben Typ sein muss. false_computation muss ein einzelnes Argument vom Typ annehmen und wird mit false_operand aufgerufen, das vom selben Typ sein muss. Der Typ des zurückgegebenen Werts von true_computation und false_computation muss gleich sein.
Je nach Wert von pred wird nur eine von true_computation und false_computation ausgeführt.
Conditional(branch_index, branch_computations, branch_operands)
| Argumente | Typ | Semantik |
|---|---|---|
branch_index |
XlaOp |
Skalar vom Typ S32 |
branch_computations |
Folge von N XlaComputation |
Xla-Berechnungen vom Typ |
branch_operands |
Sequenz von N XlaOp |
Argumente vom Typ |
Führt branch_computations[branch_index] aus und gibt das Ergebnis zurück. Wenn branch_index eine S32 ist, die < 0 oder >= N ist, wird branch_computations[N-1] als Standardzweig ausgeführt.
Jede branch_computations[b] muss ein einzelnes Argument vom Typ annehmen und wird mit branch_operands[b] aufgerufen, das vom selben Typ sein muss. Der Typ des zurückgegebenen Werts von branch_computations[b] muss bei allen Elementen gleich sein.
Je nach Wert von branch_index wird nur eine der branch_computations-Aktionen ausgeführt.
Conv (Faltung)
Weitere Informationen finden Sie unter XlaBuilder::Conv.
Wie ConvWithGeneralPadding, aber die Füllung wird kurz als SAME oder VALID angegeben. Bei der SAME-Ausrichtung wird die Eingabe (lhs) mit Nullen aufgefüllt, damit die Ausgabe dieselbe Form wie die Eingabe hat, wenn der Schritt nicht berücksichtigt wird. VALID padding bedeutet einfach, dass kein Padding verwendet wird.
ConvWithGeneralPadding (Faltung)
Weitere Informationen finden Sie unter XlaBuilder::ConvWithGeneralPadding.
Er berechnet eine Convolution, wie sie in neuronalen Netzwerken verwendet wird. Hier kann eine Convolution als n-dimensionales Fenster betrachtet werden, das sich über einen n-dimensionalen Basisbereich bewegt. Für jede mögliche Position des Fensters wird eine Berechnung durchgeführt.
| Argumente | Typ | Semantik |
|---|---|---|
lhs |
XlaOp |
Array mit n + 2 Eingängen |
rhs |
XlaOp |
n + 2 rangiges Array mit Kernelgewichten |
window_strides |
ArraySlice<int64> |
n-D-Array der Kernelschritte |
padding |
ArraySlice< pair<int64,int64>> |
n-dimensionaler Array mit (niedrig, hoch)-Abstand |
lhs_dilation |
ArraySlice<int64> |
n-dimensionaler Array mit dem Faktor für die LHS-Erweiterung |
rhs_dilation |
ArraySlice<int64> |
n-dimensionales Array mit dem Faktor für die RHS-Dilatation |
feature_group_count |
int64 | die Anzahl der Featuregruppen |
batch_group_count |
int64 | Anzahl der Batchgruppen |
n ist die Anzahl der räumlichen Dimensionen. Das lhs-Argument ist ein Array vom Rang n+2, das die Basisfläche beschreibt. Dies wird als Eingabe bezeichnet, obwohl natürlich auch der RHS eine Eingabe ist. In einem neuronalen Netzwerk sind dies die Eingabeaktivierungen.
Die n+2 Dimensionen sind in dieser Reihenfolge:
batch: Jede Koordinate in dieser Dimension stellt eine unabhängige Eingabe dar, für die die Convolution durchgeführt wird.z/depth/features: Jede (y,x)-Position im Basisbereich ist mit einem Vektor verknüpft, der in diese Dimension eingeht.spatial_dims: Beschreibt dienräumlichen Dimensionen, die den Basisbereich definieren, über den sich das Fenster bewegt.
Das Argument rhs ist ein Array vom Rang n+2, das den Convolutional-Filter/-Kern/-Fenster beschreibt. Die Dimensionen sind in dieser Reihenfolge:
output-z: Diez-Dimension der Ausgabe.input-z: Die Größe dieser Dimension multipliziert mitfeature_group_countsollte der Größe der Dimensionzin LPS entsprechen.spatial_dims: Beschreibt dienräumlichen Dimensionen, die das n‑dimensionale Fenster definieren, das sich über den Basisbereich bewegt.
Das Argument window_strides gibt den Schritt des Faltungsfensters in den räumlichen Dimensionen an. Wenn beispielsweise die Schrittlänge in der ersten räumlichen Dimension 3 beträgt, kann das Fenster nur an Koordinaten platziert werden, bei denen der erste räumliche Index durch 3 teilbar ist.
Das Argument padding gibt an, wie viel Null-Padding auf den Basisbereich angewendet werden soll. Die Größe des Paddings kann negativ sein. Der absolute Wert des negativen Paddings gibt die Anzahl der Elemente an, die vor der Durchführung der Convolution aus der angegebenen Dimension entfernt werden. padding[0] gibt den Abstand für die Dimension y und padding[1] den Abstand für die Dimension x an. Jedes Paar hat die geringe Textabstand als erstes Element und die große Textabstand als zweites Element. Die geringe Lücke wird in Richtung niedrigerer Indizes angewendet, während die große Lücke in Richtung höherer Indizes angewendet wird. Wenn padding[1] beispielsweise (2,3) ist, wird in der zweiten räumlichen Dimension links mit zwei Nullen und rechts mit drei Nullen eingefügt. Das Hinzufügen von Padding entspricht dem Einfügen derselben Nullwerte in die Eingabe (lhs) vor der Durchführung der Convolution.
Mit den Argumenten lhs_dilation und rhs_dilation wird der Vergrößerungsfaktor angegeben, der in jeder räumlichen Dimension auf „lhs“ bzw. „rhs“ angewendet werden soll. Wenn der Vergrößerungsfaktor in einer räumlichen Dimension d ist, werden zwischen jedem der Einträge in dieser Dimension implizit d-1 Lücken platziert, wodurch die Größe des Arrays erhöht wird. Die Löcher werden mit einem Nullwert gefüllt, was bei der Convolution Nullen bedeutet.
Die Dilatation der rechten Seite wird auch als atrosische Convolution bezeichnet. Weitere Informationen finden Sie unter tf.nn.atrous_conv2d. Die Dilatation des linken Glieds wird auch als transponierte Konvolution bezeichnet. Weitere Informationen finden Sie unter tf.nn.conv2d_transpose.
Das Argument feature_group_count (Standardwert 1) kann für gruppierte Convolutionen verwendet werden. feature_group_count muss sowohl für die Eingabe- als auch für die Ausgabe-Featuredimension ein Teiler sein. Wenn feature_group_count größer als 1 ist, bedeutet das, dass die Eingabe- und Ausgabefeature-Dimension und die rhs-Ausgabefeature-Dimension konzeptionell gleichmäßig in viele feature_group_count-Gruppen aufgeteilt werden, wobei jede Gruppe aus einer fortlaufenden Folge von Features besteht. Die Eingabemerkmalsdimension rhs muss der Eingabemerkmalsdimension lhs geteilt durch feature_group_count entsprechen. Sie hat also bereits die Größe einer Gruppe von Eingabemerkmalen. Die i-ten Gruppen werden zusammen verwendet, um feature_group_count für viele separate Convolutionen zu berechnen. Die Ergebnisse dieser Faltungen werden in der Ausgabefeature-Dimension verkettet.
Bei der richtungsabhängigen Convolution wird das Argument feature_group_count auf die Eingabefeature-Dimension festgelegt und der Filter wird von [filter_height, filter_width, in_channels, channel_multiplier] in [filter_height, filter_width, 1, in_channels * channel_multiplier] umgewandelt. Weitere Informationen finden Sie unter tf.nn.depthwise_conv2d.
Das Argument batch_group_count (Standardwert 1) kann für gruppierte Filter während der Backpropagation verwendet werden. batch_group_count muss ein Divisor der Größe der Batchdimension lhs (Eingabe) sein. Wenn batch_group_count größer als 1 ist, sollte die Ausgabe-Batchdimension die Größe input batch
/ batch_group_count haben. Die batch_group_count muss ein Teiler der Größe der Ausgabeelemente sein.
Die Ausgabeform hat in dieser Reihenfolge die folgenden Dimensionen:
batch: Die Größe dieser Dimension multipliziert mitbatch_group_countmuss der Größe der Dimensionbatchin lhs entsprechen.z: Entspricht der Größe vonoutput-zim Kernel (rhs).spatial_dims: Ein Wert für jede gültige Platzierung des Convolutional-Fensters.

Die Abbildung oben zeigt, wie das Feld batch_group_count funktioniert. Tatsächlich teilen wir jeden LH-Batch in batch_group_count-Gruppen auf und führen denselben Vorgang für die Ausgabefeatures aus. Anschließend führen wir für jede dieser Gruppen paarweise Convolutionen durch und fügen die Ausgabe entlang der Ausgabemerkmalsdimension zusammen. Die betriebliche Semantik aller anderen Dimensionen (Feature- und räumliche) bleibt unverändert.
Die gültigen Platzierungen des Convolutional-Fensters werden durch die Schritte und die Größe der Grundfläche nach dem Padding bestimmt.
Um die Funktionsweise einer Faltung zu beschreiben, betrachten Sie eine 2D-Faltung und wählen feste batch-, z-, y- und x-Koordinaten in der Ausgabe aus. Dann ist (y,x) die Position einer Ecke des Fensters im Basisbereich (z. B. die linke obere Ecke, je nachdem, wie Sie die räumlichen Dimensionen interpretieren). Wir haben jetzt ein 2D-Fenster aus dem Basisbereich, bei dem jeder 2D-Punkt mit einem 1D-Vektor verknüpft ist. So erhalten wir einen 3D-Quader. Da wir die Ausgabekoordinate z für den Convolutional-Kernel festgelegt haben, haben wir auch einen 3D-Box. Die beiden Boxen haben dieselben Abmessungen, sodass wir die Summe der elementweisen Produkte zwischen den beiden Boxen nehmen können (ähnlich wie bei einem Skalarprodukt). Das ist der Ausgabewert.
Wenn output-z z.B. 5, dann werden für jede Position des Fensters fünf Werte in der Ausgabe in der Dimension z generiert. Diese Werte unterscheiden sich darin, welcher Teil des Convolutional Kernels verwendet wird – für jede output-z-Koordinate wird ein separater 3D-Feldwert verwendet. Sie können es sich also als fünf separate
Faltungen mit einem anderen Filter vorstellen.
Hier ist der Pseudocode für eine 2D-Konvolution mit Padding und Schrittweite:
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
ConvertElementType
Weitere Informationen finden Sie unter XlaBuilder::ConvertElementType.
Ähnlich wie eine elementweise static_cast in C++ führt dieser Befehl eine elementweise Konvertierung von einer Datenform in eine Zielform aus. Die Dimensionen müssen übereinstimmen und die Conversion muss elementweise erfolgen. Beispiel: s32-Elemente werden über eine s32-zu-f32-Conversion-Routine in f32-Elemente umgewandelt.
ConvertElementType(operand, new_element_type)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array vom Typ T mit den Dimensionen D |
new_element_type |
PrimitiveType |
Typ U |
Die Abmessungen des Operanden und der Zielform müssen übereinstimmen. Die Quell- und Zielelementtypen dürfen keine Tupel sein.
Bei einer Konvertierung wie T=s32 in U=f32 wird eine normalisierende Konvertierungsroutine vom Typ „Int in Float“ ausgeführt, z. B. „auf die nächste gerade Zahl aufrunden“.
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
CrossReplicaSum
Führt AllReduce mit einer Summenberechnung aus.
CustomCall
Weitere Informationen finden Sie unter XlaBuilder::CustomCall.
Eine vom Nutzer bereitgestellte Funktion innerhalb einer Berechnung aufrufen.
CustomCall(target_name, args..., shape)
| Argumente | Typ | Semantik |
|---|---|---|
target_name |
string |
Name der Funktion. Es wird eine Aufrufanweisung ausgegeben, die auf diesen Symbolnamen ausgerichtet ist. |
args |
Folge von N XlaOps |
N Argumente beliebigen Typs, die an die Funktion übergeben werden. |
shape |
Shape |
Ausgabeform der Funktion |
Die Funktionssignatur ist unabhängig von der Arity oder dem Typ von args identisch:
extern "C" void target_name(void* out, void** in);
Beispiel:
let x = f32[2] {1,2};
let y = f32[2x3] { {10, 20, 30}, {40, 50, 60} };
CustomCall("myfunc", {x, y}, f32[3x3])
Hier ein Beispiel für eine Implementierung von myfunc:
extern "C" void myfunc(void* out, void** in) {
float (&x)[2] = *static_cast<float(*)[2]>(in[0]);
float (&y)[2][3] = *static_cast<float(*)[2][3]>(in[1]);
EXPECT_EQ(1, x[0]);
EXPECT_EQ(2, x[1]);
EXPECT_EQ(10, y[0][0]);
EXPECT_EQ(20, y[0][1]);
EXPECT_EQ(30, y[0][2]);
EXPECT_EQ(40, y[1][0]);
EXPECT_EQ(50, y[1][1]);
EXPECT_EQ(60, y[1][2]);
float (&z)[3][3] = *static_cast<float(*)[3][3]>(out);
z[0][0] = x[1] + y[1][0];
// ...
}
Die vom Nutzer bereitgestellte Funktion darf keine Nebenwirkungen haben und ihre Ausführung muss idempotent sein.
Punkt
Weitere Informationen finden Sie unter XlaBuilder::Dot.
Dot(lhs, rhs)
| Argumente | Typ | Semantik |
|---|---|---|
lhs |
XlaOp |
Array vom Typ T |
rhs |
XlaOp |
Array vom Typ T |
Die genaue Semantik dieses Vorgangs hängt von den Rängen der Operanden ab:
| Eingabe | Ausgabe | Semantik |
|---|---|---|
Vektor [n] dot Vektor [n] |
Skalar | Skalarprodukt |
Matrix [m × k] dot Vektor [k] |
Vektor [m] | Matrix-Vektor-Multiplikation |
Matrix [m x k] dot Matrix [k x n] |
Matrix [m × n] | Matrixmultiplikation |
Der Vorgang führt die Summe der Produkte über die zweite Dimension von lhs (oder die erste, wenn sie Rang 1 hat) und die erste Dimension von rhs aus. Das sind die „zusammengeführten“ Dimensionen. Die minimierten Abmessungen von lhs und rhs müssen gleich groß sein. In der Praxis kann es zum Ausführen von Skalarprodukten zwischen Vektoren, Vektor-/Matrixmultiplikationen oder Matrix-/Matrixmultiplikationen verwendet werden.
DotGeneral
Weitere Informationen finden Sie unter XlaBuilder::DotGeneral.
DotGeneral(lhs, rhs, dimension_numbers)
| Argumente | Typ | Semantik |
|---|---|---|
lhs |
XlaOp |
Array vom Typ T |
rhs |
XlaOp |
Array vom Typ T |
dimension_numbers |
DotDimensionNumbers |
Vertrags- und Batch-Dimensionsnummern |
Ähnlich wie bei Punkt, ermöglicht aber die Angabe von Nummern für Vertrags- und Batchgrößen sowohl für lhs als auch für rhs.
| DotDimensionNumbers-Felder | Typ | Semantik |
|---|---|---|
lhs_contracting_dimensions
|
repeated int64 | lhs Nummer der Dimension für den Auftrag |
rhs_contracting_dimensions
|
wiederholte Int64-Daten | rhs Nummer der Dimension für den Auftrag |
lhs_batch_dimensions
|
repeated int64 | lhs Batch-Dimensionsnummern |
rhs_batch_dimensions
|
wiederholte Int64-Daten | rhs Batchdimension
Nummern |
DotGeneral berechnet die Summe der Produkte über die vertraglich vereinbarten Dimensionen, die in dimension_numbers angegeben sind.
Die zugehörigen Nummern der Vertragsdimensionen aus lhs und rhs müssen nicht identisch sein, aber dieselben Dimensionsgrößen haben.
Beispiel mit schrumpfenden Dimensionszahlen:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { {6.0, 12.0},
{15.0, 30.0} }
Die zugehörigen Nummern der Batchdimensionen aus lhs und rhs müssen dieselbe Dimensionsgröße haben.
Beispiel mit Batch-Dimensionsnummern (Batchgröße 2, 2x2-Matrizen):
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| Eingabe | Ausgabe | Semantik |
|---|---|---|
[b0, m, k] dot [b0, k, n] |
[b0, m, n] | batch matmul |
[b0, b1, m, k] dot [b0, b1, k, n] |
[b0, b1, m, n] | batch matmul |
Daraus folgt, dass die sich ergebende Dimensionsnummer mit der Batch-Dimension beginnt, dann mit der Dimension lhs für befristete/nicht Batch-bezogene und schließlich mit der Dimension rhs für nicht vertragsbezogene und nicht Batch-bezogene.
DynamicSlice
Weitere Informationen finden Sie unter XlaBuilder::DynamicSlice.
Mit DynamicSlice wird ein Teilarray aus dem Eingabearray an der dynamischen Position start_indices extrahiert. Die Größe des Segments in jeder Dimension wird in size_indices übergeben. Damit wird der Endpunkt exklusiver Segmentintervalle in jeder Dimension angegeben: [Start, Start + Größe). Die Form von start_indices muss den Rang 1 haben und die Dimensionsgröße muss dem Rang von operand entsprechen.
DynamicSlice(operand, start_indices, size_indices)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
N-dimensionales Array vom Typ T |
start_indices |
Sequenz von N XlaOp |
Liste von N ganzzahligen Skalaren, die die Startindizes des Ausschnitts für jede Dimension enthalten. Der Wert muss größer oder gleich null sein. |
size_indices |
ArraySlice<int64> |
Liste mit N Ganzzahlen, die die Größe der Scheibe für jede Dimension enthalten. Jeder Wert muss größer als null sein. „Start“ + „Größe“ darf nicht größer als die Größe der Dimension sein, um einen Umbruch nach der Modulo-Größe der Dimension zu vermeiden. |
Die effektiven Intervallindices werden berechnet, indem vor dem Ausführen des Intervalls die folgende Transformation auf jeden Index i in [1, N) angewendet wird:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - size_indices[i])
Dadurch wird sichergestellt, dass das extrahierte Segment in Bezug auf das Operand-Array immer innerhalb der Grenzen liegt. Wenn sich der Ausschnitt vor der Anwendung der Transformation innerhalb des Bereichs befindet, hat die Transformation keine Auswirkungen.
Eindimensionales Beispiel:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let s = {2}
DynamicSlice(a, s, {2}) produces:
{2.0, 3.0}
Zweidimensionales Beispiel:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
DynamicUpdateSlice
Weitere Informationen finden Sie unter XlaBuilder::DynamicUpdateSlice.
„DynamicUpdateSlice“ generiert ein Ergebnis, das dem Wert des Eingabearrays operand entspricht, wobei ein Slice update an start_indices überschrieben wird.
Die Form von update bestimmt die Form des Teilarrays des Ergebnisses, das aktualisiert wird.
Die Form von start_indices muss den Rang 1 haben und die Dimensionsgröße muss dem Rang von operand entsprechen.
DynamicUpdateSlice(operand, update, start_indices)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
N-dimensionales Array vom Typ T |
update |
XlaOp |
Ein n-dimensionales Array vom Typ T, das die Aktualisierung des Slabs enthält. Jede Dimension der Update-Form muss größer als null sein und „start“ + „update“ muss für jede Dimension kleiner oder gleich der Operandengröße sein, um Indexwerte zu vermeiden, die außerhalb des zulässigen Bereichs liegen. |
start_indices |
Sequenz von N XlaOp |
Liste von N ganzzahligen Skalaren, die die Startindizes des Ausschnitts für jede Dimension enthalten. Wert muss größer oder gleich null sein. |
Die effektiven Intervallindices werden berechnet, indem vor dem Ausführen des Intervalls die folgende Transformation auf jeden Index i in [1, N) angewendet wird:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
So wird sichergestellt, dass der aktualisierte Ausschnitt immer innerhalb des Operandenarrays liegt. Wenn das Segment vor der Anwendung der Transformation innerhalb der Grenzen liegt, hat die Transformation keine Auswirkungen.
Eindimensionales Beispiel:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s) produces:
{0.0, 1.0, 5.0, 6.0, 4.0}
2-dimensionales Beispiel:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s) produces:
{ {0.0, 1.0, 2.0},
{3.0, 12.0, 13.0},
{6.0, 14.0, 15.0},
{9.0, 16.0, 17.0} }
Elementweise binäre arithmetische Operationen
Weitere Informationen finden Sie unter XlaBuilder::Add.
Es werden eine Reihe von elementweisen binären arithmetischen Operationen unterstützt.
Op(lhs, rhs)
Dabei steht Op für eine der folgenden Funktionen: Add (Addition), Sub (Subtraktion), Mul (Multiplikation), Div (Division), Pow (Potenz), Rem (Rest), Max (Maximum), Min (Minimum), And (logisches AND), Or (logisches OR), Xor (logisches XOR), ShiftLeft (Linksverschiebung), ShiftRightArithmetic (Arithmetische Rechtsverschiebung), ShiftRightLogical (logische Rechtsverschiebung), Atan2 (Arkustangens mit zwei Argumenten) oder Complex (Kombiniert den reellen und den imaginären Teil zu einer komplexen Zahl)
| Argumente | Typ | Semantik |
|---|---|---|
lhs |
XlaOp |
Operand auf der linken Seite: Array vom Typ T |
rhs |
XlaOp |
Operand auf der rechten Seite: Array vom Typ T |
Die Formen der Argumente müssen entweder ähnlich oder kompatibel sein. In der Dokumentation zu Übertragungen erfahren Sie, was es bedeutet, dass Formen kompatibel sind. Das Ergebnis einer Operation hat die Form, die durch das Broadcasten der beiden Eingabearrays entsteht. Bei dieser Variante werden Vorgänge zwischen Arrays verschiedener Ränge nicht unterstützt, es sei denn, einer der Operanden ist ein Skalar.
Wenn Op = Rem ist, wird das Vorzeichen des Ergebnisses aus dem Dividenden übernommen und der absolute Wert des Ergebnisses ist immer kleiner als der absolute Wert des Nenners.
Bei einem Überlauf bei der Ganzzahldivision (Division/Rest mit Vorzeichen/ohne Vorzeichen durch Null oder Division/Rest mit Vorzeichen von INT_SMIN mit -1) wird ein implementierungsdefinierter Wert ausgegeben.
Für diese Vorgänge gibt es eine alternative Variante mit Unterstützung für die Übertragung mit unterschiedlichen Rangfolgen:
Op(lhs, rhs, broadcast_dimensions)
Dabei ist Op wie oben angegeben. Diese Variante des Vorgangs sollte für arithmetische Operationen zwischen Arrays unterschiedlicher Ränge verwendet werden, z. B. wenn einem Vektor eine Matrix hinzugefügt wird.
Der zusätzliche broadcast_dimensions-Operand ist ein Array von Ganzzahlen, mit dem der Rang des Operanden mit niedrigerem Rang auf den Rang des Operanden mit höherem Rang erweitert wird. broadcast_dimensions ordnet die Abmessungen der Form mit dem niedrigeren Rang den Abmessungen der Form mit dem höheren Rang zu. Die nicht zugeordneten Dimensionen der erweiterten Form werden mit Dimensionen der Größe 1 ausgefüllt. Bei der Übertragung mit degenerierten Dimensionen werden die Formen dann entlang dieser degenerierten Dimensionen übertragen, um die Formen beider Operanden anzugleichen. Die Semantik wird auf der Übertragungsseite ausführlich beschrieben.
Elementweise Vergleichsvorgänge
Weitere Informationen finden Sie unter XlaBuilder::Eq.
Es werden eine Reihe standardmäßiger elementweiser binärer Vergleichsvorgänge unterstützt. Beachten Sie, dass die Standard-IEEE 754-Gleitkommasemantik beim Vergleich von Gleitkommatypen angewendet wird.
Op(lhs, rhs)
Dabei steht Op für Eq (gleich), Ne (ungleich), Ge (größer oder gleich), Gt (größer), Le (kleiner oder gleich) oder Lt (kleiner). Die Operatoren „EqTotalOrder“, „NeTotalOrder“, „GeTotalOrder“, „GtTotalOrder“, „LeTotalOrder“ und „LtTotalOrder“ bieten dieselben Funktionen, mit der Ausnahme, dass sie zusätzlich eine totale Ordnung über die Gleitkommazahlen unterstützen, indem sie -NaN < -Inf < -Finite < -0 < +0 < +Finite < +Inf < +NaN erzwingen.
| Argumente | Typ | Semantik |
|---|---|---|
lhs |
XlaOp |
Operand auf der linken Seite: Array vom Typ T |
rhs |
XlaOp |
Operand auf der rechten Seite: Array vom Typ T |
Die Formen der Argumente müssen entweder ähnlich oder kompatibel sein. In der Dokumentation zu Übertragungen erfahren Sie, was es bedeutet, dass Formen kompatibel sind. Das Ergebnis einer Operation hat die Form, die durch das Broadcasten der beiden Eingabearrays mit dem Elementtyp PRED entsteht. Bei dieser Variante werden keine Operationen zwischen Arrays unterschiedlicher Ränge unterstützt, es sei denn, einer der Operanden ist ein Skalar.
Für diese Vorgänge gibt es eine alternative Variante mit Unterstützung für die Übertragung mit unterschiedlichen Rangfolgen:
Op(lhs, rhs, broadcast_dimensions)
Dabei ist Op dasselbe wie oben. Diese Variante des Vorgangs sollte für Vergleichsvorgänge zwischen Arrays mit unterschiedlichen Rängen verwendet werden, z. B. für das Hinzufügen einer Matrix zu einem Vektor.
Der zusätzliche Operand broadcast_dimensions ist ein Array von Ganzzahlen, das die Dimensionen angibt, die für die Übertragung der Operanden verwendet werden sollen. Die Semantik wird auf der Seite „Übertragungen“ ausführlich beschrieben.
Elementweise unary functions
XlaBuilder unterstützt die folgenden elementweisen unaryn Funktionen:
Abs(operand) Elementweiser x -> |x|-Abs.
Cbrt(operand) Elementweise Kubikwurzel x -> cbrt(x)
Ceil(operand) Elementweiser Wert x -> ⌈x⌉.
Clz(operand) Zählt führende Nullen elementweise.
Cos(operand) Elementweiser Kosinus x -> cos(x).
Erf(operand) Elementweise Fehlerfunktion x -> erf(x) mit
.
Exp(operand) Elementweise natürliche Exponentialfunktion x -> e^x.
Expm1(operand) Elementweises natürliches Exponential minus ein x -> e^x - 1
Floor(operand) Elementweises Stockwerk x -> ⌊x⌋.
Imag(operand) Elementweiser imaginärer Teil einer komplexen (oder reellen) Form. x -> imag(x). Wenn der Operand ein Gleitkommatyp ist, wird 0 zurückgegeben.
IsFinite(operand) Prüft, ob jedes Element von operand endlich ist, d. h., nicht positiv oder negativ unendlich und nicht NaN ist. Gibt ein Array von PRED-Werten mit derselben Form wie die Eingabe zurück. Jedes Element ist true, wenn und nur wenn das entsprechende Eingabeelement endlich ist.
Log(operand) Elementweiser natürlicher Logarithmus x -> ln(x).
Log1p(operand) Elementweise verschobener natürlicher Logarithmus x -> ln(1+x).
Logistic(operand) Elementweise Berechnung der logistischen Funktion x ->
logistic(x).
Neg(operand) Elementweise Negation x -> -x.
Not(operand) Elementweises logisches Nicht x -> !(x).
PopulationCount(operand) Berechnet die Anzahl der Bits, die in jedem Element von operand festgelegt sind.
Real(operand) Elementweiser reeller Teil einer komplexen (oder reellen) Form.
x -> real(x). Wenn der Operand ein Gleitkommatyp ist, wird derselbe Wert zurückgegeben.
Round(operand) Elementweises Runden, gleicht null auf.
RoundNearestEven(operand) Elementweises Runden auf die nächste gerade Zahl.
Rsqrt(operand) Elementweises Kehrwert der Quadratwurzelx -> 1.0 / sqrt(x).
Sign(operand) Elementweiser Signaturvorgang x -> sgn(x), wobei
mit dem Vergleichsoperator des Elementtyps operand.
Sin(operand) Elementweiser Sinus x -> sin(x).
Sqrt(operand) Elementweiser Quadratwurzelvorgang x -> sqrt(x).
Tan(operand) Elementweise Tangente x -> tan(x).
Tanh(operand) Elementweiser hyperbolischer Tangens x -> tanh(x).
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Den Operanden der Funktion |
Die Funktion wird auf jedes Element im operand-Array angewendet, was zu einem Array mit derselben Form führt. operand darf ein Skalar (Rang 0) sein.
Fft
Die XLA FFT-Operation implementiert die Vorwärts- und Inverse-Fourier-Transformationen für reale und komplexe Ein-/Ausgaben. Es werden multidimensionale FFTs auf bis zu drei Achsen unterstützt.
Weitere Informationen finden Sie unter XlaBuilder::Fft.
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Das Array, das wir durch die Fourier-Transformation berechnen. |
fft_type |
FftType |
Siehe die folgende Tabelle. |
fft_length |
ArraySlice<int64> |
Die Längen der Achsen in der Zeitdomain, die transformiert werden. Dies ist insbesondere für die IRFFT erforderlich, um die innerste Achse richtig zu skalieren, da RFFT(fft_length=[16]) dieselbe Ausgabeform wie RFFT(fft_length=[17]) hat. |
FftType |
Semantik |
|---|---|
FFT |
Direkte komplexe-zu-komplexe FFT. Die Form bleibt unverändert. |
IFFT |
Inverse komplexe-zu-komplexe FFT. Die Form bleibt unverändert. |
RFFT |
Weiterleiten von Echtzeit-FFT (Real-to-Complexed FFT). Die Form der innersten Achse wird auf fft_length[-1] // 2 + 1 reduziert, wenn fft_length[-1] einen Wert ungleich 0 hat. Dabei wird der umgekehrte konjugierte Teil des transformierten Signals über der Nyquist-Frequenz weggelassen. |
IRFFT |
Inverse reell-zu-komplexe FFT (d. h. nimmt komplexe Werte an, gibt reelle Werte zurück). Die Form der innersten Achse wird auf fft_length[-1] erweitert, wenn fft_length[-1] ein Wert ungleich Null ist. Der Teil des transformierten Signals, der über der Nyquist-Frequenz liegt, wird aus dem umgekehrten Konjugat der Einträge 1 bis fft_length[-1] // 2 + 1 abgeleitet. |
Multidimensionale FFT
Wenn mehr als eine fft_length angegeben wird, entspricht dies der Anwendung einer Kaskade von FFT-Vorgängen auf jede der innersten Achsen. Beachten Sie, dass bei den Fällen „reell → komplex“ und „komplex → reell“ die Transformation der innersten Achse (effektiv) zuerst ausgeführt wird (RFFT; bei IRFFT zuletzt). Deshalb ändert sich die Größe der innersten Achse. Andere Achsentransformationen sind dann „komplex“ -> „komplex“.
Implementierungsdetails
Die CPU-FFT wird von Eigens TensorFFT unterstützt. GPU FFT verwendet cuFFT.
Sammeln
Der XLA-Gattervorgang fügt mehrere Segmente (jedes Segment mit einem potenziell unterschiedlichen Laufzeitoffset) eines Eingabearrays zusammen.
Allgemeine Semantik
Weitere Informationen finden Sie unter XlaBuilder::Gather.
Eine intuitivere Beschreibung finden Sie unten im Abschnitt „Informale Beschreibung“.
gather(operand, start_indices, offset_dims, collapsed_slice_dims, slice_sizes, start_index_map)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Die Matrix, aus der wir Daten sammeln. |
start_indices |
XlaOp |
Array mit den Startindizes der erfassten Segmente. |
index_vector_dim |
int64 |
Die Dimension in start_indices, die die Anfangsindizes „enthält“. Eine detaillierte Beschreibung finden Sie unten. |
offset_dims |
ArraySlice<int64> |
Der Satz von Dimensionen in der Ausgabeform, die in ein Array versetzt werden, das vom Operanden getrennt ist. |
slice_sizes |
ArraySlice<int64> |
slice_sizes[i] sind die Grenzen für das Segment nach Dimension i. |
collapsed_slice_dims |
ArraySlice<int64> |
Die Dimensionen in jedem Segment, die minimiert sind. Diese Abmessungen müssen Größe 1 haben. |
start_index_map |
ArraySlice<int64> |
Eine Zuordnung, die beschreibt, wie Indizes in start_indices auf zulässige Indizes im Operanden abgebildet werden. |
indices_are_sorted |
bool |
Gibt an, ob die Indexe garantiert vom Aufrufer sortiert werden. |
Der Einfachheit halber werden Dimensionen im Ausgabearray, nicht in offset_dims, mit batch_dims gekennzeichnet.
Die Ausgabe ist ein Array vom Rang batch_dims.size + offset_dims.size.
operand.rank muss der Summe von offset_dims.size und collapsed_slice_dims.size entsprechen. Außerdem muss slice_sizes.size mit operand.rank übereinstimmen.
Wenn index_vector_dim = start_indices.rank, wird davon ausgegangen, dass start_indices eine nachgestellte 1-Dimension hat. Wenn start_indices also die Form [6,7] hat und index_vector_dim = 2, wird davon ausgegangen, dass start_indices die Form [6,7,1] hat.
Die Grenzen für das Ausgabearray entlang der Dimension i werden so berechnet:
Wenn
iinbatch_dimsvorhanden ist (d.h. für einigekgleichbatch_dims[k]ist), wählen wir die entsprechenden Dimensionsgrenzen ausstart_indices.shapeaus und überspringenindex_vector_dim(d.h. wählen Siestart_indices.shape.dims[k] aus, wennk<index_vector_dimist, und ansonstenstart_indices.shape.dims[k+1].Wenn
iinoffset_dimsvorhanden ist (d. h.offset_dims[k] für eine bestimmtekentspricht), wählen wir die entsprechende Grenze ausslice_sizesaus, nachdemcollapsed_slice_dimsberücksichtigt wurde. Das heißt, wir wählenadjusted_slice_sizes[k] aus, wobeiadjusted_slice_sizesslice_sizesist, ohne die Grenzen an den Indizescollapsed_slice_dims.
Der Operandenindex In, der einem bestimmten Ausgabeindex Out entspricht, wird formal so berechnet:
Angenommen,
G= {Out[k] fürkinbatch_dims}. Verwenden SieG, um einen VektorSzu schneiden, sodassS[i] =start_indices[Combine(G,i)] ist, wobei Combine(A, b) b an Positionindex_vector_dimin A einfügt. Hinweis: Dies ist auch dann eindeutig definiert, wennGleer ist: IstGleer, dann istS=start_indices.Erstellen Sie einen Startindex (
Sin) inoperandmithilfe vonS. Verteilen Sie dazuSmitstart_index_map. Genauer gesagt:Sin[start_index_map[k]] =S[k], wennk<start_index_map.size.Sin[_] =0andernfalls.
Erstellen Sie einen Index
Oininoperand, indem Sie die Indizes an den Versatzdimensionen inOutgemäß dem Satzcollapsed_slice_dimsverteilen. Genauer gesagt:Oin[remapped_offset_dims(k)] =Out[offset_dims[k]] wennk<offset_dims.size(remapped_offset_dimsist unten definiert).Oin[_] =0andernfalls.
InistOin+Sin, wobei „+“ die elementweise Addition ist.
remapped_offset_dims ist eine monotone Funktion mit der Definitionsmenge [0, offset_dims.size) und dem Definitionsbereich [0, operand.rank) \ collapsed_slice_dims. Wenn also z.B. Wenn offset_dims.size = 4, operand.rank = 6 und collapsed_slice_dims = {0, 2}, ist remapped_offset_dims = {0→1, 1→3, 2→4, 3→5}.
Wenn indices_are_sorted auf „wahr“ gesetzt ist, kann XLA davon ausgehen, dass start_indices vom Nutzer sortiert wurde (in aufsteigender Reihenfolge, nachdem die Werte gemäß start_index_map verstreut wurden). Andernfalls werden die Semantiken von der Implementierung definiert.
Informelle Beschreibung und Beispiele
Informell entspricht jeder Index-Out im Ausgabearray einem Element E im Operanden-Array, das so berechnet wird:
Anhand der Batch-Dimensionen in
Outwird ein Startindex ausstart_indicesabgerufen.Mit
start_index_mapwird der Startindex (dessen Größe kleiner als operand.rank sein kann) einem „vollständigen“ Startindex inoperandzugeordnet.Wir schneiden dynamisch einen Ausschnitt mit der Größe
slice_sizesmit dem vollständigen Startindex aus.Die Form des Slice wird durch Minimieren der
collapsed_slice_dims-Dimensionen angepasst. Da alle minimierten Dimensionsebenen eine Obergrenze von 1 haben müssen, ist diese Neuformatierung immer zulässig.Wir verwenden die Offset-Dimensionen in
Out, um in diesem Snippet zu indexieren und das EingabeelementEzu erhalten, das dem AusgabeindexOutentspricht.
In allen folgenden Beispielen ist index_vector_dim auf start_indices.rank bis 1 festgelegt. Interessantere Werte für index_vector_dim ändern die Funktionsweise nicht grundlegend, erschweren aber die visuelle Darstellung.
Um zu verstehen, wie das alles zusammenhängt, sehen wir uns ein Beispiel an, bei dem fünf Scheiben der Form [8,6] aus einem [16,11]-Array erfasst werden. Die Position eines Segments im [16,11]-Array kann als Indexvektor der Form S64[2] dargestellt werden. Die fünf Positionen können also als S64[5,2]-Array dargestellt werden.
Das Verhalten des Aggregationsvorgangs kann dann als Indextransformation dargestellt werden, die [G,O0,O1] als Index in der Ausgabeform annimmt und auf folgende Weise einem Element im Eingabearray zuordnet:

Wir wählen zuerst mit G einen (X,Y)-Vektor aus dem Index-Array für die Gruppierung aus.
Das Element im Ausgabearray mit dem Index [G,O0,O1] ist dann das Element im Eingabearray mit dem Index [X+O0,Y+O1].
slice_sizes ist [8,6], wodurch der Bereich von O0 und O1 bestimmt wird. Dies wiederum bestimmt die Grenzen des Slice.
Dieser Erfassungsvorgang agiert als ein dynamisches Batch-Slice mit G als Batchdimension.
Die Datenerfassungsindexe können mehrdimensional sein. In einer allgemeineren Version des obigen Beispiels mit einem Array zum Sammeln von Indexen der Form [4,5,2] würden Indexe beispielsweise so übersetzt werden:

Auch hier handelt es sich um einen dynamischen Batch-Ausschnitt G0 mit den Batch-Dimensionen G1. Die Größe der Scheibe bleibt [8,6].
Der GATHER-Vorgang in XLA verallgemeinert die oben beschriebenen informellen Semantiken auf folgende Weise:
Wir können konfigurieren, welche Dimensionen im Ausgabeformat die Offset-Dimensionen sind (Dimensionen mit
O0,O1im letzten Beispiel). Die Ausgabe-Batchdimensionen (Dimensionen mitG0,G1im letzten Beispiel) sind die Ausgabedimensionen, die keine Offset-Dimensionen sind.Die Anzahl der explizit in der Ausgabeform vorhandenen Ausgabe-Offset-Dimensionen kann kleiner als der Eingaberang sein. Diese „fehlenden“ Dimensionen, die ausdrücklich als
collapsed_slice_dimsaufgeführt sind, müssen eine Segmentgröße von1haben. Da sie eine Slice-Größe von1haben, ist der einzige gültige Index für sie0. Das Weglassen von ihnen führt nicht zu Mehrdeutigkeiten.Das aus dem Array "Aggregate-Indexe" (im letzten Beispiel
X,Y) extrahierte Segment kann weniger Elemente als der Rang des Eingabearrays haben. Eine explizite Zuordnung gibt vor, wie der Index so erweitert werden soll, dass er denselben Rang wie die Eingabe hat.
Als letztes Beispiel verwenden wir (2) und (3) zur Implementierung von tf.gather_nd:

Mit G0 und G1 wird wie gewohnt ein Startindex aus dem Array „Indexe für die Datenerhebung“ extrahiert. Der Unterschied besteht darin, dass der Startindex nur ein Element hat: X. Ebenso gibt es nur einen Ausgabeoffsetindex mit dem Wert O0. Bevor sie jedoch als Indizes in das Eingabearray übernommen werden, werden sie gemäß „Indexzuordnung für die Datenerhebung“ (start_index_map in der formellen Beschreibung) und „Offsetzuordnung“ (remapped_offset_dims in der formellen Beschreibung) in [X,0] und [0,O0] erweitert. Die Summe dieser beiden Indizes ergibt [X,O0]. Mit anderen Worten: Der Ausgabeindex [G0,G1,O0] wird dem Eingabeindex [GatherIndices[G0,G1,0],O0] zugeordnet, was die Semantik für tf.gather_nd ergibt.
slice_sizes für diesen Fall ist [1,11]. Intuitiv bedeutet das, dass jeder Index X im Array „Zusammenfassungsindex“ eine ganze Zeile auswählt und das Ergebnis die Koncatenate aller dieser Zeilen ist.
GetDimensionSize
Weitere Informationen finden Sie unter XlaBuilder::GetDimensionSize.
Gibt die Größe der angegebenen Dimension des Operanden zurück. Der Operand muss ein Array sein.
GetDimensionSize(operand, dimension)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
n-dimensionales Eingabearray |
dimension |
int64 |
Ein Wert im Intervall [0, n), der die Dimension angibt |
SetDimensionSize
Weitere Informationen finden Sie unter XlaBuilder::SetDimensionSize.
Legt die dynamische Größe der angegebenen Dimension von XlaOp fest. Der Operand muss ein Array sein.
SetDimensionSize(operand, size, dimension)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
n-dimensionalen Eingabearray. |
size |
XlaOp |
int32, die die dynamische Größe der Laufzeit darstellt. |
dimension |
int64 |
Ein Wert im Intervall [0, n), der die Dimension angibt. |
Der Operand wird als Ergebnis übergeben, wobei die dynamische Dimension vom Compiler erfasst wird.
Aufgefüllte Werte werden von nachgelagerten Reduktionsvorgängen ignoriert.
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
GetTupleElement
Weitere Informationen finden Sie unter XlaBuilder::GetTupleElement.
Indexiert in einem Tupel mit einem konstanten Wert zur Kompilierungszeit.
Der Wert muss eine Konstante zur Kompilierungszeit sein, damit die Forminferenz den Typ des resultierenden Werts bestimmen kann.
Das entspricht std::get<int N>(t) in C++. Konzeptionell:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
Weitere Informationen finden Sie unter tf.tuple.
Infeed
Weitere Informationen finden Sie unter XlaBuilder::Infeed.
Infeed(shape)
| Argument | Typ | Semantik |
|---|---|---|
shape |
Shape |
Form der aus der In-Feed-Oberfläche gelesenen Daten. Das Layoutfeld der Form muss mit dem Layout der an das Gerät gesendeten Daten übereinstimmen. Andernfalls ist das Verhalten nicht definiert. |
Liest ein einzelnes Datenelement aus der impliziten InFeed-Streaming-Schnittstelle des Geräts, interpretiert die Daten als gegebene Form und ihr Layout und gibt eine XlaOp der Daten zurück. In einer Berechnung sind mehrere In-Feed-Vorgänge zulässig. Es muss jedoch eine Gesamtreihenfolge für die In-Feed-Vorgänge geben. Im folgenden Code haben beispielsweise zwei Infeeds eine Gesamtreihenfolge, da es eine Abhängigkeit zwischen den While-Schleifen gibt.
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
Verschachtelte Tupelformen werden nicht unterstützt. Bei einer leeren Tupelform ist der Infeed-Vorgang im Grunde ein Null-Vorgang und wird ausgeführt, ohne dass Daten aus dem Infeed des Geräts gelesen werden.
Iota
Weitere Informationen finden Sie unter XlaBuilder::Iota.
Iota(shape, iota_dimension)
Es wird ein konstantes Literal auf dem Gerät erstellt, anstatt eine potenziell große Hostübertragung. Erstellt ein Array mit einer angegebenen Form und den Werten, die bei null beginnen und entlang der angegebenen Dimension um eins erhöht werden. Bei Gleitkommatypen entspricht das erzeugte Array ConvertElementType(Iota(...)), wobei der Iota vom Typ und die Konvertierung in den Gleitkommatyp ist.
| Argumente | Typ | Semantik |
|---|---|---|
shape |
Shape |
Form des von Iota() erstellten Arrays |
iota_dimension |
int64 |
Die Dimension, entlang derer der Wert erhöht werden soll. |
Beispiel: Iota(s32[4, 8], 0) gibt
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
Iota(s32[4, 8], 1) für Retouren
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
Karte
Weitere Informationen finden Sie unter XlaBuilder::Map.
Map(operands..., computation)
| Argumente | Typ | Semantik |
|---|---|---|
operands |
Sequenz von N XlaOps |
N Arrays der Typen T0..T{N-1} |
computation |
XlaComputation |
Berechnung vom Typ T_0, T_1, .., T_{N + M -1} -> S mit N Parametern vom Typ T und M vom beliebigen Typ |
dimensions |
int64-Array |
Array mit Kartenabmessungen |
Wendet eine Skalarfunktion auf die angegebenen operands-Arrays an und erzeugt dabei ein Array mit denselben Abmessungen, wobei jedes Element das Ergebnis der zugeordneten Funktion ist, die auf die entsprechenden Elemente in den Eingabearrays angewendet wird.
Die zugeordnete Funktion ist eine beliebige Berechnung mit der Einschränkung, dass sie N Eingaben vom Skalartyp T und eine einzelne Ausgabe vom Typ S hat. Die Ausgabe hat dieselben Dimensionen wie die Operanden, mit der Ausnahme, dass der Elementtyp T durch S ersetzt wird.
Beispiel: Map(op1, op2, op3, computation, par1) ordnet elem_out <-
computation(elem1, elem2, elem3, par1) jedem (mehrdimensionalen) Index in den Eingabearrays zu, um das Ausgabearray zu erstellen.
OptimizationBarrier
Verhindert, dass Optimierungsdurchläufe Berechnungen über die Barriere hinweg verschieben.
Damit wird sichergestellt, dass alle Eingaben vor allen Operatoren ausgewertet werden, die von den Ausgaben der Barriere abhängen.
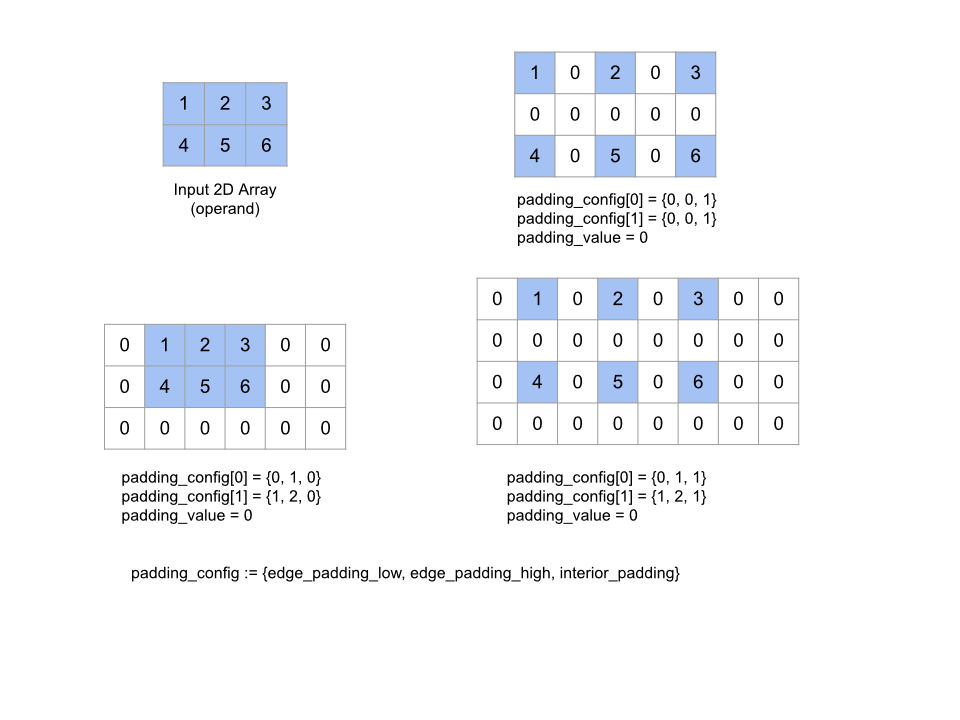
Pad
Weitere Informationen finden Sie unter XlaBuilder::Pad.
Pad(operand, padding_value, padding_config)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array vom Typ T |
padding_value |
XlaOp |
Skalar vom Typ T, um das hinzugefügte Padding auszufüllen |
padding_config |
PaddingConfig |
Abstand auf beiden Rändern (niedrig, hoch) und zwischen den Elementen der einzelnen Abmessungen |
Erweitert das angegebene operand-Array, indem um das Array herum und zwischen den Elementen des Arrays mit dem angegebenen padding_value ein Abstand hinzugefügt wird. padding_config gibt den Rahmen des Rands und den Innenrand für jede Dimension an.
PaddingConfig ist ein wiederkehrendes Feld von PaddingConfigDimension, das drei Felder für jede Dimension enthält: edge_padding_low, edge_padding_high und interior_padding.
edge_padding_low und edge_padding_high geben den Grad des Paddings an, das am unteren Ende (neben Index 0) bzw. am oberen Ende (neben dem höchsten Index) jeder Dimension hinzugefügt wird. Die Größe des Randabstands kann negativ sein. Der absolute Wert des negativen Abstands gibt die Anzahl der Elemente an, die aus der angegebenen Dimension entfernt werden sollen.
interior_padding gibt den Abstand zwischen zwei beliebigen Elementen in jeder Dimension an. Dieser Wert darf nicht negativ sein. Das Innenabstand wird logisch vor dem Randabstand angewendet. Bei einem negativen Randabstand werden Elemente aus dem Operanden mit Innenabstand entfernt.
Dieser Vorgang ist wirkungslos, wenn alle Ränder (0, 0) und alle Werte für den Innenabstand 0 sind. Die folgende Abbildung zeigt Beispiele für verschiedene edge_padding- und interior_padding-Werte für ein zweidimensionales Array.
Recv
Weitere Informationen finden Sie unter XlaBuilder::Recv.
Recv(shape, channel_handle)
| Argumente | Typ | Semantik |
|---|---|---|
shape |
Shape |
Form der zu empfangenden Daten |
channel_handle |
ChannelHandle |
eindeutige Kennung für jedes Sende-/Empfangspaar |
Empfängt Daten der angegebenen Form aus einer Send-Anweisung in einer anderen Berechnung mit demselben Kanal-Handle. Gibt eine XlaOp für die empfangenen Daten zurück.
Die Client API des Recv-Vorgangs stellt die synchrone Kommunikation dar.
Die Anweisung wird jedoch intern in zwei HLO-Anweisungen (Recv und RecvDone) zerlegt, um asynchrone Datenübertragungen zu ermöglichen. Siehe auch HloInstruction::CreateRecv und HloInstruction::CreateRecvDone.
Recv(const Shape& shape, int64 channel_id)
Hier werden Ressourcen zugewiesen, die zum Empfangen von Daten aus einer Send-Anweisung mit derselben channel_id erforderlich sind. Gibt einen Kontext für die zugewiesenen Ressourcen zurück, der von einer nachfolgenden RecvDone-Anweisung verwendet wird, um auf den Abschluss der Datenübertragung zu warten. Der Kontext ist ein Tupel von {Empfangsbuffer (Form), Anfrage-ID (U32)} und kann nur von einer RecvDone-Anweisung verwendet werden.
RecvDone(HloInstruction context)
Wartet bei einem durch eine Recv-Anweisung erstellten Kontext auf den Abschluss der Datenübertragung und gibt die empfangenen Daten zurück.
Einschränken
Weitere Informationen finden Sie unter XlaBuilder::Reduce.
Wendet eine Reduzierungsfunktion parallel auf ein oder mehrere Arrays an.
Reduce(operands..., init_values..., computation, dimensions)
| Argumente | Typ | Semantik |
|---|---|---|
operands |
Sequenz von N XlaOp |
N Arrays vom Typ T_0, ..., T_{N-1}. |
init_values |
Sequenz von N XlaOp |
N Skalare vom Typ T_0, ..., T_{N-1}. |
computation |
XlaComputation |
Berechnung vom Typ T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}). |
dimensions |
int64-Array |
Unsortiertes Array der Dimensionen, die reduziert werden sollen. |
Wobei:
- N muss größer oder gleich 1 sein.
- Die Berechnung muss "grob" assoziativ sein (siehe unten).
- Alle Eingabearrays müssen dieselbe Größe haben.
- Alle Anfangswerte müssen unter
computationeine Identität bilden. - Wenn
N = 1,Collate(T)=T. - Wenn
N > 1,Collate(T_0, ..., T_{N-1})ein Tupel vonN-Elementen vom TypTist.
Bei diesem Vorgang werden eine oder mehrere Dimensionen jedes Eingabearrays in Skalare umgewandelt.
Der Rang jedes zurückgegebenen Arrays ist rank(operand) - len(dimensions). Die Ausgabe der Operation ist Collate(Q_0, ..., Q_N), wobei Q_i ein Array vom Typ T_i ist, dessen Dimensionen unten beschrieben werden.
Verschiedene Back-Ends können die Reduktionsberechnung neu zuordnen. Dies kann zu numerischen Abweichungen führen, da einige Reduktionsfunktionen wie die Addition für Gleitkommazahlen nicht assoziativ sind. Wenn der Datenbereich jedoch begrenzt ist, reicht die Gleitkommazahl in den meisten praktischen Anwendungen so gut aus, dass sie assoziativ ist.
Beispiele
Wenn Sie in einem einzelnen 1D-Array mit Werten [10, 11,
12, 13] über eine Dimension mit der Reduzierungsfunktion f (das ist computation) reduzieren, kann das so berechnet werden:
f(10, f(11, f(12, f(init_value, 13)))
Es gibt aber auch viele andere Möglichkeiten, z. B.
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
Im Folgenden finden Sie ein grobes Pseudocode-Beispiel dafür, wie eine Reduzierung implementiert werden könnte. Dabei wird die Summe als Reduktionsberechnung mit einem Anfangswert von 0 verwendet.
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the rank of the result
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
Hier ein Beispiel für die Reduzierung eines 2D-Arrays (einer Matrix): Die Form hat den Rang 2, die Dimension 0 hat die Größe 2 und die Dimension 1 die Größe 3:
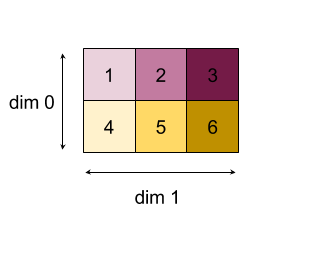
Ergebnisse der Reduzierung der Dimensionen 0 oder 1 mit einer Additionsfunktion:
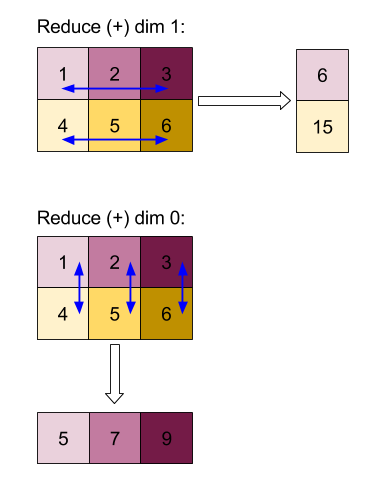
Beachten Sie, dass beide Ergebnisse der Dimensionsreduzierung eindimensionale Arrays sind. Im Diagramm werden sie nur zu Veranschaulichung als Spalte und Zeile dargestellt.
Hier ein komplexeres Beispiel für ein 3D-Array: Der Rang ist 3, Dimension 0 hat die Größe 4, Dimension 1 die Größe 2 und Dimension 2 die Größe 3. Zur Vereinfachung werden die Werte 1 bis 6 in Dimension 0 repliziert.
Ähnlich wie beim 2D-Beispiel können wir nur eine Dimension reduzieren. Wenn wir beispielsweise Dimension 0 reduzieren, erhalten wir ein Array Rang-2, in dem alle Werte der Dimension 0 zu einem Skalar zusammengefasst werden:
| 4 8 12 |
| 16 20 24 |
Wenn wir Dimension 2 reduzieren, erhalten wir auch ein Array – Rang 2, in dem alle Werte in Dimension 2 zu einem Skalar zusammengefasst wurden:
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
Die relative Reihenfolge zwischen den verbleibenden Dimensionen in der Eingabe wird in der Ausgabe beibehalten. Einige Dimensionen erhalten jedoch möglicherweise neue Zahlen, da sich der Rang ändert.
Wir können auch mehrere
Dimensionen reduzieren. Wenn Sie die Dimensionen 0 und 1 hinzufügen und reduzieren, erhalten Sie das 1‑dimensionale Array [20, 28, 36].
Wenn das 3D-Array über alle Dimensionen hinweg reduziert wird, wird das skalare 84-Element erzeugt.
Variadic Reduce
Bei N > 1 ist die Anwendung der Funktion „Reduzieren“ etwas komplexer, da sie gleichzeitig auf alle Eingaben angewendet wird. Die Operanden werden der Berechnung in der folgenden Reihenfolge zugeführt:
- Reduzierter Wert für den ersten Operanden wird ausgeführt
- …
- Reduzierter Wert für den n-ten Operanden wird ausgeführt
- Eingabewert für den ersten Operanden
- …
- Eingabewert für den n-ten Operanden
Betrachten Sie beispielsweise die folgende Reduktionsfunktion, mit der der Maximalwert und der Argmax eines eindimensionalen Arrays parallel berechnet werden können:
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
Bei eindimensionalen Eingabearrays V = Float[N], K = Int[N] und Anfangswerten I_V = Float, I_K = Int entspricht das Ergebnis f_(N-1) der Reduzierung über die einzige Eingabedimension der folgenden rekursiven Anwendung:
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
Wenn Sie diese Reduktion auf ein Array von Werten und ein Array mit sequenziellen Indizes (z. B. „iota“) anwenden, werden die Arrays gemeinsam durchlaufen und ein Tupel mit dem maximalen Wert und dem zugehörigen Index zurückgegeben.
ReducePrecision
Weitere Informationen finden Sie unter XlaBuilder::ReducePrecision.
Hiermit wird die Umwandlung von Gleitkommawerten in ein Format mit niedrigerer Genauigkeit (z. B. IEEE-FP16) und zurück in das Originalformat simuliert. Die Anzahl der Exponenten- und Mantissenbits im Format mit niedrigerer Genauigkeit kann beliebig festgelegt werden. Allerdings werden möglicherweise nicht alle Bitgrößen von allen Hardwareimplementierungen unterstützt.
ReducePrecision(operand, mantissa_bits, exponent_bits)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array des Gleitkommatyps T. |
exponent_bits |
int32 |
Anzahl der Exponentenbits im Format mit niedrigerer Genauigkeit |
mantissa_bits |
int32 |
Anzahl der Mantissenbits im Format mit niedrigerer Genauigkeit |
Das Ergebnis ist ein Array vom Typ T. Die Eingabewerte werden auf den nächsten Wert gerundet, der mit der angegebenen Anzahl von Mantissenbits darstellbar ist (mit der Semantik „Gleichgewicht auf gerade Zahlen“). Alle Werte, die den durch die Anzahl der Exponentenbits angegebenen Bereich überschreiten, werden auf positive oder negative Unendlichkeit begrenzt. NaN-Werte werden beibehalten, können aber in kanonische NaN-Werte umgewandelt werden.
Das Format mit geringerer Genauigkeit muss mindestens ein Exponentenbit haben (um einen Nullwert von einem Unendlich zu unterscheiden, da beide eine Null-Mantisse haben) und eine nicht negative Anzahl von Mantissenbits haben. Die Anzahl der Exponenten- oder Mantissenbits kann den entsprechenden Wert für den Typ T überschreiten. Der entsprechende Teil der Konvertierung ist dann einfach eine Null-Operation.
ReduceScatter
Weitere Informationen finden Sie unter XlaBuilder::ReduceScatter.
ReduceScatter ist ein kollektiver Vorgang, der effektiv einen AllReduce durchführt und das Ergebnis dann verteilt, indem es in shard_count-Blöcke entlang des scatter_dimension-Werts aufgeteilt wird. Das Replikat i in der Replikatgruppe empfängt den ith-Shard.
ReduceScatter(operand, computation, scatter_dim, shard_count,
replica_group_ids, channel_id)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array oder ein nicht leeres Tupel von Arrays, das über Replikate hinweg reduziert werden soll. |
computation |
XlaComputation |
Berechnung der Reduzierung |
scatter_dimension |
int64 |
Dimension für die Streudiagramme. |
shard_count |
int64 |
Anzahl der zu teilenden Blöcke: scatter_dimension |
replica_groups |
Vektor von Vektoren von int64 |
Gruppen, zwischen denen die Rabatte gewährt werden |
channel_id |
Optional int64 |
Optionale Channel-ID für die moduleübergreifende Kommunikation |
- Wenn
operandein Tupel von Arrays ist, wird die Reduzierungs-/Scattering-Operation auf jedes Element des Tupels angewendet. replica_groupsist eine Liste von Replikationsgruppen, zwischen denen die Reduzierung durchgeführt wird. Die Replikations-ID für das aktuelle Replik kann mitReplicaIdabgerufen werden. Die Reihenfolge der Replikate in jeder Gruppe bestimmt die Reihenfolge, in der das Ergebnis der Allreduce-Funktion verteilt wird.replica_groupsmuss entweder leer sein (in diesem Fall gehören alle Replikate zu einer einzigen Gruppe) oder dieselbe Anzahl von Elementen wie die Anzahl der Replikate enthalten. Wenn es mehrere Replikationsgruppen gibt, müssen sie alle dieselbe Größe haben. Beispielsweise führtreplica_groups = {0, 2}, {1, 3}eine Reduzierung zwischen den Replikaten0und2sowie1und3durch und verteilt dann das Ergebnis.shard_countist die Größe der einzelnen Replikationsgruppen. Wir benötigen diese Informationen, wennreplica_groupsleer ist. Wennreplica_groupsnicht leer ist, mussshard_countder Größe jeder Replikatgruppe entsprechen.channel_idwird für die moduleübergreifende Kommunikation verwendet: Nurreduce-scatter-Vorgänge mit demselbenchannel_idkönnen miteinander kommunizieren.
Die Ausgabeform ist die Eingabeform, bei der die scatter_dimension um shard_count mal kleiner ist. Wenn es beispielsweise zwei Replikate gibt und der Operand den Wert [1.0, 2.25] bzw. [3.0, 5.25] für die beiden Replikate hat, ist der Ausgabewert dieses Vorgangs, bei dem scatter_dim 0 ist, [4.0] für das erste Replikat und [7.5] für das zweite Replikat.
ReduceWindow
Weitere Informationen finden Sie unter XlaBuilder::ReduceWindow.
Wendet eine Reduktionsfunktion auf alle Elemente in jedem Fenster einer Sequenz von N mehrdimensionalen Arrays an und gibt ein einzelnes oder ein Tupel von N mehrdimensionalen Arrays als Ausgabe zurück. Jedes Ausgabearray hat dieselbe Anzahl von Elementen wie die Anzahl der gültigen Positionen des Fensters. Eine Pooling-Ebene kann als ReduceWindow ausgedrückt werden. Ähnlich wie bei Reduce wird der angewendete computation immer an den init_values auf der linken Seite übergeben.
ReduceWindow(operands..., init_values..., computation, window_dimensions,
window_strides, padding)
| Argumente | Typ | Semantik |
|---|---|---|
operands |
N XlaOps |
Eine Sequenz von N mehrdimensionalen Arrays vom Typ T_0,..., T_{N-1}, die jeweils den Grundriss darstellen, auf dem das Fenster platziert wird. |
init_values |
N XlaOps |
Die N Ausgangswerte für die Reduktion, jeweils einer für jeden der N Operanden. Weitere Informationen finden Sie unter Reduzieren. |
computation |
XlaComputation |
Reduktionsfunktion vom Typ T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}), die auf die Elemente in jedem Fenster mit allen Eingabeoperanden angewendet wird. |
window_dimensions |
ArraySlice<int64> |
Array von Ganzzahlen für Werte der Dimensionskategorie „Window“ |
window_strides |
ArraySlice<int64> |
Ganzzahlen-Array für Werte für die Fensterschrittweite |
base_dilations |
ArraySlice<int64> |
Array mit Ganzzahlen für Basisvergrößerungswerte |
window_dilations |
ArraySlice<int64> |
Array mit Ganzzahlen für Werte der Fenstererweiterung |
padding |
Padding |
Art des Paddings für das Fenster (Padding::kSame, das den Ausgang so auffüllt, dass er dieselbe Form wie die Eingabe hat, wenn der Schritt 1 ist, oder Padding::kValid, das kein Padding verwendet und das Fenster „stoppt“, sobald es nicht mehr passt) |
Wobei:
- N muss größer oder gleich 1 sein.
- Alle Eingabearrays müssen dieselbe Größe haben.
- Wenn
N = 1,Collate(T)=T. - Wenn
N > 1,Collate(T_0, ..., T_{N-1})ein Tupel vonN-Elementen vom Typ(T0,...T{N-1})ist.
Der folgende Code und die folgende Abbildung zeigen ein Beispiel für die Verwendung von ReduceWindow. Die Eingabe ist eine Matrix der Größe [4 x 6] und sowohl „window_dimensions“ als auch „window_stride_dimensions“ haben die Größe [2 x 3].
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
Ein Schritt von 1 in einer Dimension gibt an, dass sich die Position eines Fensters in der Dimension um ein Element vom benachbarten Fenster entfernt befindet. Wenn Sie angeben möchten, dass sich keine Fenster überschneiden, müssen „window_stride_dimensions“ und „window_dimensions“ gleich sein. Die folgende Abbildung veranschaulicht die Verwendung von zwei verschiedenen Schrittwerten. Das Padding wird auf jede Dimension der Eingabe angewendet. Die Berechnungen erfolgen so, als hätte die Eingabe die Dimensionen, die sie nach dem Padding hat.
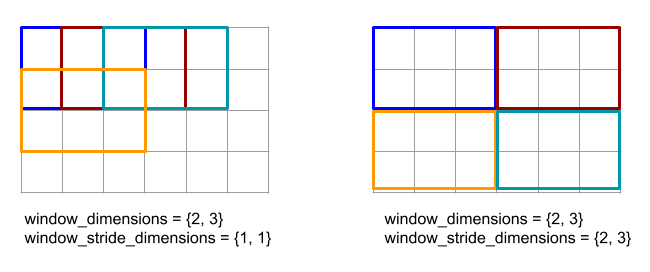
Bei einem nicht trivialen Beispiel für das Auffüllen könnten Sie das Minimum der Fensterreduzierung (Anfangswert ist MAX_FLOAT) mit der Dimension 3 berechnen und 2 über das Eingabearray [10000, 1000, 100, 10, 1] ziehen. Mit kValid werden Mindestwerte über zwei gültige Fenster berechnet: [10000, 1000, 100] und [100, 10, 1]. Das Ergebnis ist [100, 1]. Mit Padding kSame wird das Array zuerst so ergänzt, dass die Form nach dem Reduzierungsfenster derselben wie die Eingabe für Schritt 1 entspricht. Dazu werden an beiden Seiten Anfangselemente hinzugefügt, sodass [MAX_VALUE, 10000, 1000, 100, 10, 1,
MAX_VALUE] entsteht. Wenn Sie das Reduzieren des Fensters über das aufgefüllte Array ausführen, werden die drei Fenster [MAX_VALUE, 10000, 1000], [1000, 100, 10], [10, 1, MAX_VALUE] und Ertragsgruppen [1000, 10, 1] angewendet.
Die Auswertungsreihenfolge der Reduzierungsfunktion ist beliebig und kann nicht deterministisch sein. Daher sollte die Reduzierungsfunktion nicht zu empfindlich auf eine erneute Verknüpfung reagieren. Weitere Informationen finden Sie in der Diskussion zur Assoziativität im Kontext von Reduce.
ReplicaId
Weitere Informationen finden Sie unter XlaBuilder::ReplicaId.
Gibt die eindeutige ID (U32-Skalar) des Replikats zurück.
ReplicaId()
Die eindeutige ID jedes Replikats ist eine Ganzzahl ohne Vorzeichen im Intervall [0, N), wobei N die Anzahl der Replicas ist. Da auf allen Replicas dasselbe Programm ausgeführt wird, gibt ein ReplicaId()-Aufruf im Programm auf jedem Replikat einen anderen Wert zurück.
Neu gestalten
Weitere Informationen finden Sie unter XlaBuilder::Reshape und Collapse.
Die Dimensionen eines Arrays werden in eine neue Konfiguration umgewandelt.
Reshape(operand, new_sizes)
Reshape(operand, dimensions, new_sizes)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array vom Typ T |
dimensions |
int64 Vektor |
Reihenfolge, in der Dimensionen minimiert werden |
new_sizes |
int64 Vektor |
Vektor von Größen neuer Dimensionen |
Konzeptionell wird ein Array zuerst in einen eindimensionalen Vektor mit Datenwerten umgewandelt und dann in eine neue Form gebracht. Die Eingabeargumente sind ein beliebiges Array vom Typ T, ein Compilezeitkonstanter Vektor von Dimensionsindizes und ein Compilezeitkonstanter Vektor von Dimensionsgrößen für das Ergebnis.
Die Werte im dimension-Vektor, falls angegeben, müssen eine Permutation aller Dimensionen von T sein. Wenn sie nicht angegeben sind, ist der Standardwert {0, ..., rank - 1}. Die Reihenfolge der Dimensionen in dimensions geht vom Element mit der langsamsten (höchsten) Variation (most major) zum Element mit der schnellsten (niedrigsten) Variation (most minor) im Schleifennest, wodurch das Eingabearray in eine einzelne Dimension zusammengefasst wird. Der Vektor new_sizes bestimmt die Größe des Ausgabearrays. Der Wert bei Index 0 in new_sizes ist die Größe der Dimension 0, der Wert bei Index 1 ist die Größe der Dimension 1 usw. Das Produkt der new_size-Dimensionen muss dem Produkt der Dimensionsgrößen des Operanden entsprechen. Wenn Sie das minimierte Array in das von new_sizes definierte mehrdimensionale Array verfeinern, werden die Dimensionen in new_sizes von der langsamsten (wichtigsten) bis zur schnellsten (unwichtigsten) Variante sortiert.
Lassen Sie v z. B. ein Array mit 24 Elementen sein:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
In-order collapse:
let v012_24 = Reshape(v, {0,1,2}, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {0,1,2}, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
Out-of-order collapse:
let v021_24 = Reshape(v, {1,2,0}, {24});
then v012_24 == f32[24] {10, 20, 30, 40, 11, 21, 31, 41, 12, 22, 32, 42,
15, 25, 35, 45, 16, 26, 36, 46, 17, 27, 37, 47};
let v021_83 = Reshape(v, {1,2,0}, {8,3});
then v021_83 == f32[8x3] { {10, 20, 30}, {40, 11, 21},
{31, 41, 12}, {22, 32, 42},
{15, 25, 35}, {45, 16, 26},
{36, 46, 17}, {27, 37, 47} };
let v021_262 = Reshape(v, {1,2,0}, {2,6,2});
then v021_262 == f32[2x6x2] { { {10, 20}, {30, 40},
{11, 21}, {31, 41},
{12, 22}, {32, 42} },
{ {15, 25}, {35, 45},
{16, 26}, {36, 46},
{17, 27}, {37, 47} } };
Als Sonderfall kann reshape ein Array mit einem Element in ein Skalar und umgekehrt umwandeln. Beispiel:
Reshape(f32[1x1] { {5} }, {0,1}, {}) == 5;
Reshape(5, {}, {1,1}) == f32[1x1] { {5} };
Rev (Rückwärts)
Weitere Informationen finden Sie unter XlaBuilder::Rev.
Rev(operand, dimensions)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array vom Typ T |
dimensions |
ArraySlice<int64> |
Umzukehrende Dimensionen |
Die Reihenfolge der Elemente im operand-Array wird entlang des angegebenen dimensions umgekehrt. Dadurch wird ein Ausgabearray derselben Form generiert. Jedes Element des Operandenarrays an einem mehrdimensionalen Index wird im Ausgabearray an einem umgewandelten Index gespeichert. Der mehrdimensionale Index wird transformiert, indem der Index in jeder Dimension umgekehrt wird, die umgekehrt werden soll. Wenn eine Dimension der Größe N eine der Dimensionen ist, die umgekehrt werden sollen, wird ihr Index i in N − 1 − i umgewandelt.
Der Rev-Vorgang kann beispielsweise verwendet werden, um das Array mit den Convolutionsgewichten entlang der beiden Fensterdimensionen während der Gradientenberechnung in neuronalen Netzwerken umzukehren.
RngNormal
Weitere Informationen finden Sie unter XlaBuilder::RngNormal.
Erzeugt eine Ausgabe einer bestimmten Form mit Zufallszahlen, die gemäß der -Normalverteilung generiert werden. Die Parameter und sowie die Ausgabeform müssen einen Gleitkommaelementartyp haben. Außerdem müssen die Parameter skalare Werte haben.
RngNormal(mu, sigma, shape)
| Argumente | Typ | Semantik |
|---|---|---|
mu |
XlaOp |
Skalar vom Typ T, der den Mittelwert der generierten Zahlen angibt |
sigma |
XlaOp |
Skalar vom Typ T, der die Standardabweichung der generierten |
shape |
Shape |
Ausgabeform vom Typ T |
RngUniform
Weitere Informationen finden Sie unter XlaBuilder::RngUniform.
Erstellt eine Ausgabe einer bestimmten Form mit Zufallszahlen, die gemäß der gleichmäßigen Verteilung über das Intervall generiert werden. Die Parameter und der Ausgabeelementtyp müssen ein boolescher Typ, ein Ganzzahltyp oder ein Gleitkommatyp sein. Die Typen müssen übereinstimmen. CPU- und GPU-Back-Ends unterstützen derzeit nur F64, F32, F16, BF16, S64, U64, S32 und U32. Außerdem müssen die Parameter skalar sein. Wenn das Ergebnis implementierungsabhängig ist.
RngUniform(a, b, shape)
| Argumente | Typ | Semantik |
|---|---|---|
a |
XlaOp |
Skalar vom Typ T, der die Untergrenze des Intervalls angibt |
b |
XlaOp |
Skalar vom Typ T, der die Obergrenze des Intervalls angibt |
shape |
Shape |
Ausgabeform vom Typ T |
RngBitGenerator
Er generiert eine Ausgabe mit einer bestimmten Form, die mithilfe des angegebenen Algorithmus (oder des Backend-Standards) mit gleichmäßig verteilten Zufallsbits gefüllt ist, und gibt einen aktualisierten Zustand (mit derselben Form wie der Anfangszustand) und die generierten Zufallsdaten zurück.
Der Anfangszustand ist der Anfangszustand der aktuellen Generierung der Zufallszahl. Die erforderliche Form und die zulässigen Werte hängen vom verwendeten Algorithmus ab.
Die Ausgabe ist garantiert eine deterministische Funktion des Anfangszustands, aber sie ist nicht deterministisch zwischen Back-Ends und verschiedenen Compiler-Versionen.
RngBitGenerator(algorithm, key, shape)
| Argumente | Typ | Semantik |
|---|---|---|
algorithm |
RandomAlgorithm |
Zu verwendender PRNG-Algorithmus. |
initial_state |
XlaOp |
Anfangsstatus für den PRNG-Algorithmus. |
shape |
Shape |
Ausgabeformat für generierte Daten. |
Verfügbare Werte für algorithm:
rng_default: Back-End-spezifischer Algorithmus mit back-end-spezifischen Formanforderungen.rng_three_fry: Der PRNG-Algorithmus ThreeFry mit Zähler. Die Forminitial_stateistu64[2]mit beliebigen Werten. Salmon et al. SC 2011. Parallele Zufallszahlen: so einfach wie 1, 2, 3.rng_philox: Philox-Algorithmus zum parallelen Erzeugen von Zufallszahlen. Die Forminitial_stateistu64[3]mit beliebigen Werten. Salmon et al. SC 2011. Parallele Zufallszahlen: So einfach wie das Einmaleins.
Streudiagramm
Der XLA-Speichervorgang generiert eine Sequenz von Ergebnissen, die die Werte des Eingabearrays operands sind. Dabei werden mehrere Scheiben (an den durch scatter_indices angegebenen Indizes) mit der Sequenz von Werten in updates mithilfe von update_computation aktualisiert.
Weitere Informationen finden Sie unter XlaBuilder::Scatter.
scatter(operands..., scatter_indices, updates..., update_computation,
index_vector_dim, update_window_dims, inserted_window_dims,
scatter_dims_to_operand_dims)
| Argumente | Typ | Semantik |
|---|---|---|
operands |
Sequenz von N XlaOp |
N Arrays des Typs T_0, ..., T_N, in die verteilt werden soll. |
scatter_indices |
XlaOp |
Array mit den Startindizes der Segmente, in die die Daten verstreut werden müssen. |
updates |
Sequenz von N XlaOp |
N Arrays vom Typ T_0, ..., T_N. updates[i] enthält die Werte, die für die Streuung operands[i] verwendet werden müssen. |
update_computation |
XlaComputation |
Berechnung, die zum Kombinieren der vorhandenen Werte im Eingabearray und der Aktualisierungen während der Streuung verwendet wird. Diese Berechnung sollte vom Typ T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N) sein. |
index_vector_dim |
int64 |
Die Dimension in scatter_indices, die die Startindexe enthält. |
update_window_dims |
ArraySlice<int64> |
Die Menge der Abmessungen in der Form updates, die Fensterabmessungen sind. |
inserted_window_dims |
ArraySlice<int64> |
Die Fensterabmessungen, die in die updates-Form eingefügt werden müssen. |
scatter_dims_to_operand_dims |
ArraySlice<int64> |
Eine Dimensionszuordnung von den Streuungsindices zum Operandenindexbereich. Dieses Array wird als Zuordnung von i zu scatter_dims_to_operand_dims[i] interpretiert. Sie muss eins zu eins und vollständig sein. |
indices_are_sorted |
bool |
Gibt an, ob die Indexe garantiert vom Aufrufer sortiert werden. |
unique_indices |
bool |
Gibt an, ob die Indizes vom Aufrufer garantiert eindeutig sind. |
Wobei:
- N muss größer oder gleich 1 sein.
operands[0], …,operands[N-1] müssen alle dieselben Abmessungen haben.updates[0], …,updates[N-1] müssen alle dieselben Abmessungen haben.- Wenn
N = 1,Collate(T)=T. - Wenn
N > 1,Collate(T_0, ..., T_N)ein Tupel vonN-Elementen vom TypTist.
Wenn index_vector_dim mit scatter_indices.rank übereinstimmt, wird davon ausgegangen, dass scatter_indices eine nachgestellte 1-Dimension hat.
Wir definieren update_scatter_dims vom Typ ArraySlice<int64> als die Menge der Dimensionen in Form von updates, die nicht in update_window_dims enthalten sind, in aufsteigender Reihenfolge.
Die Streuargumente sollten den folgenden Einschränkungen folgen:
Jedes
updates-Array muss den Rangupdate_window_dims.size + scatter_indices.rank - 1haben.Die Grenzen der Dimension
iin jedemupdates-Array müssen den folgenden Anforderungen entsprechen:- Wenn
iinupdate_window_dimsvorhanden ist (d. h.update_window_dims[k] für eine bestimmtekentspricht), darf die Grenze der Dimensioniinupdatesdie entsprechende Grenze vonoperandnicht überschreiten, nachdem dieinserted_window_dimsberücksichtigt wurden (d. h.adjusted_window_bounds[k], wobeiadjusted_window_boundsdie Grenzen vonoperandohne die Grenzen an den Indizesinserted_window_dimsenthält). - Wenn
iinupdate_scatter_dimsvorhanden ist (d. h.i=update_scatter_dims[k] für eine bestimmtek), muss die Grenze der Dimensioniinupdatesder entsprechenden Grenze vonscatter_indicesentsprechen, wobeiindex_vector_dimübersprungen wird (d. h.scatter_indices.shape.dims[k], wennk<index_vector_dim, andernfallsscatter_indices.shape.dims[k+1]).
- Wenn
update_window_dimsmuss in aufsteigender Reihenfolge vorliegen, darf keine sich wiederholenden Dimensionsnummern enthalten und muss im Bereich[0, updates.rank)liegen.inserted_window_dimsmuss in aufsteigender Reihenfolge vorliegen, darf keine sich wiederholenden Dimensionsnummern enthalten und muss im Bereich[0, operand.rank)liegen.operand.rankmuss der Summe vonupdate_window_dims.sizeundinserted_window_dims.sizeentsprechen.scatter_dims_to_operand_dims.sizemussscatter_indices.shape.dims[index_vector_dim] entsprechen und die Werte müssen im Bereich[0, operand.rank)liegen.
Für einen bestimmten Index U in jedem updates-Array wird der entsprechende Index I im entsprechenden operands-Array, in das diese Aktualisierung angewendet werden muss, so berechnet:
- Angenommen,
G= {U[k] fürkinupdate_scatter_dims}. Verwenden SieG, um einen IndexvektorSim Arrayscatter_indicesso abzurufen, dassS[i] =scatter_indices[Combine(G,i)] ist, wobei Combine(A, b) b an den Positionenindex_vector_dimin A einfügt. - Erstellen Sie einen Index
SininoperandmitS, indem SieSmithilfe der Kartescatter_dims_to_operand_dimsstreuen. Formeller:Sin[scatter_dims_to_operand_dims[k]] =S[k], wennk<scatter_dims_to_operand_dims.size.Sin[_] =0andernfalls.
- Erstellen Sie einen Index
Winin jedemoperands-Array, indem Sie die Indizes inupdate_window_dimsinUgemäßinserted_window_dimsverteilen. Formeller:Win[window_dims_to_operand_dims(k)] =U[k], wennkinupdate_window_dimsliegt. Dabei istwindow_dims_to_operand_dimsdie monotone Funktion mit dem Definitionsbereich [0,update_window_dims.size) und dem Wertebereich [0,operand.rank) \inserted_window_dims. Wennupdate_window_dims.sizebeispielsweise4,operand.rank6undinserted_window_dims{0,2} ist, istwindow_dims_to_operand_dims{0→1,1→3,2→4,3→5}.Win[_] =0andernfalls.
IistWin+Sin, wobei „+“ die elementweise Addition ist.
Zusammenfassend lässt sich der Streuungsvorgang so definieren:
- Initialisieren Sie
outputmitoperands, d. h. für alle IndexeJund für alle IndexeOim Arrayoperands[J]:
output[J][O] =operands[J][O] - Für jeden Index
Uim Arrayupdates[J] und den entsprechenden IndexOim Arrayoperand[J], wennOein gültiger Index füroutputist:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
Die Reihenfolge, in der Aktualisierungen angewendet werden, ist nicht deterministisch. Wenn also mehrere Indexe in updates auf denselben Index in operands verweisen, ist der entsprechende Wert in output nicht deterministisch.
Der erste Parameter, der an update_computation übergeben wird, ist immer der aktuelle Wert aus dem output-Array und der zweite Parameter ist immer der Wert aus dem updates-Array. Das ist insbesondere in Fällen wichtig, in denen update_computation nicht kommutativ ist.
Wenn indices_are_sorted auf „wahr“ gesetzt ist, kann XLA davon ausgehen, dass scatter_indices vom Nutzer sortiert wurde (in aufsteigender Reihenfolge, nachdem die Werte gemäß scatter_dims_to_operand_dims verstreut wurden). Andernfalls werden die Semantiken von der Implementierung definiert.
Wenn unique_indices auf "true" gesetzt ist, kann XLA davon ausgehen, dass alle verstreuten Elemente eindeutig sind. So können für XLA nicht atomarer Vorgänge verwendet werden. Wenn unique_indices auf „wahr“ gesetzt ist und die Indizes, auf die verteilt wird, nicht eindeutig sind, wird die Semantik durch die Implementierung definiert.
Die Streuvorgänge können als Umkehr der Sammelvorgänge betrachtet werden. Das bedeutet, dass die Streuvorgänge die Elemente in der Eingabe aktualisieren, die durch die entsprechenden Sammelvorgänge extrahiert werden.
Eine ausführliche informelle Beschreibung und Beispiele finden Sie unter Gather im Abschnitt „Informale Beschreibung“.
Auswählen
Weitere Informationen finden Sie unter XlaBuilder::Select.
Erstellt ein Ausgabearray aus Elementen von zwei Eingabearrays basierend auf den Werten eines Prädikatsarrays.
Select(pred, on_true, on_false)
| Argumente | Typ | Semantik |
|---|---|---|
pred |
XlaOp |
Array vom Typ PRED |
on_true |
XlaOp |
Array vom Typ T |
on_false |
XlaOp |
Array vom Typ T |
Die Arrays on_true und on_false müssen dieselbe Form haben. Dies ist auch die Form des Ausgabearrays. Das Array pred muss dieselbe Dimension wie on_true und on_false haben und den Elementtyp PRED.
Für jedes Element P von pred wird das entsprechende Element des Ausgabe-Arrays aus on_true übernommen, wenn der Wert von P true ist, und aus on_false, wenn der Wert von P false ist. Als eingeschränkte Form der Broadcasting-Technologie kann pred ein Skalar vom Typ PRED sein. In diesem Fall wird das Ausgabearray vollständig aus on_true übernommen, wenn pred den Wert true hat, und aus on_false, wenn pred den Wert false hat.
Beispiel mit nicht skalarem pred:
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
Beispiel mit skalarem pred:
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
Die Auswahl zwischen Tupeln wird unterstützt. Tupel gelten zu diesem Zweck als Skalartypen. Wenn on_true und on_false Tupel sind (die dieselbe Form haben müssen), muss pred ein Skalar vom Typ PRED sein.
SelectAndScatter
Weitere Informationen finden Sie unter XlaBuilder::SelectAndScatter.
Dieser Vorgang kann als zusammengesetzter Vorgang betrachtet werden, der zuerst ReduceWindow für das operand-Array berechnet, um ein Element aus jedem Fenster auszuwählen, und dann das source-Array auf die Indexe der ausgewählten Elemente verteilt, um ein Ausgabearray mit derselben Form wie das Operand-Array zu erstellen. Mit der binären select-Funktion wird ein Element aus jedem Fenster ausgewählt, indem es auf jedes Fenster angewendet wird. Sie wird mit der Eigenschaft aufgerufen, dass der Indexvektor des ersten Parameters lexikografisch kleiner ist als der Indexvektor des zweiten Parameters. Die Funktion select gibt true zurück, wenn der erste Parameter ausgewählt ist, und false, wenn der zweite Parameter ausgewählt ist. Außerdem muss die Funktion transitiv sein, d. h., wenn select(a, b) und select(b, c) true sind, dann ist auch select(a, c) true. Das ausgewählte Element darf also nicht von der Reihenfolge der Elemente abhängen, die für ein bestimmtes Fenster durchlaufen werden.
Die Funktion scatter wird auf jeden ausgewählten Index im Ausgabearray angewendet. Es nimmt zwei Skalarparameter an:
- Aktueller Wert am ausgewählten Index im Ausgabearray
- Der Streuwert aus
source, der für den ausgewählten Index gilt
Er kombiniert die beiden Parameter und gibt einen Skalarwert zurück, mit dem der Wert am ausgewählten Index im Ausgabearray aktualisiert wird. Anfangs sind alle Indizes des Ausgabearrays auf init_value gesetzt.
Das Ausgabearray hat dieselbe Form wie das operand-Array und das source-Array muss dieselbe Form haben wie das Ergebnis der Anwendung einer ReduceWindow-Operation auf das operand-Array. Mit SelectAndScatter können die Gradientenwerte für eine Pooling-Ebene in einem neuronalen Netzwerk zurückgepropagiert werden.
SelectAndScatter(operand, select, window_dimensions, window_strides,
padding, source, init_value, scatter)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Array vom Typ T, über das die Fenster laufen |
select |
XlaComputation |
Binäre Berechnung vom Typ T, T -> PRED, die auf alle Elemente in jedem Fenster angewendet wird; gibt true zurück, wenn der erste Parameter ausgewählt ist, und false, wenn der zweite Parameter ausgewählt ist |
window_dimensions |
ArraySlice<int64> |
Array mit Ganzzahlen für Werte der Dimensionskategorie „Window“ |
window_strides |
ArraySlice<int64> |
Ganzzahlen-Array für Werte für die Fensterschrittweite |
padding |
Padding |
Abstandstyp für Fenster (Padding::kSame oder Padding::kValid) |
source |
XlaOp |
Array vom Typ T mit den zu verstreuenden Werten |
init_value |
XlaOp |
Skalarwert vom Typ T für den Anfangswert des Ausgabearrays |
scatter |
XlaComputation |
Binäre Berechnung vom Typ T, T -> T, um jedes Streuungselement der Quelle auf das Zielelement anzuwenden |
Die folgende Abbildung zeigt Beispiele für die Verwendung von SelectAndScatter. Dabei berechnet die Funktion select den maximalen Wert ihrer Parameter. Wenn sich die Fenster überlappen, wie in der Abbildung (2) unten gezeigt, kann ein Index des operand-Arrays mehrfach von verschiedenen Fenstern ausgewählt werden. In der Abbildung wird das Element mit dem Wert 9 von beiden oberen Fenstern (blau und rot) ausgewählt. Die binäre Additionsfunktion scatter erzeugt das Ausgabeelement mit dem Wert 8 (2 + 6).
Die Auswertungsreihenfolge der scatter-Funktion ist beliebig und kann nicht deterministisch sein. Daher sollte die scatter-Funktion nicht zu empfindlich auf eine erneute Verknüpfung reagieren. Weitere Informationen finden Sie in der Diskussion über Assoziativität im Kontext von Reduce.
Senden
Weitere Informationen finden Sie unter XlaBuilder::Send.
Send(operand, channel_handle)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Zu sendende Daten (Array vom Typ T) |
channel_handle |
ChannelHandle |
eindeutige Kennung für jedes Sende-/Empfangspaar |
Sendet die angegebenen Operandendaten an eine Recv-Anweisung in einer anderen Berechnung, die denselben Channel-Handle verwendet. Es werden keine Daten zurückgegeben.
Ähnlich wie beim Recv-Vorgang stellt die Client-API des Send-Vorgangs eine synchrone Kommunikation dar und wird intern in zwei HLO-Anweisungen (Send und SendDone) zerlegt, um asynchrone Datenübertragungen zu ermöglichen. Siehe auch HloInstruction::CreateSend und HloInstruction::CreateSendDone.
Send(HloInstruction operand, int64 channel_id)
Initiiert eine asynchrone Übertragung des Operanden an die Ressourcen, die durch die Recv-Anweisung mit derselben Kanal-ID zugewiesen wurden. Gibt einen Kontext zurück, der von einer nachfolgenden SendDone-Anweisung verwendet wird, um auf den Abschluss der Datenübertragung zu warten. Der Kontext ist ein Tupel von {Operand (Form), Anfrage-ID (U32)} und kann nur von einer SendDone-Anweisung verwendet werden.
SendDone(HloInstruction context)
Bei einem Kontext, der von einer Send-Anweisung erstellt wurde, wird auf den Abschluss der Datenübertragung gewartet. Durch die Anweisung werden keine Daten zurückgegeben.
Zeitplanung für Kanalanweisungen
Die Ausführungsreihenfolge der vier Anweisungen für jeden Kanal (Recv, RecvDone, Send, SendDone) ist unten dargestellt.
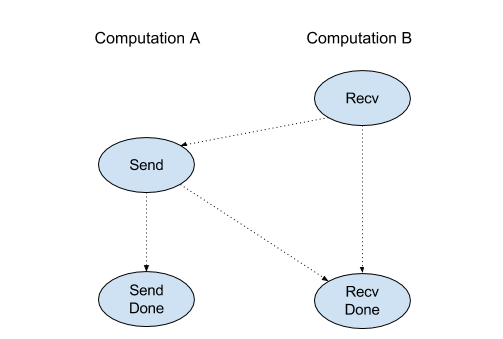
Recvgeschieht vorSendSendgeschieht vorRecvDoneRecvgeschieht vorRecvDoneSendgeschieht vorSendDone
Wenn die Back-End-Compiler einen linearen Zeitplan für jede Berechnung generieren, die über Kanalanweisungen kommuniziert, dürfen keine Zyklen zwischen den Berechnungen vorhanden sein. Die folgenden Zeitpläne führen beispielsweise zu Deadlocks.
Slice
Weitere Informationen finden Sie unter XlaBuilder::Slice.
Mit dem Slicing wird ein Teilarray aus dem Eingabearray extrahiert. Das Unterarray hat denselben Rang wie die Eingabe und enthält die Werte innerhalb eines Begrenzungsrahmens im Eingabearray. Die Abmessungen und Indizes des Begrenzungsrahmens werden als Argumente für den Slice-Vorgang angegeben.
Slice(operand, start_indices, limit_indices, strides)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
N-dimensionales Array des Typs T |
start_indices |
ArraySlice<int64> |
Liste mit N Ganzzahlen, die die Startindizes des Ausschnitts für jede Dimension enthalten. Die Werte müssen größer oder gleich null sein. |
limit_indices |
ArraySlice<int64> |
Liste mit N Ganzzahlen, die die Endindizes (exklusiv) für den Ausschnitt für jede Dimension enthalten. Jeder Wert muss größer oder gleich dem jeweiligen start_indices-Wert für die Dimension und kleiner oder gleich der Größe der Dimension sein. |
strides |
ArraySlice<int64> |
Liste mit N Ganzzahlen, die den Eingabe-Stride des Segments festlegt. Dabei wird jedes strides[d]-Element in der Dimension d ausgewählt. |
Eindimensionales Beispiel:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4}) produces:
{2.0, 3.0}
Zweidimensionales Beispiel:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
Sortieren
Weitere Informationen finden Sie unter XlaBuilder::Sort.
Sort(operands, comparator, dimension, is_stable)
| Argumente | Typ | Semantik |
|---|---|---|
operands |
ArraySlice<XlaOp> |
Die Operanden, die sortiert werden sollen. |
comparator |
XlaComputation |
Die zu verwendende Vergleichsberechnung. |
dimension |
int64 |
Die Dimension, nach der sortiert werden soll. |
is_stable |
bool |
Gibt an, ob eine stabile Sortierung verwendet werden soll. |
Wenn nur ein Operand angegeben ist:
Wenn der Operand ein Tensor mit Rang 1 (ein Array) ist, ist das Ergebnis ein sortiertes Array. Wenn Sie das Array in aufsteigender Reihenfolge sortieren möchten, sollte der Vergleichsoperator einen Vergleich durchführen, der kleiner als ist. Nach der Sortierung des Arrays gilt für alle Indexpositionen
i, jmiti < jentwedercomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseodercomparator(value[i], value[j]) = true.Wenn der Operand einen höheren Rang hat, wird er anhand der angegebenen Dimension sortiert. Bei einem Tensor mit Rang 2 (einer Matrix) werden beispielsweise mit dem Dimensionswert
0alle Spalten unabhängig voneinander sortiert und mit dem Dimensionswert1alle Zeilen unabhängig voneinander. Wenn keine Dimensionsnummer angegeben wird, wird standardmäßig die letzte Dimension ausgewählt. Für die sortierte Dimension gilt dieselbe Sortierreihenfolge wie für Rang-1.
Wenn n > 1-Operanden angegeben werden:
Alle
n-Operanden müssen Tensoren mit denselben Dimensionen sein. Die Elementtypen der Tensoren können unterschiedlich sein.Alle Operanden werden gemeinsam und nicht einzeln sortiert. Die Operanden werden konzeptionell als Tupel behandelt. Wenn geprüft werden soll, ob die Elemente der einzelnen Operanden an den Indexpositionen
iundjvertauscht werden müssen, wird der Vergleicher mit2 * nSkalarparametern aufgerufen. Dabei entspricht der Parameter2 * kdem Wert an Positionides Operandenk-thund der Parameter2 * k + 1dem Wert an Positionjdes Operandenk-th. Normalerweise vergleicht der Vergleichsoperator die Parameter2 * kund2 * k + 1miteinander und verwendet möglicherweise andere Parameterpaare als Tiebreaker.Das Ergebnis ist ein Tupel, das die Operanden in sortierter Reihenfolge (wie oben angegeben) enthält. Der
i-th-Operand des Tupels entspricht demi-th-Operanden von Sort.
Beispiel: Wenn es die drei Operanden operand0 = [3, 1], operand1 = [42, 50] und operand2 = [-3.0, 1.1] gibt und der Vergleicher nur die Werte von operand0 mit Kleiner-als-Werten vergleicht, ist die Ausgabe der Sortierung das Tupel ([1, 3], [50, 42], [1.1, -3.0]).
Wenn is_stable auf „wahr“ gesetzt ist, ist die Sortierung garantiert stabil. Das bedeutet, dass die relative Reihenfolge der gleichwertigen Werte beibehalten wird, wenn es Elemente gibt, die vom Vergleicher als gleich betrachtet werden. Zwei Elemente e1 und e2 sind genau dann gleich, wenn comparator(e1, e2) = comparator(e2, e1) = false. Standardmäßig ist is_stable auf „false“ festgelegt.
Transponieren
Weitere Informationen finden Sie unter tf.reshape.
Transpose(operand)
| Argumente | Typ | Semantik |
|---|---|---|
operand |
XlaOp |
Operand, der transponiert werden soll. |
permutation |
ArraySlice<int64> |
So ordnen Sie die Dimensionen neu an. |
Die Operandendimensionen werden mit der angegebenen Permutation permutiert, also ∀ i . 0 ≤ i < rank ⇒ input_dimensions[permutation[i]] = output_dimensions[i].
Dies entspricht der Funktion „Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions))“.
TriangularSolve
Weitere Informationen finden Sie unter XlaBuilder::TriangularSolve.
Löst lineare Gleichungssysteme mit unter- oder oberdiagonalen Koeffizientenmatrizen durch Vorwärts- oder Rückwärtssubstitution. Diese Routine überträgt eine führende Dimension und löst eines der Matrixsysteme op(a) * x =
b oder x * op(a) = b für die Variable x, wobei a und b angegeben werden, wobei op(a) entweder op(a) = a oder op(a) = Transpose(a) oder op(a) = Conj(Transpose(a)) ist.
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| Argumente | Typ | Semantik |
|---|---|---|
a |
XlaOp |
ein Array mit Rang > 2 eines komplexen oder Gleitkommatyps mit der Form [..., M, M]. |
b |
XlaOp |
ein Array mit Rang > 2 desselben Typs mit der Form [..., M, K], wenn left_side wahr ist, andernfalls [..., K, M]. |
left_side |
bool |
gibt an, ob ein System der Form op(a) * x = b (true) oder x * op(a) = b (false) gelöst werden soll. |
lower |
bool |
ob das obere oder untere Dreieck von a verwendet werden soll. |
unit_diagonal |
bool |
Wenn true, werden die Diagonalelemente von a als 1 angenommen und nicht darauf zugegriffen. |
transpose_a |
Transpose |
ob a unverändert verwendet, transponiert oder die konjugierte Transponierte verwendet werden soll. |
Die Eingabedaten werden je nach Wert von lower nur aus dem unteren oder oberen Dreieck von a gelesen. Werte aus dem anderen Dreieck werden ignoriert. Die Ausgabedaten werden im selben Dreieck zurückgegeben. Die Werte im anderen Dreieck sind implementierungsspezifisch und können beliebig sein.
Wenn der Rang von a und b größer als 2 ist, werden sie als Matrizenbatches behandelt, bei denen alle Dimensionen mit Ausnahme der zwei kleinsten Batchdimensionen Batchdimensionen sind. a und b müssen dieselben Batchdimensionen haben.
Tupel
Weitere Informationen finden Sie unter XlaBuilder::Tuple.
Ein Tupel mit einer variablen Anzahl von Daten-Handles, von denen jeder eine eigene Form hat.
Dies entspricht std::tuple in C++. Konzeptionell:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
Tupel können über den Vorgang GetTupleElement dekonstruiert (abgerufen) werden.
Während
Weitere Informationen finden Sie unter XlaBuilder::While.
While(condition, body, init)
| Argumente | Typ | Semantik |
|---|---|---|
condition |
XlaComputation |
XlaComputation vom Typ T -> PRED, die die Beendigungsbedingung der Schleife definiert. |
body |
XlaComputation |
XlaComputation vom Typ T -> T, die den Loop-Body definiert. |
init |
T |
Startwert für den Parameter von condition und body. |
Führt die body nacheinander aus, bis die condition fehlschlägt. Sie ähnelt einer typischen While-Schleife in vielen anderen Sprachen, mit Ausnahme der unten aufgeführten Unterschiede und Einschränkungen.
- Ein
While-Knoten gibt einen Wert vom TypTzurück. Dies ist das Ergebnis der letzten Ausführung vonbody. - Die Form des Typs
Twird statisch bestimmt und muss in allen Iterationen gleich sein.
Die T-Parameter der Berechnungen werden in der ersten Iteration mit dem Wert init initialisiert und in jeder nachfolgenden Iteration automatisch auf das neue Ergebnis von body aktualisiert.
Einer der Hauptanwendungsfälle des While-Knotens besteht darin, die wiederholte Ausführung von Trainings in neuronalen Netzwerken zu implementieren. Unten sehen Sie einen vereinfachten Pseudocode mit einem Diagramm, das die Berechnung darstellt. Den Code finden Sie unter while_test.cc.
Der Typ T in diesem Beispiel ist ein Tuple, der aus einem int32 für die Anzahl der Iterationen und einem vector[10] für den Akkumulator besteht. In 1.000 Iterationen wird dem Akkumulator in der Schleife immer wieder ein konstanter Vektor hinzugefügt.
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}