
| |  عرض المصدر على جيثب عرض المصدر على جيثب |
يقدم هذا الدليل Swift for TensorFlow من خلال بناء نموذج للتعلم الآلي يصنف زهور القزحية حسب الأنواع. ويستخدم Swift لـ TensorFlow من أجل:
- بناء نموذج،
- تدريب هذا النموذج على بيانات المثال، و
- استخدم النموذج لعمل تنبؤات حول البيانات غير المعروفة.
برمجة TensorFlow
يستخدم هذا الدليل مفاهيم Swift for TensorFlow عالية المستوى:
- استيراد البيانات باستخدام Epochs API.
- بناء النماذج باستخدام تجريدات Swift.
- استخدم مكتبات Python باستخدام إمكانية التشغيل التفاعلي لـ Swift's Python عندما لا تتوفر مكتبات Swift خالصة.
تم تصميم هذا البرنامج التعليمي مثل العديد من برامج TensorFlow:
- استيراد وتحليل مجموعات البيانات.
- حدد نوع النموذج.
- تدريب النموذج.
- تقييم فعالية النموذج.
- استخدم النموذج المدرب لعمل تنبؤات.
برنامج الإعداد
تكوين الواردات
قم باستيراد TensorFlow وبعض وحدات Python المفيدة.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
مشكلة تصنيف القزحية
تخيل أنك عالم نبات تبحث عن طريقة آلية لتصنيف كل زهرة قزحية تجدها. يوفر التعلم الآلي العديد من الخوارزميات لتصنيف الزهور إحصائيًا. على سبيل المثال، يمكن لبرنامج متطور للتعلم الآلي تصنيف الزهور بناءً على الصور الفوتوغرافية. طموحاتنا أكثر تواضعًا - سنقوم بتصنيف زهور السوسن بناءً على قياسات طول وعرض كأسياتها وبتلاتها .
يضم جنس القزحية حوالي 300 نوع، لكن برنامجنا سيصنف فقط الأنواع الثلاثة التالية:
- ايريس سيتوسا
- القزحية فيرجينيكا
- القزحية المبرقشة
 |
| الشكل 1. إيريس سيتوسا (بواسطة رادوميل ، CC BY-SA 3.0)، إيريس المبرقشة ، (بواسطة Dlanglois ، CC BY-SA 3.0)، وإيريس فيرجينيكا (بواسطة فرانك مايفيلد ، CC BY-SA 2.0). |
لحسن الحظ، قام شخص ما بالفعل بإنشاء مجموعة بيانات مكونة من 120 زهرة قزحية مع قياسات الكأسية والبتلات. هذه مجموعة بيانات كلاسيكية شائعة لمشاكل تصنيف التعلم الآلي للمبتدئين.
استيراد وتحليل مجموعة بيانات التدريب
قم بتنزيل ملف مجموعة البيانات وقم بتحويله إلى بنية يمكن استخدامها بواسطة برنامج Swift هذا.
قم بتنزيل مجموعة البيانات
قم بتنزيل ملف مجموعة بيانات التدريب من http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
فحص البيانات
مجموعة البيانات هذه، iris_training.csv ، عبارة عن ملف نصي عادي يقوم بتخزين البيانات الجدولية المنسقة كقيم مفصولة بفواصل (CSV). دعونا نلقي نظرة على أول 5 إدخالات.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
من خلال طريقة العرض هذه لمجموعة البيانات، لاحظ ما يلي:
- السطر الأول عبارة عن رأس يحتوي على معلومات حول مجموعة البيانات:
- هناك 120 أمثلة إجمالية. يحتوي كل مثال على أربع ميزات وواحد من أسماء التصنيفات الثلاثة المحتملة.
- الصفوف اللاحقة هي سجلات البيانات، مثال واحد لكل سطر، حيث:
دعنا نكتب ذلك بالكود:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
يرتبط كل تصنيف باسم سلسلة (على سبيل المثال، "setosa")، ولكن التعلم الآلي يعتمد عادةً على القيم الرقمية. يتم تعيين أرقام التسمية إلى تمثيل مسمى، مثل:
-
0: إيريس سيتوسا -
1: القزحية الملونة -
2: إيريس فيرجينيكا
لمزيد من المعلومات حول الميزات والتسميات، راجع قسم مصطلحات ML في الدورة التدريبية المكثفة للتعلم الآلي .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
قم بإنشاء مجموعة بيانات باستخدام Epochs API
تعد Swift for TensorFlow's Epochs API واجهة برمجة تطبيقات عالية المستوى لقراءة البيانات وتحويلها إلى نموذج يستخدم للتدريب.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
نظرًا لأن مجموعات البيانات التي قمنا بتنزيلها بتنسيق CSV، فلنكتب دالة لتحميلها في البيانات كقائمة بكائنات IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
يمكننا الآن استخدام وظيفة تحميل CSV لتحميل مجموعة بيانات التدريب وإنشاء كائن TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
كائن TrainingEpochs عبارة عن تسلسل لا نهائي من العصور. يحتوي كل عصر على IrisBatch es. دعونا ننظر إلى العنصر الأول من العصر الأول.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
لاحظ أن ميزات أمثلة batchSize الأولى تم تجميعها معًا (أو مجمعة ) في firstTrainFeatures ، وأن التسميات الخاصة بأمثلة batchSize الأولى مجمعة في firstTrainLabels .
يمكنك البدء في رؤية بعض المجموعات عن طريق رسم بعض الميزات من المجموعة، باستخدام matplotlib الخاص ببايثون:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
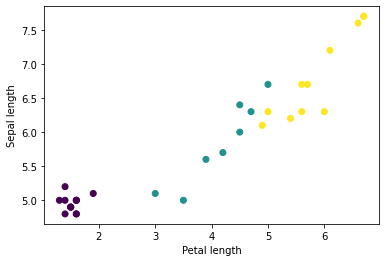
Use `print()` to show values.
حدد نوع النموذج
لماذا النموذج؟
النموذج هو العلاقة بين الميزات والتسمية. بالنسبة لمشكلة تصنيف القزحية، يحدد النموذج العلاقة بين قياسات الكأسية والبتلات وأنواع القزحية المتوقعة. يمكن وصف بعض النماذج البسيطة ببضعة أسطر من الجبر، لكن نماذج التعلم الآلي المعقدة تحتوي على عدد كبير من المعلمات التي يصعب تلخيصها.
هل يمكنك تحديد العلاقة بين السمات الأربعة وأنواع القزحية دون استخدام التعلم الآلي؟ بمعنى، هل يمكنك استخدام تقنيات البرمجة التقليدية (على سبيل المثال، الكثير من العبارات الشرطية) لإنشاء نموذج؟ ربما، إذا قمت بتحليل مجموعة البيانات لفترة كافية لتحديد العلاقات بين قياسات البتلة والكأس لنوع معين. ويصبح هذا صعبًا، وربما مستحيلًا، في مجموعات البيانات الأكثر تعقيدًا. إن النهج الجيد للتعلم الآلي هو الذي يحدد النموذج المناسب لك . إذا قمت بإدخال ما يكفي من الأمثلة التمثيلية في نوع نموذج التعلم الآلي المناسب، فسيكتشف البرنامج العلاقات نيابةً عنك.
حدد النموذج
نحن بحاجة إلى تحديد نوع النموذج للتدريب. هناك العديد من أنواع النماذج واختيار النموذج الجيد يتطلب الخبرة. يستخدم هذا البرنامج التعليمي شبكة عصبية لحل مشكلة تصنيف القزحية. يمكن للشبكات العصبية إيجاد علاقات معقدة بين الميزات والتسمية. إنه رسم بياني عالي التنظيم، منظم في طبقة مخفية واحدة أو أكثر. وتتكون كل طبقة مخفية من خلية عصبية واحدة أو أكثر. هناك عدة فئات من الشبكات العصبية ويستخدم هذا البرنامج شبكة عصبية كثيفة أو متصلة بالكامل : تتلقى الخلايا العصبية في طبقة واحدة اتصالات الإدخال من كل خلية عصبية في الطبقة السابقة. على سبيل المثال، يوضح الشكل 2 شبكة عصبية كثيفة تتكون من طبقة إدخال، وطبقتين مخفيتين، وطبقة إخراج:
 |
| الشكل 2. شبكة عصبية ذات ميزات وطبقات مخفية وتنبؤات. |
عندما يتم تدريب النموذج من الشكل 2 وتغذيته بمثال غير مسمى، فإنه ينتج ثلاثة تنبؤات: احتمال أن تكون هذه الزهرة هي نوع القزحية المحدد. ويسمى هذا التنبؤ الاستدلال . في هذا المثال، مجموع توقعات المخرجات هو 1.0. في الشكل 2، ينقسم هذا التنبؤ إلى: 0.02 لـ Iris setosa و 0.95 لـ Iris versicolor و 0.03 لـ Iris virginica . وهذا يعني أن النموذج يتنبأ - باحتمال 95% - أن مثال الزهرة غير المسماة هو زهرة قزحية ملونة .
أنشئ نموذجًا باستخدام مكتبة التعلم العميق Swift for TensorFlow
تحدد مكتبة التعلم العميق Swift for TensorFlow الطبقات والاصطلاحات البدائية لتوصيلها معًا، مما يجعل من السهل بناء النماذج والتجربة.
النموذج عبارة عن struct تتوافق مع Layer ، مما يعني أنه يحدد طريقة callAsFunction(_:) التي تقوم بتعيين Tensor s لإخراج Tensor s. غالبًا ما تقوم طريقة callAsFunction(_:) بتسلسل الإدخال من خلال الطبقات الفرعية. دعونا نحدد IrisModel الذي يقوم بتسلسل الإدخال من خلال ثلاث طبقات فرعية Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
تحدد وظيفة التنشيط شكل الإخراج لكل عقدة في الطبقة. تعتبر هذه اللاخطية مهمة، فبدونها سيكون النموذج معادلاً لطبقة واحدة. هناك العديد من عمليات التنشيط المتاحة، لكن ReLU شائع للطبقات المخفية.
يعتمد العدد المثالي للطبقات والخلايا العصبية المخفية على المشكلة ومجموعة البيانات. مثل العديد من جوانب التعلم الآلي، يتطلب اختيار الشكل الأفضل للشبكة العصبية مزيجًا من المعرفة والتجربة. وكقاعدة عامة، فإن زيادة عدد الطبقات المخفية والخلايا العصبية عادة ما يؤدي إلى إنشاء نموذج أكثر قوة، الأمر الذي يتطلب المزيد من البيانات للتدريب بشكل فعال.
باستخدام النموذج
دعونا نلقي نظرة سريعة على ما يفعله هذا النموذج بمجموعة من الميزات:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
هنا، يقوم كل مثال بإرجاع سجل لكل فئة.
لتحويل هذه السجلات إلى احتمالية لكل فئة، استخدم الدالة softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
إن أخذ argmax عبر الفئات يعطينا فهرس الفئة المتوقع. لكن النموذج لم يتم تدريبه بعد، لذا فهذه ليست تنبؤات جيدة.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
تدريب النموذج
التدريب هو مرحلة التعلم الآلي التي يتم فيها تحسين النموذج تدريجيًا، أو يتعلم النموذج مجموعة البيانات. الهدف هو معرفة ما يكفي عن بنية مجموعة بيانات التدريب للتنبؤ بالبيانات غير المرئية. إذا تعلمت الكثير عن مجموعة بيانات التدريب، فإن التنبؤات تعمل فقط مع البيانات التي شاهدتها ولن تكون قابلة للتعميم. تسمى هذه المشكلة بالتركيب الزائد ، وهي تشبه حفظ الإجابات بدلًا من فهم كيفية حل المشكلة.
تعد مشكلة تصنيف القزحية مثالاً على التعلم الآلي الخاضع للإشراف : يتم تدريب النموذج من الأمثلة التي تحتوي على تسميات. في التعلم الآلي غير الخاضع للرقابة ، لا تحتوي الأمثلة على تسميات. وبدلاً من ذلك، عادةً ما يجد النموذج أنماطًا بين الميزات.
اختر وظيفة الخسارة
تحتاج كل من مرحلتي التدريب والتقييم إلى حساب خسارة النموذج. يقيس هذا مدى اختلاف تنبؤات النموذج عن التسمية المطلوبة، وبعبارة أخرى، مدى سوء أداء النموذج. نريد تقليل هذه القيمة أو تحسينها.
سيحسب نموذجنا خسارته باستخدام وظيفة softmaxCrossEntropy(logits:labels:) التي تأخذ تنبؤات احتمالية فئة النموذج والتسمية المطلوبة، وترجع متوسط الخسارة عبر الأمثلة.
لنحسب خسارة النموذج الحالي غير المدرب:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
إنشاء محسن
يطبق المحسن التدرجات المحسوبة على متغيرات النموذج لتقليل دالة loss . يمكنك التفكير في دالة الخسارة كسطح منحني (انظر الشكل 3) ونريد العثور على أدنى نقطة لها من خلال التجول. تشير التدرجات إلى اتجاه الصعود الأكثر انحدارًا، لذلك سنسافر في الاتجاه المعاكس ونتحرك إلى أسفل التل. من خلال حساب الخسارة والتدرج بشكل متكرر لكل دفعة، سنقوم بتعديل النموذج أثناء التدريب. تدريجيًا، سيجد النموذج أفضل مزيج من الأوزان والتحيز لتقليل الخسارة. وكلما انخفضت الخسارة، كانت توقعات النموذج أفضل.
 |
| الشكل 3. تصور خوارزميات التحسين مع مرور الوقت في الفضاء ثلاثي الأبعاد. (المصدر: فئة ستانفورد CS231n ، رخصة معهد ماساتشوستس للتكنولوجيا، حقوق الصورة: أليك رادفورد ) |
يحتوي Swift for TensorFlow على العديد من خوارزميات التحسين المتاحة للتدريب. يستخدم هذا النموذج مُحسِّن SGD الذي ينفذ خوارزمية نزول التدرج العشوائي (SGD). يحدد learningRate حجم الخطوة التي يجب اتخاذها لكل تكرار أسفل التل. هذه هي المعلمة الفائقة التي يمكنك ضبطها عادةً لتحقيق نتائج أفضل.
let optimizer = SGD(for: model, learningRate: 0.01)
دعونا نستخدم optimizer لاتخاذ خطوة نزول متدرجة واحدة. أولاً، نحسب تدرج الخسارة بالنسبة للنموذج:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
بعد ذلك، نقوم بتمرير التدرج الذي قمنا بحسابه للتو إلى المُحسِّن، والذي يقوم بتحديث متغيرات النموذج القابلة للتمييز وفقًا لذلك:
optimizer.update(&model, along: grads)
إذا قمنا بحساب الخسارة مرة أخرى، فيجب أن تكون أصغر، لأن خطوات الهبوط المتدرجة (عادةً) تقلل الخسارة:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
حلقة التدريب
مع وضع جميع القطع في مكانها الصحيح، يصبح النموذج جاهزًا للتدريب! تعمل حلقة التدريب على تغذية أمثلة مجموعة البيانات في النموذج لمساعدته على تقديم تنبؤات أفضل. تقوم كتلة التعليمات البرمجية التالية بإعداد خطوات التدريب هذه:
- كرر على كل عصر . العصر هو مرور واحد عبر مجموعة البيانات.
- خلال فترة ما، قم بالتكرار على كل دفعة في فترة التدريب
- اجمع الدفعة واحصل على ميزاتها (
x) وقم بتسميتها (y). - باستخدام ميزات الدفعة المجمعة، قم بإجراء تنبؤ ومقارنته بالملصق. قم بقياس عدم دقة التنبؤ واستخدم ذلك لحساب خسارة النموذج وتدرجاته.
- استخدم النسب المتدرج لتحديث متغيرات النموذج.
- تتبع بعض الإحصائيات للتصور.
- كرر لكل عصر.
المتغير epochCount هو عدد مرات تكرار مجموعة البيانات. وعلى عكس ما هو بديهي، فإن تدريب النموذج لفترة أطول لا يضمن نموذجًا أفضل. epochCount عبارة عن معلمة تشعبية يمكنك ضبطها. عادةً ما يتطلب اختيار الرقم الصحيح الخبرة والتجريب.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
تصور وظيفة الخسارة مع مرور الوقت
على الرغم من أنه من المفيد طباعة التقدم في تدريب النموذج، إلا أنه غالبًا ما يكون من المفيد رؤية هذا التقدم. يمكننا إنشاء مخططات أساسية باستخدام وحدة matplotlib الخاصة ببايثون.
يتطلب تفسير هذه المخططات بعض الخبرة، ولكنك تريد حقًا أن ترى انخفاض الخسارة وزيادة الدقة .
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
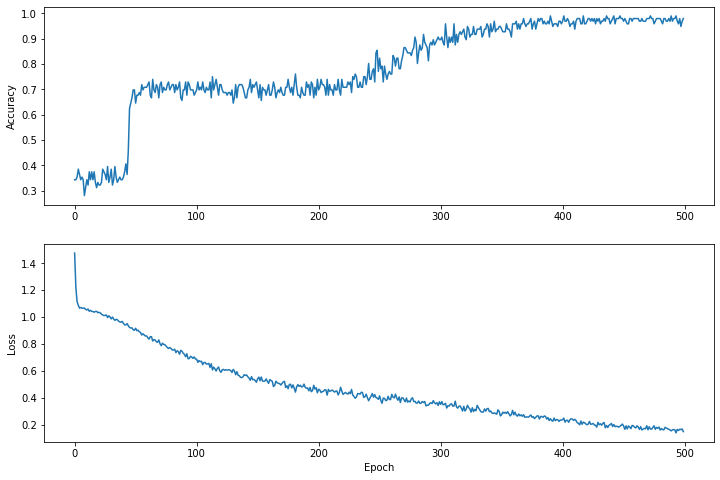
Use `print()` to show values.
لاحظ أن المحاور الصادية للرسوم البيانية لا تعتمد على الصفر.
تقييم فعالية النموذج
الآن بعد أن تم تدريب النموذج، يمكننا الحصول على بعض الإحصائيات حول أدائه.
التقييم يعني تحديد مدى فعالية النموذج في التنبؤ. لتحديد فعالية النموذج في تصنيف القزحية، قم بتمرير بعض قياسات الكأسية والبتلات إلى النموذج واطلب من النموذج التنبؤ بأنواع القزحية التي تمثلها. ثم قارن تنبؤات النموذج بالتسمية الفعلية. على سبيل المثال، النموذج الذي اختار النوع الصحيح على نصف الأمثلة المدخلة له دقة تبلغ 0.5 . يوضح الشكل 4 نموذجًا أكثر فعالية قليلًا، حيث حصل على 4 من أصل 5 تنبؤات صحيحة بدقة 80%:
| ميزات المثال | ملصق | التنبؤ النموذجي | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| الشكل 4. مصنف القزحية دقيق بنسبة 80%. | |||||
قم بإعداد مجموعة بيانات الاختبار
تقييم النموذج يشبه تدريب النموذج. الفرق الأكبر هو أن الأمثلة تأتي من مجموعة اختبار منفصلة بدلاً من مجموعة التدريب. لتقييم فعالية النموذج بشكل عادل، يجب أن تكون الأمثلة المستخدمة لتقييم النموذج مختلفة عن الأمثلة المستخدمة لتدريب النموذج.
يشبه إعداد مجموعة بيانات الاختبار إعداد مجموعة بيانات التدريب. قم بتنزيل مجموعة الاختبار من http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
الآن قم بتحميله إلى مجموعة من IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
تقييم النموذج في مجموعة بيانات الاختبار
على عكس مرحلة التدريب، يقوم النموذج بتقييم فترة واحدة فقط من بيانات الاختبار. في خلية التعليمات البرمجية التالية، نكرر كل مثال في مجموعة الاختبار ونقارن تنبؤات النموذج بالتسمية الفعلية. يُستخدم هذا لقياس دقة النموذج عبر مجموعة الاختبار بأكملها.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
يمكننا أن نرى في الدفعة الأولى، على سبيل المثال، أن النموذج عادةً ما يكون صحيحًا:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
استخدم النموذج المدرب لعمل تنبؤات
لقد قمنا بتدريب نموذج وأثبتنا أنه جيد - ولكنه ليس مثاليًا - في تصنيف أنواع القزحية. الآن دعونا نستخدم النموذج المدرّب لإجراء بعض التنبؤات على الأمثلة غير المسماة ؛ أي على الأمثلة التي تحتوي على ميزات وليس تسمية.
في الحياة الواقعية، يمكن أن تأتي الأمثلة غير المسماة من العديد من المصادر المختلفة بما في ذلك التطبيقات وملفات CSV وموجزات البيانات. في الوقت الحالي، سنقدم يدويًا ثلاثة أمثلة غير مسماة للتنبؤ بتسمياتها. تذكر أنه يتم تعيين أرقام التصنيفات لتمثيل مسمى على النحو التالي:
-
0: إيريس سيتوسا -
1: القزحية الملونة -
2: ايريس فيرجينيكا
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])