
| |  צפה במקור ב-GitHub צפה במקור ב-GitHub |
מדריך זה מציג את Swift עבור TensorFlow על ידי בניית מודל למידת מכונה שמסווג את פרחי הקשתית לפי מינים. הוא משתמש ב- Swift עבור TensorFlow כדי:
- בנה מודל,
- אמן את המודל הזה על נתונים לדוגמה, ו
- השתמש במודל כדי ליצור תחזיות לגבי נתונים לא ידועים.
תכנות TensorFlow
מדריך זה משתמש במושגי Swift עבור TensorFlow ברמה גבוהה אלה:
- ייבא נתונים עם ה-API של Epochs.
- בנה מודלים באמצעות הפשטות של Swift.
- השתמש בספריות Python באמצעות יכולת פעולה הדדית Python של Swift כאשר ספריות Swift טהורות אינן זמינות.
מדריך זה בנוי כמו תוכניות TensorFlow רבות:
- ייבא ונתח את מערכי הנתונים.
- בחר את סוג הדגם.
- לאמן את הדגם.
- הערך את יעילות המודל.
- השתמש במודל המאומן כדי ליצור תחזיות.
תוכנית התקנה
הגדר יבוא
ייבא את TensorFlow וכמה מודולים שימושיים של Python.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
בעיית סיווג הקשתית
תאר לעצמך שאתה בוטנאי שמחפש דרך אוטומטית לסווג כל פרח איריס שתמצא. למידת מכונה מספקת אלגוריתמים רבים לסיווג פרחים סטטיסטית. לדוגמה, תוכנית למידת מכונה מתוחכמת יכולה לסווג פרחים על סמך תמונות. השאיפות שלנו צנועות יותר - אנחנו הולכים לסווג את פרחי האירוס בהתבסס על מידות האורך והרוחב של עלי הכותרת ועלי הכותרת שלהם.
הסוג איריס כולל כ-300 מינים, אך התוכנית שלנו תסווג רק את השלושה הבאים:
- איריס סטוסה
- איריס וירג'יניקה
- איריס ורסיקולור
 |
| איור 1. Iris setosa (מאת Radomil , CC BY-SA 3.0), Iris versicolor , (מאת Dlanglois , CC BY-SA 3.0), ואיריס וירג'יניקה (מאת Frank Mayfield , CC BY-SA 2.0). |
למרבה המזל, מישהו כבר יצר מערך נתונים של 120 פרחי איריס עם מידות הגבי ועלי הכותרת. זהו מערך נתונים קלאסי פופולרי עבור בעיות סיווג למידת מכונה למתחילים.
ייבא ונתח את מערך ההדרכה
הורד את קובץ הנתונים והמר אותו למבנה שניתן להשתמש בו על ידי תוכנית Swift זו.
הורד את מערך הנתונים
הורד את קובץ מערך ההדרכה מאתר http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
בדוק את הנתונים
מערך נתונים זה, iris_training.csv , הוא קובץ טקסט רגיל המאחסן נתונים טבלאיים המעוצבים כערכים מופרדים בפסיקים (CSV). בואו נסתכל על 5 הערכים הראשונים.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
מתצוגה זו של מערך הנתונים, שימו לב לדברים הבאים:
- השורה הראשונה היא כותרת המכילה מידע על מערך הנתונים:
- ישנן 120 דוגמאות בסך הכל. לכל דוגמה יש ארבע תכונות ואחד משלושה שמות אפשריים של תוויות.
- שורות עוקבות הן רשומות נתונים, דוגמה אחת בכל שורה, כאשר:
בוא נכתוב את זה בקוד:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
כל תווית משויכת לשם המחרוזת (לדוגמה, "setosa"), אך למידת מכונה מסתמכת בדרך כלל על ערכים מספריים. מספרי התוויות ממופים לייצוג בעל שם, כגון:
-
0: איריס סטוסה -
1: איריס ורסיקולור -
2: איריס וירג'יניקה
למידע נוסף על תכונות ותוויות, עיין בסעיף ML Terminology של קורס התרסקות למידת מכונה .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
צור מערך נתונים באמצעות ה-API של Epochs
ה-API של Epochs של Swift for TensorFlow הוא API ברמה גבוהה לקריאת נתונים והפיכתם לטופס המשמש לאימון.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
מכיוון שמערכי הנתונים שהורדנו הם בפורמט CSV, בואו נכתוב פונקציה לטעינה בנתונים כרשימה של אובייקטי IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
כעת נוכל להשתמש בפונקציית טעינת ה-CSV כדי לטעון את מערך ההדרכה וליצור אובייקט TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
האובייקט TrainingEpochs הוא רצף אינסופי של תקופות. כל תקופה מכילה IrisBatch es. בואו נסתכל על האלמנט הראשון של התקופה הראשונה.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
שים לב שהתכונות עבור דוגמאות batchSize הראשונות מקובצות יחד (או באצווה ) לתוך firstTrainFeatures , וכי התוויות עבור דוגמאות batchSize הראשונות מקובצות ב- firstTrainLabels .
אתה יכול להתחיל לראות כמה אשכולות על ידי שרטוט של כמה תכונות מהאצווה, באמצעות matplotlib של Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
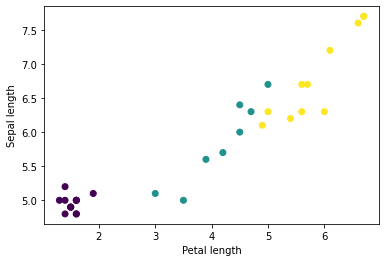
Use `print()` to show values.
בחר את סוג הדגם
למה לדגמן?
מודל הוא קשר בין תכונות לתווית. עבור בעיית סיווג הקשתית, המודל מגדיר את הקשר בין מדידת הגביע והעלים לבין מיני הקשתית החזויים. ניתן לתאר כמה מודלים פשוטים עם כמה שורות של אלגברה, אבל למודלים מורכבים של למידת מכונה יש מספר רב של פרמטרים שקשה לסכם.
האם תוכל לקבוע את הקשר בין ארבע התכונות לבין מיני הקשתית מבלי להשתמש בלמידת מכונה? כלומר, האם תוכל להשתמש בטכניקות תכנות מסורתיות (לדוגמה, הרבה הצהרות מותנות) כדי ליצור מודל? אולי - אם ניתחת את מערך הנתונים מספיק זמן כדי לקבוע את היחסים בין מדידות עלי כותרת וגביע למין מסוים. וזה הופך להיות קשה - אולי בלתי אפשרי - על מערכי נתונים מסובכים יותר. גישת למידת מכונה טובה קובעת את המודל עבורך . אם תזין מספיק דוגמאות מייצגות לסוג המודל הנכון של למידת מכונה, התוכנית תבין את הקשרים עבורך.
בחר את הדגם
אנחנו צריכים לבחור את סוג הדגם לאימון. ישנם סוגים רבים של דגמים ולבחירת אחד טוב דורש ניסיון. מדריך זה משתמש ברשת עצבית כדי לפתור את בעיית סיווג הקשתית. רשתות עצביות יכולות למצוא קשרים מורכבים בין תכונות לבין התווית. זהו גרף בעל מבנה גבוה, המאורגן בשכבה נסתרת אחת או יותר. כל שכבה נסתרת מורכבת מנוירון אחד או יותר. ישנן מספר קטגוריות של רשתות עצביות ותוכנית זו משתמשת ברשת עצבית צפופה או מחוברת לחלוטין : הנוירונים בשכבה אחת מקבלים חיבורי קלט מכל נוירון בשכבה הקודמת. לדוגמה, איור 2 ממחיש רשת עצבית צפופה המורכבת משכבת קלט, שתי שכבות נסתרות ושכבת פלט:
 |
| איור 2. רשת עצבית עם תכונות, שכבות נסתרות ותחזיות. |
כאשר המודל מאיור 2 מאומן ומוזן בדוגמה ללא תווית, הוא מניב שלוש תחזיות: הסבירות שהפרח הזה הוא זן האירוס הנתון. חיזוי זה נקרא מסקנות . עבור דוגמה זו, סכום תחזיות הפלט הוא 1.0. באיור 2, חיזוי זה מתחלק ל: 0.02 עבור Iris setosa , 0.95 עבור Iris versicolor ו 0.03 עבור Iris virginica . המשמעות היא שהמודל חוזה - בהסתברות של 95% - שפרח דוגמה ללא תווית הוא איריס ורסיקולור .
צור מודל באמצעות Swift for TensorFlow Deep Learning Library
ספריית הלמידה העמוקה של Swift for TensorFlow מגדירה שכבות ומוסכמות פרימיטיביות לחיווט ביניהן, מה שמקל על בניית מודלים וניסויים.
מודל הוא struct התואם ל- Layer , מה שאומר שהוא מגדיר שיטה callAsFunction(_:) שממפה קלט Tensor s לפלט Tensor s. השיטה callAsFunction(_:) לרוב פשוט מרצפת את הקלט דרך שכבות משנה. בואו נגדיר IrisModel שמרצף את הקלט דרך שלוש תת שכבות Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
פונקציית ההפעלה קובעת את צורת הפלט של כל צומת בשכבה. אי-לינאריות אלו חשובות - בלעדיהם המודל יהיה שווה ערך לשכבה אחת. ישנן הפעלות זמינות רבות, אך ReLU נפוץ עבור שכבות נסתרות.
המספר האידיאלי של שכבות ונוירונים נסתרות תלוי בבעיה ובמערך הנתונים. כמו היבטים רבים של למידת מכונה, בחירת הצורה הטובה ביותר של הרשת העצבית דורשת תערובת של ידע וניסוי. ככלל אצבע, הגדלת מספר השכבות והנוירונים הנסתרות יוצרת בדרך כלל מודל חזק יותר, שדורש יותר נתונים כדי להתאמן ביעילות.
שימוש בדגם
בואו נסתכל במהירות מה המודל הזה עושה לקבוצת תכונות:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
כאן, כל דוגמה מחזירה לוגיט עבור כל מחלקה.
כדי להמיר לוגיטים אלה להסתברות עבור כל מחלקה, השתמש בפונקציה softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
לקיחת ה- argmax בין מחלקות נותן לנו את אינדקס המחלקות החזוי. אבל, המודל עדיין לא עבר הכשרה, אז אלה לא תחזיות טובות.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
לאמן את הדגם
אימון הוא השלב של למידת מכונה כאשר המודל עובר אופטימיזציה הדרגתית, או שהמודל לומד את מערך הנתונים. המטרה היא ללמוד מספיק על המבנה של מערך האימון כדי לבצע תחזיות לגבי נתונים בלתי נראים. אם אתה לומד יותר מדי על מערך האימון, אזי התחזיות פועלות רק עבור הנתונים שהוא ראה ולא יהיו ניתנות להכללה. בעיה זו נקראת התאמת יתר - זה כמו לשנן את התשובות במקום להבין איך לפתור בעיה.
בעיית סיווג הקשתית היא דוגמה ללמידת מכונה מפוקחת : המודל מאומן מדוגמאות המכילות תוויות. בלמידת מכונה ללא פיקוח , הדוגמאות אינן מכילות תוויות. במקום זאת, המודל בדרך כלל מוצא דפוסים בין התכונות.
בחר פונקציית אובדן
הן שלבי ההדרכה והן שלבי ההערכה צריכים לחשב את ההפסד של המודל. זה מודד עד כמה תחזיות המודל אינן מהתווית הרצויה, במילים אחרות, עד כמה המודל מתפקד רע. אנחנו רוצים למזער, או לייעל את הערך הזה.
המודל שלנו יחשב את ההפסד שלו באמצעות הפונקציה softmaxCrossEntropy(logits:labels:) שלוקחת את תחזיות ההסתברות של המודל ואת התווית הרצויה, ומחזירה את ההפסד הממוצע על פני הדוגמאות.
בואו נחשב את ההפסד עבור המודל הנוכחי הלא מאומן:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
צור מייעל
מטעל מחיל את ההדרגות המחושבות על משתני המודל כדי למזער את פונקציית loss . אתה יכול לחשוב על פונקציית ההפסד כמשטח מעוקל (ראה איור 3) ואנחנו רוצים למצוא את הנקודה הנמוכה ביותר שלו על ידי הליכה מסביב. השיפועים מצביעים על כיוון העלייה התלולה ביותר — אז ניסע בדרך ההפוכה ונתקדם במורד הגבעה. על ידי חישוב איטרטיבי של ההפסד והשיפוע עבור כל אצווה, נתאים את המודל במהלך האימון. בהדרגה, הדגם ימצא את השילוב הטוב ביותר של משקלים והטיה כדי למזער את הירידה. וככל שההפסד נמוך יותר, תחזיות המודל טובות יותר.
 |
| איור 3. אלגוריתמי אופטימיזציה המוצגים לאורך זמן בחלל תלת מימדי. (מקור: Stanford class CS231n , רישיון MIT, קרדיט תמונה: Alec Radford ) |
ל- Swift for TensorFlow יש אלגוריתמי אופטימיזציה רבים הזמינים לאימון. מודל זה משתמש בכלי האופטימיזציה של SGD שמיישם את האלגוריתם של ירידה בשיפוע הסטוכסטי (SGD). ה- learningRate מגדיר את גודל הצעד שיש לבצע עבור כל איטרציה במורד הגבעה. זהו היפרפרמטר שבדרך כלל תתאים כדי להשיג תוצאות טובות יותר.
let optimizer = SGD(for: model, learningRate: 0.01)
בוא נשתמש optimizer כדי לבצע צעד בודד של ירידה בשיפוע. ראשית, אנו מחשבים את שיפוע ההפסד ביחס למודל:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
לאחר מכן, נעביר את הגרדיאנט שחישבנו לאופטימיזר, אשר מעדכן את המשתנים הניתנים להבדלה של המודל בהתאם:
optimizer.update(&model, along: grads)
אם מחשבים את ההפסד שוב, הוא צריך להיות קטן יותר, כי צעדי ירידה בשיפוע (בדרך כלל) מקטינים את ההפסד:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
לולאת אימון
עם כל החלקים במקום, הדגם מוכן לאימון! לולאת אימון מזינה את דוגמאות מערך הנתונים לתוך המודל כדי לעזור לו לבצע תחזיות טובות יותר. בלוק הקוד הבא מגדיר את שלבי ההדרכה האלה:
- חזור על כל תקופה . עידן הוא מעבר אחד במערך הנתונים.
- בתוך תקופה, חזור על כל אצווה בתקופת האימון
- אסוף את האצווה ותפס את התכונות שלה (
x) והתווית (y). - באמצעות התכונות של האצווה שנאספה, בצע תחזית והשווה אותה עם התווית. מדוד את חוסר הדיוק של החיזוי והשתמש בזה כדי לחשב את האובדן והשיפועים של המודל.
- השתמש בירידה בשיפוע כדי לעדכן את משתני המודל.
- עקוב אחר כמה נתונים סטטיסטיים להדמיה.
- חזור על כל תקופה.
המשתנה epochCount הוא מספר הפעמים ללולאה על אוסף הנתונים. באופן מנוגד לאינטואיטיביות, אימון מודל ארוך יותר אינו מבטיח מודל טוב יותר. epochCount הוא היפרפרמטר שאתה יכול לכוון. בחירת המספר הנכון דורשת בדרך כלל גם ניסיון וגם ניסוי.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
דמיינו את פונקציית האובדן לאורך זמן
אמנם זה מועיל להדפיס את התקדמות האימון של המודל, אבל לעתים קרובות יותר מועיל לראות את ההתקדמות הזו. אנו יכולים ליצור תרשימים בסיסיים באמצעות מודול matplotlib של Python.
פירוש התרשימים הללו דורש קצת ניסיון, אבל אתה באמת רוצה לראות את ההפסד יורד ואת הדיוק עולה.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
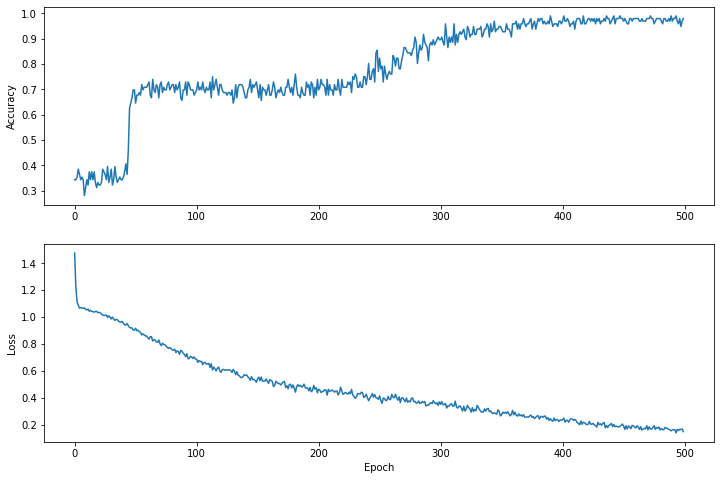
Use `print()` to show values.
שימו לב שצירי ה-y של הגרפים אינם מבוססי אפס.
הערך את יעילות המודל
כעת, כשהמודל מאומן, אנו יכולים לקבל כמה נתונים סטטיסטיים על הביצועים שלו.
הערכה פירושה קביעה באיזו יעילות המודל עושה תחזיות. כדי לקבוע את יעילות המודל בסיווג הקשתית, העבירו כמה מדידות של גביע ועלי כותרת למודל ובקשו מהמודל לחזות איזה מיני קשתית הם מייצגים. לאחר מכן השווה את התחזית של המודל מול התווית בפועל. לדוגמה, למודל שבחר את המין הנכון במחצית מדוגמאות הקלט יש דיוק של 0.5 . איור 4 מציג מודל מעט יותר יעיל, מקבל 4 מתוך 5 תחזיות נכונות ברמת דיוק של 80%:
| תכונות לדוגמה | מַדבֵּקָה | חיזוי מודל | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| איור 4. מסווג קשתית המדויק ב-80%. | |||||
הגדר את מערך הנתונים של הבדיקה
הערכת המודל דומה לאימון המודל. ההבדל הגדול ביותר הוא שהדוגמאות מגיעות ממערך מבחנים נפרד ולא ממערך האימונים. כדי להעריך בצורה הוגנת את האפקטיביות של מודל, הדוגמאות המשמשות להערכת מודל חייבות להיות שונות מהדוגמאות המשמשות לאימון המודל.
ההגדרה עבור מערך הנתונים של הבדיקה דומה להגדרה עבור מערך הנתונים של אימון. הורד את ערכת הבדיקות מ- http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
כעת טען אותו למערך של IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
הערך את המודל במערך הנתונים של הבדיקה
בניגוד לשלב ההכשרה, המודל מעריך רק תקופה בודדת של נתוני הבדיקה. בתא הקוד הבא, אנו חוזרים על כל דוגמה בערכת הבדיקה ומשווים את חיזוי המודל מול התווית בפועל. זה משמש למדידת דיוק המודל על פני כל מערך הבדיקה.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
אנו יכולים לראות באצווה הראשונה, למשל, המודל בדרך כלל נכון:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
השתמש במודל המאומן כדי ליצור תחזיות
אימנו מודל והדגמנו שהוא טוב - אבל לא מושלם - בסיווג מיני איריס. כעת הבה נשתמש במודל המאומן כדי ליצור כמה תחזיות על דוגמאות ללא תווית ; כלומר, על דוגמאות המכילות תכונות אך לא תווית.
בחיים האמיתיים, הדוגמאות ללא תווית יכולות להגיע מהרבה מקורות שונים כולל אפליקציות, קבצי CSV ועדכוני נתונים. לעת עתה, אנו נספק ידנית שלוש דוגמאות ללא תווית כדי לחזות את התוויות שלהן. כזכור, מספרי התוויות ממופים לייצוג בעל שם כ:
-
0: איריס סטוסה -
1: איריס ורסיקולור -
2: איריס וירג'יניקה
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])