
| |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें |
यह गाइड एक मशीन लर्निंग मॉडल बनाकर टेंसरफ्लो के लिए स्विफ्ट का परिचय देता है जो प्रजातियों के आधार पर आईरिस फूलों को वर्गीकृत करता है। यह TensorFlow के लिए स्विफ्ट का उपयोग करता है:
- एक मॉडल बनाएं,
- इस मॉडल को उदाहरण डेटा पर प्रशिक्षित करें, और
- अज्ञात डेटा के बारे में पूर्वानुमान लगाने के लिए मॉडल का उपयोग करें।
टेन्सरफ़्लो प्रोग्रामिंग
यह मार्गदर्शिका TensorFlow अवधारणाओं के लिए इन उच्च-स्तरीय स्विफ्ट का उपयोग करती है:
- एपोच एपीआई के साथ डेटा आयात करें।
- स्विफ्ट एब्स्ट्रैक्शन का उपयोग करके मॉडल बनाएं।
- जब शुद्ध स्विफ्ट लाइब्रेरी उपलब्ध न हो तो स्विफ्ट की पायथन इंटरऑपरेबिलिटी का उपयोग करके पायथन लाइब्रेरी का उपयोग करें।
यह ट्यूटोरियल कई TensorFlow प्रोग्रामों की तरह संरचित है:
- डेटा सेट आयात और पार्स करें।
- मॉडल का प्रकार चुनें.
- मॉडल को प्रशिक्षित करें.
- मॉडल की प्रभावशीलता का मूल्यांकन करें.
- पूर्वानुमान लगाने के लिए प्रशिक्षित मॉडल का उपयोग करें।
सेटअप प्रोग्राम
आयात कॉन्फ़िगर करें
TensorFlow और कुछ उपयोगी Python मॉड्यूल आयात करें।
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
आईरिस वर्गीकरण समस्या
कल्पना कीजिए कि आप एक वनस्पतिशास्त्री हैं जो आपको मिलने वाले प्रत्येक आईरिस फूल को वर्गीकृत करने का एक स्वचालित तरीका खोज रहे हैं। मशीन लर्निंग फूलों को सांख्यिकीय रूप से वर्गीकृत करने के लिए कई एल्गोरिदम प्रदान करता है। उदाहरण के लिए, एक परिष्कृत मशीन लर्निंग प्रोग्राम तस्वीरों के आधार पर फूलों को वर्गीकृत कर सकता है। हमारी महत्वाकांक्षाएं अधिक विनम्र हैं - हम आईरिस फूलों को उनके बाह्यदलों और पंखुड़ियों की लंबाई और चौड़ाई माप के आधार पर वर्गीकृत करने जा रहे हैं।
आइरिस जीनस में लगभग 300 प्रजातियाँ शामिल हैं, लेकिन हमारा कार्यक्रम केवल निम्नलिखित तीन को वर्गीकृत करेगा:
- आइरिस सेटोसा
- आइरिस वर्जिनिका
- आइरिस वर्सिकोलर
 |
| चित्र 1. आइरिस सेटोसा ( रेडोमिल द्वारा, CC BY-SA 3.0), आइरिस वर्सिकोलर , ( Dlanglois द्वारा, CC BY-SA 3.0), और आइरिस वर्जिनिका ( फ्रैंक मेफील्ड द्वारा, CC BY-SA 2.0)। |
सौभाग्य से, किसी ने पहले ही बाह्यदल और पंखुड़ी माप के साथ 120 आईरिस फूलों का डेटा सेट बना लिया है। यह एक क्लासिक डेटासेट है जो शुरुआती मशीन लर्निंग वर्गीकरण समस्याओं के लिए लोकप्रिय है।
प्रशिक्षण डेटासेट को आयात और पार्स करें
डेटासेट फ़ाइल डाउनलोड करें और इसे एक संरचना में परिवर्तित करें जिसका उपयोग इस स्विफ्ट प्रोग्राम द्वारा किया जा सकता है।
डेटासेट डाउनलोड करें
http://download.tensorflow.org/data/iris_training.csv से प्रशिक्षण डेटासेट फ़ाइल डाउनलोड करें
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
डेटा का निरीक्षण करें
यह डेटासेट, iris_training.csv , एक सादा पाठ फ़ाइल है जो अल्पविराम से अलग किए गए मान (CSV) के रूप में स्वरूपित सारणीबद्ध डेटा को संग्रहीत करता है। आइए पहली 5 प्रविष्टियों पर नजर डालें।
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
डेटासेट के इस दृश्य से, निम्नलिखित पर ध्यान दें:
- पहली पंक्ति एक हेडर है जिसमें डेटासेट के बारे में जानकारी होती है:
- कुल 120 उदाहरण हैं. प्रत्येक उदाहरण में चार विशेषताएं और तीन संभावित लेबल नामों में से एक है।
- बाद की पंक्तियाँ डेटा रिकॉर्ड हैं, प्रति पंक्ति एक उदाहरण , जहाँ:
आइए इसे कोड में लिखें:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
प्रत्येक लेबल स्ट्रिंग नाम (उदाहरण के लिए, "सेटोसा") से जुड़ा होता है, लेकिन मशीन लर्निंग आमतौर पर संख्यात्मक मानों पर निर्भर करती है। लेबल संख्याओं को नामित प्रतिनिधित्व में मैप किया जाता है, जैसे:
-
0: आइरिस सेटोसा -
1: आइरिस वर्सिकोलर -
2: आइरिस वर्जिनिका
सुविधाओं और लेबल के बारे में अधिक जानकारी के लिए, मशीन लर्निंग क्रैश कोर्स का एमएल शब्दावली अनुभाग देखें।
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
एपोच एपीआई का उपयोग करके एक डेटासेट बनाएं
टेन्सरफ्लो के एपोच एपीआई के लिए स्विफ्ट डेटा को पढ़ने और इसे प्रशिक्षण के लिए उपयोग किए जाने वाले फॉर्म में बदलने के लिए एक उच्च स्तरीय एपीआई है।
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
चूंकि हमारे द्वारा डाउनलोड किए गए डेटासेट सीएसवी प्रारूप में हैं, आइए आईरिसबैच ऑब्जेक्ट्स की सूची के रूप में डेटा को लोड करने के लिए एक फ़ंक्शन लिखें
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
अब हम प्रशिक्षण डेटासेट को लोड करने और TrainingEpochs ऑब्जेक्ट बनाने के लिए सीएसवी लोडिंग फ़ंक्शन का उपयोग कर सकते हैं
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
TrainingEpochs ऑब्जेक्ट युगों का एक अनंत अनुक्रम है। प्रत्येक युग में IrisBatch es शामिल हैं। आइए पहले युग के पहले तत्व को देखें।
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
ध्यान दें कि पहले batchSize उदाहरणों की सुविधाओं को firstTrainFeatures में एक साथ समूहीकृत किया गया है (या बैच किया गया है ), और पहले batchSize उदाहरणों के लेबल को firstTrainLabels में बैच किया गया है।
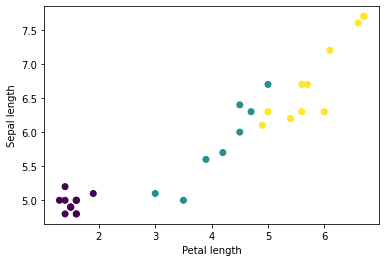
आप पायथन के matplotlib का उपयोग करके बैच से कुछ सुविधाओं को प्लॉट करके कुछ क्लस्टर देखना शुरू कर सकते हैं:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
मॉडल का प्रकार चुनें
मॉडल क्यों?
एक मॉडल सुविधाओं और लेबल के बीच का संबंध है। आईरिस वर्गीकरण समस्या के लिए, मॉडल बाह्यदल और पंखुड़ी माप और अनुमानित आईरिस प्रजातियों के बीच संबंध को परिभाषित करता है। कुछ सरल मॉडलों को बीजगणित की कुछ पंक्तियों के साथ वर्णित किया जा सकता है, लेकिन जटिल मशीन लर्निंग मॉडल में बड़ी संख्या में पैरामीटर होते हैं जिन्हें संक्षेप में प्रस्तुत करना मुश्किल होता है।
क्या आप मशीन लर्निंग का उपयोग किए बिना चार विशेषताओं और आईरिस प्रजातियों के बीच संबंध निर्धारित कर सकते हैं? अर्थात्, क्या आप एक मॉडल बनाने के लिए पारंपरिक प्रोग्रामिंग तकनीकों (उदाहरण के लिए, बहुत सारे सशर्त कथन) का उपयोग कर सकते हैं? शायद—यदि आपने किसी विशेष प्रजाति के पंखुड़ी और बाह्यदल माप के बीच संबंधों को निर्धारित करने के लिए डेटासेट का काफी देर तक विश्लेषण किया है। और अधिक जटिल डेटासेट पर यह कठिन—शायद असंभव—हो जाता है। एक अच्छा मशीन लर्निंग दृष्टिकोण आपके लिए मॉडल निर्धारित करता है । यदि आप सही मशीन लर्निंग मॉडल प्रकार में पर्याप्त प्रतिनिधि उदाहरण फ़ीड करते हैं, तो प्रोग्राम आपके लिए रिश्तों का पता लगाएगा।
मॉडल का चयन करें
हमें प्रशिक्षित करने के लिए मॉडल के प्रकार का चयन करना होगा। कई प्रकार के मॉडल हैं और एक अच्छा मॉडल चुनने के लिए अनुभव की आवश्यकता होती है। यह ट्यूटोरियल आईरिस वर्गीकरण समस्या को हल करने के लिए एक तंत्रिका नेटवर्क का उपयोग करता है। तंत्रिका नेटवर्क सुविधाओं और लेबल के बीच जटिल संबंध ढूंढ सकते हैं। यह एक उच्च संरचित ग्राफ़ है, जो एक या अधिक छिपी हुई परतों में व्यवस्थित होता है। प्रत्येक छिपी हुई परत में एक या अधिक न्यूरॉन्स होते हैं। तंत्रिका नेटवर्क की कई श्रेणियां हैं और यह प्रोग्राम एक घने, या पूरी तरह से जुड़े तंत्रिका नेटवर्क का उपयोग करता है: एक परत में न्यूरॉन्स पिछली परत में प्रत्येक न्यूरॉन से इनपुट कनेक्शन प्राप्त करते हैं। उदाहरण के लिए, चित्र 2 एक सघन तंत्रिका नेटवर्क को दर्शाता है जिसमें एक इनपुट परत, दो छिपी हुई परतें और एक आउटपुट परत शामिल है:
 |
| चित्र 2. सुविधाओं, छिपी हुई परतों और भविष्यवाणियों वाला एक तंत्रिका नेटवर्क। |
जब चित्र 2 के मॉडल को प्रशिक्षित किया जाता है और एक गैर-लेबल वाला उदाहरण खिलाया जाता है, तो इससे तीन भविष्यवाणियां मिलती हैं: संभावना है कि यह फूल दी गई आईरिस प्रजाति है। इस भविष्यवाणी को अनुमान कहा जाता है। इस उदाहरण के लिए, आउटपुट पूर्वानुमानों का योग 1.0 है। चित्र 2 में, यह भविष्यवाणी इस प्रकार विभाजित है: आइरिस सेटोसा के लिए 0.02 , आइरिस वर्सीकोलर के लिए 0.95 , और आइरिस वर्जिनिका के लिए 0.03 । इसका मतलब यह है कि मॉडल भविष्यवाणी करता है - 95% संभावना के साथ - कि एक बिना लेबल वाला उदाहरण फूल एक आइरिस वर्सिकलर है।
TensorFlow डीप लर्निंग लाइब्रेरी के लिए स्विफ्ट का उपयोग करके एक मॉडल बनाएं
टेन्सरफ्लो डीप लर्निंग लाइब्रेरी के लिए स्विफ्ट आदिम परतों और परंपराओं को एक साथ जोड़ने के लिए परिभाषित करती है, जिससे मॉडल बनाना और प्रयोग करना आसान हो जाता है।
एक मॉडल एक struct है जो Layer के अनुरूप है, जिसका अर्थ है कि यह एक callAsFunction(_:) विधि को परिभाषित करता है जो इनपुट Tensor s को आउटपुट Tensor s में मैप करता है। callAsFunction(_:) विधि अक्सर सबलेयर्स के माध्यम से इनपुट को अनुक्रमित करती है। आइए एक IrisModel परिभाषित करें जो तीन Dense उप-परतों के माध्यम से इनपुट को अनुक्रमित करता है।
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
सक्रियण फ़ंक्शन परत में प्रत्येक नोड के आउटपुट आकार को निर्धारित करता है। ये गैर-रैखिकताएँ महत्वपूर्ण हैं - इनके बिना मॉडल एक परत के बराबर होगा। कई सक्रियण उपलब्ध हैं, लेकिन छुपी परतों के लिए ReLU आम है।
छिपी हुई परतों और न्यूरॉन्स की आदर्श संख्या समस्या और डेटासेट पर निर्भर करती है। मशीन लर्निंग के कई पहलुओं की तरह, तंत्रिका नेटवर्क का सर्वोत्तम आकार चुनने के लिए ज्ञान और प्रयोग के मिश्रण की आवश्यकता होती है। सामान्य नियम के रूप में, छिपी हुई परतों और न्यूरॉन्स की संख्या में वृद्धि आम तौर पर एक अधिक शक्तिशाली मॉडल बनाती है, जिसे प्रभावी ढंग से प्रशिक्षित करने के लिए अधिक डेटा की आवश्यकता होती है।
मॉडल का उपयोग करना
आइए एक नज़र डालें कि यह मॉडल सुविधाओं के एक बैच के लिए क्या करता है:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
यहां, प्रत्येक उदाहरण प्रत्येक वर्ग के लिए एक लॉगिट लौटाता है।
इन लॉग को प्रत्येक वर्ग के लिए संभाव्यता में बदलने के लिए, सॉफ्टमैक्स फ़ंक्शन का उपयोग करें:
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
विभिन्न कक्षाओं में argmax लेने से हमें अनुमानित वर्ग सूचकांक प्राप्त होता है। लेकिन, मॉडल को अभी तक प्रशिक्षित नहीं किया गया है, इसलिए ये अच्छी भविष्यवाणियाँ नहीं हैं।
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
मॉडल को प्रशिक्षित करें
प्रशिक्षण मशीन लर्निंग का वह चरण है जब मॉडल को धीरे-धीरे अनुकूलित किया जाता है, या मॉडल डेटासेट सीखता है । लक्ष्य अदृश्य डेटा के बारे में पूर्वानुमान लगाने के लिए प्रशिक्षण डेटासेट की संरचना के बारे में पर्याप्त सीखना है। यदि आप प्रशिक्षण डेटासेट के बारे में बहुत अधिक सीखते हैं, तो पूर्वानुमान केवल उसके द्वारा देखे गए डेटा के लिए काम करते हैं और सामान्यीकरण योग्य नहीं होंगे। इस समस्या को ओवरफिटिंग कहा जाता है - यह किसी समस्या को हल करने के तरीके को समझने के बजाय उत्तरों को याद रखने जैसा है।
आईरिस वर्गीकरण समस्या पर्यवेक्षित मशीन लर्निंग का एक उदाहरण है: मॉडल को उन उदाहरणों से प्रशिक्षित किया जाता है जिनमें लेबल होते हैं। बिना पर्यवेक्षित मशीन लर्निंग में, उदाहरणों में लेबल नहीं होते हैं। इसके बजाय, मॉडल आमतौर पर सुविधाओं के बीच पैटर्न ढूंढता है।
हानि फ़ंक्शन चुनें
प्रशिक्षण और मूल्यांकन दोनों चरणों में मॉडल के नुकसान की गणना करने की आवश्यकता है। यह मापता है कि किसी मॉडल की भविष्यवाणियाँ वांछित लेबल से कितनी दूर हैं, दूसरे शब्दों में, मॉडल कितना खराब प्रदर्शन कर रहा है। हम इस मान को न्यूनतम या अनुकूलित करना चाहते हैं।
हमारा मॉडल softmaxCrossEntropy(logits:labels:) फ़ंक्शन का उपयोग करके अपने नुकसान की गणना करेगा जो मॉडल की वर्ग संभाव्यता भविष्यवाणियों और वांछित लेबल लेता है, और उदाहरणों में औसत नुकसान लौटाता है।
आइए वर्तमान अप्रशिक्षित मॉडल के नुकसान की गणना करें:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
एक अनुकूलक बनाएं
एक ऑप्टिमाइज़र loss फ़ंक्शन को कम करने के लिए मॉडल के वेरिएबल्स पर गणना किए गए ग्रेडिएंट्स को लागू करता है। आप हानि फ़ंक्शन को एक घुमावदार सतह के रूप में सोच सकते हैं (चित्र 3 देखें) और हम चारों ओर घूमकर इसका निम्नतम बिंदु खोजना चाहते हैं। ढालें सबसे तीव्र चढ़ाई की दिशा में इंगित करती हैं - इसलिए हम विपरीत दिशा में यात्रा करेंगे और पहाड़ी से नीचे की ओर बढ़ेंगे। प्रत्येक बैच के लिए हानि और ग्रेडिएंट की पुनरावर्ती गणना करके, हम प्रशिक्षण के दौरान मॉडल को समायोजित करेंगे। धीरे-धीरे, मॉडल नुकसान को कम करने के लिए वजन और पूर्वाग्रह का सबसे अच्छा संयोजन ढूंढ लेगा। और नुकसान जितना कम होगा, मॉडल की भविष्यवाणियां उतनी ही बेहतर होंगी।
 |
| चित्र 3. 3डी स्पेस में समय के साथ ऑप्टिमाइज़ेशन एल्गोरिदम की कल्पना की गई। (स्रोत: स्टैनफोर्ड क्लास सीएस231एन , एमआईटी लाइसेंस, छवि क्रेडिट: एलेक रेडफोर्ड ) |
TensorFlow के लिए स्विफ्ट में प्रशिक्षण के लिए कई अनुकूलन एल्गोरिदम उपलब्ध हैं। यह मॉडल SGD ऑप्टिमाइज़र का उपयोग करता है जो स्टोकेस्टिक ग्रेडिएंट डिसेंट (SGD) एल्गोरिदम को लागू करता है। learningRate पहाड़ी के नीचे प्रत्येक पुनरावृत्ति के लिए उठाए जाने वाले कदम का आकार निर्धारित करती है। यह एक हाइपरपैरामीटर है जिसे आप बेहतर परिणाम प्राप्त करने के लिए आमतौर पर समायोजित करेंगे।
let optimizer = SGD(for: model, learningRate: 0.01)
आइए एकल ग्रेडिएंट डिसेंट चरण लेने के लिए optimizer उपयोग करें। सबसे पहले, हम मॉडल के संबंध में हानि के ग्रेडिएंट की गणना करते हैं:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
इसके बाद, हम उस ग्रेडिएंट को पास करते हैं जिसकी हमने अभी गणना की है, ऑप्टिमाइज़र को, जो मॉडल के अलग-अलग चर को तदनुसार अपडेट करता है:
optimizer.update(&model, along: grads)
यदि हम हानि की दोबारा गणना करते हैं, तो यह छोटा होना चाहिए, क्योंकि ग्रेडिएंट डिसेंट चरण (आमतौर पर) हानि को कम करते हैं:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
प्रशिक्षण पाश
सभी टुकड़ों के साथ, मॉडल प्रशिक्षण के लिए तैयार है! एक प्रशिक्षण लूप बेहतर भविष्यवाणियां करने में मदद करने के लिए डेटासेट उदाहरणों को मॉडल में फीड करता है। निम्नलिखित कोड ब्लॉक इन प्रशिक्षण चरणों को सेट करता है:
- प्रत्येक युग को दोहराएँ। एक युग डेटासेट के माध्यम से एक बार गुजरना है।
- एक युग के भीतर, प्रशिक्षण युग में प्रत्येक बैच पर पुनरावृति करें
- बैच को एकत्रित करें और इसकी विशेषताएं (
x) और लेबल (y) लें। - एकत्रित बैच की विशेषताओं का उपयोग करके, एक भविष्यवाणी करें और लेबल के साथ इसकी तुलना करें। पूर्वानुमान की अशुद्धि को मापें और मॉडल के नुकसान और ग्रेडिएंट की गणना करने के लिए इसका उपयोग करें।
- मॉडल के वेरिएबल्स को अपडेट करने के लिए ग्रेडिएंट डिसेंट का उपयोग करें।
- विज़ुअलाइज़ेशन के लिए कुछ आँकड़ों पर नज़र रखें।
- प्रत्येक युग के लिए दोहराएँ.
epochCount वैरिएबल डेटासेट संग्रह पर लूप करने की संख्या है। प्रति-सहज ज्ञान से, किसी मॉडल को लंबे समय तक प्रशिक्षित करना बेहतर मॉडल की गारंटी नहीं देता है। epochCount एक हाइपरपैरामीटर है जिसे आप ट्यून कर सकते हैं। सही संख्या चुनने के लिए आमतौर पर अनुभव और प्रयोग दोनों की आवश्यकता होती है।
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
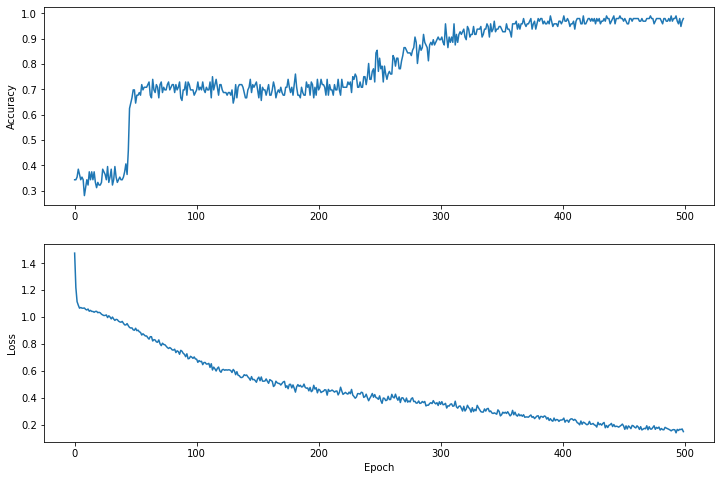
समय के साथ हानि फ़ंक्शन की कल्पना करें
हालाँकि मॉडल की प्रशिक्षण प्रगति को प्रिंट करना सहायक होता है, लेकिन इस प्रगति को देखना अक्सर अधिक सहायक होता है। हम Python के matplotlib मॉड्यूल का उपयोग करके बुनियादी चार्ट बना सकते हैं।
इन चार्टों की व्याख्या करने के लिए कुछ अनुभव की आवश्यकता होती है, लेकिन आप वास्तव में नुकसान को कम होते और सटीकता को बढ़ते हुए देखना चाहते हैं।
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
ध्यान दें कि ग्राफ़ के y-अक्ष शून्य-आधारित नहीं हैं।
मॉडल की प्रभावशीलता का मूल्यांकन करें
अब जब मॉडल प्रशिक्षित हो गया है, तो हम इसके प्रदर्शन पर कुछ आँकड़े प्राप्त कर सकते हैं।
मूल्यांकन का अर्थ यह निर्धारित करना है कि मॉडल कितनी प्रभावी ढंग से भविष्यवाणियाँ करता है। आईरिस वर्गीकरण में मॉडल की प्रभावशीलता निर्धारित करने के लिए, मॉडल में कुछ बाह्यदल और पंखुड़ी माप पास करें और मॉडल से यह अनुमान लगाने के लिए कहें कि वे किस आईरिस प्रजाति का प्रतिनिधित्व करते हैं। फिर वास्तविक लेबल के विरुद्ध मॉडल की भविष्यवाणी की तुलना करें। उदाहरण के लिए, एक मॉडल जिसने आधे इनपुट उदाहरणों पर सही प्रजाति चुनी है, उसकी सटीकता 0.5 है। चित्र 4 थोड़ा अधिक प्रभावी मॉडल दिखाता है, जिसमें 5 में से 4 भविष्यवाणियाँ 80% सटीकता पर सही होती हैं:
| उदाहरण विशेषताएँ | लेबल | मॉडल भविष्यवाणी | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| चित्र 4. एक आईरिस क्लासिफायरियर जो 80% सटीक है। | |||||
परीक्षण डेटासेट सेटअप करें
मॉडल का मूल्यांकन करना मॉडल को प्रशिक्षित करने के समान है। सबसे बड़ा अंतर यह है कि उदाहरण प्रशिक्षण सेट के बजाय एक अलग परीक्षण सेट से आते हैं। किसी मॉडल की प्रभावशीलता का निष्पक्ष मूल्यांकन करने के लिए, किसी मॉडल का मूल्यांकन करने के लिए उपयोग किए जाने वाले उदाहरण मॉडल को प्रशिक्षित करने के लिए उपयोग किए जाने वाले उदाहरणों से भिन्न होने चाहिए।
परीक्षण डेटासेट के लिए सेटअप प्रशिक्षण डेटासेट के लिए सेटअप के समान है। परीक्षण सेट http://download.tensorflow.org/data/iris_test.csv से डाउनलोड करें:
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
अब इसे IrisBatch es की एक सरणी में लोड करें:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
परीक्षण डेटासेट पर मॉडल का मूल्यांकन करें
प्रशिक्षण चरण के विपरीत, मॉडल केवल परीक्षण डेटा के एक युग का मूल्यांकन करता है। निम्नलिखित कोड सेल में, हम परीक्षण सेट में प्रत्येक उदाहरण को दोहराते हैं और वास्तविक लेबल के विरुद्ध मॉडल की भविष्यवाणी की तुलना करते हैं। इसका उपयोग संपूर्ण परीक्षण सेट में मॉडल की सटीकता को मापने के लिए किया जाता है।
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
हम पहले बैच में देख सकते हैं, उदाहरण के लिए, मॉडल आमतौर पर सही है:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
पूर्वानुमान लगाने के लिए प्रशिक्षित मॉडल का उपयोग करें
हमने एक मॉडल को प्रशिक्षित किया है और प्रदर्शित किया है कि यह आईरिस प्रजातियों को वर्गीकृत करने में अच्छा है - लेकिन सही नहीं है। आइए अब बिना लेबल वाले उदाहरणों पर कुछ पूर्वानुमान लगाने के लिए प्रशिक्षित मॉडल का उपयोग करें; यानी, ऐसे उदाहरणों पर जिनमें विशेषताएं तो हैं लेकिन लेबल नहीं।
वास्तविक जीवन में, बिना लेबल वाले उदाहरण ऐप्स, सीएसवी फ़ाइलों और डेटा फ़ीड सहित कई अलग-अलग स्रोतों से आ सकते हैं। अभी के लिए, हम उनके लेबल की भविष्यवाणी करने के लिए मैन्युअल रूप से तीन गैर-लेबल वाले उदाहरण प्रदान करने जा रहे हैं। याद रखें, लेबल संख्याओं को नामित प्रतिनिधित्व के रूप में मैप किया जाता है:
-
0: आइरिस सेटोसा -
1: आइरिस वर्सिकोलर -
2: आइरिस वर्जिनिका
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])