
| |  GitHub에서 소스 보기 GitHub에서 소스 보기 |
이 가이드에서는 붓꽃을 종별로 분류하는 기계 학습 모델을 구축하여 TensorFlow용 Swift를 소개합니다. TensorFlow용 Swift를 사용하여 다음을 수행합니다.
- 모델을 구축하고,
- 예시 데이터를 바탕으로 이 모델을 훈련합니다.
- 모델을 사용하여 알 수 없는 데이터에 대해 예측합니다.
TensorFlow 프로그래밍
이 가이드에서는 다음과 같은 상위 수준의 Swift for TensorFlow 개념을 사용합니다.
- Epochs API를 사용하여 데이터를 가져옵니다.
- Swift 추상화를 사용하여 모델을 구축하세요.
- 순수 Swift 라이브러리를 사용할 수 없는 경우 Swift의 Python 상호 운용성을 사용하여 Python 라이브러리를 사용하세요.
이 튜토리얼은 많은 TensorFlow 프로그램과 같이 구성되어 있습니다.
- 데이터 세트를 가져오고 구문 분석합니다.
- 모델 유형을 선택하세요.
- 모델을 훈련합니다.
- 모델의 효율성을 평가합니다.
- 훈련된 모델을 사용하여 예측합니다.
설치 프로그램
가져오기 구성
TensorFlow 및 일부 유용한 Python 모듈을 가져옵니다.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
붓꽃 분류 문제
당신이 찾은 각 붓꽃을 분류하는 자동화된 방법을 찾고 있는 식물학자라고 상상해 보십시오. 기계 학습은 꽃을 통계적으로 분류하기 위한 다양한 알고리즘을 제공합니다. 예를 들어, 정교한 기계 학습 프로그램은 사진을 기반으로 꽃을 분류할 수 있습니다. 우리의 야망은 좀 더 완만합니다. 붓꽃 꽃받침 과 꽃잎 의 길이와 너비 측정을 기준으로 붓꽃을 분류하겠습니다.
붓꽃 속에는 약 300종이 있지만, 우리 프로그램에서는 다음 세 가지만 분류합니다.
- 아이리스 세토사
- 아이리스 버지니아
- 아이리스 베르시컬러
 |
| 그림 1. Iris setosa ( Radomil 작성, CC BY-SA 3.0), Iris versicolor (작성: Dlanglois , CC BY-SA 3.0) 및 Iris virginica ( Frank Mayfield 작성, CC BY-SA 2.0). |
다행스럽게도 누군가 이미 꽃받침과 꽃잎 측정값을 사용하여 붓꽃 120개의 데이터 세트를 만들었습니다. 이는 초보자 기계 학습 분류 문제에 널리 사용되는 클래식 데이터 세트입니다.
학습 데이터 세트 가져오기 및 구문 분석
데이터 세트 파일을 다운로드하여 이 Swift 프로그램에서 사용할 수 있는 구조로 변환하세요.
데이터 세트 다운로드
http://download.tensorflow.org/data/iris_training.csv 에서 훈련 데이터세트 파일을 다운로드합니다.
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
데이터 검사
이 데이터세트 iris_training.csv 는 쉼표로 구분된 값(CSV) 형식의 표 형식 데이터를 저장하는 일반 텍스트 파일입니다. 처음 5개의 항목을 살펴보겠습니다.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
이 데이터세트 보기에서 다음 사항에 유의하세요.
- 첫 번째 줄은 데이터 세트에 대한 정보가 포함된 헤더입니다.
- 총 120개의 예시가 있습니다. 각 예시에는 4개의 기능과 3개의 가능한 라벨 이름 중 하나가 있습니다.
- 후속 행은 데이터 레코드이며, 한 줄에 하나의 예가 있습니다. 여기서:
이를 코드로 작성해 보겠습니다.
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
각 레이블은 문자열 이름(예: "setosa")과 연결되어 있지만 기계 학습은 일반적으로 숫자 값에 의존합니다. 레이블 번호는 다음과 같이 명명된 표현에 매핑됩니다.
-
0: 아이리스 세토사 -
1: 아이리스 버시컬러 -
2: 아이리스 버지니아
기능 및 레이블에 대한 자세한 내용은 기계 학습 단기집중과정의 ML 용어 섹션을 참조하세요.
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Epochs API를 사용하여 데이터세트 만들기
Swift for TensorFlow의 Epochs API는 데이터를 읽고 이를 훈련에 사용되는 형식으로 변환하는 고급 API입니다.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
다운로드한 데이터 세트는 CSV 형식이므로 IrisBatch 개체 목록으로 데이터를 로드하는 함수를 작성해 보겠습니다.
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
이제 CSV 로딩 기능을 사용하여 교육 데이터 세트를 로드하고 TrainingEpochs 객체를 생성할 수 있습니다.
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
TrainingEpochs 객체는 무한한 시대의 시퀀스입니다. 각 시대에는 IrisBatch 가 포함되어 있습니다. 첫 번째 시대의 첫 번째 요소를 살펴보겠습니다.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
첫 번째 batchSize 예제의 기능은 firstTrainFeatures 로 함께 그룹화(또는 일괄 처리 )되고, 첫 번째 batchSize 예제의 레이블은 firstTrainLabels 로 일괄 처리됩니다.
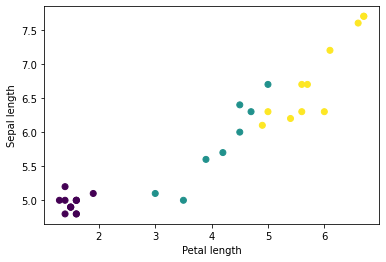
Python의 matplotlib를 사용하여 배치에서 몇 가지 기능을 플로팅하여 일부 클러스터를 볼 수 있습니다.
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
모델 유형을 선택하세요.
왜 모델인가?
모델은 기능과 레이블 간의 관계입니다. 붓꽃 분류 문제의 경우 모델은 꽃받침과 꽃잎 측정값과 예상 붓꽃 종 간의 관계를 정의합니다. 일부 간단한 모델은 몇 줄의 대수학으로 설명할 수 있지만, 복잡한 기계 학습 모델에는 요약하기 어려운 매개변수가 많습니다.
머신러닝을 사용 하지 않고도 네 가지 특징과 붓꽃 종 간의 관계를 판단할 수 있습니까? 즉, 전통적인 프로그래밍 기술(예: 많은 조건문)을 사용하여 모델을 만들 수 있습니까? 아마도 특정 종에 대한 꽃잎과 꽃받침 측정치 간의 관계를 결정할 만큼 충분히 오랫동안 데이터 세트를 분석한 경우일 것입니다. 그리고 더 복잡한 데이터 세트에서는 이것이 어려워지거나 불가능할 수도 있습니다. 좋은 기계 학습 접근 방식이 모델을 결정합니다 . 올바른 기계 학습 모델 유형에 충분한 대표 사례를 제공하면 프로그램이 관계를 파악합니다.
모델을 선택하세요
훈련할 모델의 종류를 선택해야 합니다. 모델의 종류는 다양하며 좋은 모델을 선택하려면 경험이 필요합니다. 이 튜토리얼에서는 붓꽃 분류 문제를 해결하기 위해 신경망을 사용합니다. 신경망은 기능과 레이블 간의 복잡한 관계를 찾을 수 있습니다. 하나 이상의 숨겨진 레이어 로 구성된 고도로 구조화된 그래프입니다. 각 은닉층은 하나 이상의 뉴런 으로 구성됩니다. 신경망에는 여러 범주가 있으며 이 프로그램은 조밀하거나 완전히 연결된 신경망을 사용합니다. 즉, 한 계층의 뉴런은 이전 계층의 모든 뉴런으로부터 입력 연결을 받습니다. 예를 들어, 그림 2는 입력 레이어, 두 개의 숨겨진 레이어 및 출력 레이어로 구성된 조밀한 신경망을 보여줍니다.
 |
| 그림 2. 특징, 은닉층, 예측이 포함된 신경망. |
그림 2의 모델이 훈련되고 레이블이 지정되지 않은 예를 입력하면 이 꽃이 주어진 붓꽃 종이일 가능성이라는 세 가지 예측이 나옵니다. 이 예측을 추론 이라고 합니다. 이 예에서 출력 예측의 합은 1.0입니다. 그림 2에서 이 예측은 Iris setosa 의 경우 0.02 , Iris versicolor 의 경우 0.95 , Iris virginica 의 경우 0.03 으로 분류됩니다. 이는 모델이 레이블이 지정되지 않은 예시 꽃이 Iris versicolor 임을 95% 확률로 예측한다는 것을 의미합니다.
Swift for TensorFlow 딥 러닝 라이브러리를 사용하여 모델 생성
Swift for TensorFlow 딥 러닝 라이브러리는 이들을 함께 연결하기 위한 기본 레이어와 규칙을 정의하므로 모델을 쉽게 구축하고 실험할 수 있습니다.
모델은 Layer 를 준수하는 struct 입니다. 즉, 입력 Tensor 를 출력 Tensor 에 매핑하는 callAsFunction(_:) 메서드를 정의한다는 의미입니다. callAsFunction(_:) 메소드는 종종 하위 레이어를 통해 입력의 순서를 간단히 지정합니다. 세 개의 Dense 하위 계층을 통해 입력을 순서대로 지정하는 IrisModel 정의해 보겠습니다.
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
활성화 함수는 레이어에 있는 각 노드의 출력 모양을 결정합니다. 이러한 비선형성은 중요합니다. 비선형성이 없으면 모델은 단일 레이어와 같습니다. 사용 가능한 활성화가 많이 있지만 ReLU는 숨겨진 레이어에 일반적입니다.
은닉층과 뉴런의 이상적인 수는 문제와 데이터 세트에 따라 다릅니다. 기계 학습의 여러 측면과 마찬가지로 신경망의 가장 좋은 모양을 선택하려면 지식과 실험이 혼합되어 필요합니다. 경험상 히든 레이어와 뉴런의 수를 늘리면 일반적으로 더 강력한 모델이 생성되므로 효과적으로 훈련하려면 더 많은 데이터가 필요합니다.
모델 사용
이 모델이 일련의 기능에 대해 어떤 역할을 하는지 간단히 살펴보겠습니다.
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
여기에서 각 예는 각 클래스에 대한 로짓을 반환합니다.
이러한 로짓을 각 클래스의 확률로 변환하려면 소프트맥스 함수를 사용하십시오.
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
클래스 전체에서 argmax 취하면 예측 클래스 인덱스가 제공됩니다. 그러나 모델이 아직 훈련되지 않았으므로 이는 좋은 예측이 아닙니다.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
모델 학습
훈련은 모델이 점진적으로 최적화되거나 모델이 데이터 세트를 학습하는 기계 학습 단계입니다. 목표는 훈련 데이터 세트의 구조에 대해 충분히 학습하여 보이지 않는 데이터에 대해 예측하는 것입니다. 훈련 데이터 세트에 대해 너무 많이 배우면 예측은 본 데이터에 대해서만 작동하며 일반화할 수 없습니다. 이 문제를 과적합 이라고 합니다. 이는 문제 해결 방법을 이해하는 대신 답을 외우는 것과 같습니다.
붓꽃 분류 문제는 지도 기계 학습 의 한 예입니다. 모델은 레이블이 포함된 예를 통해 훈련됩니다. 비지도 기계 학습 에서는 예제에 레이블이 포함되어 있지 않습니다. 대신 모델은 일반적으로 특성 중에서 패턴을 찾습니다.
손실 함수 선택
훈련 단계와 평가 단계 모두 모델의 손실을 계산해야 합니다. 이는 모델의 예측이 원하는 레이블과 얼마나 다른지, 즉 모델의 성능이 얼마나 나쁜지를 측정합니다. 우리는 이 값을 최소화하거나 최적화하려고 합니다.
우리 모델은 모델의 클래스 확률 예측과 원하는 레이블을 가져와 예제 전반에 걸쳐 평균 손실을 반환하는 softmaxCrossEntropy(logits:labels:) 함수를 사용하여 손실을 계산합니다.
현재 학습되지 않은 모델의 손실을 계산해 보겠습니다.
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
옵티마이저 생성
최적화 프로그램은 계산된 기울기를 모델 변수에 적용하여 loss 함수를 최소화합니다. 손실 함수를 곡면으로 생각할 수 있으며(그림 3 참조) 주위를 둘러보면서 가장 낮은 지점을 찾고 싶습니다. 경사도는 가장 가파른 오르막 방향을 가리키므로 우리는 반대 방향으로 이동하여 언덕을 내려갑니다. 각 배치의 손실과 기울기를 반복적으로 계산하여 훈련 중에 모델을 조정합니다. 점차적으로 모델은 손실을 최소화하기 위해 가중치와 편향의 최상의 조합을 찾습니다. 손실이 낮을수록 모델의 예측이 더 좋아집니다.
 |
| 그림 3. 3D 공간에서 시간 경과에 따라 시각화된 최적화 알고리즘. (출처: Stanford 클래스 CS231n , MIT 라이센스, 이미지 출처: Alec Radford ) |
TensorFlow용 Swift에는 훈련에 사용할 수 있는 많은 최적화 알고리즘이 있습니다. 이 모델은 확률적 경사하강법 (SGD) 알고리즘을 구현하는 SGD 최적화 프로그램을 사용합니다. learningRate 언덕 아래로 각 반복에 대해 취할 단계 크기를 설정합니다. 이는 더 나은 결과를 얻기 위해 일반적으로 조정하는 초매개변수 입니다.
let optimizer = SGD(for: model, learningRate: 0.01)
optimizer 사용하여 단일 경사하강법 단계를 수행해 보겠습니다. 먼저 모델에 대한 손실의 기울기를 계산합니다.
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
다음으로, 방금 계산한 그래디언트를 옵티마이저에 전달하고 그에 따라 모델의 미분 가능한 변수를 업데이트합니다.
optimizer.update(&model, along: grads)
손실을 다시 계산하면 경사 하강 단계(일반적으로)가 손실을 감소시키기 때문에 더 작아야 합니다.
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
훈련 루프
모든 조각이 제자리에 있으면 모델을 훈련할 준비가 되었습니다! 훈련 루프는 더 나은 예측을 할 수 있도록 데이터 세트 예제를 모델에 제공합니다. 다음 코드 블록은 이러한 학습 단계를 설정합니다.
- 각 epoch를 반복합니다. 에포크는 데이터 세트를 한 번 통과하는 것입니다.
- 한 에포크 내에서 훈련 에포크의 각 배치를 반복합니다.
- 배치를 대조하고 해당 기능 (
x)과 레이블 (y)을 가져옵니다. - 대조된 배치의 특징을 사용하여 예측을 수행하고 이를 레이블과 비교합니다. 예측의 부정확성을 측정하고 이를 사용하여 모델의 손실 및 기울기를 계산합니다.
- 모델의 변수를 업데이트하려면 경사하강법을 사용하세요.
- 시각화를 위해 일부 통계를 추적하세요.
- 각 시대마다 반복합니다.
epochCount 변수는 데이터 세트 컬렉션을 반복하는 횟수입니다. 직관과는 반대로 모델을 더 오래 훈련한다고 해서 더 나은 모델이 보장되는 것은 아닙니다. epochCount 조정할 수 있는 하이퍼파라미터 입니다. 올바른 숫자를 선택하려면 일반적으로 경험과 실험이 모두 필요합니다.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
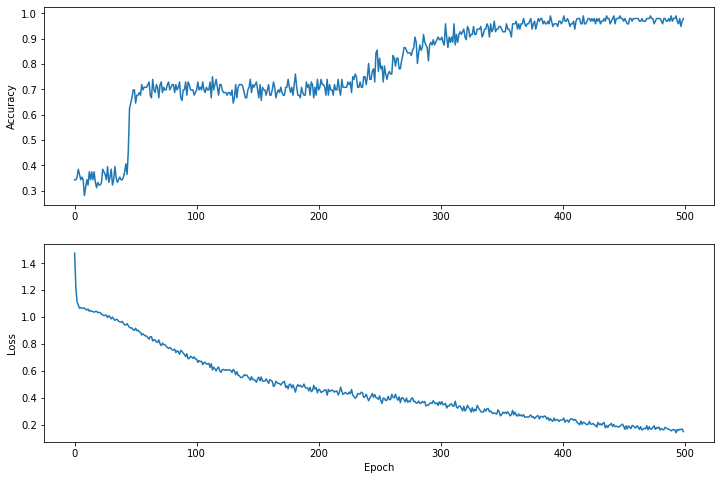
시간 경과에 따른 손실 함수 시각화
모델의 훈련 진행 상황을 인쇄하는 것도 도움이 되지만, 이 진행 상황을 확인하는 것이 더 도움이 되는 경우가 많습니다. Python의 matplotlib 모듈을 사용하여 기본 차트를 만들 수 있습니다.
이 차트를 해석하려면 약간의 경험이 필요하지만 실제로는 손실이 줄어들고 정확도가 높아지는 것을 확인하고 싶습니다.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
그래프의 y축은 0부터 시작하지 않습니다.
모델의 효율성 평가
이제 모델이 훈련되었으므로 성능에 대한 통계를 얻을 수 있습니다.
평가는 모델이 얼마나 효과적으로 예측하는지 결정하는 것을 의미합니다. 붓꽃 분류에서 모델의 효율성을 확인하려면 일부 꽃받침 및 꽃잎 측정값을 모델에 전달하고 모델에 붓꽃 종을 예측하도록 요청합니다. 그런 다음 모델의 예측을 실제 라벨과 비교합니다. 예를 들어, 입력 예제의 절반에서 올바른 종을 선택한 모델의 정확도 는 0.5 입니다. 그림 4는 80% 정확도로 5개 예측 중 4개를 정확하게 맞추는 약간 더 효과적인 모델을 보여줍니다.
| 예시 기능 | 상표 | 모델 예측 | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| 그림 4. 80% 정확도의 붓꽃 분류기. | |||||
테스트 데이터 세트 설정
모델을 평가하는 것은 모델을 훈련하는 것과 유사합니다. 가장 큰 차이점은 예제가 훈련 세트가 아닌 별도의 테스트 세트 에서 나온다는 것입니다. 모델의 효율성을 공정하게 평가하려면 모델을 평가하는 데 사용되는 예제가 모델을 학습하는 데 사용되는 예제와 달라야 합니다.
테스트 데이터 세트의 설정은 학습 데이터 세트의 설정과 유사합니다. http://download.tensorflow.org/data/iris_test.csv 에서 테스트 세트를 다운로드합니다.
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
이제 IrisBatch 배열에 로드합니다.
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
테스트 데이터 세트에서 모델을 평가합니다.
훈련 단계와 달리 모델은 테스트 데이터의 단일 에포크 만 평가합니다. 다음 코드 셀에서는 테스트 세트의 각 예를 반복하고 모델의 예측을 실제 레이블과 비교합니다. 이는 전체 테스트 세트에서 모델의 정확도를 측정하는 데 사용됩니다.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
예를 들어 첫 번째 배치에서 모델이 일반적으로 정확하다는 것을 확인할 수 있습니다.
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
훈련된 모델을 사용하여 예측하기
우리는 모델을 훈련하여 붓꽃 종을 분류하는 데 적합하지만 완벽하지는 않음을 입증했습니다. 이제 훈련된 모델을 사용하여 라벨이 지정되지 않은 예시 에 대해 몇 가지 예측을 해보겠습니다. 즉, 기능은 포함하지만 레이블은 포함하지 않는 예입니다.
실제로 라벨이 지정되지 않은 예는 앱, CSV 파일, 데이터 피드를 비롯한 다양한 소스에서 나올 수 있습니다. 지금은 라벨을 예측하기 위해 라벨이 지정되지 않은 세 가지 예를 수동으로 제공하겠습니다. 레이블 번호는 다음과 같이 명명된 표현에 매핑됩니다.
-
0: 아이리스 세토사 -
1: 아이리스 버시컬러 -
2: 아이리스 버지니아
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])