

识别音频所表示内容的任务称为音频分类。我们可以对音频分类模型进行训练以识别各种音频事件。例如,您可以训练模型来识别表示三种不同事件的事件:鼓掌、打响指动和打字。TensorFlow Lite 提供经过优化的预训练模型,您可以将其部署在您的移动应用中。请点击这里了解有关使用 TensorFlow 进行音频分类的更多信息。
下图展示了音频分类模型在 Android 上的输出。
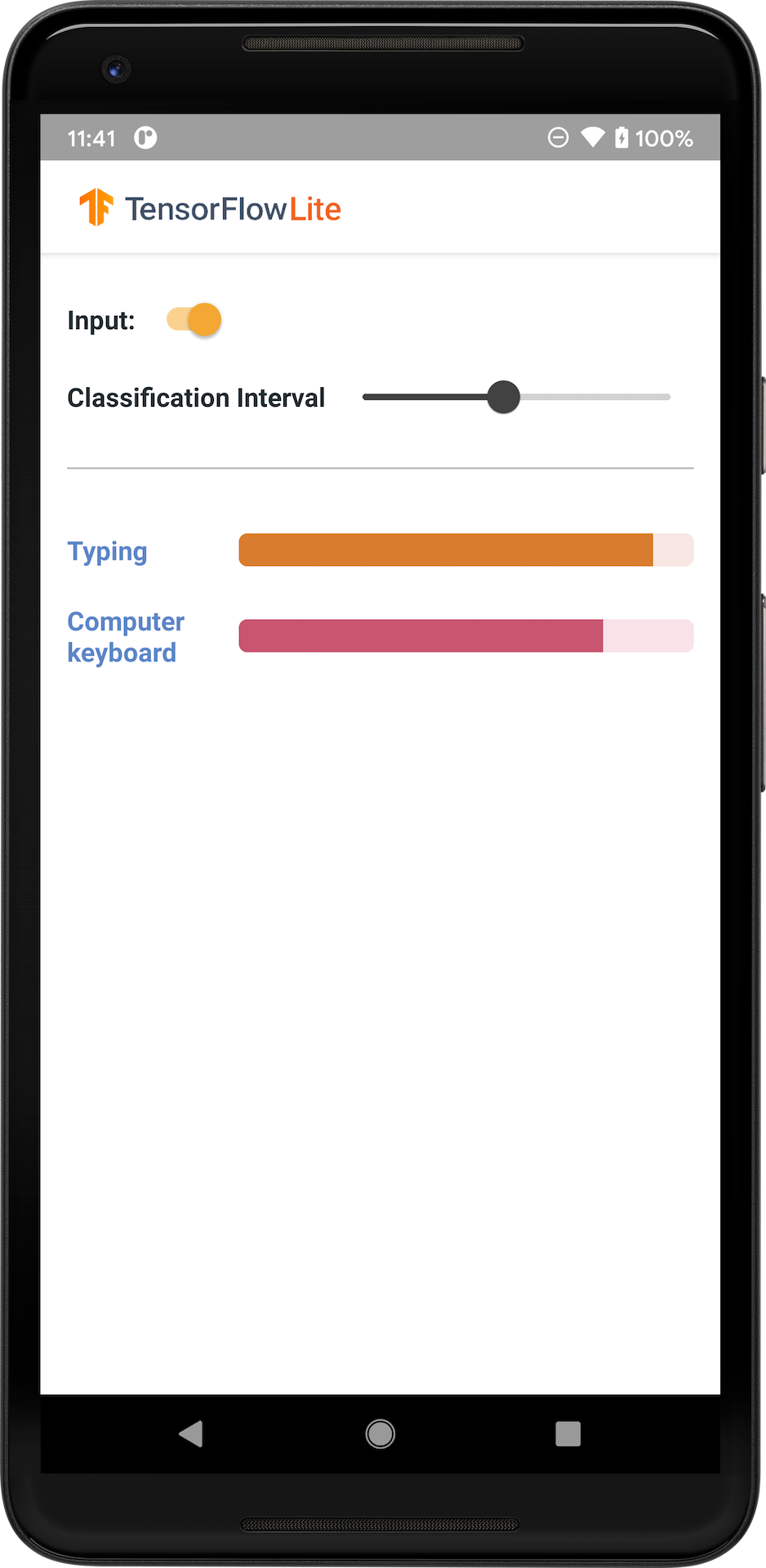
注:(1) 要集成现有模型,请尝试 TensorFlow Lite Task Library。(2) 要自定义模型,请尝试 TensorFlow Lite Model Maker。
开始
如果您是 TensorFlow Lite 新用户,并且使用的是 Android 平台,我们建议您研究以下可以帮助您入门的示例应用。
您可以利用 TensorFlow Lite Task Library 中开箱即用的 API,只需几行代码即可集成音频分类模型。您也可以使用 TensorFlow Lite Support Library 构建自己的自定义推断流水线。
下面的 Android 示例使用TFLite Task Library 演示了实现:
如果您使用的平台不是 Android/iOS,或者您已经熟悉 TensorFlow Lite API,请下载入门模型和支持文件(如果适用)。
模型说明
YAMNet 是一个音频事件分类器,它将音频波形作为输入,并从 AudioSet 本体中对 521 个音频事件中的每个事件进行独立预测。该模型使用 MobileNet v1 架构,并使用 AudioSet 语料库进行训练。该模型最初在 TensorFlow Model Garden 中发布,其中有模型源代码、原始模型检查点和详细文档。
工作原理
转换为 TFLite 的 YAMNet 模型有两个版本:
YAMNet 是原始的音频分类模型,具有动态输入大小,适合迁移学习、Web 和 移动部署。它的输出也更加复杂。
YAMNet/分类是一个经过量化的版本,具有更简单的固定长度帧输入(15600 个样本),并返回 521 个音频事件类的单个分数向量。
输入
该模型接受长度为 15600 的 1 维 float32 张量或 NumPy 数组,该数组包含 0.975 秒的波形,表示为在范围 [-1.0, +1.0] 内的单声道 16 kHz 样本。
输出
该模型返回形状为 (1, 521) 的 2 维 float32 张量,其中包含 YAMNet 支持的 AudioSet 本体中 521 个类中每个类的预测分数。使用 YAMNet 类映射将分数张量的列索引 (0-520) 映射到相应的 AudioSet 类名称,该类映射可作为打包到模型文件中的关联文件 yamnet_label_list.txt 使用。用法见下文。
适合的用途
YAMNet 可用作:
- 独立的音频事件分类器,在各种音频事件之间提供合理的基线。
- 高级特征提取器:YAMNet 的 1024 维嵌入向量输出可以用作另一个模型的输入特征,然后可以用少量数据对该模型进行训练,用于特定的任务。这样可以快速创建专门的音频分类器,而不需要大量带标签数据,也不需要训练大型端到端模型。
- 热启动:YAMNet 模型参数可以用于初始化较大模型的一部分,提高微调和模型探索的速度。
函数式模型示例:
- YAMNet 的分类器输出尚未跨类进行校准,因此您不能直接将输出视为概率。对于任何给定的任务,您很可能需要使用特定于任务的数据执行校准,以便您为每个类分配适当的分数阈值和比例。
- YAMNet 已经过数百万个 YouTube 视频的训练,尽管这些视频非常多样化,但对于任何给定的任务,典型 YouTube 视频和预期的音频输入之间仍然可能存在领域不匹配。您应该进行一些微调和校准,以使 YAMNet 在您构建的任何系统中变得可用。
模型自定义
所提供的预训练模型经过了检测 521 个不同音频类的训练。有关类的完整列表,请参阅模型库中的标签文件。
您可以使用一种称为迁移学习的技术来重新训练模型,以识别不在原始集合中的类。例如,您可以重新训练模型以检测多种鸟鸣。为此,您需要为您希望训练的每个新标签提供一组训练音频。推荐的方式是使用 TensorFlow Lite Model Maker 库,该库只需几行代码即可简化使用自定义数据集训练 TensorFlow Lite 模型的过程。它使用迁移学习来减少所需的训练数据量和时间。您还可以将适用于音频识别的迁移学习作为迁移学习的一个示例并从中进行学习。
补充阅读和资源
请使用以下资源了解有关音频分类相关概念的更多信息: