
TensorFlow Lite 元数据为模型描述提供了标准。元数据是与模型功能及其输入/输出信息有关的重要信息来源。元数据包含以下两个部分:
- 人员可读部分,用于传达使用模型时的最佳做法,以及
- 机器可读部分,可供诸如 TensorFlow Lite Android 代码生成器和 Android Studio 机器学习绑定特征等代码生成器使用。
TensorFlow Hub 上发布的所有图像模型都已填充元数据。
具有元数据格式的模型
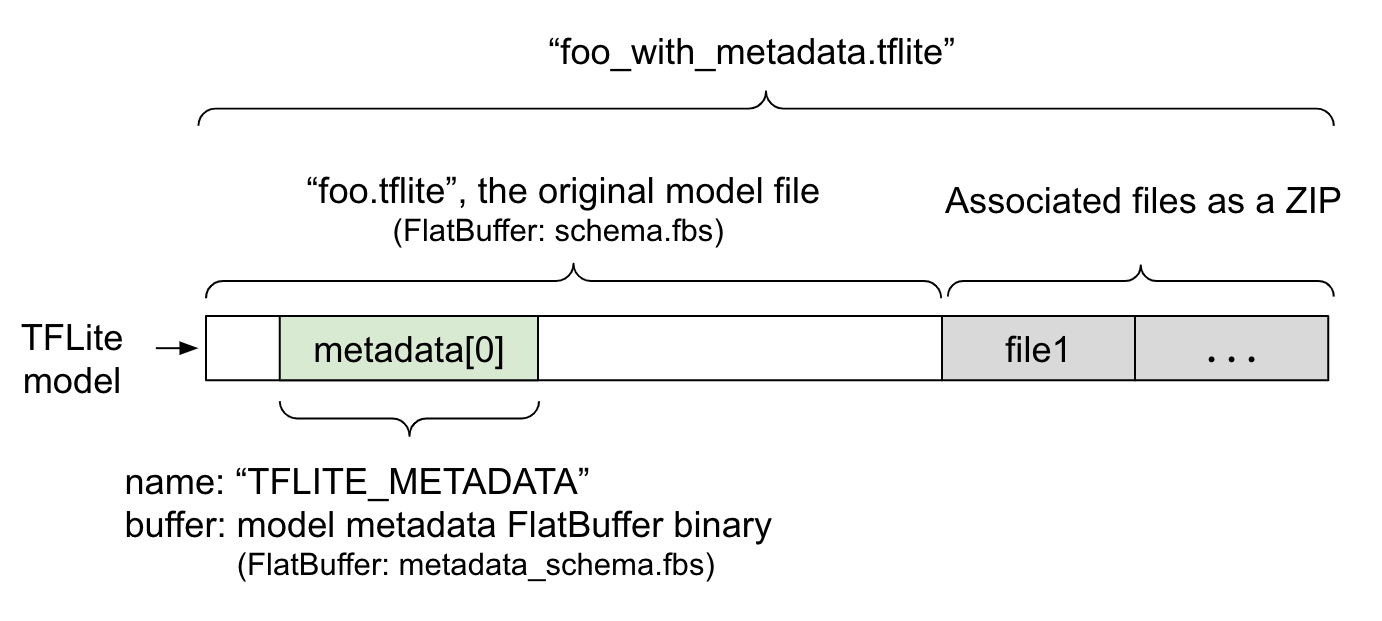
模型元数据在 FlatBuffers 文件 metadata_schema.fbs 中进行定义。如图 1 所示,它以 "TFLITE_METADATA" 的名称存储在 TFLite 模型模式的 metadata 字段中。某些模型可能随附关联文件,例如分类标签文件。这些文件将使用 ZipFile “附加”模式('a' 模式)作为 ZIP 文件连接到原始模型文件的末尾。TFLite 解释器可以像之前一样使用新文件格式。请参阅打包关联文件,了解更多信息。
请参阅以下有关如何填充、呈现和读取元数据的说明。
设置元数据工具
将元数据添加到模型之前,您需要设置 Python 编程环境以便运行 TensorFlow。此处提供了有关设置方法的详细指南。
设置 Python 编程环境后,您将需要安装附加工具:
pip install tflite-support
TensorFlow Lite 元数据工具支持 Python 3。
使用 Flatbuffers Python API 添加元数据
注:要为 TensorFlow Lite Task Library 中支持的常用 ML 任务创建元数据,请使用 TensorFlow Lite Metadata Writer Library 中的高级 API。
模型元数据模式中包含三个部分:
- 模型信息 - 模型的总体说明以及许可条款等项目信息。请参阅 ModelMetadata。
- 输入信息 - 输入以及诸如归一化等所需预处理的描述。请参阅 SubGraphMetadata.input_tensor_metadata。
- 输出信息 - 输出以及诸如标签映射等所需后处理的描述,请参阅 SubGraphMetadata.output_tensor_metadata。
由于 TensorFlow Lite 目前仅支持单一子图,因此在显示元数据和生成代码时,TensorFlow Lite 代码生成器 和 Android Studio 机器学习绑定特征将使用 ModelMetadata.name 和 ModelMetadata.description,而非 SubGraphMetadata.name 和 SubGraphMetadata.description。
支持的输入/输出类型
用于输入和输出的 TensorFlow Lite 元数据在设计时并未考虑特定的模型类型,而是考虑了输入和输出类型。只要输入和输出类型是由以下项目或以下项目的组合构成,TensorFlow Lite 元数据即可支持该模型,无论模型功能如何:
- 特征 - 无符号整数或 float32 类型的数字。
- 图像 - 元数据当前支持 RGB 和灰度图像。
- 边界框 - 矩形边界框。模式支持多种编号方案。
打包关联文件
TensorFlow Lite 模型可能随附不同的关联文件。例如,自然语言模型通常具有可将单词片段映射到单词 ID 的 vocab 文件;分类模型可能具有指示对象类别的标签文件。不使用关联文件(如有),模型将无法正常运行。
现在可以通过元数据 Python 库将关联文件与模型捆绑在一起。新的 TensorFlow Lite 模型现在以包含模型和关联文件的 zip 文件形式提供。该文件可使用常用的 zip 工具进行解包。这种新模型格式沿用了相同的文件扩展名 .tflite。它与现有的 TFLite 框架和解释器兼容。请参阅将元数据和关联文件打包到模型中,了解详细信息。
关联文件信息可以记录在元数据内。根据文件类型和文件附加到的位置(即 ModelMetadata、SubGraphMetadata 和 TensorMetadata),TensorFlow Lite Android 代码生成器可能会将相应的预处理/后处理自动应用于对象。请参阅元数据模式各种关联文件类型的 <Codegen usage> 部分,了解详细信息 。
归一化和量化参数
归一化是机器学习中的常见数据预处理技术。归一化的目标是将值更改为通用的标量,而不会扭曲值范围内的差异。
模型量化技术支持对权重的低精度表示,并可以选择激活存储和计算。
就预处理和后处理而言,归一化和量化是两个独立的步骤。详情如下。
| Normalization | Quantization | |
|---|---|---|
| \ | 浮动模型:\ | 浮动模型:\ |
| : MobileNet 中分别 : - 平均:127.5 \ : - 零点:0 \ : | ||
| : 针对浮点模型和 : - std:127.5 \ : - scale:1.0 \ : | ||
| : 量化模型的 : 量化模型: \ : 量化模型: \ : | ||
| : 输入图像 : - 平均:127.5 \ : - 零点:128.0 \ : | ||
| : 的参数值 : - 标准:127.5 : - 缩放:0.0078125f \ : | ||
| : 示例。 : : : | ||
| \ | \ | 浮动模型 |
| : \ : \ : 不需要量化。\ : | ||
| : \ : 输入:如果在训练中 : 量化模型再预处理/ : | ||
| : \ : 对输入数据进行了 : 后处理中 : | ||
| : When to invoke? : 归一化,则需要对 : 可能需要量化, : | ||
| : : 推断的输入数据 : 也可能不需要量化。具体取决于 : | ||
| : : 执行相应的 : on 输入/输出张量的 : | ||
| : : 归一化。\ : 数据类型。\ : | ||
| : : 输出:输出 : - 浮点张量:预处理/ : | ||
| : : 数据通常 : 后处理中不需要 : | ||
| : : 不进行归一化。 : 进行量化。量化 : | ||
| : : : 运算和去量化运算 : | ||
| : : : 被烘焙到模型 : | ||
| : : : graph. \ : | ||
| : : : - int8/uint8 张量: : | ||
| : : : 需要再预处理/后处理 : | ||
| : : : 中进行量化。 : | ||
| \ | \ | 对输入进行量化: |
| : \ : \ : \ : | ||
| : 公式 : normalized_input = : q = f / scale + : | ||
| : : (输入 - 平均) / 标准 : 零点 \ : | ||
| : : : **对输出进行 : | ||
| : : : outputs**: \ : | ||
| : : : f = (q - 零点) * : | ||
| : : : scale : | ||
| \ | 由模型创建者填充 | 由 TFLite 转换器 |
| : 参数位于 : 并存储在模型 : 自动填充,并 : | ||
| : 什么位置 : 元数据中,作为 : 存储在 tflite 模型 : | ||
: : NormalizationOptions : 文件中。 : |
||
| 如何获得 | 通过 | 通过 TFLite |
: 参数? : MetadataExtractor API : Tensor API [1] 或 : |
||
| : : [2] : 通过 : | ||
: : : MetadataExtractor API : |
||
| : : : [2] : | ||
| 是,浮点和量化 | 是,浮点和量化 | 否,浮动模型 |
| : 模型是否共享相同的 : 模型使用相同的 : 不需要量化。 : | ||
| : 值? : 归一化 : : | ||
| : : parameters : : | ||
| TFLite 代码 | \ | \ |
| : 生成器或 Android : 是 : 是 : | ||
| : Studio 机器学习绑定 : : : | ||
| : 是否会在数据处理过程中 : : : | ||
| : 自动生成参数? : : : |
[1] TensorFlow Lite Java API 和 TensorFlow Lite C++ API。
[2] Metadata Extractor 库
针对 uint8 模型处理图像数据时,有时可以跳过归一化和量化步骤。当像素值在 [0, 255] 区间内时可以跳过。但通常来说,如果适用,应始终根据归一化和量化参数处理数据。
如果您在元数据中设置了 NormalizationOptions,则 TensorFlow Lite Task Library 可以为您处理归一化。量化和反量化处理始终被封装在一起。
示例
注:在运行脚本之前,指定的导出目录必须已存在;过程中不会创建目录。
您可以在此处找到有关如何针对不同类型的模型填充元数据的示例:
图像分类
在此处下载用于将元数据填充至 mobilenet_v1_0.75_160_quantized.tflite 的脚本。通过如下方法运行脚本:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
要针对其他图像分类模型填充元数据,请将与此类似的模型规范添加到脚本中。本指南其余部分将重点介绍图像分类示例中的一些关键部分,以说明关键要素。
深入了解图像分类示例
模型信息
元数据首先需要创建新的模型信息:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
输入/输出信息
本节向您展示如何描述模型的输入和输出签名。自动代码生成器可以使用此元数据来创建预处理和后处理代码。要创建有关张量的输入或输出信息:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
图像输入
图像是机器学习的常见输入类型。TensorFlow Lite 元数据支持色彩空间等信息以及归一化等预处理信息。不需要手动指定图像尺寸,因为输入张量的形状已提供了该信息,并且可以自动推断。
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
标签输出
可以使用 TENSOR_AXIS_LABELS 通过关联文件将标签映射到输出张量。
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
创建元数据 FlatBuffers
以下代码可将模型信息与输入和输出信息组合在一起:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
将元数据和关联文件打包到模型中
在元数据 FlatBuffers 创建完成后,元数据和标签文件即可通过 populate 方法写入到 TFLite 文件中:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
您可以通过 load_associated_files 将所需数量的关联文件打包到模型中。但是,至少须对元数据内记录的文件进行打包。在本例中,必须对标签文件进行打包。
呈现元数据
您可以使用 Netron 呈现您的元数据,也可以使用 MetadataDisplayer 将 TensorFlow Lite 模型中的元数据读取为 json 格式:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio 还支持通过 Android Studio 机器学习绑定功能显示元数据。
元数据版本控制
元数据模式的版本控制可通过跟踪模式文件变更的语义化版本控制编号以及指示真实版本兼容性的 FlatBuffers 文件标识予以实现。
语义化版本控制编号
元数据模式可以通过诸如 MAJOR.MINOR.PATCH 等语义化版本控制编号实现版本控制。它可以依据此处所述规则跟踪模式变更。请参阅 1.0.0 版本之后添加的字段历史记录。
FlatBuffers 文件标识
在符合规则的情况下,语义化版本控制能够保证兼容性,但无法指示真实版本的不兼容性。当 MAJOR 编号增大时,不一定表示向后兼容性被破坏。因此,我们使用 FlatBuffers 文件标识 (file_identifiler) 来表示元数据模式的真实兼容性。文件标识符长度为 4 个字符。该长度对于特定元数据模式是固定的,不支持用户更改。如果出于某种原因必须破坏元数据模式的向后兼容性,则 file_identifier 将增大(例如从“M001”变为“M002”)。与 metadata_version 相比,file_identifiler 的预期变更频率要低得多。
所需元数据解析器最低版本
所需元数据解析器最低版本是可以完整读取元数据 FlatBuffers 的元数据解析器(FlatBuffers 生成的代码)的最低版本。该版本实际上是填充了所有字段的版本中编号最大的版本,同时也是文件标识符所指示的最小的兼容版本。当将元数据填充到 TFLite 模型中时,所需元数据解析器最低版本将由 MetadataPopulator 自动填充。有关如何使用所需元数据解析器最低版本的更多信息,请参阅元数据提取器。
从模型中读取元数据
Metadata Extractor 库是从不同平台的模型中读取元数据和关联文件的便捷工具(请参阅 Java 版本和 C++ 版本)。您可以使用 FlatBuffers 库以其他语言构建自己的元数据提取工具。
读取以 Java 编写的元数据
要在您的 Android 应用中使用 Metadata Extractor 库,我们建议使用托管在 MavenCentral 上的 TensorFlow Lite Metadata AAR。它包含 MetadataExtractor 类,以及针对元数据模式和模型模式的 FlatBuffers Java 绑定。
您可以在 build.gradle 依赖项中加以指定,如下所示:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
要使用 Nightly 快照,请确保您已添加 Sonatype 快照存储库。
您可以使用指向模型的 ByteBuffer 来初始化 MetadataExtractor 对象:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer 在 MetadataExtractor 对象的整个生命周期中必须保持不变。如果模型元数据的 FlatBuffers 文件标识符与元数据解析器的标识符不匹配,则初始化可能会失败。请参阅元数据版本控制,了解更多信息。
在文件标识符匹配的情况下,由于 FlatBuffers 的向前和向后兼容机制,元数据提取器将能成功读取所有由过去和未来模式生成的元数据。但是,来自未来模式的字段不能被旧的元数据提取器提取。元数据的所需元数据解析器最低版本指示了能够完整读取元数据 FlatBuffers 的元数据解析器的最低版本。您可以使用以下方法来验证是否满足所需元数据解析器最低版本的条件:
public final boolean isMinimumParserVersionSatisfied();
允许传入没有元数据的模型。但是,调用从元数据读取的方法将导致运行时错误。您可以通过调用 hasMetadata 方法来检查模型是否有元数据:
public boolean hasMetadata();
MetadataExtractor 为您提供了获取输入/输出张量元数据的便捷功能。例如,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
尽管 TensorFlow Lite 模型模式支持多个子计算图,但 TFLite 解释器当前仅支持单个子计算图。因此,MetadataExtractor 在其方法中省略了子计算图索引作为输入参数。
从模型中读取关联文件
包含元数据和关联文件的 TensorFlow Lite 模型本质上是 zip 文件,可以用常见的 zip 工具解包得到关联文件。例如,可以解压 mobilenet_v1_0.75_160_quantized 并提取模型中的标签文件,如下所示:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
您还可以通过 Metadata Extractor 库读取关联文件。
在 Java 中,可以将文件名传递到 MetadataExtractor.getAssociatedFile 方法中:
public InputStream getAssociatedFile(String fileName);
同样,在 C++ 中,可以通过 ModelMetadataExtractor::GetAssociatedFile 方法来实现:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;