
| |
 在 Github 上查看源代码 在 Github 上查看源代码 |
|
|
为设备端 ML 应用部署此模型时,TensorFlow Lite Model Maker 库可以简化将 TensorFlow 神经网络模型适配和转换为特定输入数据的过程。
此笔记本展示了一个端到端示例,该示例使用 Model Maker 库演示了如何调整和转换在移动设备上对花卉进行分类的常用图像分类模型。
前提条件
要运行此示例,我们首先需要安装几个所需的软件包,包括 GitHub 仓库中的 Model Maker 软件包。
sudo apt -y install libportaudio2pip install -q tflite-model-maker
导入所需的软件包。
import os
import numpy as np
import tensorflow as tf
assert tf.__version__.startswith('2')
from tflite_model_maker import model_spec
from tflite_model_maker import image_classifier
from tflite_model_maker.config import ExportFormat
from tflite_model_maker.config import QuantizationConfig
from tflite_model_maker.image_classifier import DataLoader
import matplotlib.pyplot as plt
简单的端到端示例
获取数据路径
让我们获取一些图像来试验一下这个简单的端到端示例。对 Model Maker 来说,数百个图像是好的开始,但更多数据可以获得更高的准确率。
image_path = tf.keras.utils.get_file(
'flower_photos.tgz',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
extract=True)
image_path = os.path.join(os.path.dirname(image_path), 'flower_photos')
您可以将 image_path 替换为自己的图像文件夹。对于将数据上传到 Colab,您可以在左侧边栏中找到上传按钮(如下图中的红色方框所示)。您可以尝试上传一个 Zip 文件并将其解压缩。根文件路径为当前路径。
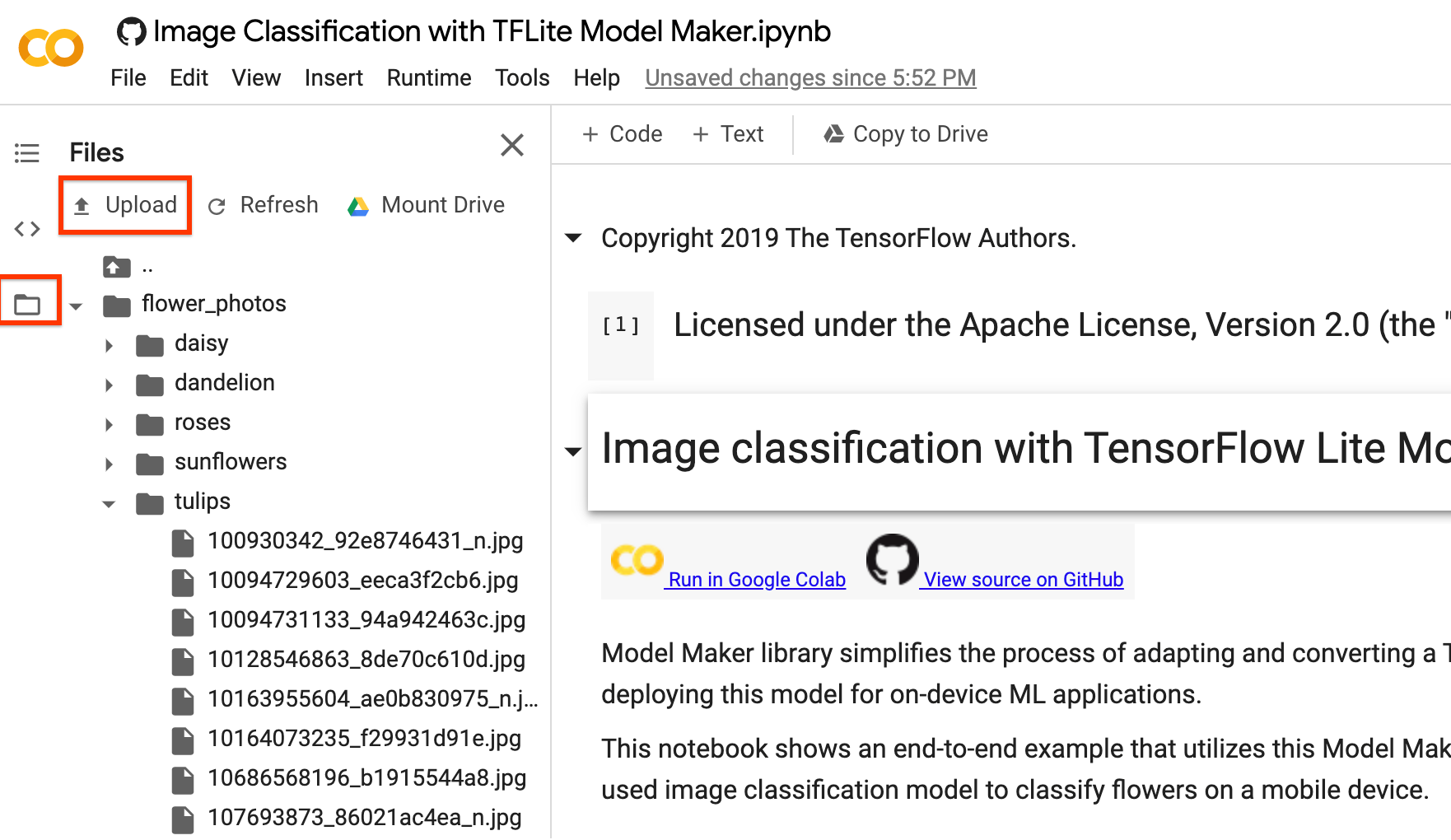
如果您不想将图像上传到云端,也可以按照 GitHub 中的指南尝试在本地运行库。
运行示例
如下所示,该示例包含 4 行代码,每行代码表示整个过程中的一个步骤。
第 1 步:加载特定于设备端 ML 应用的输入数据,并将其拆分为训练数据和测试数据。
data = DataLoader.from_folder(image_path)
train_data, test_data = data.split(0.9)
第 2 步:自定义 TensorFlow 模型。
model = image_classifier.create(train_data)
第 3 步:评估模型。
loss, accuracy = model.evaluate(test_data)
第 4 步:导出为 TensorFlow Lite 模型。
在这里,我们导出带有元数据的 TensorFlow Lite 模型,它提供了模型描述的标准。标签文件嵌入在元数据中。默认的训练后量化技术是图像分类任务的全整数量化。
与上传部分相同,您可以在左侧边栏下载它供您自己使用。
model.export(export_dir='.')
完成上述 4 个简单步骤后,我们可以在设备端应用(如图像分类参考应用)中进一步使用 TensorFlow Lite 模型文件。
详细流程
目前,我们支持多种用于图像分类的预训练模型(例如 EfficientNet-Lite*、MobileNetV2 和 ResNet50 模型)。向此库添加新的预训练模型也很灵活,您只需编写几行代码。
下文对此端到端示例进行了逐步介绍,以展示更多详细信息。
第 1 步:加载特定于设备端 ML 应用的输入数据
花卉数据集包含分属于 5 个类的 3670 个图像。下载数据集的存档版本并解压缩。
该数据集具有以下目录结构:
<b>flower_photos</b>
|__ <b>daisy</b>
|______ 100080576_f52e8ee070_n.jpg
|______ 14167534527_781ceb1b7a_n.jpg
|______ ...
|__ <b>dandelion</b>
|______ 10043234166_e6dd915111_n.jpg
|______ 1426682852_e62169221f_m.jpg
|______ ...
|__ <b>roses</b>
|______ 102501987_3cdb8e5394_n.jpg
|______ 14982802401_a3dfb22afb.jpg
|______ ...
|__ <b>sunflowers</b>
|______ 12471791574_bb1be83df4.jpg
|______ 15122112402_cafa41934f.jpg
|______ ...
|__ <b>tulips</b>
|______ 13976522214_ccec508fe7.jpg
|______ 14487943607_651e8062a1_m.jpg
|______ ...
image_path = tf.keras.utils.get_file(
'flower_photos.tgz',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
extract=True)
image_path = os.path.join(os.path.dirname(image_path), 'flower_photos')
使用 DataLoader 类加载数据。
对于 from_folder() 方法,它可以从文件夹加载数据。它假定同一类的图像数据位于相同的子目录中,且子文件夹名称为类名称。目前支持 JPEG 编码的图像和 PNG 编码的图像。
data = DataLoader.from_folder(image_path)
将它拆分为训练数据 (80%)、验证数据(10%,可选)和测试数据 (10%)。
train_data, rest_data = data.split(0.8)
validation_data, test_data = rest_data.split(0.5)
显示 25 个带标签的图像样本。
plt.figure(figsize=(10,10))
for i, (image, label) in enumerate(data.gen_dataset().unbatch().take(25)):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(image.numpy(), cmap=plt.cm.gray)
plt.xlabel(data.index_to_label[label.numpy()])
plt.show()
第 2 步:自定义 TensorFlow 模型
根据加载的数据创建自定义图像分类器模型。默认模型为 EfficientNet-Lite0。
model = image_classifier.create(train_data, validation_data=validation_data)
看一下详细的模型结构。
model.summary()
第 3 步:评估自定义的模型
评估模型的结果,获得模型的损失和准确率。
loss, accuracy = model.evaluate(test_data)
我们可以对 100 个测试图像的预测结果进行绘制。红色的预测标签为错误的预测结果,其余为正确的预测。
# A helper function that returns 'red'/'black' depending on if its two input
# parameter matches or not.
def get_label_color(val1, val2):
if val1 == val2:
return 'black'
else:
return 'red'
# Then plot 100 test images and their predicted labels.
# If a prediction result is different from the label provided label in "test"
# dataset, we will highlight it in red color.
plt.figure(figsize=(20, 20))
predicts = model.predict_top_k(test_data)
for i, (image, label) in enumerate(test_data.gen_dataset().unbatch().take(100)):
ax = plt.subplot(10, 10, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(image.numpy(), cmap=plt.cm.gray)
predict_label = predicts[i][0][0]
color = get_label_color(predict_label,
test_data.index_to_label[label.numpy()])
ax.xaxis.label.set_color(color)
plt.xlabel('Predicted: %s' % predict_label)
plt.show()
如果准确率不符合应用要求,可以参考高级用法来探索替代方法(例如更改为更大的模型、调整重新训练参数等)。
第 4 步:导出为 TensorFlow Lite 模型
将经过训练的模型转换为带有元数据的 TensorFlow Lite 模型格式,以便您以后可以在设备端 ML 应用中使用。标签文件和词汇文件嵌入在元数据中。默认的 TFLite 文件名是 model.tflite。
在许多设备端 ML 应用中,模型大小是一个重要因素。因此,建议您应用量化模型以使其更小并可能加快运行速度。对于图像分类任务,默认的训练后量化技术是全整数量化。
model.export(export_dir='.')
有关如何将 TensorFlow Lite 模型集成到移动应用中的更多详细信息,请参阅图片分类示例指南。
可以使用 TensorFlow Lite Task Library 的 ImageClassifier API 将此模型集成到 Android 或 iOS 应用中。
允许的导出格式可以是以下列表中的一个或多个:
默认情况下,它仅导出带有元数据的 TensorFlow Lite 模型。您也可以有选择地导出不同的文件。例如,仅导出标签文件,如下所示:
model.export(export_dir='.', export_format=ExportFormat.LABEL)
您还可以使用 evaluate_tflite 方法评估 tflite 模型。
model.evaluate_tflite('model.tflite', test_data)
高级用法
create 函数是此库的关键部分。它使用迁移学习以及与教程类似的预训练模型。
create 函数包含以下步骤:
- 根据参数
validation_ratio和test_ratio将数据拆分为训练数据、验证数据和测试数据。validation_ratio和test_ratio的默认值分别是0.1和0.1。 - 从 TensorFlow Hub 下载图像特征向量作为基础模型。默认的预训练模型是 EfficientNet-Lite0。
- 在头层和预训练模型之间添加一个包含带
dropout_rate的随机失活层的分类器头。默认的dropout_rate是 TensorFlow Hub 上 make_image_classifier_lib 中的默认dropout_rate值。 - 预处理原始输入数据。目前,预处理步骤包括将每个图像像素的值归一化为模型输入尺度,并将其调整为模型输入大小。EfficientNet-Lite0 的输入尺度为
[0, 1],输入图像大小为[224, 224, 3]。 - 将数据馈送到分类器模型中。默认情况下,训练参数(例如训练周期、批次大小、学习率、动量)是 TensorFlow Hub 上 make_image_classifier_lib 中的默认值。只有分类器头经过了训练。
在本部分中,我们介绍了几个高级主题,包括切换到不同的图像分类器模型、更改训练超参数等。
在 TensorFlow Lite 模型上自定义训练后量化
训练后量化是一种转换技术,可以缩减模型大小并缩短推断延迟,同时改善 CPU 和硬件加速器推断速度,且几乎不会降低模型准确率。因此,它被广泛用于优化模型。
Model Maker 库在导出模型时会应用默认的训练后量化技术。如果您想自定义训练后量化,Model Maker 也支持使用 QuantizationConfig 的多个训练后量化选项。我们以 float16 量化为例。首先,定义量化配置。
config = QuantizationConfig.for_float16()
然后,我们使用此配置导出 TensorFlow Lite 模型。
model.export(export_dir='.', tflite_filename='model_fp16.tflite', quantization_config=config)
在 Colab 中,您可以从左侧边栏下载名为 model_fp16.tflite 的模型,与上文中的上传部分相同。
更改模型
更改为此库所支持的模型。
此库目前支持 EfficientNet-Lite、MobileNetV2 和 ResNet50 模型。EfficientNet-Lite 是一系列图像分类模型,可以实现最先进的准确率,并适用于 Edge 设备。默认模型为 EfficientNet-Lite0。
我们只需将 create 方法中的参数 model_spec 设置为 MobileNetV2 模型规范,即可将模型切换为 MobileNetV2。
model = image_classifier.create(train_data, model_spec=model_spec.get('mobilenet_v2'), validation_data=validation_data)
评估新近重新训练的 MobileNetV2 模型,查看测试数据中的准确率和损失。
loss, accuracy = model.evaluate(test_data)
更改为 TensorFlow Hub 中的模型
此外,我们还可以切换为其他新模型,这些模型输入图像并输出具有 TensorFlow Hub 格式的特征向量。
以 Inception V3 模型为例,我们可以定义 inception_v3_spec,它是 image_classifier.ModelSpec 的对象,且包含 Inception V3 模型的规范。
我们需要指定模型名称 name,以及 TensorFlow Hub 模型的网址 uri。同时,input_image_shape 的默认值为 [224, 224]。对于 Inception V3 模型,我们需要将其更改为 [299, 299]。
inception_v3_spec = image_classifier.ModelSpec(
uri='https://tfhub.dev/google/imagenet/inception_v3/feature_vector/1')
inception_v3_spec.input_image_shape = [299, 299]
然后,将 create 方法中的参数 model_spec 设置为 inception_v3_spec,我们便可重新训练 Inception V3 模型。
其余步骤完全相同,最后我们可以获得自定义的 InceptionV3 TensorFlow Lite 模型。
更改您的自定义模型
如果我们想使用 TensorFlow Hub 中没有的自定义模型,应在 TensorFlow Hub 中创建并导出 ModelSpec。
然后像上面的过程一样开始定义 ModelSpec 对象。
更改训练超参数
我们还可以更改训练超参数(如 epochs、dropout_rate 和 batch_size),它们可能会影响模型的准确率。可以调整的模型参数包括:
epochs:更多的周期可能会获得更高的准确率,直到收敛为止,但训练的周期过多可能会导致过拟合。dropout_rate:随机失活率,避免过拟合。默认为 None。batch_size:在一个训练步骤中使用的样本数。默认为 None。validation_data:验证数据。如果为 None,则跳过验证过程。默认为 None。train_whole_model:如果为 True,则将 Hub 模块与顶部的分类层一起训练。否则,仅训练顶部分类层。默认为 None。learning_rate:基础学习率。默认为 None。momentum:转发给优化器的 Python 浮点数。仅在use_hub_library为 True 时使用。默认为 None。shuffle:布尔值,表示是否应对数据进行乱序。默认为 False。use_augmentation:布尔值,使用数据增强进行预处理。默认为 False。use_hub_library:布尔值,使用来自 TensorFlow Hub 的make_image_classifier_lib重新训练模型。对于具有多个类别的复杂数据集,此训练流水线可以实现更好的性能。默认为 True。warmup_steps:用于学习率预热计划的预热步骤数。如果为 None,则使用默认的 warmup_steps,它是两个周期中的总训练步数。仅当use_hub_library为 False 时使用。默认为 None。model_dir: 可选,模型检查点文件的位置。仅当use_hub_library为 False 时使用。默认为 None。
默认为 None 的参数(如 epochs),将从 TensorFlow Hub 库或 train_image_classifier_lib 获取 make_image_classifier_lib 中的具体默认参数。
例如,我们可以进行更多周期的训练。
model = image_classifier.create(train_data, validation_data=validation_data, epochs=10)
使用 10 个训练周期评估新近重新训练的模型。
loss, accuracy = model.evaluate(test_data)
阅读更多
您可以阅读我们的图像分类示例以了解技术细节。如需了解更多信息,请参阅:
- TensorFlow Lite Model Maker 指南和 API 参考。
- Task Library:用于部署的 ImageClassifier。
- 端到端参考应用: Android、 iOS 和 Raspberry PI。