

ビデオ分類は、ビデオが何を表しているかを識別する機械学習タスクです。ビデオ分類モデルは、さまざまなアクションや動きなどの固有のクラスのセットを含むビデオ データセットでトレーニングされます。モデルはビデオ フレームを入力として受け取り、ビデオ内で表現される各クラスの確率を出力します。
ビデオ分類モデルと画像分類モデルは両方とも、事前定義されたクラスに属する画像の確率を予測するための入力として画像を使用します。ただし、ビデオ分類モデルは、ビデオ内のアクションを認識するために、隣接するフレーム間の時空間関係も処理します。
たとえば、ビデオ動作認識モデルをトレーニングして、走る、拍手する、手を振るなどの人間の動作を識別することができます。次の画像は、Android でのビデオ分類モデルの出力を示しています。
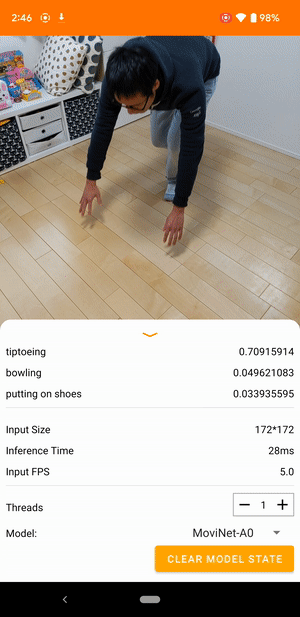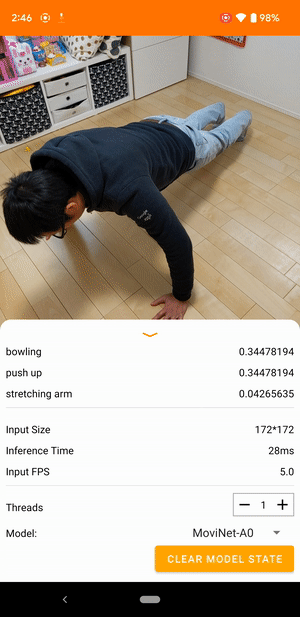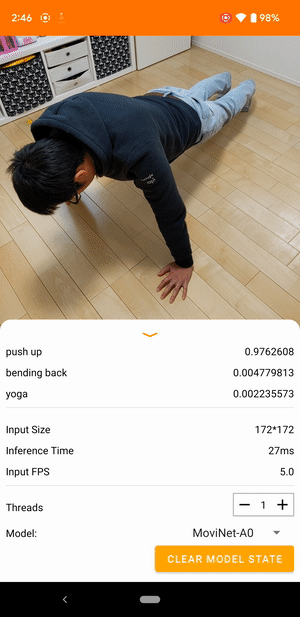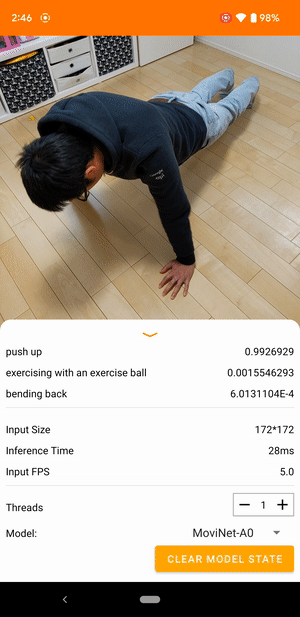
始めましょう
Android または Raspberry Pi 以外のプラットフォームを使用している場合、またはすでにTensorFlow Lite APIに精通している場合は、スターター ビデオ分類モデルとサポート ファイルをダウンロードしてください。 TensorFlow Lite サポート ライブラリを使用して独自のカスタム推論パイプラインを構築することもできます。
TensorFlow Lite を初めて使用し、Android または Raspberry Pi を使用している場合は、開始に役立つ次のサンプル アプリケーションを検討してください。
アンドロイド
Android アプリケーションは、デバイスの背面カメラを使用して継続的なビデオ分類を行います。推論はTensorFlow Lite Java APIを使用して実行されます。デモ アプリはフレームを分類し、予測された分類をリアルタイムで表示します。
ラズベリーパイ
Raspberry Pi の例では、TensorFlow Lite と Python を使用して、連続ビデオ分類を実行します。 Raspberry Pi を Pi Camera などのカメラに接続して、リアルタイムのビデオ分類を実行します。カメラからの結果を表示するには、モニターを Raspberry Pi に接続し、SSH を使用して Pi シェルにアクセスします (キーボードを Pi に接続することを避けるため)。
開始する前に、Raspberry Pi OS (できれば Buster に更新) を使用して Raspberry Pi をセットアップします。
モデルの説明
モバイル ビデオ ネットワーク ( MoViNets ) は、モバイル デバイス用に最適化された効率的なビデオ分類モデルのファミリーです。 MoViNet は、いくつかの大規模なビデオ アクション認識データセットで最先端の精度と効率を実証しており、ビデオ アクション認識タスクに最適です。
TensorFlow Lite のMoviNetモデルには、 MoviNet-A0 、 MoviNet-A1 、およびMoviNet-A2の 3 つのバリアントがあります。これらのバリアントは、600 の異なる人間の動作を認識するために、 Kinetics-600データセットを使用してトレーニングされました。 MoviNet-A0は最小、最速、精度が最も低くなります。 MoviNet-A2は最大で、最も遅く、最も正確です。 MoviNet-A1 は、 A0 と A2 の間の妥協点です。
使い方
トレーニング中に、ビデオ分類モデルにはビデオとそれに関連付けられたラベルが提供されます。各ラベルは、モデルが認識することを学習する個別の概念またはクラスの名前です。ビデオ アクション認識の場合、ビデオは人間のアクションのものとなり、ラベルは関連するアクションになります。
ビデオ分類モデルは、新しいビデオがトレーニング中に提供されるクラスのいずれかに属するかどうかを予測することを学習できます。このプロセスは推論と呼ばれます。転移学習を使用して、既存のモデルを使用して新しいクラスのビデオを識別することもできます。
このモデルは、連続ビデオを受信し、リアルタイムで応答するストリーミング モデルです。モデルはビデオ ストリームを受信すると、トレーニング データセットのいずれかのクラスがビデオ内で表現されているかどうかを識別します。モデルはフレームごとに、ビデオがそのクラスを表す確率とともにこれらのクラスを返します。特定の時点での出力例は次のようになります。
| アクション | 確率 |
|---|---|
| スクエアダンス | 0.02 |
| 糸通し針 | 0.08 |
| 指をいじる | 0.23 |
| 手を振る | 0.67 |
出力内の各アクションは、トレーニング データ内のラベルに対応します。確率は、アクションがビデオに表示される可能性を示します。
モデル入力
モデルは、RGB ビデオ フレームのストリームを入力として受け入れます。入力ビデオのサイズは柔軟ですが、理想的にはモデルのトレーニング解像度とフレームレートに一致します。
- MoviNet-A0 : 5 fps で 172 x 172
- MoviNet-A1 : 5 fps で 172 x 172
- MoviNet-A1 : 224 x 224、5 fps
入力ビデオは、一般的な画像入力規則に従って、0 から 1 の範囲内のカラー値を持つことが期待されます。
モデルは内部的に、前のフレームで収集された情報を使用して各フレームのコンテキストも分析します。これは、モデル出力から内部状態を取得し、それを今後のフレームのモデルにフィードバックすることによって実現されます。
モデルの出力
モデルは、一連のラベルとそれに対応するスコアを返します。スコアは、各クラスの予測を表すロジット値です。これらのスコアは、softmax 関数 ( tf.nn.softmax ) を使用して確率に変換できます。
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
内部的には、モデル出力にはモデルの内部状態も含まれており、それが今後のフレームのモデルにフィードバックされます。
パフォーマンスのベンチマーク
パフォーマンス ベンチマーク数値は、ベンチマーク ツールを使用して生成されます。 MoviNet は CPU のみをサポートします。
モデルのパフォーマンスは、モデルが特定のハードウェア上で推論を実行するのにかかる時間によって測定されます。時間が短いほど、モデルが高速であることを意味します。精度は、モデルがビデオ内のクラスを正しく分類する頻度によって測定されます。
| モデル名 | サイズ | 正確さ * | デバイス | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (整数量子化) | 3.1MB | 65% | ピクセル4 | 5ミリ秒 |
| ピクセル3 | 11ミリ秒 | |||
| MoviNet-A1 (整数量子化) | 4.5MB | 70% | ピクセル4 | 8ミリ秒 |
| ピクセル3 | 19ミリ秒 | |||
| MoviNet-A2 (整数量子化) | 5.1MB | 72% | ピクセル4 | 15ミリ秒 |
| ピクセル3 | 36ミリ秒 |
* Kinetics-600データセットで測定されたトップ 1 の精度。
** 遅延は 1 スレッドの CPU で実行したときに測定されました。
モデルのカスタマイズ
事前トレーニングされたモデルは、 Kinetics-600データセットから 600 の人間の動作を認識するようにトレーニングされています。転移学習を使用してモデルを再トレーニングし、元のセットにない人間の行動を認識することもできます。これを行うには、モデルに組み込む新しいアクションごとに一連のトレーニング ビデオが必要です。
カスタム データのモデルの微調整の詳細については、 MoViNets リポジトリとMoViNets チュートリアルを参照してください。
さらに詳しい資料とリソース
このページで説明する概念について詳しくは、次のリソースを使用してください。