
使用图形处理单元 (GPU) 运行机器学习 (ML) 模型可以显著改善模型的性能和支持 ML 的应用的用户体验。在 iOS 设备上,您可以使用委托启用对模型的 GPU 加速执行。委托充当 TensorFlow Lite 的硬件驱动程序,允许您在 GPU 处理器上运行模型的代码。
本页介绍了如何在 iOS 应用中为 TensorFlow Lite 模型启用 GPU 加速。有关将 GPU 委托用于 TensorFlow Lite 的更多信息,包括最佳做法和高级技术,请参阅 GPU 委托页面。
将 GPU 与 Interpreter API 结合使用
TensorFlow Lite Interpreter API 提供了一组用于构建机器学习应用的通用 API。以下说明指导您如何将 GPU 支持添加到 iOS 应用。本指南假设您已经拥有一个可以使用 TensorFlow Lite 成功执行 ML 模型的 iOS 应用。
注:如果您还没有使用 TensorFlow Lite 的 iOS 应用,请按照 iOS 快速入门操作来构建演示应用。完成本教程后,您可以按照这些说明启用 GPU 支持。
修改 Podfile 以包含 GPU 支持
从 TensorFlow Lite 2.3.0 版本开始,会从 Pod 中排除 GPU 委托,以缩减二进制文件的大小。您可以通过为 TensorFlowLiteSwift Pod 指定子规范来包含它们:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
或者
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
如果您想使用 Objective-C(2.4.0 及更高版本)或 C API,也可以使用 TensorFlowLiteObjC 或 TensorFlowLiteC。
注:对于 TensorFlow Lite 版本 2.1.0 到 2.2.0,TensorFlowLiteC Pod 中已包含 GPU 委托。您可以根据使用的编程语言在 TensorFlowLiteC 和 TensorFlowLiteSwift 之间进行选择。
初始化和使用 GPU 委托
您可以将 GPU 委托与具有多种编程语言的 TensorFlow Lite Interpreter API 一起使用。建议使用 Swift 和 Objective-C,但您也可以使用 C++ 和 C。如果您使用 2.4 版本之前的 TensorFlow Lite,则需要使用 C。以下代码示例概述了如何将委托与这些语言中的每一种一起使用。
Swift
import TensorFlowLite // Load model ... // Initialize TensorFlow Lite interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Objective-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
C++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C(2.4.0 之前)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
GPU API 语言使用说明
- 2.4.0 版本之前的 TensorFlow Lite 只能使用 Objective-C 的 C API。
- 仅当您使用 Bazel 或自行构建 TensorFlow Lite 时,C++ API 才可用。C++ API 不能与 CocoaPods 一起使用。
- 将具有 C++ 的 GPU 委托与 TensorFlow Lite 一起使用时,请通过
TFLGpuDelegateCreate()函数获取 GPU 委托,然后将其传递给Interpreter::ModifyGraphWithDelegate(),而不是调用Interpreter::AllocateTensors()。
使用发布模式构建和测试
使用适当的 Metal API 加速器设置更改为发布构建以获得更好的性能并进行最终测试。本部分介绍如何启用发布构建和配置 Metal 加速设置。
注:这些说明要求 XCode v10.1 或更高版本。
要更改为发布构建,请执行以下操作:
- 通过选择 Product > Scheme > Edit Scheme... 编辑构建设置,然后选择 Run。
- 在 Info 标签页上,将 Build Configuration 更改为 Release 并取消选中 Debug executable。
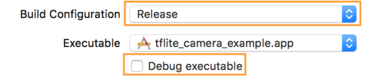
- 点击
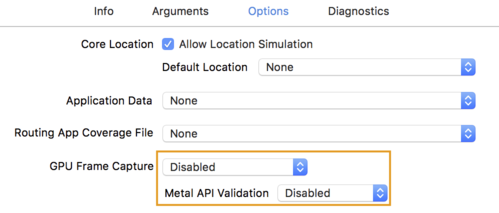
Options标签页并将GPU Frame Capture更改为Disabled,将Metal API Validation更改为Disabled。
- 确保在 64 位架构上选择仅发布构建。在 Project navigator > tflite_camera_example > PROJECT > your_project_name > Build Settings 下,将 Build Active Architecture Only > Release 设置为 Yes。

高级 GPU 支持
本部分介绍 iOS 的 GPU 委托的高级用法,包括委托选项、输入和输出缓冲区以及量化模型的使用。
iOS 委托选项
GPU 委托的构造函数接受 Swift API、Objective-C API 和 C API 中选项的 struct。向初始值设定项传递 nullptr (C API) 或不传递任何内容(Objective-C 和 Swift API)即可设置默认选项(上方“基本用法”示例已作说明)。
Swift
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Objective-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
C
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
提示:尽管使用 nullptr 或默认构造函数十分方便,但您应当显式设置选项,以避免将来因更改默认值而发生任何意外行为。
使用 C++ API 的输入/输出缓冲区
GPU 上的计算要求数据对 GPU 可用。此要求通常意味着必需执行内存复制。如果可能,您应该避免让数据越过 CPU/GPU 内存边界,因为这会占用大量时间。通常,这种越界是不可避免的,但在某些特殊情况下却可以忽略其中一种内存。
注:仅当您使用 Bazel 或自行构建 TensorFlow Lite 时,以下技术才可用。C++ API 不能与 CocoaPods 一起使用。
如果网络的输入为 GPU 内存中已加载的图像(例如,包含摄像头画面的 GPU 纹理),则它可以驻留在 GPU 内存中而无需进入 CPU 内存。同样,如果网络的输出为可渲染图像形式(例如,图像风格转换运算),则可以直接在屏幕上显示结果。
为了获得最佳性能,TensorFlow Lite 使用户可以直接从 TensorFlow 硬件缓冲区读取和写入数据,并绕过可避免的内存复制过程。
假设图像输入位于 GPU 内存中,则必须首先将其转换为 Metal 的 MTLBuffer 对象。您可以使用 TFLGpuDelegateBindMetalBufferToTensor() 将 TfLiteTensor 关联至用户准备的 MTLBuffer。请注意,必须在 Interpreter::ModifyGraphWithDelegate() 之后调用此函数。此外,在默认情况下,推断输出会从 GPU 内存复制到 CPU 内存。可以通过在初始化期间调用 Interpreter::SetAllowBufferHandleOutput(true) 来关闭此行为。
C++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
关闭默认行为后,将推断输出从 GPU 内存复制到 CPU 内存需要为每个输出张量显式调用 Interpreter::EnsureTensorDataIsReadable()。这种方法也适用于量化模型,但您仍然需要使用 float32 大小的缓冲区和 float32 数据,因为缓冲区绑定到内部去量化缓冲区。
量化模型
iOS GPU 委托库默认支持量化模型。您无需更改任何代码即可将量化模型与 GPU 委托一起使用。以下部分说明了如何停用量化支持以用于测试或实验目的。
停用量化模型支持
以下代码显示了如何停用对量化模型的支持。
Swift
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Objective-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
C
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
有关使用 GPU 加速运行量化模型的更多信息,请参阅 GPU 委托概述。