

وظیفه شناسایی آنچه که یک صدا نشان دهنده آن است طبقه بندی صدا نامیده می شود. یک مدل طبقه بندی صوتی برای تشخیص رویدادهای صوتی مختلف آموزش داده شده است. برای مثال، میتوانید مدلی را برای تشخیص رویدادهایی که سه رویداد مختلف را نشان میدهند، آموزش دهید: کف زدن، ضربه زدن انگشت، و تایپ کردن. TensorFlow Lite مدل های از پیش آموزش دیده بهینه شده ای را ارائه می دهد که می توانید آنها را در برنامه های تلفن همراه خود مستقر کنید. درباره طبقه بندی صدا با استفاده از TensorFlow در اینجا بیشتر بیاموزید.
تصویر زیر خروجی مدل طبقه بندی صدا در اندروید را نشان می دهد.
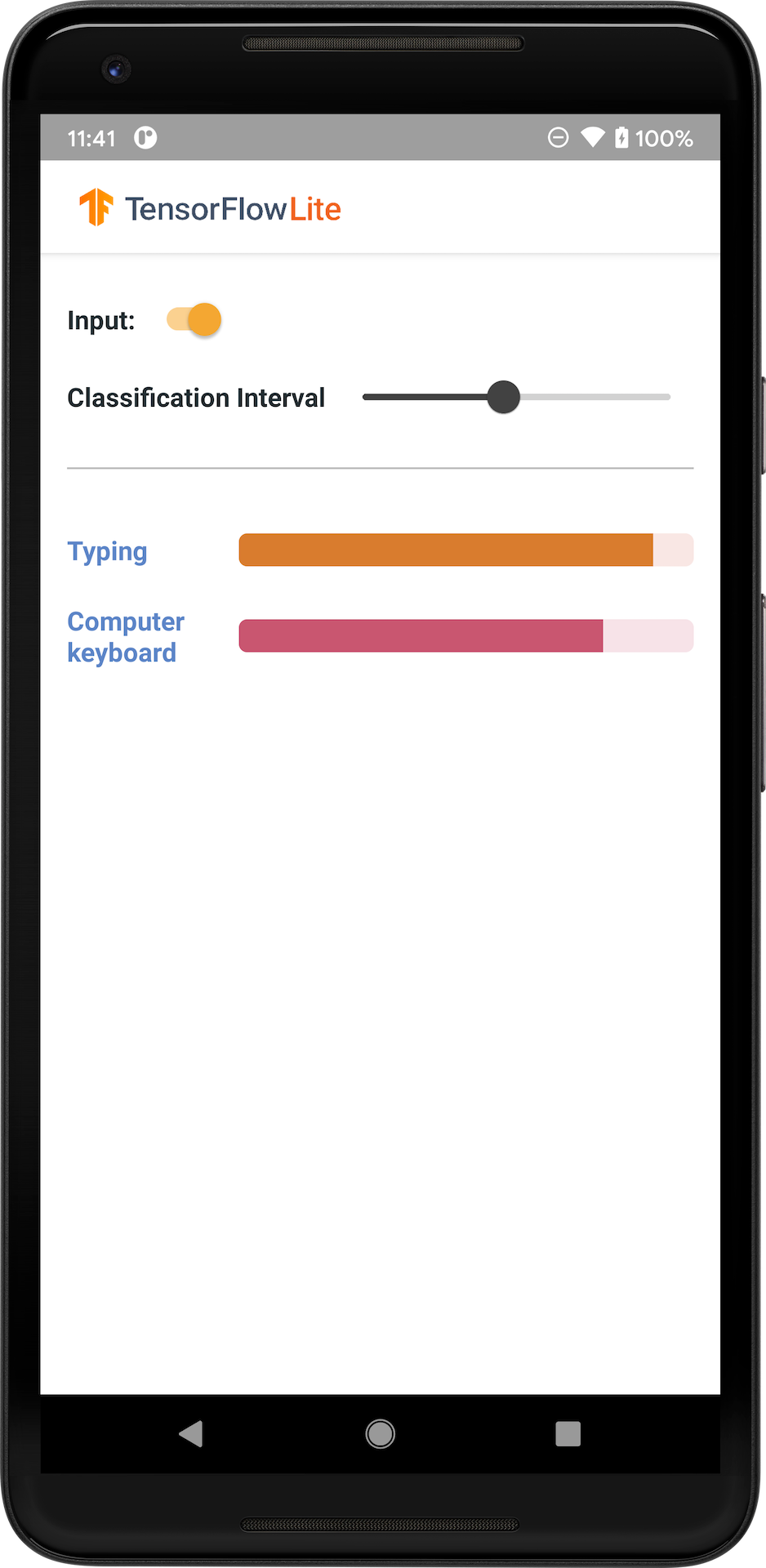
شروع کنید
اگر به تازگی با TensorFlow Lite آشنا هستید و با اندروید کار می کنید، توصیه می کنیم نمونه برنامه های زیر را بررسی کنید که می توانند به شما در شروع کار کمک کنند.
میتوانید از API خارج از جعبه از TensorFlow Lite Task Library استفاده کنید تا مدلهای طبقهبندی صدا را تنها در چند خط کد یکپارچه کنید. شما همچنین می توانید خط لوله استنتاج سفارشی خود را با استفاده از کتابخانه پشتیبانی TensorFlow Lite بسازید.
مثال اندروید زیر پیاده سازی را با استفاده از TFLite Task Library نشان می دهد
اگر از پلتفرمی غیر از Android/iOS استفاده میکنید، یا اگر قبلاً با APIهای TensorFlow Lite آشنا هستید، مدل شروع و فایلهای پشتیبانی را دانلود کنید (در صورت وجود).
مدل استارتر را از TensorFlow Hub دانلود کنید
توضیحات مدل
YAMNet یک طبقهبندی کننده رویداد صوتی است که شکل موج صوتی را به عنوان ورودی دریافت میکند و برای هر یک از 521 رویداد صوتی از هستیشناسی AudioSet پیشبینیهای مستقلی انجام میدهد. این مدل از معماری MobileNet v1 استفاده می کند و با استفاده از مجموعه AudioSet آموزش داده شده است. این مدل در اصل در باغ مدل تنسورفلو منتشر شد، جایی که کد منبع مدل، نقطه بازرسی مدل اصلی و مستندات دقیقتر است.
چگونه کار می کند
دو نسخه از مدل YAMNet تبدیل به TFLite وجود دارد:
YAMNet مدل اصلی طبقه بندی صوتی، با اندازه ورودی پویا، مناسب برای آموزش انتقال، استقرار وب و موبایل است. همچنین خروجی پیچیده تری دارد.
YAMNet/طبقهبندی یک نسخه کوانتیزه شده با ورودی قاب با طول ثابت سادهتر (15600 نمونه) است و یک بردار واحد از امتیازات را برای 521 کلاس رویداد صوتی برمیگرداند.
ورودی ها
این مدل یک آرایه 1-D float32 Tensor یا NumPy به طول 15600 را می پذیرد که حاوی یک شکل موج 0.975 ثانیه است که به صورت نمونه های تک 16 کیلوهرتز در محدوده [-1.0, +1.0] نشان داده شده است.
خروجی ها
این مدل یک تانسور 2 بعدی float32 با شکل (1, 521) برمی گرداند که حاوی امتیازات پیش بینی شده برای هر یک از 521 کلاس در هستی شناسی AudioSet است که توسط YAMNet پشتیبانی می شود. شاخص ستون (0-520) تانسور امتیازها با استفاده از نقشه کلاس YAMNet به نام کلاس AudioSet مربوطه نگاشت می شود که به عنوان یک فایل مرتبط yamnet_label_list.txt در فایل مدل بسته بندی شده است. برای استفاده به زیر مراجعه کنید
استفاده های مناسب
YAMNet قابل استفاده است
- بهعنوان یک طبقهبندیکننده رویداد صوتی مستقل که یک خط پایه معقول را در طیف گستردهای از رویدادهای صوتی ارائه میکند.
- به عنوان یک استخراج کننده ویژگی سطح بالا: خروجی تعبیه شده 1024-D YAMNet را می توان به عنوان ویژگی های ورودی مدل دیگری استفاده کرد که سپس می تواند روی مقدار کمی داده برای یک کار خاص آموزش داده شود. این امکان ایجاد سریع طبقهبندیکنندههای صوتی تخصصی را بدون نیاز به دادههای برچسبگذاریشده زیاد و بدون نیاز به آموزش یک مدل بزرگ به صورت سرتاسری فراهم میکند.
- به عنوان یک شروع گرم: پارامترهای مدل YAMNet را می توان برای مقداردهی اولیه بخشی از یک مدل بزرگتر استفاده کرد که امکان تنظیم سریعتر و کاوش مدل را فراهم می کند.
محدودیت ها
- خروجی های طبقه بندی کننده YAMNet در بین کلاس ها کالیبره نشده اند، بنابراین نمی توانید مستقیماً خروجی ها را به عنوان احتمال در نظر بگیرید. برای هر کار مشخصی، به احتمال زیاد نیاز به کالیبراسیون با دادههای مربوط به کار دارید که به شما امکان میدهد آستانه امتیاز و مقیاس بندی مناسب برای هر کلاس را تعیین کنید.
- YAMNet بر روی میلیونها ویدیوی YouTube آموزش دیده است و اگرچه اینها بسیار متنوع هستند، اما هنوز هم میتواند بین میانگین ویدیوی YouTube و ورودیهای صوتی مورد انتظار برای هر کار مشخص، عدم تطابق دامنه وجود داشته باشد. باید انتظار داشته باشید مقداری تنظیم دقیق و کالیبراسیون انجام دهید تا YAMNet در هر سیستمی که میسازید قابل استفاده باشد.
سفارشی سازی مدل
مدل های از پیش آموزش دیده ارائه شده برای تشخیص 521 کلاس صوتی مختلف آموزش دیده اند. برای فهرست کامل کلاسها، فایل برچسبها را در مخزن مدل ببینید.
میتوانید از تکنیکی به نام یادگیری انتقالی برای آموزش مجدد یک مدل برای تشخیص کلاسهایی که در مجموعه اصلی نیستند استفاده کنید. به عنوان مثال، می توانید مدل را دوباره آموزش دهید تا چندین آواز پرنده را تشخیص دهد. برای انجام این کار، به مجموعه ای از فایل های صوتی آموزشی برای هر یک از برچسب های جدیدی که می خواهید آموزش دهید، نیاز دارید. روش پیشنهادی استفاده از کتابخانه TensorFlow Lite Model Maker است که فرآیند آموزش یک مدل TensorFlow Lite را با استفاده از مجموعه داده های سفارشی در چند خط کد ساده می کند. از یادگیری انتقالی برای کاهش داده های آموزشی و زمان مورد نیاز استفاده می کند. همچنین می توانید از Transfer Learning برای تشخیص صدا به عنوان نمونه ای از آموزش انتقال یاد بگیرید.
مطالعه بیشتر و منابع
از منابع زیر برای کسب اطلاعات بیشتر در مورد مفاهیم مرتبط با طبقه بندی صدا استفاده کنید: