
| |
導入
大規模言語モデル (LLM) は、大規模なデータセットに基づいてテキストを生成するようにトレーニングされた機械学習モデルのクラスです。これらは、テキスト生成、質問応答、機械翻訳などの自然言語処理 (NLP) タスクに使用できます。これらは Transformer アーキテクチャに基づいており、多くの場合数十億の単語を含む大量のテキスト データに基づいてトレーニングされます。 GPT-2 などの小規模な LLM であっても、優れたパフォーマンスを発揮できます。 TensorFlow モデルをより軽量、高速、低電力のモデルに変換すると、デバイス上で生成 AI モデルを実行できるようになり、データがデバイスから流出することがないため、ユーザーのセキュリティが向上するというメリットがあります。
この Runbook では、Keras LLM を実行するために TensorFlow Lite を使用して Android アプリを構築する方法を示し、量子化手法を使用したモデルの最適化に関する提案を提供します。これを行わないと、実行に大量のメモリとより大きな計算能力が必要になります。
私たちは、互換性のある TFLite LLM をプラグインできるAndroid アプリ フレームワークをオープンソース化しました。以下に 2 つのデモを示します。
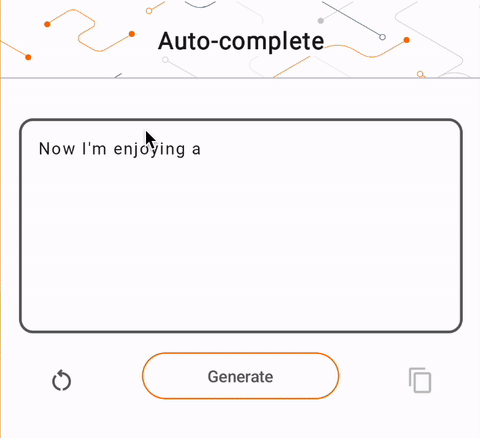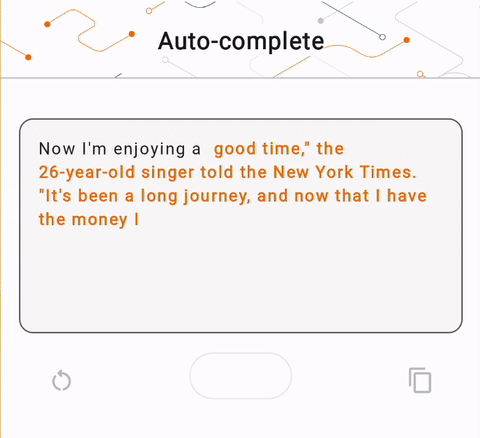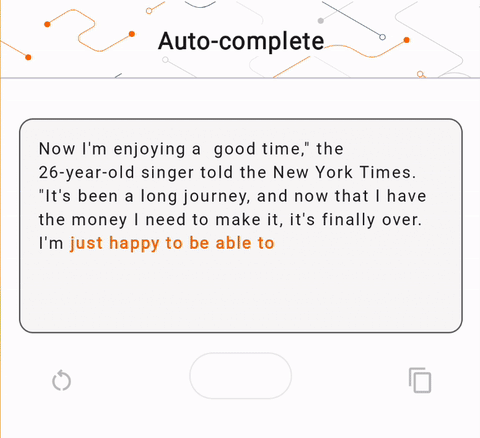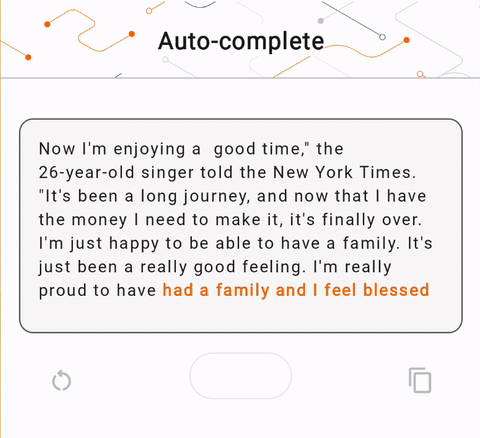
- 図 1 では、Keras GPT-2 モデルを使用して、デバイス上でテキスト補完タスクを実行しました。
- 図 2 では、命令調整されたPaLM モデル(15 億パラメータ) のバージョンを TFLite に変換し、TFLite ランタイムを通じて実行しました。
ガイド
モデルのオーサリング
このデモでは、KerasNLP を使用して GPT-2 モデルを取得します。 KerasNLP は、自然言語処理タスク用の最先端の事前トレーニング済みモデルを含むライブラリであり、開発サイクル全体を通じてユーザーをサポートできます。 KerasNLP リポジトリで利用可能なモデルのリストを確認できます。ワークフローはモジュール式コンポーネントから構築されており、そのまま使用する場合は最先端のプリセットウェイトとアーキテクチャを備えており、より詳細な制御が必要な場合は簡単にカスタマイズできます。 GPT-2 モデルの作成は、次の手順で行うことができます。
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
これら 3 行のコードの共通点の 1 つは、 from_preset()メソッドです。このメソッドは、プリセット アーキテクチャや重みから Keras API の一部をインスタンス化し、事前トレーニングされたモデルをロードします。このコード スニペットからは、次の 3 つのモジュール コンポーネントにも気づくでしょう。
Tokenizer : 生の文字列入力を Keras Embedding レイヤーに適した整数のトークン ID に変換します。 GPT-2 は、特にバイト ペア エンコーディング (BPE) トークナイザーを使用します。
プリプロセッサ: Keras モデルに供給される入力をトークン化してパッキングするためのレイヤー。ここで、プリプロセッサは、トークン化後にトークン ID のテンソルを指定された長さ (256) にパディングします。
Backbone : SoTA トランスフォーマー バックボーン アーキテクチャに従い、プリセットされた重みを持つ Keras モデル。
さらに、 GitHubで完全な GPT-2 モデル実装をチェックアウトできます。
モデル変換
TensorFlow Lite は、モバイル、マイクロコントローラー、その他のエッジ デバイスにメソッドをデプロイするためのモバイル ライブラリです。最初のステップは、TensorFlow Liteコンバーターを使用して Keras モデルをよりコンパクトな TensorFlow Lite 形式に変換し、次にモバイル デバイス用に高度に最適化された TensorFlow Liteインタープリターを使用して、変換されたモデルを実行することです。
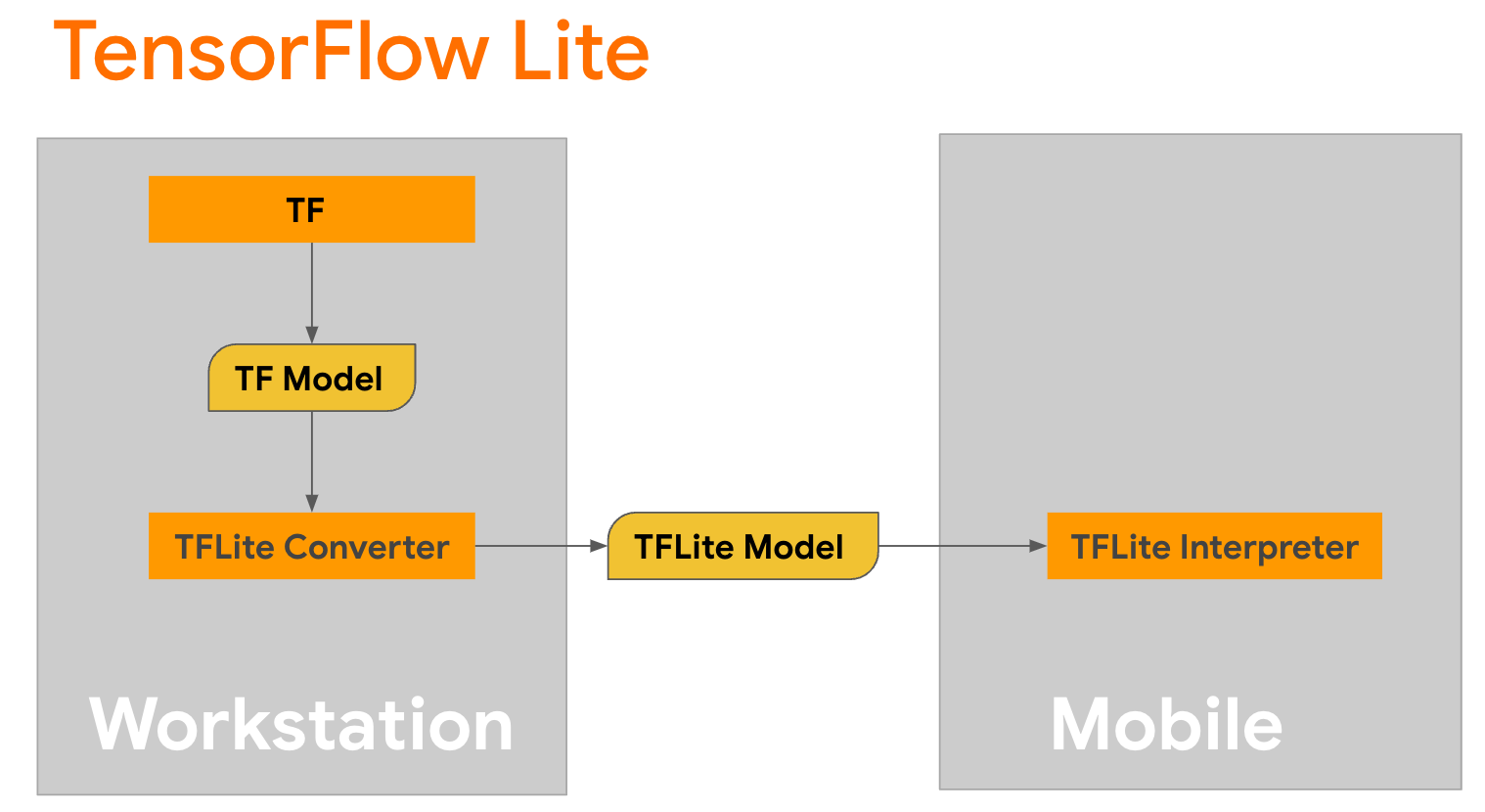 変換を実行する
変換を実行するGPT2CausalLMのgenerate()関数から始めます。 generate()関数をラップして具体的な TensorFlow 関数を作成します。
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
変換を実行するために、 TFLiteConverterのfrom_keras_model()を使用することもできることに注意してください。
次に、入力と TFLite モデルを使用して推論を実行するヘルパー関数を定義します。 TensorFlow テキスト演算は TFLite ランタイムの組み込み演算ではないため、インタープリターがこのモデルで推論を行うには、これらのカスタム演算を追加する必要があります。このヘルパー関数は、入力と、変換を実行する関数、つまり上記で定義したgenerator()関数を受け入れます。
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
これでモデルを変換できます。
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
量子化
TensorFlow Lite は、モデルのサイズを削減し、推論を高速化できる量子化と呼ばれる最適化手法を実装しています。量子化プロセスを通じて、32 ビット浮動小数点はより小さい 8 ビット整数にマッピングされるため、モデル サイズが 4 分の 1 に削減され、最新のハードウェアでより効率的に実行できます。 TensorFlow で量子化を行う方法はいくつかあります。詳細については、TFLite モデルの最適化ページとTensorFlow モデル最適化ツールキットのページを参照してください。量子化の種類については、以下で簡単に説明します。
ここでは、コンバーター最適化フラグをtf.lite.Optimize.DEFAULTに設定することで、GPT-2 モデルでトレーニング後のダイナミック レンジ量子化を使用します。変換プロセスの残りの部分は、前に説明したものと同じです。この量子化技術を使用すると、最大出力長を 100 に設定した Pixel 7 でレイテンシが約 6.7 秒であることがテストされました。
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
ダイナミックレンジ
ダイナミック レンジ量子化は、オンデバイス モデルを最適化するための開始点として推奨されます。モデル サイズを約 4 分の 1 に削減でき、キャリブレーション用の代表的なデータセットを用意しなくてもメモリ使用量が削減され、計算が高速化されるため、開始点として推奨されます。このタイプの量子化では、変換時に重みのみを浮動小数点から 8 ビット整数に静的に量子化します。
FP16
浮動小数点モデルは、重みを float16 型に量子化することによって最適化することもできます。 float16 量子化の利点は、モデル サイズが最大半分に縮小され (すべての重みがそのサイズの半分になるため)、精度の低下が最小限に抑えられること、および float16 データを直接操作できる GPU デリゲートをサポートしていることです (結果として float32 よりも高速な計算が可能になります)。データ)。 float16 重みに変換されたモデルは、追加の変更を加えることなく CPU 上で実行できます。 float16 の重みは、最初の推論の前に float32 にアップサンプリングされます。これにより、レイテンシと精度への影響を最小限に抑える代わりに、モデル サイズを削減できます。
完全な整数量子化
完全な整数量子化では、重みとアクティベーションを含む 32 ビット浮動小数点数が最も近い 8 ビット整数に変換されます。このタイプの量子化により、推論速度が向上した小型のモデルが得られます。これは、マイクロコントローラーを使用する場合に非常に価値があります。このモードは、アクティベーションが量子化の影響を受ける場合に推奨されます。
Android アプリの統合
このAndroid の例に従って、TFLite モデルを Android アプリに統合できます。
前提条件
まだインストールしていない場合は、Web サイトの手順に従ってAndroid Studioをインストールします。
- Android Studio 2022.2.1 以降。
- 4G を超えるメモリを搭載した Android デバイスまたは Android エミュレータ
Android Studio を使用したビルドと実行
- Android Studio を開き、ようこそ画面で[既存の Android Studio プロジェクトを開く]を選択します。
- 表示される [ファイルまたはプロジェクトを開く] ウィンドウから、TensorFlow Lite サンプル GitHub リポジトリをクローンした場所から
lite/examples/generative_ai/androidディレクトリに移動して選択します。 - エラー メッセージに応じて、さまざまなプラットフォームやツールのインストールが必要になる場合もあります。
- 変換された .tflite モデルの名前を
autocomplete.tfliteに変更し、app/src/main/assets/フォルダーにコピーします。 - メニューの[Build] -> [Make Project]を選択してアプリをビルドします。 (Ctrl+F9、バージョンに応じて)。
- メニュー[実行] -> ['app' を実行]をクリックします。 (Shift+F10、バージョンに応じて)
あるいは、 gradle ラッパーを使用してコマンド ラインでビルドすることもできます。詳細については、Gradle のドキュメントを参照してください。
(オプション) .aar ファイルの構築
デフォルトでは、アプリは必要な.aarファイルを自動的にダウンロードします。ただし、独自にビルドする場合は、 app/libs/build_aar/フォルダーに切り替えて./build_aar.shを実行します。このスクリプトは、TensorFlow Text から必要な ops を取得し、Select TF オペレーターの aar を構築します。
コンパイル後、新しいファイルtftext_tflite_flex.aarが生成されます。 app/libs/フォルダー内の .aar ファイルを置き換えて、アプリを再ビルドします。
標準のtensorflow-lite aar を Gradle ファイルに含める必要があることに注意してください。
コンテキストウィンドウのサイズ
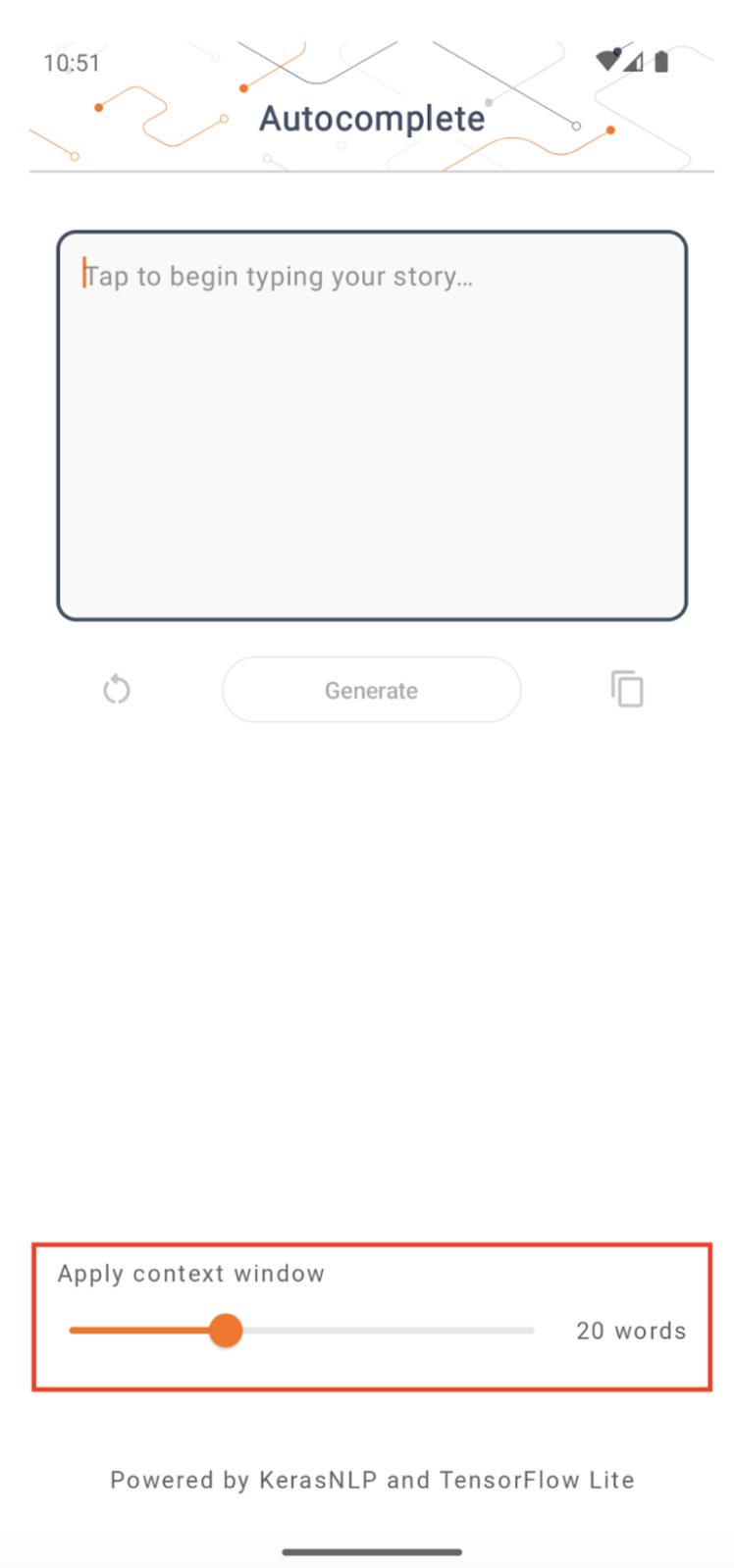
アプリには変更可能なパラメーター「コンテキスト ウィンドウ サイズ」があり、これが必要なのは、今日の LLM は一般に固定のコンテキスト サイズを持っており、「プロンプト」としてモデルに入力できる単語/トークンの数を制限しているためです (「単語」は必ずしも必要ではないことに注意してください)トークン化方法が異なるため、この場合は「トークン」に相当します)。この数字は次の理由から重要です。
- 設定が小さすぎると、モデルには意味のある出力を生成するための十分なコンテキストがなくなります。
- 設定が大きすぎると、モデルで作業するのに十分なスペースがなくなります (出力シーケンスにプロンプトが含まれるため)。
試してみることもできますが、出力シーケンスの長さの ~50% に設定するのが良いスタートです。
安全性と責任ある AI
元のOpenAI GPT-2 の発表で述べたように、GPT-2 モデルには注目すべき注意事項と制限があります。実際、今日の LLM は一般に、幻覚、公平性、偏見などのいくつかのよく知られた課題を抱えています。これは、これらのモデルが現実世界のデータでトレーニングされており、現実世界の問題を反映しているためです。
このコードラボは、TensorFlow ツールを使用して LLM を利用したアプリを作成する方法をデモンストレーションする目的のみに作成されています。このコードラボで作成されたモデルは教育目的のみを目的としており、運用環境での使用を目的としていません。
LLM の実稼働環境での使用には、トレーニング データセットの慎重な選択と包括的な安全性の軽減が必要です。この Android アプリで提供されるそのような機能の 1 つは、不適切なユーザー入力またはモデル出力を拒否する冒涜フィルターです。不適切な言語が検出された場合、アプリはそのアクションを拒否します。 LLM のコンテキストにおける Responsible AI について詳しく知りたい場合は、Google I/O 2023 の生成言語モデルを使用した安全で責任ある開発技術セッションを視聴し、 Responsible AI Toolkitを確認してください。