
یک بازی رومیزی در برابر یک عامل انجام دهید که با استفاده از یادگیری تقویتی آموزش دیده و با TensorFlow Lite به کار گرفته شده است.
شروع کنید
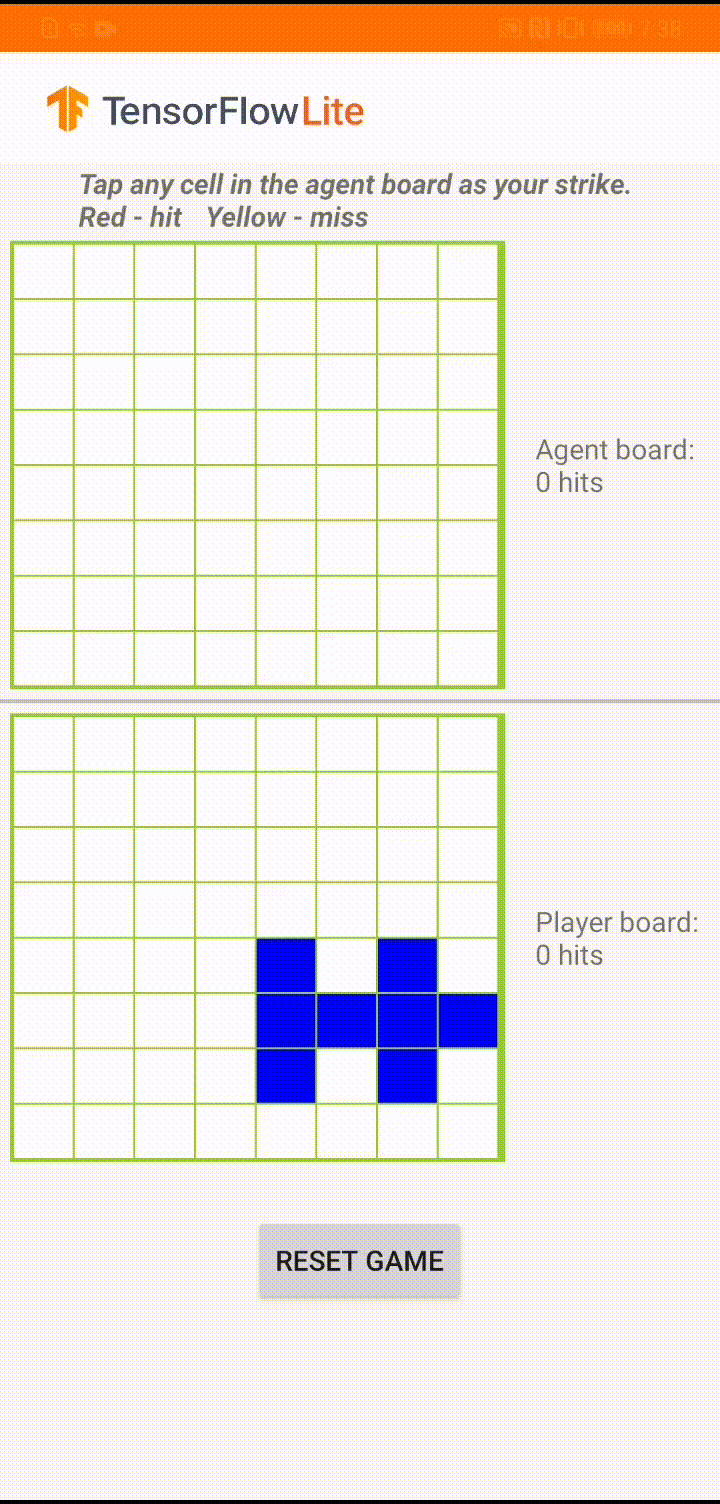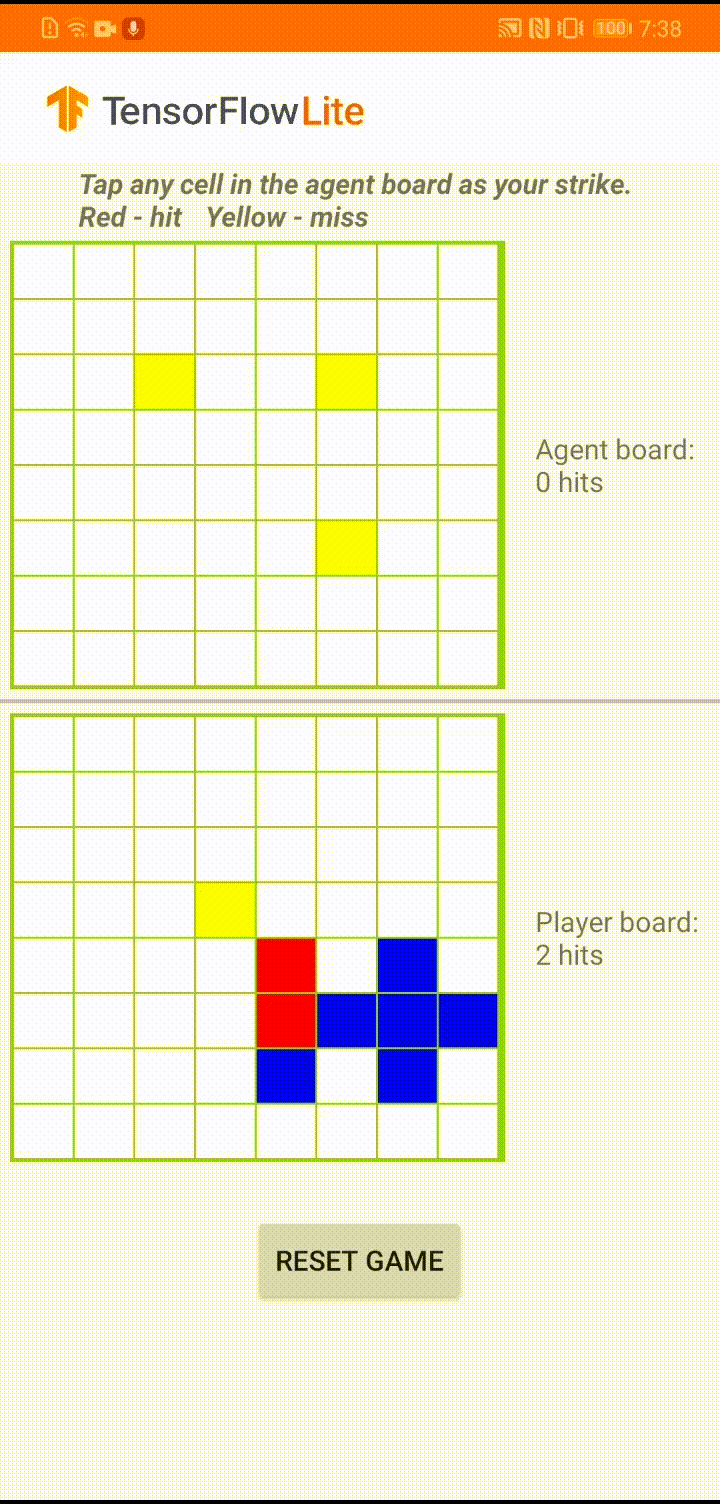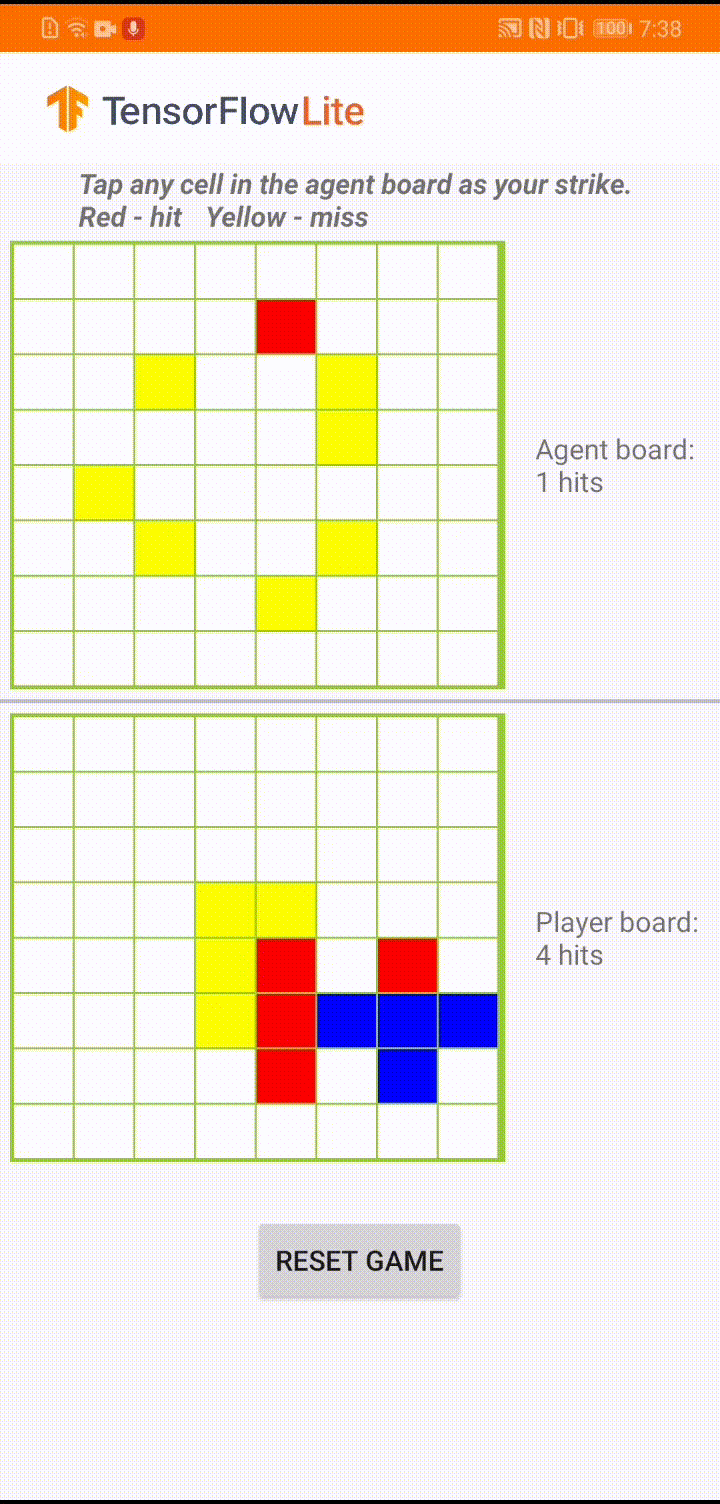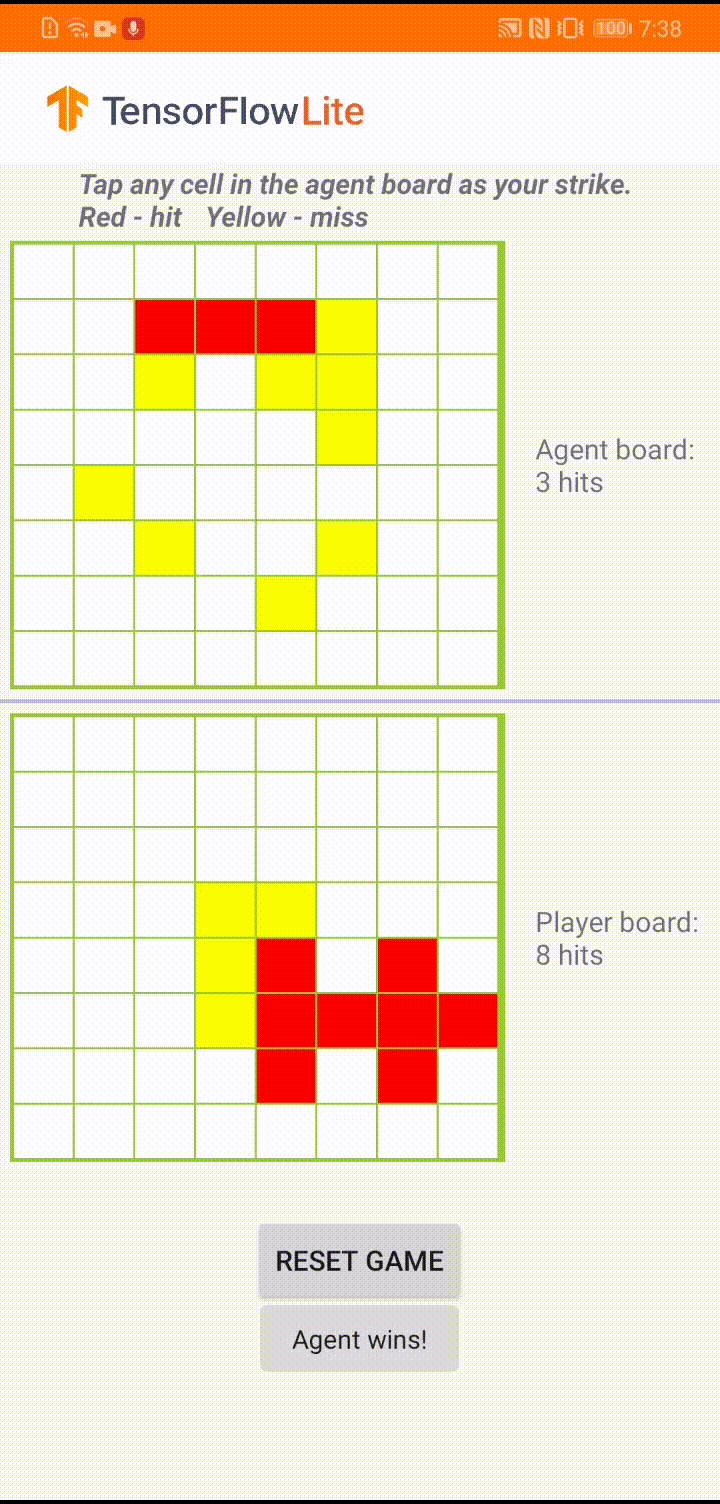
اگر با TensorFlow Lite تازه کار هستید و با اندروید کار می کنید، توصیه می کنیم برنامه مثال زیر را بررسی کنید که می تواند به شما در شروع کار کمک کند.
اگر از پلتفرمی غیر از اندروید استفاده میکنید یا قبلاً با APIهای TensorFlow Lite آشنا هستید، میتوانید مدل آموزشدیده ما را دانلود کنید.
چگونه کار می کند
این مدل برای یک عامل بازی ساخته شده است تا بتواند یک بازی تخته کوچک به نام "Plane Strike" را انجام دهد. برای معرفی سریع این بازی و قوانین آن، لطفا به این README مراجعه کنید.
در زیر رابط کاربری برنامه، عاملی ساختهایم که علیه بازیکن انسان بازی میکند. عامل یک MLP 3 لایه است که حالت برد را به عنوان ورودی می گیرد و امتیاز پیش بینی شده برای هر یک از 64 سلول تخته ممکن را به بیرون می دهد. این مدل با استفاده از گرادیان خط مشی (REINFORCE) آموزش داده شده است و می توانید کد آموزشی را در اینجا پیدا کنید. پس از آموزش عامل، مدل را به TFLite تبدیل کرده و در برنامه اندروید مستقر می کنیم.
در طول بازی واقعی در برنامه اندروید، زمانی که نوبت به عامل می رسد که اقدامی انجام دهد، نماینده به وضعیت تابلوی بازیکن انسانی (تخته در پایین) نگاه می کند که حاوی اطلاعاتی در مورد ضربات موفق و ناموفق قبلی (ضربه ها و از دست دادن ها) است. ، و از مدل آموزش دیده برای پیش بینی محل ضربه بعدی استفاده می کند تا بتواند بازی را قبل از اینکه بازیکن انسانی انجام دهد به پایان برساند.
معیارهای عملکرد
اعداد معیار عملکرد با ابزار توضیح داده شده در اینجا تولید می شوند.
| نام مدل | اندازه مدل | دستگاه | CPU |
|---|---|---|---|
| گرادیان سیاست | 84 کیلوبایت | پیکسل 3 (اندروید 10) | 0.01 میلیثانیه* |
| پیکسل 4 (اندروید 10) | 0.01 میلیثانیه* |
* 1 نخ استفاده شده است.
ورودی ها
مدل یک تانسور 3 بعدی float32 از (1، 8، 8) را به عنوان حالت تخته می پذیرد.
خروجی ها
مدل یک تانسور 2 بعدی float32 شکل (1،64) را به عنوان امتیازات پیش بینی شده برای هر یک از 64 موقعیت ضربه ممکن برمی گرداند.
مدل خود را آموزش دهید
می توانید با تغییر پارامتر BOARD_SIZE در کد آموزشی ، مدل خود را برای یک برد بزرگتر/کوچکتر آموزش دهید.