TensorFlow용 텍스트 처리 도구
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
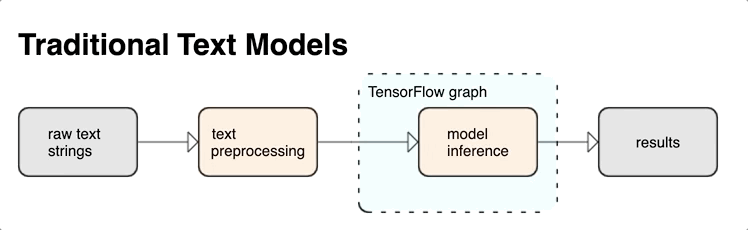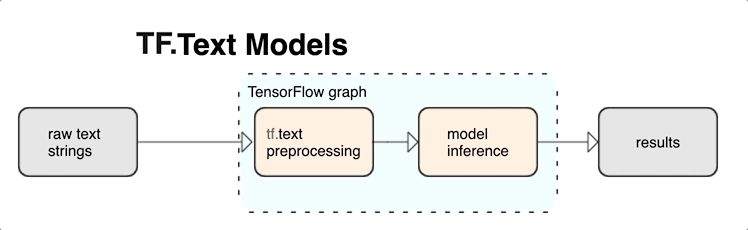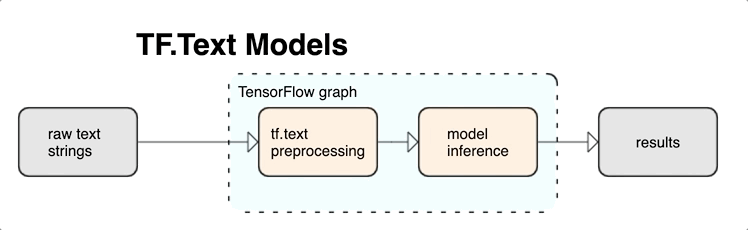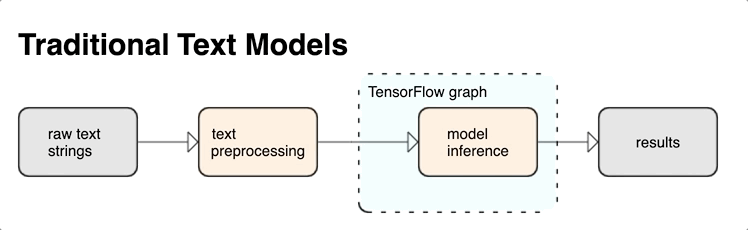
TensorFlow는 풍부한 작업 및 라이브러리 컬렉션을 제공하여 텍스트 형식(예: 원시 텍스트 문자열 또는 문서)의 입력을 사용하는 데 도움이 됩니다. 이러한 라이브러리는 텍스트 기반 모델에 필요한 사전 처리를 정기적으로 실행할 수 있으며 시퀀스 모델링에 유용한 기타 특징을 포함합니다.
TensorFlow 그래프 내에서 강력한 구문과 시맨틱 텍스트 특징을 신경망의 입력으로 추출할 수 있습니다.
TensorFlow 그래프와 사전 처리를 통합하면 다음과 같은 이점이 있습니다.
- 텍스트 작업을 위한 대규모 툴킷 사용이 가능합니다.
- 대규모 TensorFlow 도구 묶음과 통합하여 학습, 평가, 실행을 통해 문제 정의 측면에서 프로젝트를 지원합니다.
- 서빙 시간의 복잡도를 줄이고 학습-제공 편향을 방지합니다.
위의 내용 외에도 학습 시 토큰화가 추론 시 토큰화와 다르다거나 사전 처리 스크립트를 관리하는 것에 관해 걱정할 필요가 없습니다.