適用於 TensorFlow 的文字處理工具
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
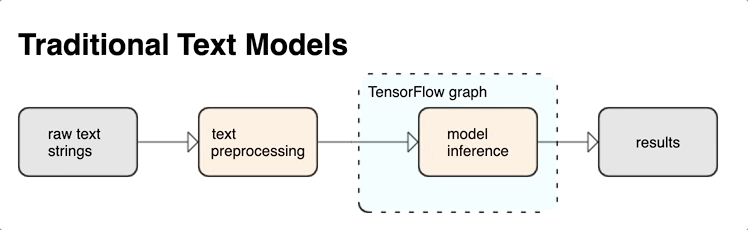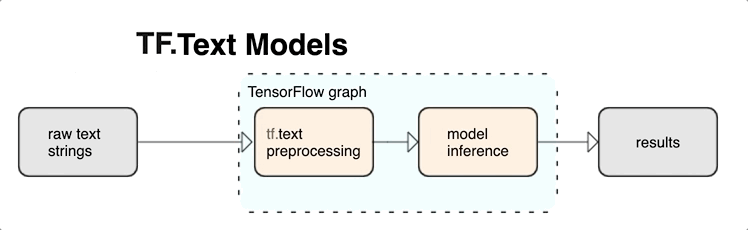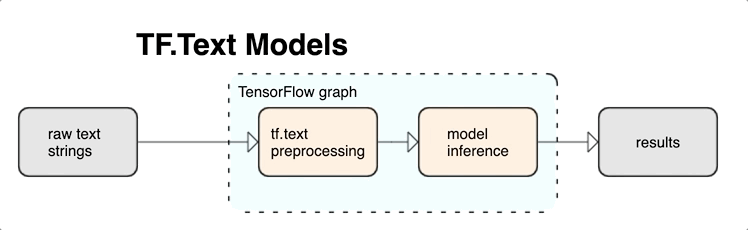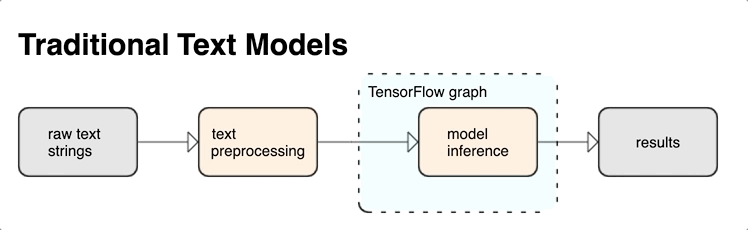
TensorFlow 為您提供豐富的運算和程式庫,協助您以文字的形式處理輸入內容,例如原始文字字串或文件。這些程式庫能按照文字型模型的要求定期執行預先處理作業,還提供其他適合用來建立序列模型的實用功能。
您可以從 TensorFlow 圖形內部擷取強大的語法和語意文字特徵,做為類神經網路的輸入內容。
若使用 TensorFlow 圖形整合預先處理作業,能享有下列好處:
- 提供用於處理文字的大型工具組
- 能夠與大型 TensorFlow 工具套件整合,為從問題定義、訓練、評估一直到推出的專案提供支援
- 降低提供時的複雜度,並避免產生訓練/應用偏差
除了上述好處以外,您不需要擔心訓練時的權杖化與推論時的權杖化會不一樣,也不必管理預先處理指令碼。