| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
Um dos maiores desafios no Reconhecimento Automático de Fala é a preparação e o aumento de dados de áudio. A análise de dados de áudio pode ser no domínio do tempo ou da frequência, o que adiciona complexidade adicional em comparação com outras fontes de dados, como imagens.
Como parte do ecossistema TensorFlow, tensorflow-io pacote fornece algumas APIs relacionados com áudio úteis bastante que ajuda facilitando a preparação e aumento dos dados de áudio.
Configurar
Instale os pacotes necessários e reinicie o tempo de execução
pip install tensorflow-io
Uso
Ler um arquivo de áudio
Em TensorFlow IO, classe tfio.audio.AudioIOTensor permite que você leia um arquivo de áudio em um lazy-carregado IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
No exemplo acima, o arquivo Flac brooklyn.flac é de um clipe de áudio de acesso público no Google Cloud .
O endereço GCS gs://cloud-samples-tests/speech/brooklyn.flac são usados diretamente porque GCS é um sistema de arquivos suportados no TensorFlow. Além Flac formato, WAV , Ogg , MP3 , e MP4A também são suportados por AudioIOTensor com detecção automática formato de arquivo.
AudioIOTensor é preguiçoso-carregada de forma única forma, dtipo, e taxa de amostragem são mostrados inicialmente. A forma do AudioIOTensor é representado como [samples, channels] , o que significa que o clipe de áudio que é carregado com mono canal 28979 amostras em int16 .
O conteúdo do clipe de áudio só será lido como necessário, quer através da conversão AudioIOTensor para Tensor através to_tensor() , ou através de corte. O fatiamento é especialmente útil quando apenas uma pequena parte de um clipe de áudio grande é necessária:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
O áudio pode ser reproduzido através de:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
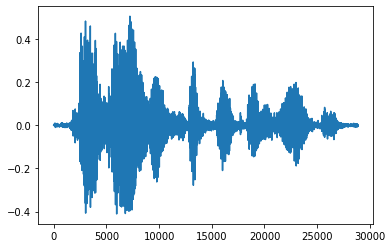
É mais conveniente converter o tensor em números flutuantes e mostrar o clipe de áudio no gráfico:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
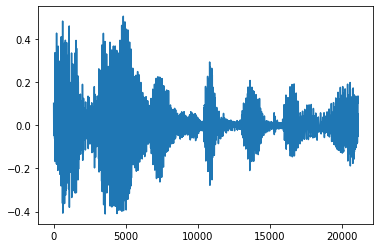
Corte o barulho
Às vezes faz sentido para cortar o ruído do áudio, o que poderia ser feito através da API tfio.audio.trim . Retornado do API é um par de [start, stop] posição do segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
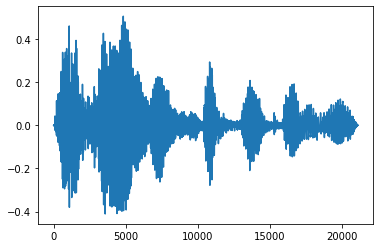
Fade In e Fade Out
Uma técnica útil de engenharia de áudio é o fade, que aumenta ou diminui gradualmente os sinais de áudio. Isto pode ser feito através tfio.audio.fade . tfio.audio.fade suporta diferentes formas de desbota, tais como linear , logarithmic , ou exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
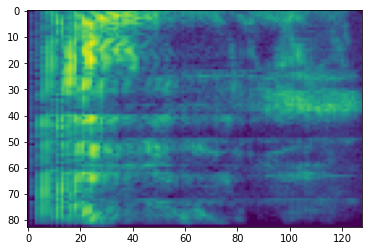
Espectrograma
O processamento de áudio avançado geralmente funciona em mudanças de frequência ao longo do tempo. Em tensorflow-io uma forma de onda pode ser convertido para espectrograma através tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
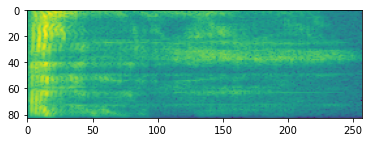
Transformações adicionais para diferentes escalas também são possíveis:
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
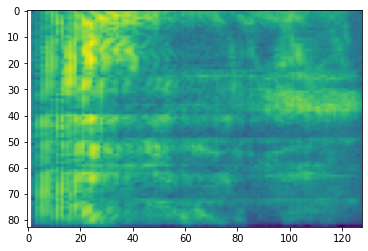
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
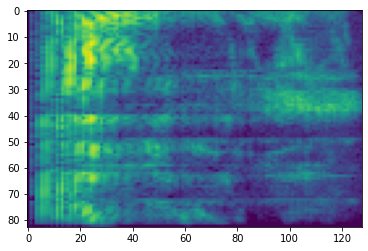
SpecAugment
Em adição ao acima APIs de preparação de dados e de potencialização mencionados, tensorflow-io pacote também proporciona aumentos espectrograma avançadas, mais notavelmente a frequência e o tempo de máscara discutido em SpecAugment: (. Park et al, 2019) Um método de dados de aumento simples para Reconhecimento Automático de Voz .
Mascaramento de Frequência
Em mascaramento frequência, canais de frequência [f0, f0 + f) são mascarados em que f é escolhido a partir de uma distribuição uniforme de 0 para a máscara de frequências parâmetro F , e f0 é escolhida a partir de (0, ν − f) onde ν é o número de canais de frequência.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
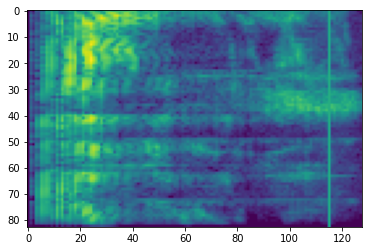
Mascaramento do Tempo
Em mascaramento tempo, t intervalos de tempo consecutivos [t0, t0 + t) são mascarados onde t é escolhido a partir de uma distribuição uniforme de 0 para a máscara de tempo parâmetro T , e t0 é escolhido a partir de [0, τ − t) onde τ é a passos de tempo.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>