
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
מדריך זה הוא סקירה כללית של האילוצים והמסדרים המסופקים על ידי ספריית TensorFlow Lattice (TFL). כאן אנו משתמשים באומדנים משומרים של TFL על מערכי נתונים סינתטיים, אך שימו לב שניתן לעשות הכל במדריך זה גם עם מודלים שנבנו משכבות TFL Keras.
לפני שתמשיך, ודא שבזמן הריצה שלך מותקנות כל החבילות הנדרשות (כפי שיובאו בתאי הקוד למטה).
להכין
התקנת חבילת TF Lattice:
pip install -q tensorflow-lattice
ייבוא חבילות נדרשות:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
ערכי ברירת מחדל המשמשים במדריך זה:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
מערך הדרכה לדירוג מסעדות
תארו לעצמכם תרחיש פשוט שבו אנו רוצים לקבוע אם משתמשים ילחצו על תוצאת חיפוש של מסעדה או לא. המשימה היא לחזות את שיעור הקליקים (CTR) בהינתן תכונות קלט:
- דירוג ממוצע (
avg_rating): תכונת ערכים מספרית בטווח [1,5]. - מספר הביקורות (
num_reviews): תכונת ערכים מספרית כתרים ב 200, אשר אנו משתמשים כמדד trendiness. - דירוג דולר (
dollar_rating): תכונת קטגורים עם ערכי מחרוזת בקבוצת { "D", "DD", "DDD", "DDDD"}.
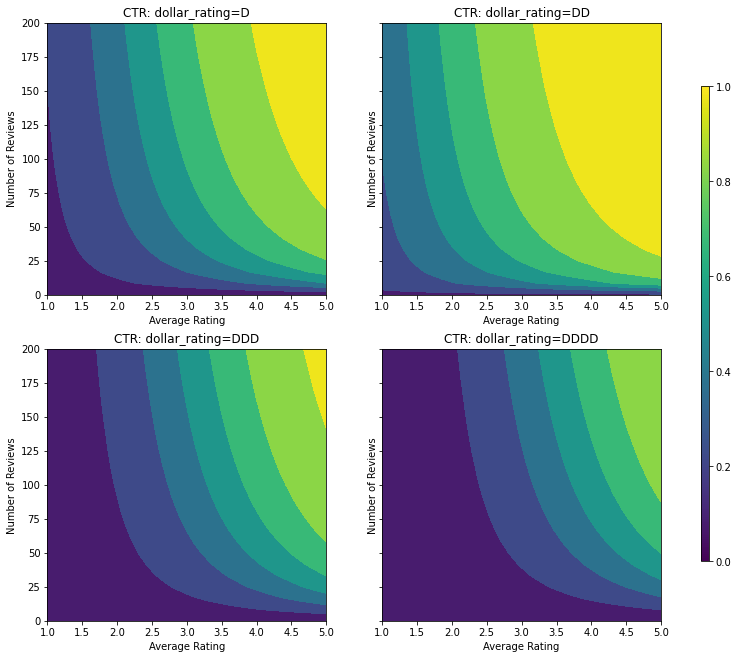
כאן אנו יוצרים מערך נתונים סינתטי שבו שיעור הקליקים האמיתי ניתן על ידי הנוסחה:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
איפה \(b(\cdot)\) מתרגם כל dollar_rating לערך הבסיס:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
נוסחה זו משקפת דפוסי משתמש טיפוסיים. למשל בהינתן כל השאר קבוע, המשתמשים מעדיפים מסעדות עם דירוגי כוכבים גבוהים יותר, ומסעדות "\$\$" יקבלו יותר קליקים מאשר "\$", ואחריהן "\$\$\$" ו-"\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
בואו נסתכל על קווי המתאר של פונקציית CTR זו.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
הכנת נתונים
כעת עלינו ליצור את מערכי הנתונים הסינתטיים שלנו. אנו מתחילים ביצירת מערך נתונים מדומה של מסעדות והתכונות שלהן.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
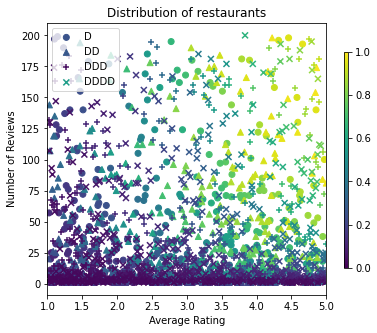
בואו לייצר את מערכי ההדרכה, האימות והבדיקות. כאשר מסעדה נראית בתוצאות החיפוש, אנו יכולים לתעד את המעורבות של המשתמש (קליק או לא קליק) כנקודה לדוגמה.
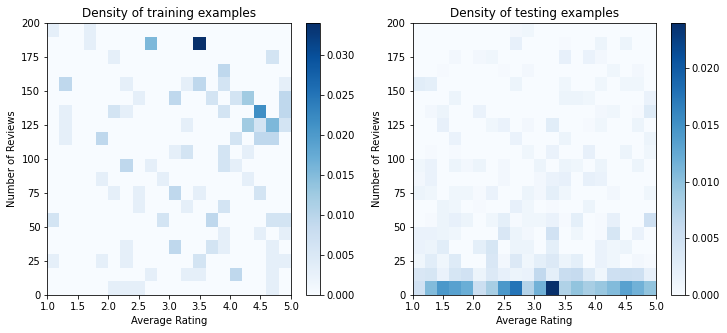
בפועל, משתמשים לרוב לא עוברים על כל תוצאות החיפוש. המשמעות היא שסביר להניח שמשתמשים יראו רק מסעדות שכבר נחשבות ל"טובות" לפי מודל הדירוג הנוכחי שנמצא בשימוש. כתוצאה מכך, מסעדות "טובות" מתרשמות בתדירות גבוהה יותר ומיוצגות יתר על המידה במערך הנתונים של ההדרכה. בעת שימוש בתכונות נוספות, מערך ההדרכה יכול להיות בעל פערים גדולים בחלקים "רעים" של מרחב התכונות.
כאשר המודל משמש לדירוג, הוא מוערך לעתים קרובות על כל התוצאות הרלוונטיות עם התפלגות אחידה יותר שאינה מיוצגת היטב על ידי מערך ההדרכה. מודל גמיש ומסובך עלול להיכשל במקרה זה עקב התאמת יתר של נקודות הנתונים המיוצגות יתר על המידה ובכך חוסר יכולת הכללה. אנו מטפלים בבעיה זו על ידי שימוש בידע התחום להוסיף אילוצי צורת מנחי המודל לבצע תחזיות סבירות כשזה לא יכול לאסוף אותם מן נתון הכשרה.
בדוגמה זו, מערך ההדרכה מורכב בעיקר מאינטראקציות של משתמשים עם מסעדות טובות ופופולריות. למערך הנתונים של הבדיקה יש התפלגות אחידה כדי לדמות את הגדרת ההערכה שנדונה לעיל. שים לב שמערך נתונים לבדיקה כזה לא יהיה זמין בהגדרת בעיה אמיתית.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
הגדרת input_fns המשמשים להדרכה והערכה:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
התאמת עצים בעלי שיפור שיפוע
בואו נתחיל עם רק שתי תכונות: avg_rating ו num_reviews .
אנו יוצרים כמה פונקציות עזר לשרטוט וחישוב מדדי אימות ובדיקה.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
אנו יכולים להתאים עצי החלטה עם חיזוק שיפוע של TensorFlow במערך הנתונים:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
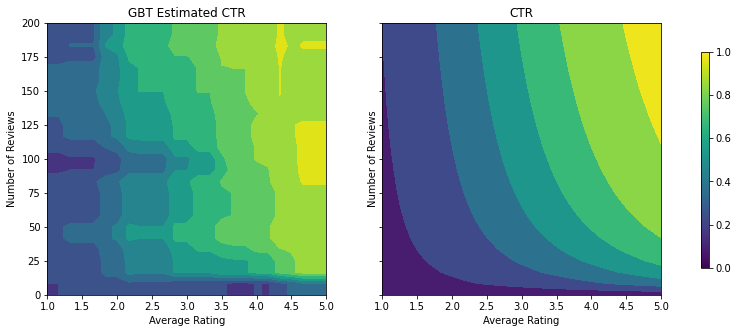
למרות שהמודל תפס את הצורה הכללית של שיעור הקליקים האמיתי ויש לו מדדי אימות הגונים, יש לו התנהגות נוגדת אינטואיטיבית בכמה חלקים של מרחב הקלט: שיעור הקליקים המשוער יורד ככל שהדירוג הממוצע או מספר הביקורות עולה. הסיבה לכך היא מחסור בנקודות מדגם באזורים שאינם מכוסים היטב על ידי מערך ההדרכה. למודל פשוט אין דרך להסיק את ההתנהגות הנכונה רק מהנתונים.
כדי לפתור בעיה זו, אנו אוכפים את מגבלת הצורה לפיה המודל חייב להפיק ערכים מונוטוניים הגדלים באופן מונוטוני הן ביחס לדרוג הממוצע והן למספר הביקורות. בהמשך נראה כיצד ליישם זאת ב-TFL.
התאמת DNN
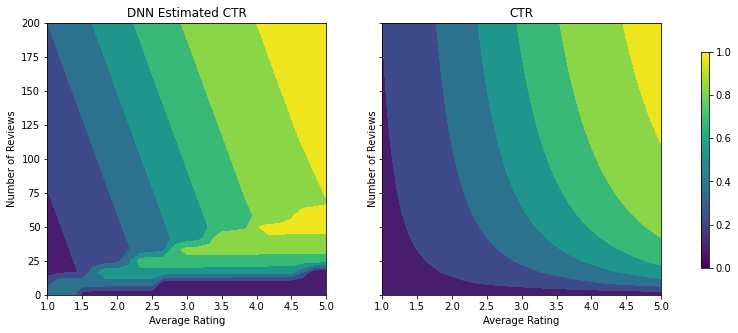
אנחנו יכולים לחזור על אותם שלבים עם מסווג DNN. אנו יכולים להבחין בדפוס דומה: אין מספיק נקודות מדגם עם מספר קטן של ביקורות גורם לאקסטרפולציה חסרת היגיון. שימו לב שלמרות שמדד האימות טוב יותר מפתרון העץ, מדד הבדיקה גרוע בהרבה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
אילוצי צורה
TensorFlow Lattice (TFL) מתמקד באכיפת אילוצי צורה כדי להגן על התנהגות המודל מעבר לנתוני האימון. אילוצי צורה אלו מוחלים על שכבות TFL Keras. ניתן למצוא את פרטיהם בתיבות נייר JMLR שלנו .
במדריך זה אנו משתמשים באומדנים משומרי TF כדי לכסות אילוצי צורה שונים, אך שימו לב שניתן לבצע את כל השלבים הללו עם מודלים שנוצרו משכבות TFL Keras.
כמו בכול הערכת TensorFlow אחרת, TFL משומר אומד להשתמש בעמודות תכונה להגדיר את מבנה הקלט ולהשתמש input_fn כשר להעביר את נתון. שימוש באומדנים משומרים TFL דורש גם:
- תצורת דגם: הגדרת ארכיטקטורת המודל ואילוצי צורה לכול תכונת regularizers.
- input_fn ניתוח תכונה: א TF input_fn העברת נתונים עבור אתחול TFL.
לתיאור יסודי יותר, עיין במדריך לאומדנים משומרים או במסמכי ה-API.
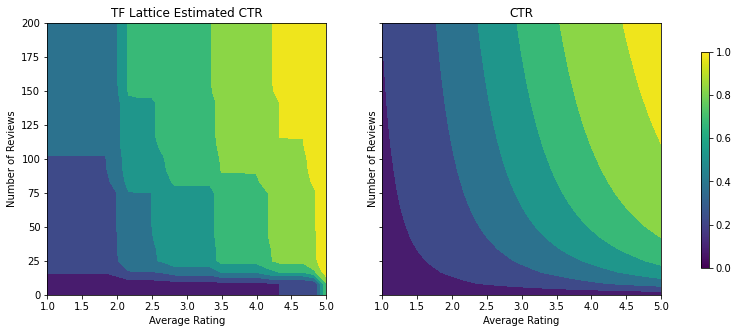
מונוטוניות
תחילה אנו מתייחסים לחששות המונוטוניות על ידי הוספת אילוצי צורת מונוטוניות לשתי התכונות.
כדי להורות TFL לאכוף אילוצי צורה, אנו מגדירים את אילוצי configs התכונה. מופעי הקוד הבאים איך אנחנו יכולים לדרוש את הפלט להיות הגדלת מונוטונית לגבי שני num_reviews ו avg_rating ידי הגדרת monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
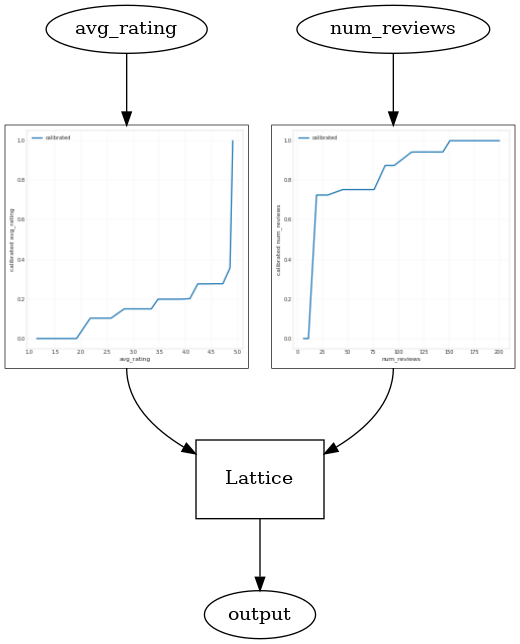
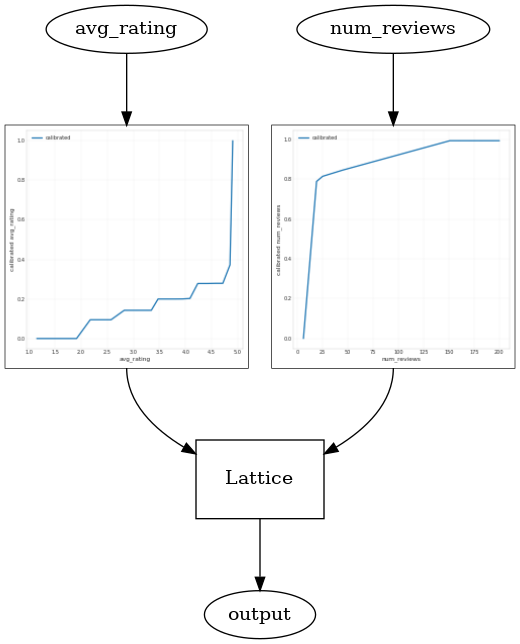
באמצעות CalibratedLatticeConfig יוצר מסווג משומר כי הראשון חל כיל לכול קלט (פונקציה לינארית פיסה-חכמה עבור תכונות מספריות) ואחריו שכבת סריג אל הלא-לינארית פתיל התכונות המכוילות. אנו יכולים להשתמש tfl.visualization לדמיין המודל. במיוחד, העלילה הבאה מציגה את שני המכיילים המאומנים הכלולים במסווג המשומר.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
עם האילוצים שנוספו, שיעור הקליקים המשוער תמיד יגדל ככל שהדירוג הממוצע יגדל או מספר הביקורות יגדל. זה נעשה על ידי לוודא שהכייל והסריג מונוטוניים.
החזרות פוחתות
תפוקה שולית פוחת אמצעים כי הרווח השולי של הגדלת ערך תכונה מסוימת יקטן ככל שנגדיל את הערך. במקרה שלנו אנו מצפים כי num_reviews תכונה כדלקמן הדפוס הזה, כדי שנוכל להגדיר כַּיָל שלה בהתאם. שימו לב שאנחנו יכולים לפרק תשואות מצטמצמות לשני תנאים מספיקים:
- המכייל עולה באופן מונוטוני, ו
- המכייל קעור.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
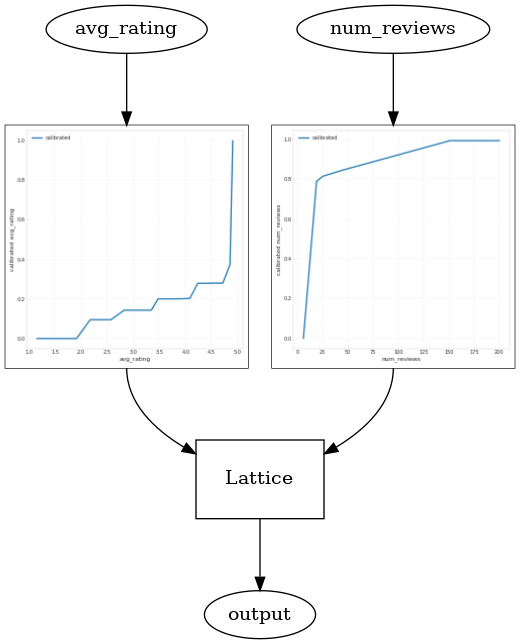
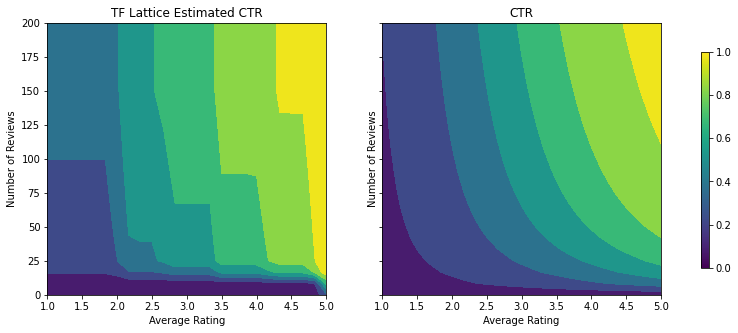
שימו לב כיצד מדד הבדיקה משתפר על ידי הוספת אילוץ הקיעור. עלילת החיזוי גם דומה יותר לאמת הקרקע.
אילוץ צורה דו מימדי: אמון
דירוג של 5 כוכבים למסעדה עם רק ביקורת אחת או שתיים הוא כנראה דירוג לא אמין (ייתכן שהמסעדה לא ממש טובה), בעוד שדירוג 4 כוכבים למסעדה עם מאות ביקורות הוא הרבה יותר אמין (המסעדה היא כנראה טוב במקרה זה). אנו יכולים לראות שמספר הביקורות על מסעדה משפיע על מידת האמון שאנו נותנים בדרוג הממוצע שלה.
אנו יכולים להפעיל אילוצי אמון של TFL כדי ליידע את המודל שהערך הגדול יותר (או הקטן יותר) של תכונה אחת מצביע על יותר הסתמכות או אמון בתכונה אחרת. הדבר נעשה על ידי קביעת reflects_trust_in תצורת config התכונה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
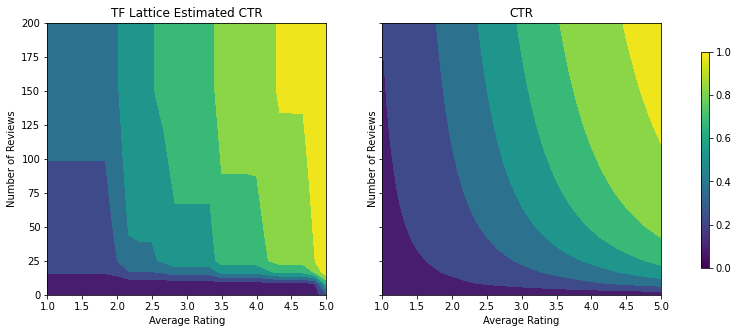
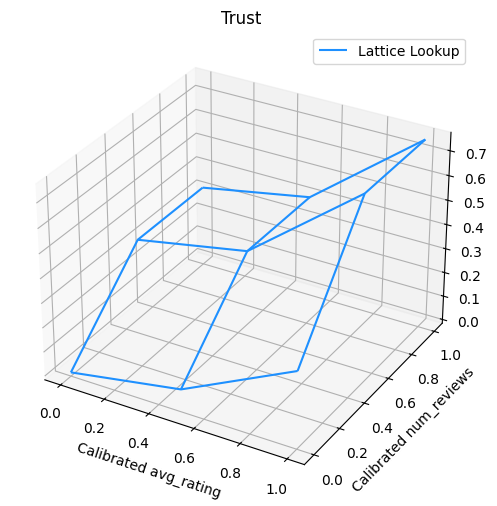
העלילה הבאה מציגה את פונקציית הסריג המאומן. בשל אילוץ אמון, אנו מצפים כי ערכים גדולים יותר של מכויל num_reviews יאלץ מדרון גבוה ביחס מכויל avg_rating , וכתוצאה מכך מהלך משמעותי יותר בפלט הסריג.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
מחליקים מכיילים
בואו עכשיו נסתכל על כיל של avg_rating . למרות שהוא הולך וגדל באופן מונוטוני, השינויים במדרונות שלו הם פתאומיים וקשים לפירוש. זה מרמז שאנחנו אולי כדאי לשקול החלקת כַּיָל זו באמצעות התקנת regularizer ב regularizer_configs .
כאן אנו להחיל wrinkle regularizer להפחית שינויי העקמומיות. אתה יכול גם להשתמש laplacian regularizer כדי לשטח את כיל ואת hessian regularizer כדי להפוך אותו ליותר ליניארי.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
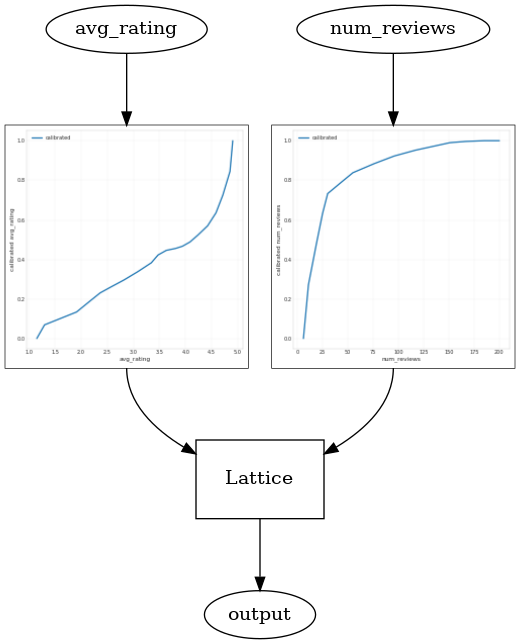
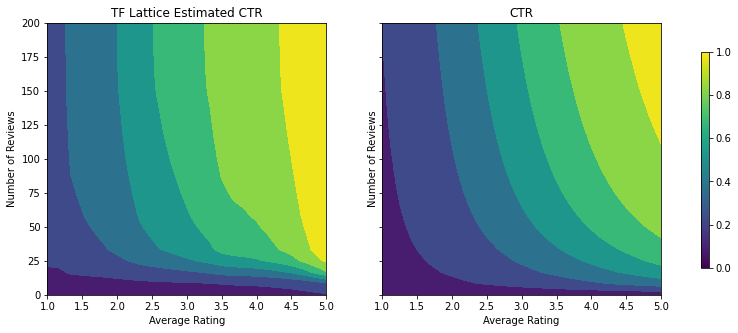
המכיילים כעת חלקים, ושיעור הקליקים המשוער הכולל תואם טוב יותר את האמת הבסיסית. זה בא לידי ביטוי הן במדד הבדיקה והן במגרשי המתאר.
מונוטוניות חלקית לכיול קטגורי
עד כה השתמשנו רק בשניים מהתכונות המספריות בדגם. כאן נוסיף תכונה שלישית באמצעות שכבת כיול קטגורית. שוב אנו מתחילים בהגדרת פונקציות מסייעות לשרטוט וחישוב מטרי.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
לערב את התכונה השלישית, dollar_rating , עלינו לזכור כי התכונות קטגורי דורשים טיפול מעט שונה TFL, הן בטור תכונה וכתוצאה config תכונה. כאן אנו אוכפים את מגבלת המונוטוניות החלקית לפיה התפוקות עבור מסעדות "DD" צריכות להיות גדולות יותר ממסעדות "D" כאשר כל שאר התשומות קבועות. הדבר נעשה באמצעות monotonicity השוקעת config התכונה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
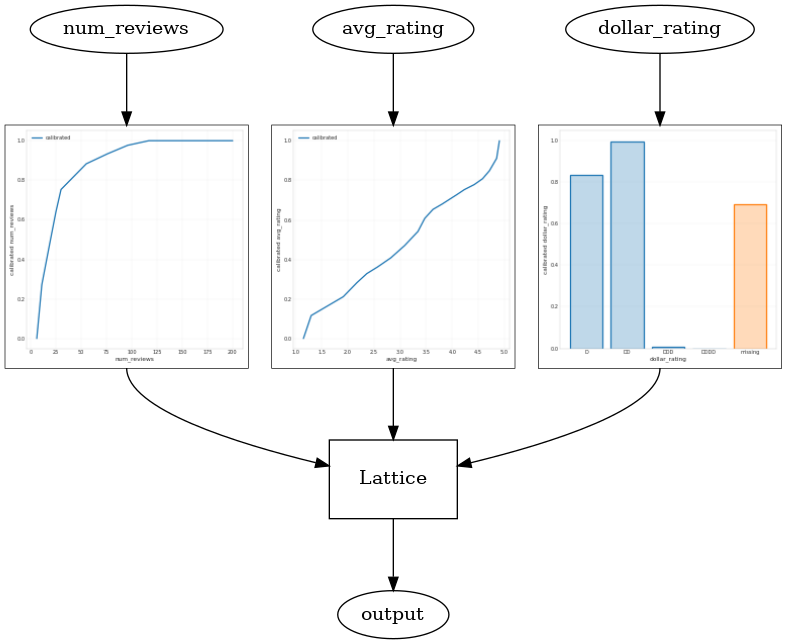
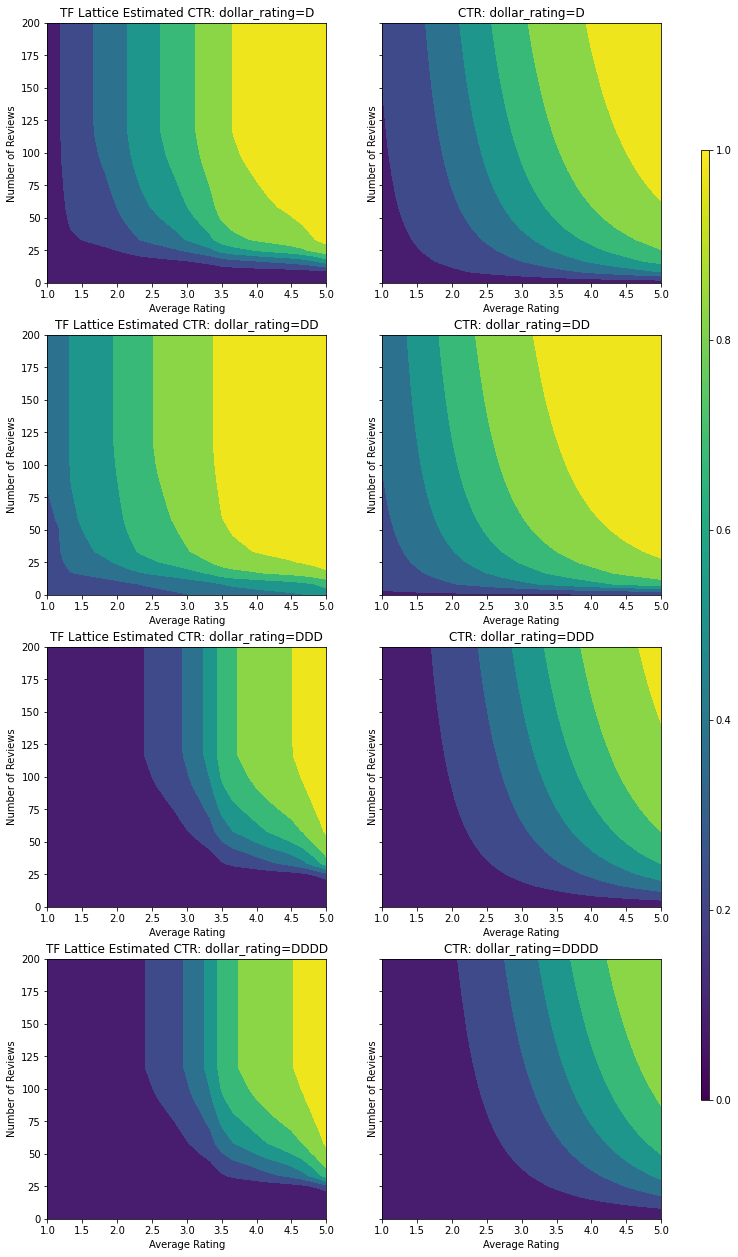
מכייל קטגורי זה מציג את ההעדפה של פלט הדגם: DD > D > DDD > DDDD, מה שעולה בקנה אחד עם ההגדרה שלנו. שימו לב שיש גם עמודה לערכים חסרים. למרות שלא חסרה תכונה בנתוני ההדרכה והבדיקות שלנו, המודל מספק לנו זקיפה לערך החסר אם זה יקרה במהלך הגשת המודל במורד הזרם.
כאן אנו גם העלילה שיעור הקליקים החזוי של מודל זה מותנה dollar_rating . שימו לב שכל האילוצים שדרשנו מתקיימים בכל אחת מהפרוסות.
כיול פלט
עבור כל דגמי ה-TFL שאימנו עד כה, שכבת הסריג (המסומנת כ"סריג" בגרף המודל) מוציאה ישירות את חיזוי המודל. לפעמים אנחנו לא בטוחים אם יש לשנות את קנה המידה של פלט הסריג כדי לפלוט פלטי מודל:
- התכונות הן \(log\) סעיפים בעוד התוויות הן עבירות.
- הסריג מוגדר כך שיהיו לו מעט מאוד קודקודים, אך התפלגות התווית מסובכת יחסית.
במקרים אלו נוכל להוסיף כייל נוסף בין פלט הסריג לפלט הדגם כדי להגביר את גמישות הדגם. כאן בואו נוסיף שכבת כיול עם 5 נקודות מפתח לדגם שזה עתה בנינו. אנו מוסיפים גם מסדר לכייל הפלט כדי לשמור על הפונקציה חלקה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


מדד הבדיקה והעלילות הסופיות מראים כיצד שימוש באילוצים של הגיון בריא יכול לעזור למודל להימנע מהתנהגות בלתי צפויה ולהרחיב טוב יותר לכל מרחב הקלט.
,| | | צפה במקור ב-GitHub | |
סקירה כללית
מדריך זה הוא סקירה כללית של האילוצים והמסדרים המסופקים על ידי ספריית TensorFlow Lattice (TFL). כאן אנו משתמשים באומדנים משומרים של TFL על מערכי נתונים סינתטיים, אך שימו לב שניתן לעשות הכל במדריך זה גם עם מודלים שנבנו משכבות TFL Keras.
לפני שתמשיך, ודא שבזמן הריצה שלך מותקנות כל החבילות הנדרשות (כפי שיובאו בתאי הקוד למטה).
להכין
התקנת חבילת TF Lattice:
pip install -q tensorflow-lattice
ייבוא חבילות נדרשות:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
ערכי ברירת מחדל המשמשים במדריך זה:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
מערך הדרכה לדירוג מסעדות
תארו לעצמכם תרחיש פשוט שבו אנו רוצים לקבוע אם משתמשים ילחצו על תוצאת חיפוש של מסעדה או לא. המשימה היא לחזות את שיעור הקליקים (CTR) בהינתן תכונות קלט:
- דירוג ממוצע (
avg_rating): תכונת ערכים מספרית בטווח [1,5]. - מספר הביקורות (
num_reviews): תכונת ערכים מספרית כתרים ב 200, אשר אנו משתמשים כמדד trendiness. - דירוג דולר (
dollar_rating): תכונת קטגורים עם ערכי מחרוזת בקבוצת { "D", "DD", "DDD", "DDDD"}.
כאן אנו יוצרים מערך נתונים סינתטי שבו שיעור הקליקים האמיתי ניתן על ידי הנוסחה:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
איפה \(b(\cdot)\) מתרגם כל dollar_rating לערך הבסיס:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
נוסחה זו משקפת דפוסי משתמש טיפוסיים. למשל בהינתן כל השאר קבוע, המשתמשים מעדיפים מסעדות עם דירוגי כוכבים גבוהים יותר, ומסעדות "\$\$" יקבלו יותר קליקים מאשר "\$", ואחריהן "\$\$\$" ו-"\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
בואו נסתכל על קווי המתאר של פונקציית CTR זו.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
הכנת נתונים
כעת עלינו ליצור את מערכי הנתונים הסינתטיים שלנו. אנו מתחילים ביצירת מערך נתונים מדומה של מסעדות והתכונות שלהן.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
בואו לייצר את מערכי ההדרכה, האימות והבדיקות. כאשר מסעדה נראית בתוצאות החיפוש, אנו יכולים לתעד את המעורבות של המשתמש (קליק או לא קליק) כנקודה לדוגמה.
בפועל, משתמשים לרוב לא עוברים על כל תוצאות החיפוש. המשמעות היא שסביר להניח שמשתמשים יראו רק מסעדות שכבר נחשבות ל"טובות" לפי מודל הדירוג הנוכחי שנמצא בשימוש. כתוצאה מכך, מסעדות "טובות" מתרשמות בתדירות גבוהה יותר ומיוצגות יתר על המידה במערך הנתונים של ההדרכה. בעת שימוש בתכונות נוספות, מערך ההדרכה יכול להיות בעל פערים גדולים בחלקים "רעים" של מרחב התכונות.
כאשר המודל משמש לדירוג, הוא מוערך לעתים קרובות על כל התוצאות הרלוונטיות עם התפלגות אחידה יותר שאינה מיוצגת היטב על ידי מערך ההדרכה. מודל גמיש ומסובך עלול להיכשל במקרה זה עקב התאמת יתר של נקודות הנתונים המיוצגות יתר על המידה ובכך חוסר יכולת הכללה. אנו מטפלים בבעיה זו על ידי שימוש בידע התחום להוסיף אילוצי צורת מנחי המודל לבצע תחזיות סבירות כשזה לא יכול לאסוף אותם מן נתון הכשרה.
בדוגמה זו, מערך ההדרכה מורכב בעיקר מאינטראקציות של משתמשים עם מסעדות טובות ופופולריות. למערך הנתונים של הבדיקה יש התפלגות אחידה כדי לדמות את הגדרת ההערכה שנדונה לעיל. שים לב שמערך נתונים לבדיקה כזה לא יהיה זמין בהגדרת בעיה אמיתית.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
הגדרת input_fns המשמשים להדרכה והערכה:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
התאמת עצים בעלי שיפור שיפוע
בואו נתחיל עם רק שתי תכונות: avg_rating ו num_reviews .
אנו יוצרים כמה פונקציות עזר לשרטוט וחישוב מדדי אימות ובדיקה.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
אנו יכולים להתאים עצי החלטה עם חיזוק שיפוע של TensorFlow במערך הנתונים:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
למרות שהמודל תפס את הצורה הכללית של שיעור הקליקים האמיתי ויש לו מדדי אימות הגונים, יש לו התנהגות נוגדת אינטואיטיבית בכמה חלקים של מרחב הקלט: שיעור הקליקים המשוער יורד ככל שהדירוג הממוצע או מספר הביקורות עולה. הסיבה לכך היא מחסור בנקודות מדגם באזורים שאינם מכוסים היטב על ידי מערך ההדרכה. למודל פשוט אין דרך להסיק את ההתנהגות הנכונה רק מהנתונים.
כדי לפתור בעיה זו, אנו אוכפים את מגבלת הצורה לפיה המודל חייב להפיק ערכים מונוטוניים הגדלים באופן מונוטוני הן ביחס לדרוג הממוצע והן למספר הביקורות. בהמשך נראה כיצד ליישם זאת ב-TFL.
התאמת DNN
אנחנו יכולים לחזור על אותם שלבים עם מסווג DNN. אנו יכולים להבחין בדפוס דומה: אין מספיק נקודות מדגם עם מספר קטן של ביקורות גורם לאקסטרפולציה חסרת היגיון. שימו לב שלמרות שמדד האימות טוב יותר מפתרון העץ, מדד הבדיקה גרוע בהרבה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
אילוצי צורה
TensorFlow Lattice (TFL) מתמקד באכיפת אילוצי צורה כדי להגן על התנהגות המודל מעבר לנתוני האימון. אילוצי צורה אלו מוחלים על שכבות TFL Keras. ניתן למצוא את פרטיהם בתיבות נייר JMLR שלנו .
במדריך זה אנו משתמשים באומדנים משומרי TF כדי לכסות אילוצי צורה שונים, אך שימו לב שניתן לבצע את כל השלבים הללו עם מודלים שנוצרו משכבות TFL Keras.
כמו בכול הערכת TensorFlow אחרת, TFL משומר אומד להשתמש בעמודות תכונה להגדיר את מבנה הקלט ולהשתמש input_fn כשר להעביר את נתון. שימוש באומדנים משומרים TFL דורש גם:
- תצורת דגם: הגדרת ארכיטקטורת המודל ואילוצי צורה לכול תכונת regularizers.
- input_fn ניתוח תכונה: א TF input_fn העברת נתונים עבור אתחול TFL.
לתיאור יסודי יותר, עיין במדריך לאומדנים משומרים או במסמכי ה-API.
מונוטוניות
תחילה אנו מתייחסים לחששות המונוטוניות על ידי הוספת אילוצי צורת מונוטוניות לשתי התכונות.
כדי להורות TFL לאכוף אילוצי צורה, אנו מגדירים את אילוצי configs התכונה. מופעי הקוד הבאים איך אנחנו יכולים לדרוש את הפלט להיות הגדלת מונוטונית לגבי שני num_reviews ו avg_rating ידי הגדרת monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
באמצעות CalibratedLatticeConfig יוצר מסווג משומר כי הראשון חל כיל לכול קלט (פונקציה לינארית פיסה-חכמה עבור תכונות מספריות) ואחריו שכבת סריג אל הלא-לינארית פתיל התכונות המכוילות. אנו יכולים להשתמש tfl.visualization לדמיין המודל. במיוחד, העלילה הבאה מציגה את שני המכיילים המאומנים הכלולים במסווג המשומר.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
עם האילוצים שנוספו, שיעור הקליקים המשוער תמיד יגדל ככל שהדירוג הממוצע יגדל או מספר הביקורות יגדל. זה נעשה על ידי לוודא שהכייל והסריג מונוטוניים.
החזרות פוחתות
תפוקה שולית פוחת אמצעים כי הרווח השולי של הגדלת ערך תכונה מסוימת יקטן ככל שנגדיל את הערך. במקרה שלנו אנו מצפים כי num_reviews תכונה כדלקמן הדפוס הזה, כדי שנוכל להגדיר כַּיָל שלה בהתאם. שימו לב שאנחנו יכולים לפרק תשואות מצטמצמות לשני תנאים מספיקים:
- המכייל עולה באופן מונוטוני, ו
- המכייל קעור.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
שימו לב כיצד מדד הבדיקה משתפר על ידי הוספת אילוץ הקיעור. עלילת החיזוי גם דומה יותר לאמת הקרקע.
אילוץ צורה דו מימדי: אמון
דירוג של 5 כוכבים למסעדה עם רק ביקורת אחת או שתיים הוא כנראה דירוג לא אמין (ייתכן שהמסעדה לא ממש טובה), בעוד שדירוג 4 כוכבים למסעדה עם מאות ביקורות הוא הרבה יותר אמין (המסעדה היא כנראה טוב במקרה זה). אנו יכולים לראות שמספר הביקורות על מסעדה משפיע על מידת האמון שאנו נותנים בדרוג הממוצע שלה.
אנו יכולים להפעיל אילוצי אמון של TFL כדי ליידע את המודל שהערך הגדול יותר (או הקטן יותר) של תכונה אחת מצביע על יותר הסתמכות או אמון בתכונה אחרת. הדבר נעשה על ידי קביעת reflects_trust_in תצורת config התכונה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
העלילה הבאה מציגה את פונקציית הסריג המאומן. בשל אילוץ האמון, אנו מצפים כי ערכים גדולים יותר של מכויל num_reviews ייאלצו מדרון גבוה ביחס מכויל avg_rating , וכתוצאה מכך מהלך משמעותי יותר בפלט הסריג.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
מחליקים מכיילים
בואו עכשיו נסתכל על כיל של avg_rating . למרות שהוא הולך וגדל באופן מונוטוני, השינויים במדרונות שלו הם פתאומיים וקשים לפירוש. זה מרמז שאנחנו אולי כדאי לשקול החלקת כַּיָל זו באמצעות התקנת regularizer ב regularizer_configs .
כאן אנו להחיל wrinkle regularizer להפחית שינויי העקמומיות. אתה יכול גם להשתמש laplacian regularizer כדי לשטח את כיל ואת hessian regularizer כדי להפוך אותו ליותר ליניארי.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
המכיילים כעת חלקים, ושיעור הקליקים המשוער הכולל תואם טוב יותר את האמת הבסיסית. זה בא לידי ביטוי הן במדד הבדיקה והן במגרשי המתאר.
מונוטוניות חלקית לכיול קטגורי
עד כה השתמשנו רק בשניים מהתכונות המספריות בדגם. כאן נוסיף תכונה שלישית באמצעות שכבת כיול קטגורית. שוב אנו מתחילים בהגדרת פונקציות מסייעות לשרטוט וחישוב מטרי.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
לערב את התכונה השלישית, dollar_rating , עלינו לזכור כי התכונות קטגורי דורשים טיפול מעט שונה TFL, הן בטור תכונה וכתוצאה config תכונה. כאן אנו אוכפים את מגבלת המונוטוניות החלקית לפיה התפוקות עבור מסעדות "DD" צריכות להיות גדולות יותר ממסעדות "D" כאשר כל שאר התשומות קבועות. הדבר נעשה באמצעות monotonicity השוקעת config התכונה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
מכייל קטגורי זה מציג את ההעדפה של פלט הדגם: DD > D > DDD > DDDD, מה שעולה בקנה אחד עם ההגדרה שלנו. שימו לב שיש גם עמודה לערכים חסרים. למרות שלא חסרה תכונה בנתוני ההדרכה והבדיקות שלנו, המודל מספק לנו זקיפה לערך החסר אם זה יקרה במהלך הגשת המודל במורד הזרם.
כאן אנו גם העלילה שיעור הקליקים החזוי של מודל זה מותנה dollar_rating . שימו לב שכל האילוצים שדרשנו מתקיימים בכל אחת מהפרוסות.
כיול פלט
עבור כל דגמי ה-TFL שאימנו עד כה, שכבת הסריג (המסומנת כ"סריג" בגרף המודל) מוציאה ישירות את חיזוי המודל. לפעמים אנחנו לא בטוחים אם יש לשנות את קנה המידה של פלט הסריג כדי לפלוט פלטי מודל:
- התכונות הן \(log\) סעיפים בעוד התוויות הן עבירות.
- הסריג מוגדר כך שיהיו לו מעט מאוד קודקודים, אך התפלגות התווית מסובכת יחסית.
במקרים אלו נוכל להוסיף כייל נוסף בין פלט הסריג לפלט הדגם כדי להגביר את גמישות הדגם. כאן בואו נוסיף שכבת כיול עם 5 נקודות מפתח לדגם שזה עתה בנינו. אנו מוסיפים גם מסדר לכייל הפלט כדי לשמור על הפונקציה חלקה.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
מדד הבדיקה והעלילות הסופיות מראים כיצד שימוש באילוצים של הגיון בריא יכול לעזור למודל להימנע מהתנהגות בלתי צפויה ולהרחיב טוב יותר לכל מרחב הקלט.