
| |
การแนะนำ
โมเดลภาษาขนาดใหญ่ (LLM) คือคลาสของโมเดลการเรียนรู้ของเครื่องที่ได้รับการฝึกฝนให้สร้างข้อความตามชุดข้อมูลขนาดใหญ่ สามารถใช้สำหรับงานประมวลผลภาษาธรรมชาติ (NLP) รวมถึงการสร้างข้อความ การตอบคำถาม และการแปลด้วยเครื่อง ขึ้นอยู่กับสถาปัตยกรรม Transformer และได้รับการฝึกอบรมเกี่ยวกับข้อมูลข้อความจำนวนมหาศาล ซึ่งมักจะเกี่ยวข้องกับคำศัพท์หลายพันล้านคำ แม้แต่ LLM ที่มีขนาดเล็กกว่า เช่น GPT-2 ก็สามารถทำงานได้อย่างน่าประทับใจ การแปลงโมเดล TensorFlow ให้เป็นโมเดลที่เบากว่า เร็วกว่า และใช้พลังงานต่ำช่วยให้เราสามารถรันโมเดล AI เจนเนอเรชั่นบนอุปกรณ์ได้ พร้อมข้อดีของการรักษาความปลอดภัยของผู้ใช้ที่ดีขึ้น เนื่องจากข้อมูลจะไม่มีวันออกจากอุปกรณ์ของคุณ
คู่มือรันนี้จะแสดงวิธีสร้างแอป Android ด้วย TensorFlow Lite เพื่อเรียกใช้ Keras LLM และให้คำแนะนำสำหรับการเพิ่มประสิทธิภาพโมเดลโดยใช้เทคนิคการวัดปริมาณ ซึ่งมิฉะนั้นจะต้องใช้หน่วยความจำจำนวนมากขึ้นมากและพลังในการคำนวณที่มากขึ้นในการรัน
เรามีเฟรมเวิร์ กแอป Android แบบโอเพ่นซอร์ส ที่ TFLite LLM ที่เข้ากันได้สามารถเสียบเข้ากับได้ นี่คือการสาธิตสองรายการ:
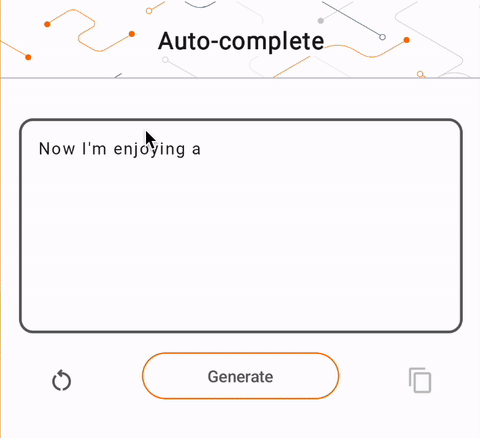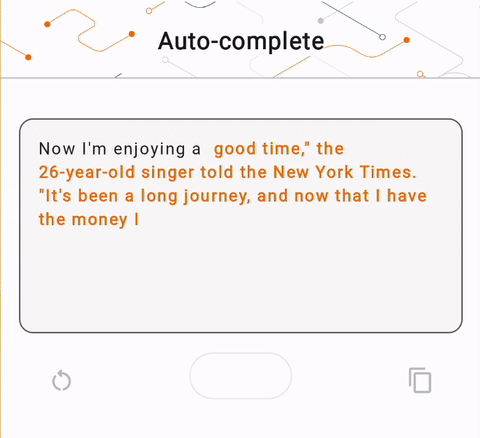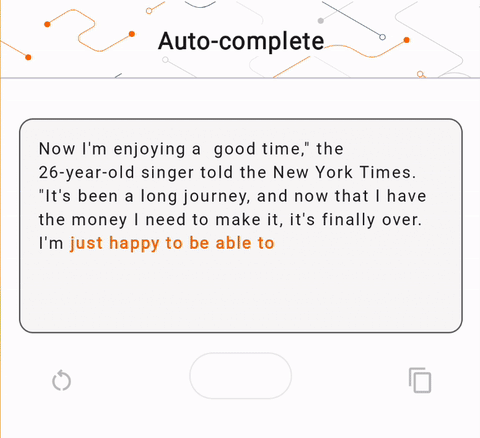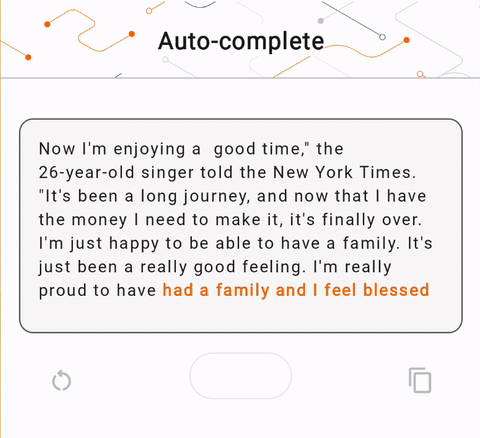
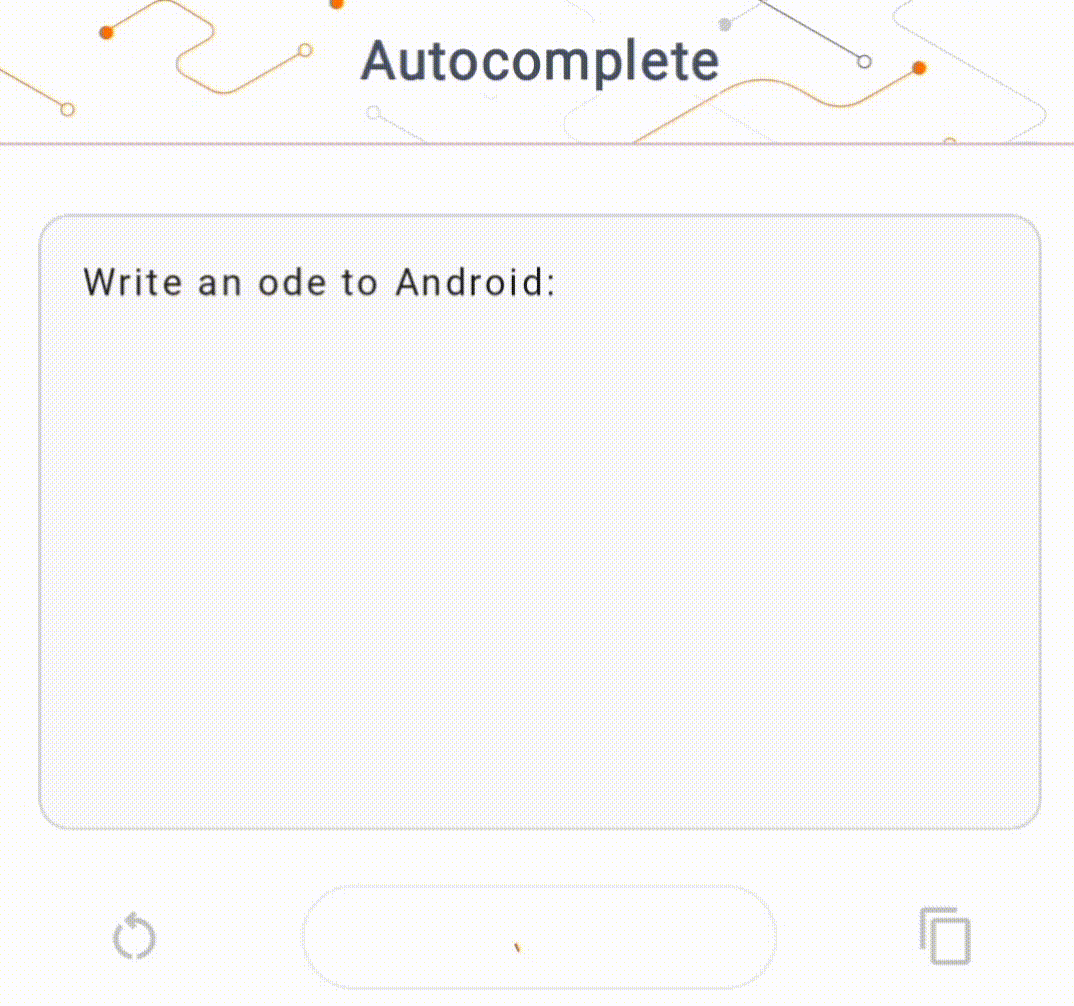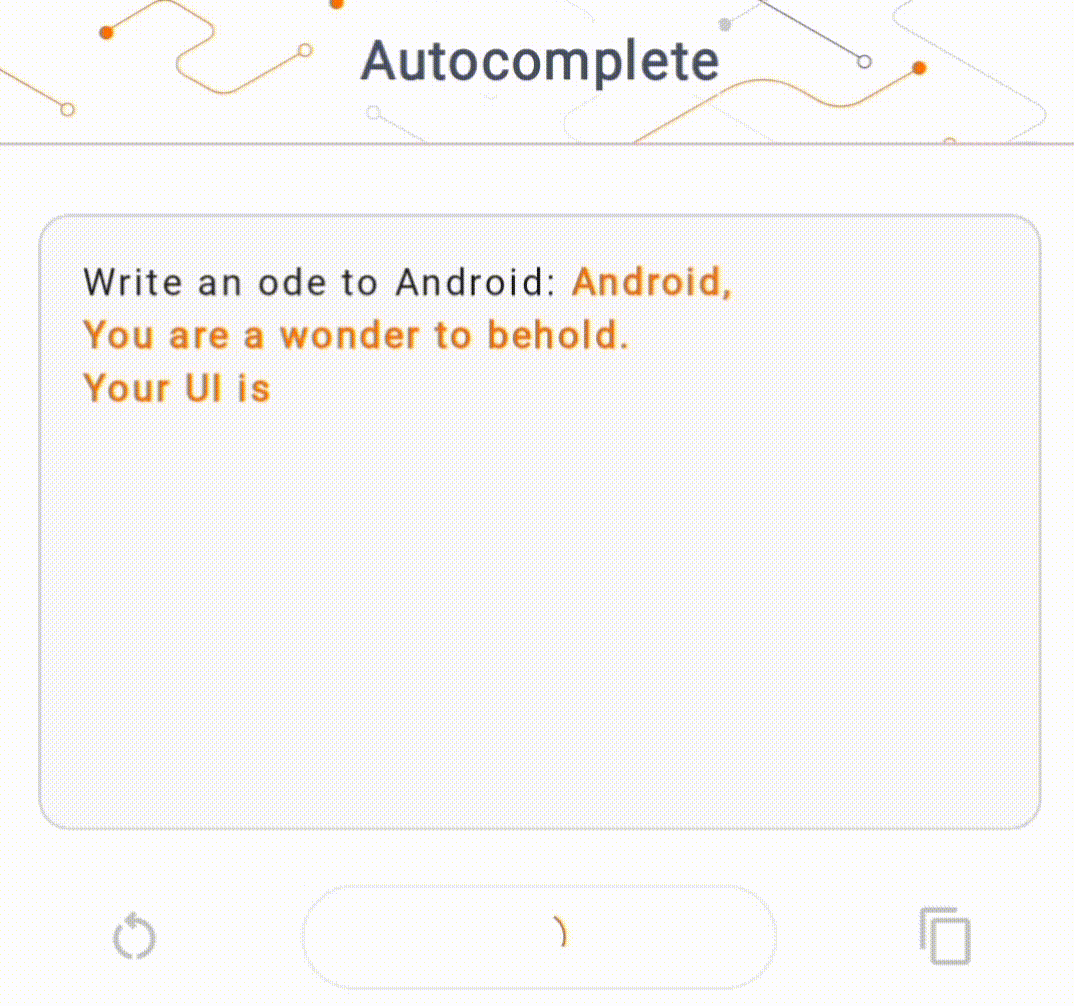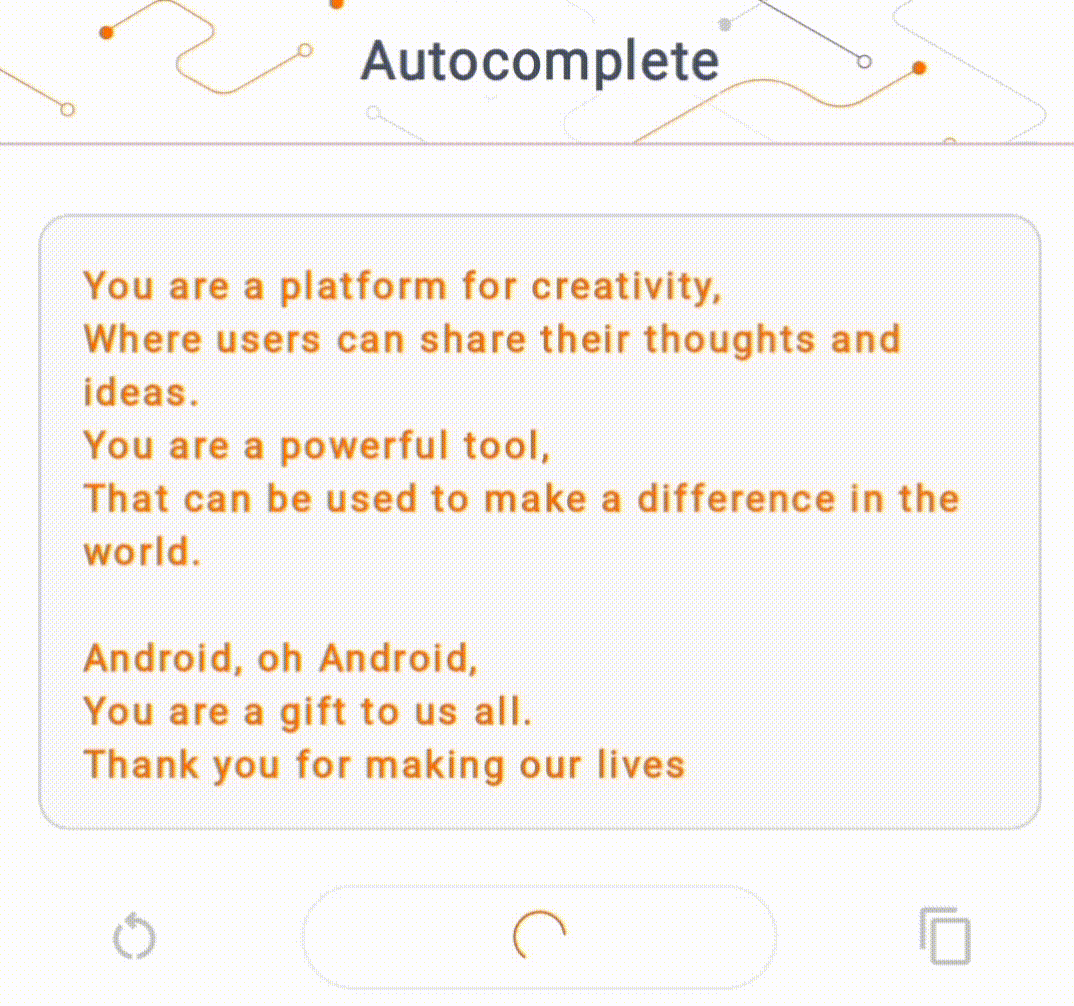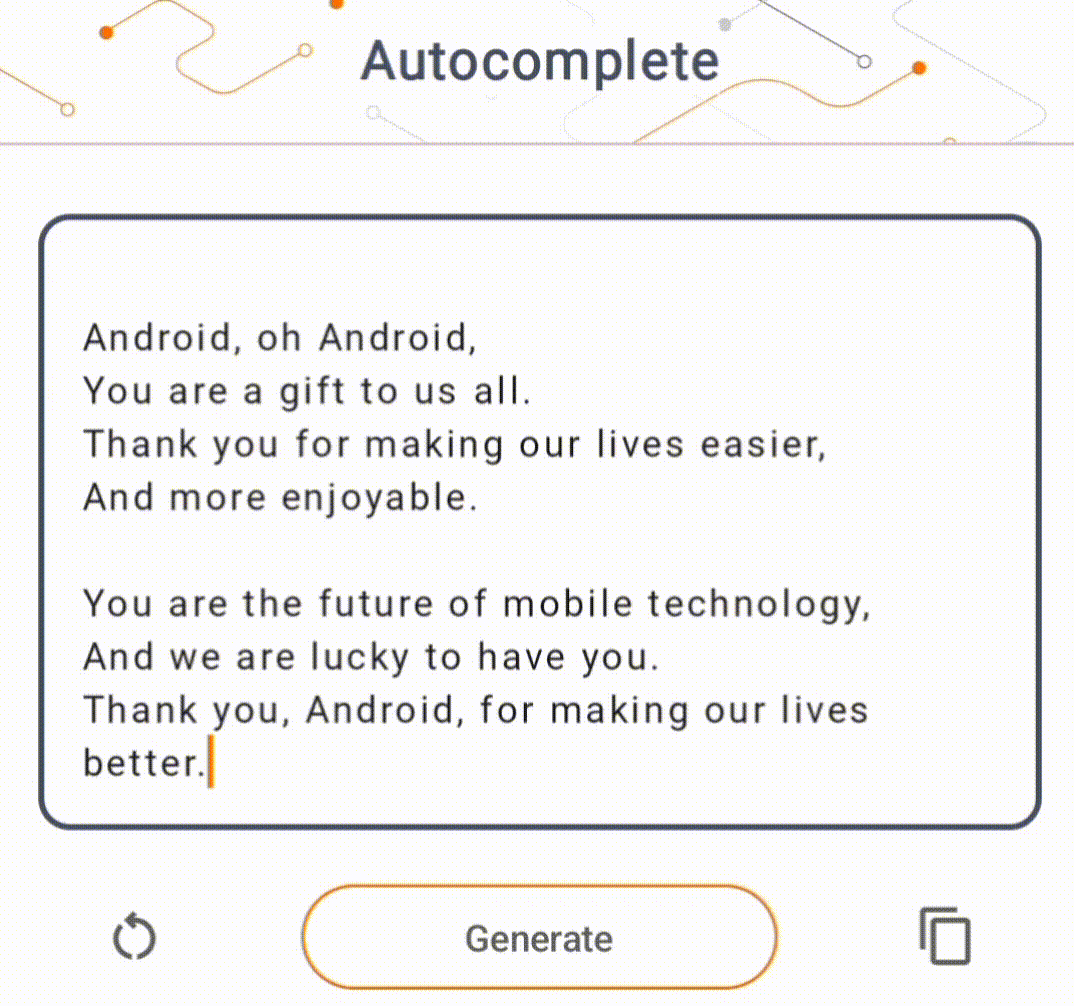
- ในรูปที่ 1 เราใช้โมเดล Keras GPT-2 เพื่อดำเนินการเติมข้อความบนอุปกรณ์
- ในรูปที่ 2 เราได้แปลงเวอร์ชันของ โมเดล PaLM ที่ปรับแต่งตามคำสั่ง (พารามิเตอร์ 1.5 พันล้านพารามิเตอร์) เป็น TFLite และดำเนินการผ่านรันไทม์ TFLite
คำแนะนำ
การเขียนแบบจำลอง
สำหรับการสาธิตนี้ เราจะใช้ KerasNLP เพื่อรับโมเดล GPT-2 KerasNLP เป็นไลบรารีที่ประกอบด้วยโมเดลที่ได้รับการฝึกล่วงหน้าอันล้ำสมัยสำหรับงานการประมวลผลภาษาธรรมชาติ และสามารถรองรับผู้ใช้ตลอดวงจรการพัฒนาทั้งหมดได้ คุณสามารถดูรายการรุ่นที่มีอยู่ใน ที่เก็บ KerasNLP ขั้นตอนการทำงานสร้างขึ้นจากส่วนประกอบแบบโมดูลาร์ที่มีน้ำหนักและสถาปัตยกรรมที่ตั้งไว้ล่วงหน้าที่ล้ำสมัยเมื่อใช้งานนอกกรอบ และปรับแต่งได้ง่ายเมื่อจำเป็นต้องมีการควบคุมเพิ่มเติม การสร้างโมเดล GPT-2 สามารถทำได้โดยทำตามขั้นตอนต่อไปนี้:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
ความเหมือนกันอย่างหนึ่งในโค้ดทั้งสามบรรทัดนี้คือเมธอด from_preset() ซึ่งจะสร้างอินสแตนซ์ส่วนของ Keras API จากสถาปัตยกรรมที่กำหนดไว้ล่วงหน้าและ/หรือน้ำหนัก ดังนั้น จึงโหลดโมเดลที่ได้รับการฝึกล่วงหน้า จากข้อมูลโค้ดนี้ คุณจะสังเกตเห็นส่วนประกอบแบบโมดูลาร์สามส่วน:
Tokenizer : แปลงอินพุตสตริงดิบเป็น ID โทเค็นจำนวนเต็มที่เหมาะสมสำหรับเลเยอร์ Keras Embedding GPT-2 ใช้โทเค็นไนเซอร์การเข้ารหัสคู่ไบต์ (BPE) โดยเฉพาะ
ตัวประมวลผลล่วงหน้า : เลเยอร์สำหรับโทเค็นและบรรจุอินพุตที่จะป้อนลงในโมเดล Keras ในที่นี้ ตัวประมวลผลล่วงหน้าจะแพดเทนเซอร์ของรหัสโทเค็นตามความยาวที่ระบุ (256) หลังจากโทเค็น
แบ็คโบน : โมเดล Keras ที่เป็นไปตามสถาปัตยกรรมแบ็คโบนของหม้อแปลง SoTA และมีน้ำหนักที่ตั้งไว้ล่วงหน้า
นอกจากนี้ คุณสามารถตรวจสอบการใช้งานโมเดล GPT-2 แบบเต็มได้บน GitHub
การแปลงโมเดล
TensorFlow Lite เป็นไลบรารีเคลื่อนที่สำหรับการปรับใช้วิธีการบนอุปกรณ์เคลื่อนที่ ไมโครคอนโทรลเลอร์ และอุปกรณ์ Edge อื่นๆ ขั้นตอนแรกคือการแปลงโมเดล Keras เป็นรูปแบบ TensorFlow Lite ที่กะทัดรัดยิ่งขึ้นโดยใช้ตัว แปลง TensorFlow Lite จากนั้นใช้ ล่าม TensorFlow Lite ซึ่งได้รับการปรับให้เหมาะสมที่สุดสำหรับอุปกรณ์มือถือ เพื่อเรียกใช้โมเดลที่แปลงแล้ว
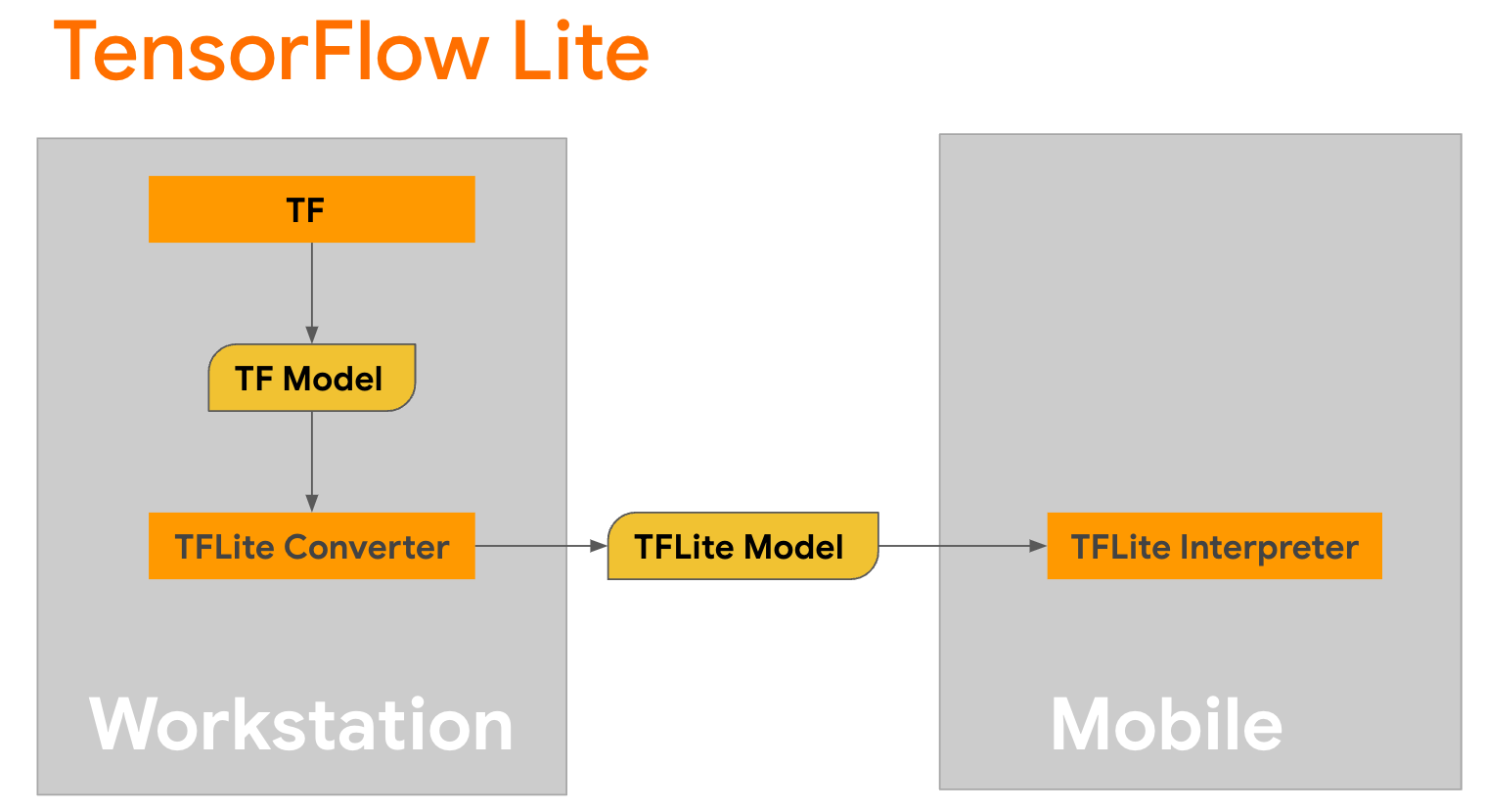 เริ่มต้นด้วยฟังก์ชัน
เริ่มต้นด้วยฟังก์ชัน generate() จาก GPT2CausalLM ที่ทำการแปลง รวมฟังก์ชัน generate() เพื่อสร้างฟังก์ชัน TensorFlow ที่เป็นรูปธรรม:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
โปรดทราบว่าคุณสามารถใช้ from_keras_model() จาก TFLiteConverter เพื่อทำการแปลงได้
ตอนนี้ให้กำหนดฟังก์ชันตัวช่วยที่จะรันการอนุมานด้วยอินพุตและโมเดล TFLite ตัวเลือกข้อความ TensorFlow ไม่ใช่ตัวเลือกในตัวในรันไทม์ TFLite ดังนั้นคุณจะต้องเพิ่มตัวเลือกที่กำหนดเองเหล่านี้เพื่อให้ล่ามทำการอนุมานโมเดลนี้ได้ ฟังก์ชันตัวช่วยนี้ยอมรับอินพุตและฟังก์ชันที่ทำการแปลง กล่าวคือฟังก์ชัน generator() ที่กำหนดไว้ข้างต้น
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
คุณสามารถแปลงโมเดลได้ทันที:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
การหาปริมาณ
TensorFlow Lite ได้ใช้เทคนิคการเพิ่มประสิทธิภาพที่เรียกว่า การหาปริมาณ ซึ่งสามารถลดขนาดโมเดลและเร่งการอนุมานได้ ด้วยกระบวนการหาปริมาณ โฟลตแบบ 32 บิตจะถูกแมปกับจำนวนเต็ม 8 บิตที่เล็กลง ดังนั้น จึงลดขนาดโมเดลลง 4 เท่าเพื่อการดำเนินการที่มีประสิทธิภาพมากขึ้นบนฮาร์ดแวร์สมัยใหม่ การทำปริมาณใน TensorFlow มีหลายวิธี คุณสามารถไปที่หน้า การเพิ่มประสิทธิภาพโมเดล TFLite และ ชุดเครื่องมือเพิ่มประสิทธิภาพโมเดล TensorFlow เพื่อดูข้อมูลเพิ่มเติม ประเภทของการหาปริมาณจะอธิบายโดยย่อด้านล่างนี้
ที่นี่ คุณจะใช้ การวัดปริมาณช่วงไดนามิกหลังการฝึก ในโมเดล GPT-2 โดยการตั้งค่าแฟล็กการเพิ่มประสิทธิภาพตัวแปลงเป็น tf.lite.Optimize.DEFAULT และกระบวนการแปลงที่เหลือจะเหมือนกับรายละเอียดก่อนหน้านี้ เราทดสอบว่าด้วยเทคนิคการหาปริมาณนี้ เวลาแฝงจะอยู่ที่ประมาณ 6.7 วินาทีบน Pixel 7 โดยตั้งค่าความยาวเอาต์พุตสูงสุดไว้ที่ 100
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
ช่วงไดนามิก
การหาปริมาณช่วงไดนามิกเป็นจุดเริ่มต้นที่แนะนำสำหรับการเพิ่มประสิทธิภาพโมเดลในอุปกรณ์ สามารถลดขนาดโมเดลลงได้ประมาณ 4 เท่า และเป็นจุดเริ่มต้นที่แนะนำ เนื่องจากช่วยลดการใช้หน่วยความจำและการคำนวณที่รวดเร็วขึ้น โดยที่คุณไม่ต้องจัดเตรียมชุดข้อมูลตัวแทนสำหรับการสอบเทียบ การหาปริมาณประเภทนี้จะวัดปริมาณแบบคงที่เฉพาะน้ำหนักจากจุดลอยตัวถึงจำนวนเต็ม 8 บิต ณ เวลาที่แปลง
FP16
โมเดลจุดลอยตัวยังสามารถปรับให้เหมาะสมได้โดยการวัดปริมาณน้ำหนักเป็นประเภท float16 ข้อดีของ การหาปริมาณ float16 คือการลดขนาดของโมเดลลงถึงครึ่งหนึ่ง (เนื่องจากน้ำหนักทั้งหมดมีขนาดลดลงครึ่งหนึ่ง) ทำให้สูญเสียความแม่นยำน้อยที่สุด และรองรับผู้ร่วมประชุม GPU ที่สามารถทำงานบนข้อมูล float16 ได้โดยตรง (ซึ่งส่งผลให้การคำนวณเร็วกว่าบน float32 ข้อมูล). แบบจำลองที่แปลงเป็นน้ำหนัก float16 ยังคงสามารถทำงานบน CPU ได้โดยไม่ต้องแก้ไขเพิ่มเติม น้ำหนัก float16 ได้รับการสุ่มตัวอย่างเป็น float32 ก่อนการอนุมานครั้งแรก ซึ่งช่วยลดขนาดโมเดลเพื่อแลกกับผลกระทบที่น้อยที่สุดต่อเวลาแฝงและความแม่นยำ
การหาปริมาณจำนวนเต็ม
การหาจำนวนเต็มจำนวนเต็ม จะแปลงตัวเลขทศนิยม 32 บิต รวมถึงน้ำหนักและการเปิดใช้งาน ไปเป็นจำนวนเต็ม 8 บิตที่ใกล้ที่สุด การหาปริมาณประเภทนี้ส่งผลให้โมเดลมีขนาดเล็กลงและมีความเร็วในการอนุมานเพิ่มขึ้น ซึ่งมีประโยชน์อย่างเหลือเชื่อเมื่อใช้ไมโครคอนโทรลเลอร์ แนะนำให้ใช้โหมดนี้เมื่อการเปิดใช้งานมีความละเอียดอ่อนต่อการหาปริมาณ
การรวมแอพ Android
คุณสามารถทำตาม ตัวอย่าง Android นี้เพื่อรวมโมเดล TFLite ของคุณเข้ากับแอป Android
ข้อกำหนดเบื้องต้น
หากคุณยังไม่ได้ติดตั้ง Android Studio ตามคำแนะนำบนเว็บไซต์
- Android Studio 2022.2.1 ขึ้นไป
- อุปกรณ์ Android หรือโปรแกรมจำลอง Android ที่มีหน่วยความจำมากกว่า 4G
การสร้างและใช้งานด้วย Android Studio
- เปิด Android Studio และจากหน้าจอต้อนรับ ให้เลือก เปิดโครงการ Android Studio ที่มีอยู่
- จากหน้าต่าง Open File หรือ Project ที่ปรากฏขึ้น ให้นำทางไปยังและเลือกไดเร็กทอรี
lite/examples/generative_ai/androidจากทุกที่ที่คุณโคลน repo GitHub ตัวอย่าง TensorFlow Lite - คุณอาจต้องติดตั้งแพลตฟอร์มและเครื่องมือต่าง ๆ ตามข้อความแสดงข้อผิดพลาด
- เปลี่ยนชื่อโมเดล .tflite ที่แปลงแล้วเป็น
autocomplete.tfliteและคัดลอกลงในโฟลเดอร์app/src/main/assets/ - เลือกเมนู สร้าง -> สร้างโครงการ เพื่อสร้างแอป (Ctrl+F9 ขึ้นอยู่กับเวอร์ชันของคุณ)
- คลิกเมนู Run -> Run 'app' (Shift+F10 ขึ้นอยู่กับเวอร์ชันของคุณ)
หรือคุณสามารถใช้ gradle wrapper เพื่อสร้างมันในบรรทัดคำสั่งได้ โปรดดู เอกสารประกอบ Gradle สำหรับข้อมูลเพิ่มเติม
(ทางเลือก) การสร้างไฟล์ .aar
ตามค่าเริ่มต้น แอปจะดาวน์โหลดไฟล์ .aar ที่จำเป็นโดยอัตโนมัติ แต่ถ้าคุณต้องการสร้างของคุณเอง ให้สลับไปที่ app/libs/build_aar/ folder run ./build_aar.sh สคริปต์นี้จะดึงการดำเนินการที่จำเป็นจาก TensorFlow Text และสร้าง aar สำหรับตัวดำเนินการ Select TF
หลังจากการคอมไพล์ ไฟล์ใหม่ tftext_tflite_flex.aar จะถูกสร้างขึ้น แทนที่ไฟล์ .aar ในโฟลเดอร์ app/libs/ และสร้างแอปใหม่
โปรดทราบว่าคุณยังคงต้องรวม aar มาตรฐาน tensorflow-lite ไว้ในไฟล์ gradle ของคุณ
ขนาดหน้าต่างบริบท
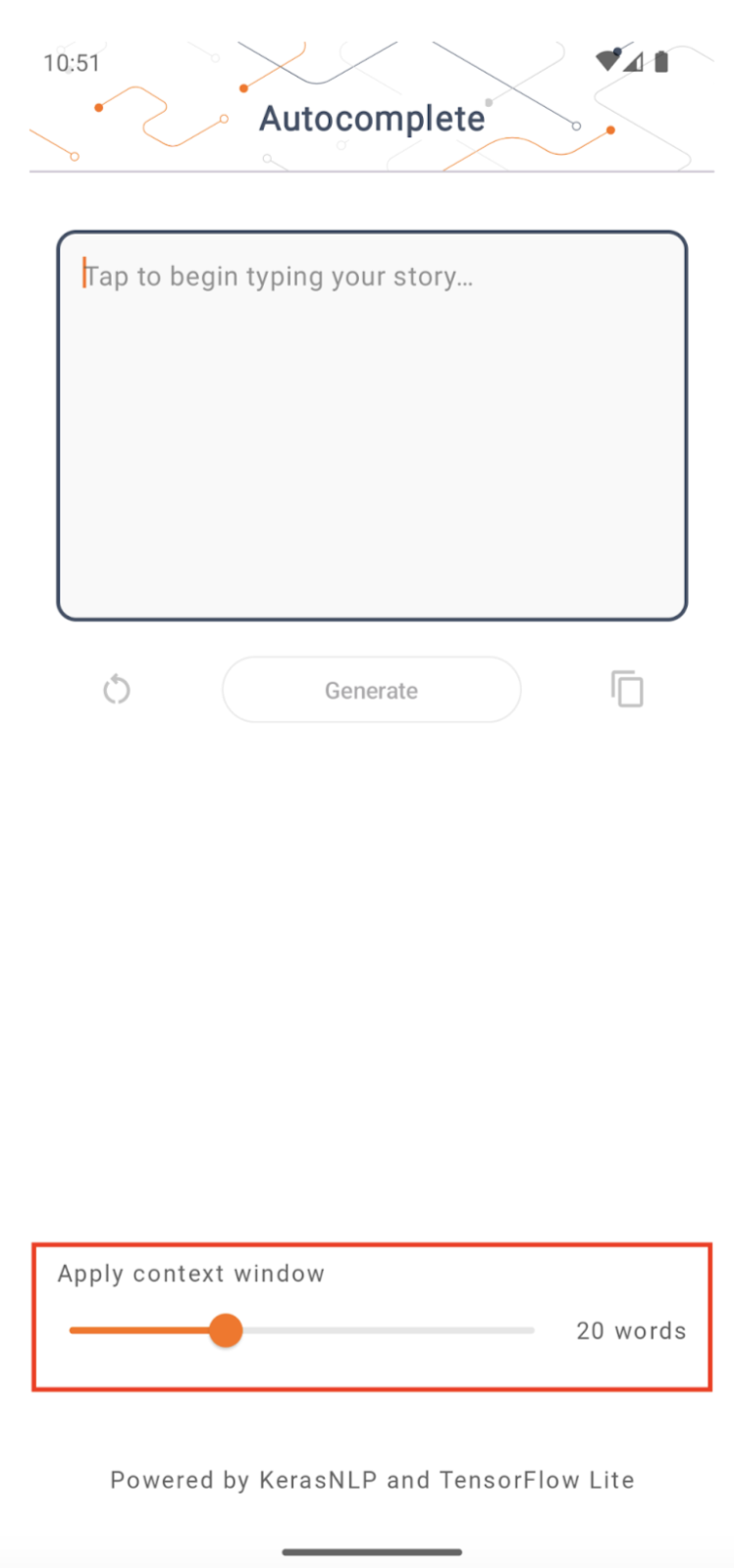
แอปมีพารามิเตอร์ 'ขนาดหน้าต่างบริบท' ที่เปลี่ยนแปลงได้ ซึ่งจำเป็นเนื่องจากโดยทั่วไปแล้ว LLM ในปัจจุบันจะมีขนาดบริบทคงที่ซึ่งจำกัดจำนวนคำ/โทเค็นที่สามารถป้อนลงในโมเดลเป็น 'พร้อมท์' (โปรดทราบว่า 'คำ' ไม่จำเป็น เทียบเท่ากับ 'โทเค็น' ในกรณีนี้ เนื่องจากวิธีการโทเค็นต่างกัน) หมายเลขนี้มีความสำคัญเนื่องจาก:
- การตั้งค่าให้เล็กเกินไป โมเดลจะไม่มีบริบทเพียงพอที่จะสร้างผลลัพธ์ที่มีความหมาย
- การตั้งค่าให้ใหญ่เกินไป โมเดลจะไม่มีพื้นที่เพียงพอในการทำงาน (เนื่องจากลำดับเอาต์พุตรวมพรอมต์ไว้ด้วย)
คุณสามารถทดลองใช้งานได้ แต่การตั้งค่าเป็น ~50% ของความยาวลำดับเอาต์พุตเป็นการเริ่มต้นที่ดี
AI ที่ปลอดภัยและมีความรับผิดชอบ
ตามที่ระบุไว้ใน ประกาศ OpenAI GPT-2 ดั้งเดิม มี คำเตือนและข้อจำกัดที่โดดเด่น สำหรับรุ่น GPT-2 ในความเป็นจริง LLM ในปัจจุบันโดยทั่วไปมีความท้าทายบางอย่างที่รู้จักกันดี เช่น ภาพหลอน ความเป็นธรรม และอคติ; เนื่องจากโมเดลเหล่านี้ได้รับการฝึกอบรมเกี่ยวกับข้อมูลในโลกแห่งความเป็นจริง ซึ่งทำให้โมเดลเหล่านี้สะท้อนถึงปัญหาในโลกแห่งความเป็นจริง
Codelab นี้สร้างขึ้นเพื่อสาธิตวิธีสร้างแอปที่ขับเคลื่อนโดย LLM ด้วยเครื่องมือ TensorFlow เท่านั้น โมเดลที่ผลิตใน Codelab นี้มีวัตถุประสงค์เพื่อการศึกษาเท่านั้น และไม่ได้มีไว้สำหรับการใช้งานจริง
การใช้งานการผลิต LLM จำเป็นต้องเลือกชุดข้อมูลการฝึกอบรมอย่างรอบคอบและการบรรเทาผลกระทบด้านความปลอดภัยที่ครอบคลุม ฟังก์ชันหนึ่งที่นำเสนอในแอป Android นี้คือตัวกรองคำหยาบคาย ซึ่งจะปฏิเสธอินพุตของผู้ใช้หรือเอาต์พุตโมเดลที่ไม่เหมาะสม หากตรวจพบภาษาที่ไม่เหมาะสม แอปจะปฏิเสธการกระทำนั้นเป็นการตอบแทน หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Responsible AI ในบริบทของ LLM อย่าลืมชมเซสชันทางเทคนิคของ Responsible Development with Generative Language Models ที่ Google I/O 2023 และดู ชุดเครื่องมือ Responsible AI Toolkit