
| |  Kaynağı GitHub'da görüntüle Kaynağı GitHub'da görüntüle |
Kişiselleştirilmiş öneriler, mobil cihazlarda medya içeriği alma, alışveriş ürünü önerisi ve sonraki uygulama önerisi gibi çeşitli kullanım durumları için yaygın olarak kullanılmaktadır. Kullanıcı gizliliğine saygı göstererek uygulamanızda kişiselleştirilmiş öneriler sunmak istiyorsanız aşağıdaki örneği ve araç setini incelemenizi öneririz.
Başlamak
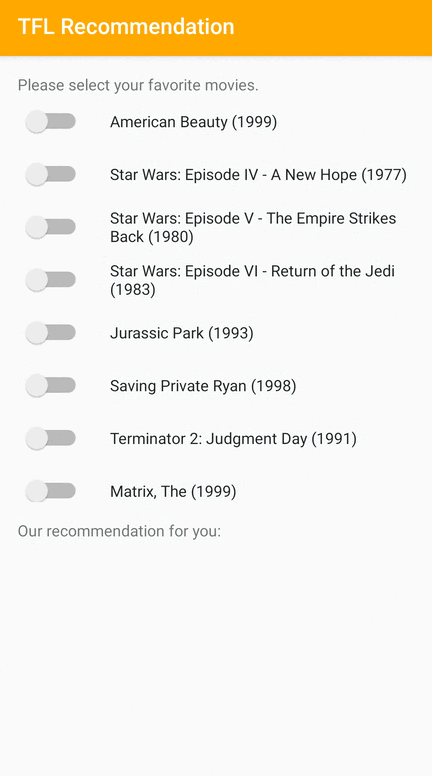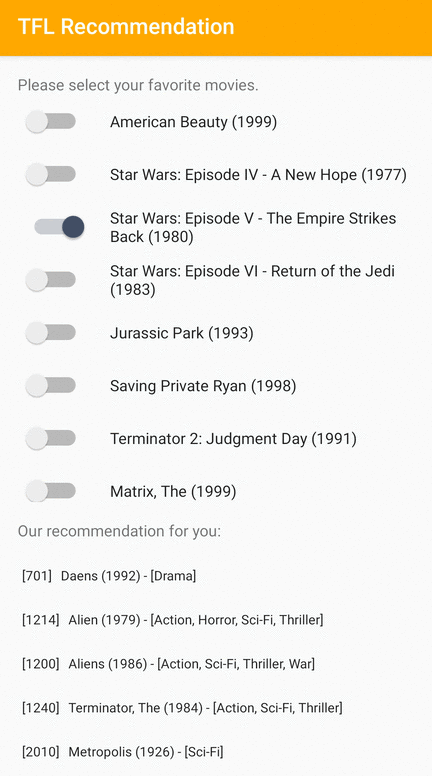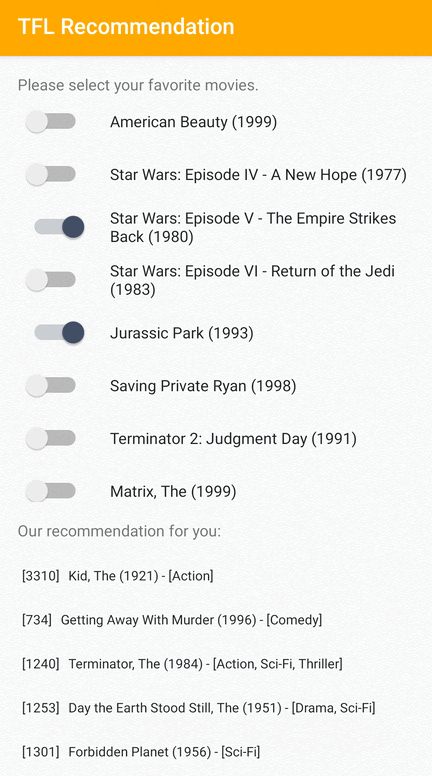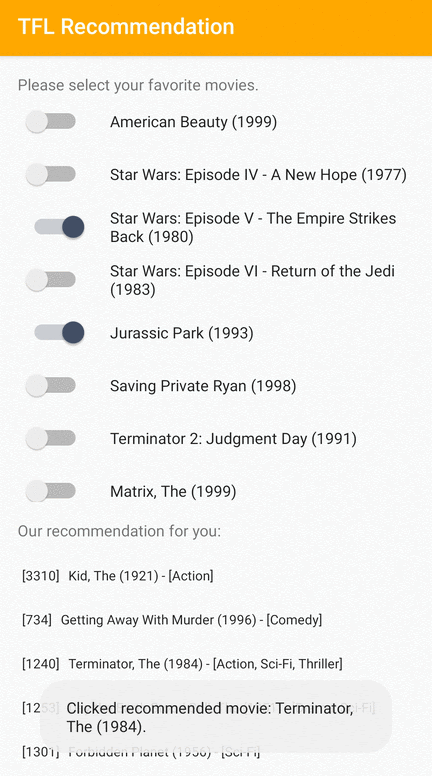
İlgili öğelerin Android'deki kullanıcılara nasıl önerileceğini gösteren bir TensorFlow Lite örnek uygulaması sunuyoruz.
Android dışında bir platform kullanıyorsanız veya TensorFlow Lite API'lerine zaten aşina iseniz başlangıç öneri modelimizi indirebilirsiniz.
Kendi modelinizi yapılandırılabilir bir şekilde eğitmek için Github'da eğitim komut dosyası da sağlıyoruz.
Model mimarisini anlayın
Sıralı kullanıcı geçmişini kodlamak için bağlam kodlayıcı ve tahmin edilen öneri adayını kodlamak için etiket kodlayıcı içeren çift kodlayıcılı bir model mimarisinden yararlanıyoruz. Bağlam ve etiket kodlamaları arasındaki benzerlik, tahmin edilen adayın kullanıcının ihtiyaçlarını karşılama olasılığını temsil etmek için kullanılır.
Bu kod tabanında üç farklı sıralı kullanıcı geçmişi kodlama tekniği sağlanmaktadır:
- Kelime çantası kodlayıcı (BOW): bağlam sırasını dikkate almadan kullanıcı etkinliklerinin yerleştirmelerinin ortalamasını alır.
- Evrişimli sinir ağı kodlayıcısı (CNN): bağlam kodlaması oluşturmak için birden çok evrişimli sinir ağı katmanının uygulanması.
- Tekrarlayan sinir ağı kodlayıcısı (RNN): içerik sırasını kodlamak için tekrarlayan sinir ağının uygulanması.
Her bir kullanıcı etkinliğini modellemek için etkinlik öğesinin kimliğini (kimlik tabanlı) veya öğenin birden fazla özelliğini (özellik tabanlı) veya her ikisinin bir kombinasyonunu kullanabiliriz. Kullanıcı davranışlarını toplu olarak kodlamak için birden fazla özelliği kullanan özellik tabanlı model. Bu kod tabanıyla, ID tabanlı veya özellik tabanlı modelleri yapılandırılabilir bir şekilde oluşturabilirsiniz.
Eğitimden sonra, öneri adayları arasında doğrudan en iyi K tahminlerini sağlayabilecek bir TensorFlow Lite modeli dışa aktarılacaktır.
Egzersiz verilerinizi kullanın
Eğitilen modele ek olarak, modelleri kendi verilerinizle eğitmek için GitHub'da açık kaynaklı bir araç seti sağlıyoruz. Araç setini nasıl kullanacağınızı ve eğitilen modelleri kendi mobil uygulamalarınızda nasıl dağıtacağınızı öğrenmek için bu eğitimi takip edebilirsiniz.
Kendi veri kümelerinizi kullanarak bir öneri modeli eğitmek için burada kullanılan tekniğin aynısını uygulamak için lütfen bu öğreticiyi izleyin.
Örnekler
Örnek olarak öneri modellerini hem kimlik tabanlı hem de özellik tabanlı yaklaşımlarla eğittik. Kimlik tabanlı model, giriş olarak yalnızca film kimliklerini alır ve özellik tabanlı model, giriş olarak hem film kimliklerini hem de film türü kimliklerini alır. Lütfen aşağıdaki giriş ve çıkış örneklerini bulun.
Girişler
Bağlam film kimlikleri:
- Aslan Kral (ID: 362)
- Oyuncak Hikayesi (ID: 1)
- (ve dahası)
Bağlam filmi tür kimlikleri:
- Animasyon (ID: 15)
- Çocuk (ID: 9)
- Müzikal (ID: 13)
- Animasyon (ID: 15)
- Çocuk (ID: 9)
- Komedi (ID: 2)
- (ve dahası)
Çıktılar:
- Önerilen film kimlikleri:
- Oyuncak Hikayesi 2 (ID: 3114)
- (ve dahası)
Performans kıyaslamaları
Performans kıyaslama numaraları burada açıklanan araçla oluşturulur.
| Model adı | Model Boyutu | Cihaz | İşlemci |
|---|---|---|---|
| öneri (giriş olarak film kimliği) | 0,52 Mb | Piksel 3 | 0,09 ms* |
| Piksel 4 | 0,05 ms* | ||
| öneri (giriş olarak film kimliği ve film türü) | 1,3 MB | Piksel 3 | 0,13 ms* |
| Piksel 4 | 0,06 ms* |
* 4 konu kullanıldı.
Egzersiz verilerinizi kullanın
Eğitilen modele ek olarak, modelleri kendi verilerinizle eğitmek için GitHub'da açık kaynaklı bir araç seti sağlıyoruz. Araç setini nasıl kullanacağınızı ve eğitilen modelleri kendi mobil uygulamalarınızda nasıl dağıtacağınızı öğrenmek için bu eğitimi takip edebilirsiniz.
Kendi veri kümelerinizi kullanarak bir öneri modeli eğitmek için burada kullanılan tekniğin aynısını uygulamak için lütfen bu öğreticiyi izleyin.
Verilerinizle model özelleştirmeye yönelik ipuçları
Bu demo uygulamasına entegre edilen önceden eğitilmiş model, MovieLens veri kümesiyle eğitilmiştir; kelime boyutu, yerleştirme karartmaları ve giriş bağlamı uzunluğu gibi kendi verilerinize göre model yapılandırmasını değiştirmek isteyebilirsiniz. İşte birkaç ipucu:
Giriş bağlamı uzunluğu: En iyi giriş bağlamı uzunluğu veri kümelerine göre değişir. Giriş bağlamı uzunluğunu, etiket olaylarının uzun vadeli ilgilerle ne kadar ilişkili olduğuna ve kısa vadeli bağlamla ne kadar ilişkili olduğuna bağlı olarak seçmenizi öneririz.
Kodlayıcı türü seçimi: Giriş içeriği uzunluğuna göre kodlayıcı türünü seçmenizi öneririz. Kelime çantası kodlayıcısı, kısa giriş bağlamı uzunluğu için (örn. <10) iyi çalışır; CNN ve RNN kodlayıcıları, uzun giriş bağlamı uzunluğu için daha fazla özetleme yeteneği sağlar.
Öğeleri veya kullanıcı etkinliklerini temsil etmek için temel özelliklerin kullanılması, model performansını iyileştirebilir, yeni öğeleri daha iyi barındırabilir, muhtemelen yerleştirme alanlarının ölçeğini küçültebilir, dolayısıyla bellek tüketimini azaltabilir ve daha cihaz dostu olabilir.