
| |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub |
I consigli personalizzati sono ampiamente utilizzati per una varietà di casi d'uso sui dispositivi mobili, come il recupero di contenuti multimediali, suggerimenti sui prodotti per l'acquisto e consigli sull'app successiva. Se sei interessato a fornire consigli personalizzati nella tua applicazione rispettando la privacy dell'utente, ti consigliamo di esplorare l'esempio e il toolkit seguenti.
Iniziare
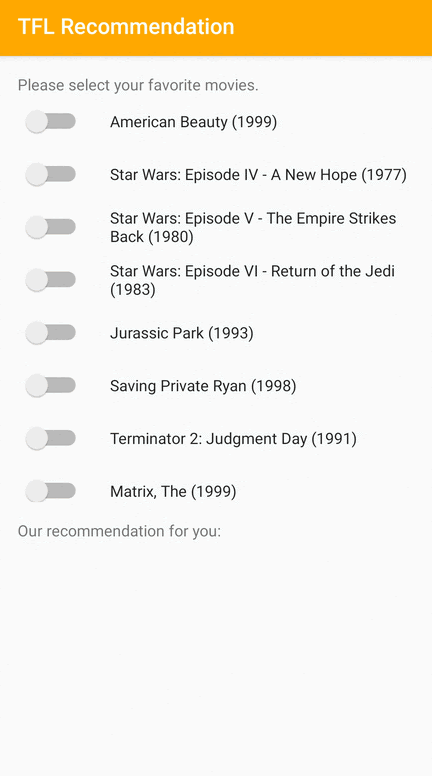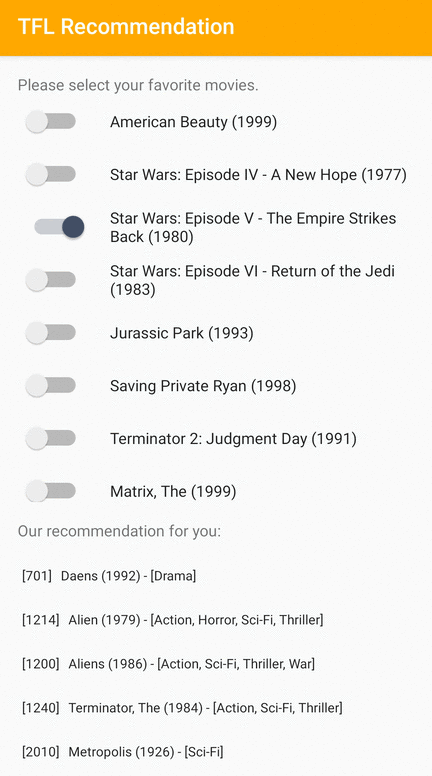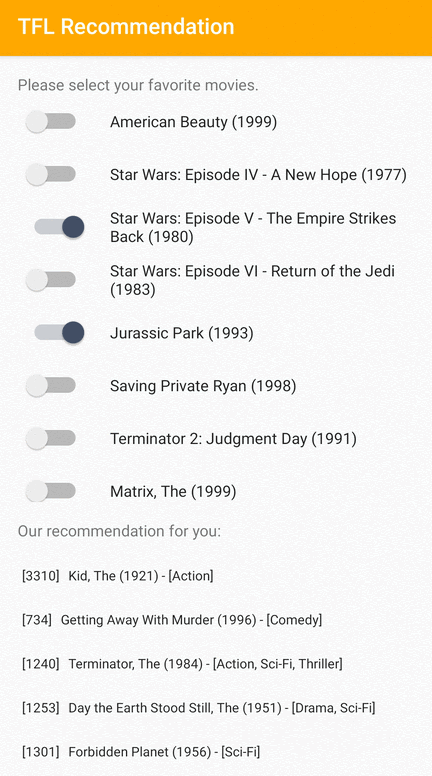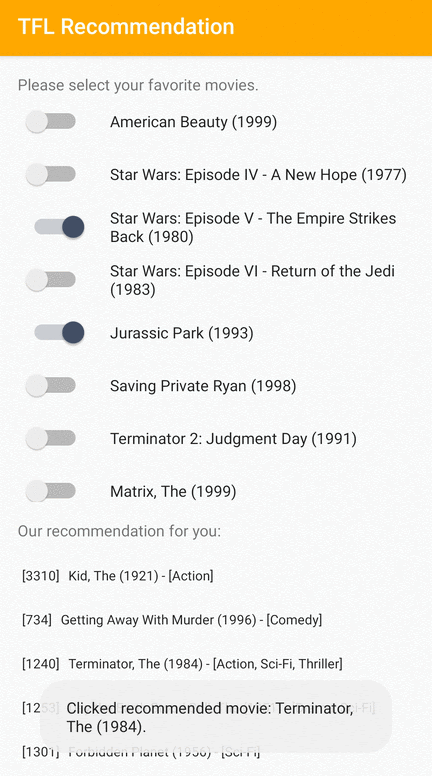
Forniamo un'applicazione di esempio TensorFlow Lite che dimostra come consigliare articoli pertinenti agli utenti su Android.
Se utilizzi una piattaforma diversa da Android o hai già familiarità con le API TensorFlow Lite, puoi scaricare il nostro modello di consigli iniziale.
Forniamo anche script di formazione in Github per addestrare il tuo modello in modo configurabile.
Comprendere l'architettura del modello
Sfruttiamo un'architettura del modello a doppio codificatore, con codificatore di contesto per codificare la cronologia utente sequenziale e codificatore di etichette per codificare il candidato alla raccomandazione prevista. La somiglianza tra le codifiche del contesto e delle etichette viene utilizzata per rappresentare la probabilità che il candidato previsto soddisfi le esigenze dell'utente.
Con questa base di codice vengono fornite tre diverse tecniche di codifica della cronologia utente sequenziale:
- Codificatore bag-of-words (BOW): media degli incorporamenti delle attività dell'utente senza considerare l'ordine del contesto.
- Codificatore di rete neurale convoluzionale (CNN): applicazione di più strati di reti neurali convoluzionali per generare la codifica del contesto.
- Codificatore di rete neurale ricorrente (RNN): applicazione della rete neurale ricorrente per codificare la sequenza del contesto.
Per modellare l'attività di ogni utente, potremmo utilizzare l'ID dell'elemento dell'attività (basato sull'ID) o più funzionalità dell'elemento (basato sulle funzionalità) o una combinazione di entrambi. Il modello basato sulle funzionalità che utilizza più funzionalità per codificare collettivamente il comportamento degli utenti. Con questa codebase è possibile creare modelli basati su ID o basati su funzionalità in modo configurabile.
Dopo la formazione, verrà esportato un modello TensorFlow Lite in grado di fornire direttamente previsioni top-K tra i candidati alla raccomandazione.
Usa i tuoi dati di allenamento
Oltre al modello addestrato, forniamo un toolkit open source in GitHub per addestrare i modelli con i tuoi dati. Puoi seguire questo tutorial per imparare come utilizzare il toolkit e distribuire modelli addestrati nelle tue applicazioni mobili.
Segui questo tutorial per applicare la stessa tecnica utilizzata qui per addestrare un modello di consigli utilizzando i tuoi set di dati.
Esempi
Ad esempio, abbiamo addestrato modelli di raccomandazione con approcci sia basati su ID che basati su funzionalità. Il modello basato su ID accetta solo gli ID dei film come input, mentre il modello basato sulle funzionalità accetta come input sia gli ID dei film che gli ID dei generi di film. Si prega di trovare i seguenti esempi di input e output.
Ingressi
ID film contestuali:
- Il Re Leone (ID: 362)
- Storia di giocattoli (ID: 1)
- (e altro)
ID dei generi di film contestuali:
- Animazione (ID: 15)
- Bambini (ID: 9)
- Musicale (ID: 13)
- Animazione (ID: 15)
- Bambini (ID: 9)
- Commedia (ID: 2)
- (e altro)
Uscite:
- ID film consigliati:
- Toy Story 2 (ID: 3114)
- (e altro)
Benchmark delle prestazioni
I numeri dei benchmark delle prestazioni vengono generati con lo strumento qui descritto .
| Nome del modello | Dimensioni del modello | Dispositivo | processore |
|---|---|---|---|
| raccomandazione (ID film come input) | 0,52 MB | Pixel 3 | 0,09 ms* |
| Pixel 4 | 0,05 ms* | ||
| raccomandazione (ID film e genere film come input) | 1,3 MB | Pixel 3 | 0,13 ms* |
| Pixel 4 | 0,06 ms* |
* 4 fili utilizzati.
Usa i tuoi dati di allenamento
Oltre al modello addestrato, forniamo un toolkit open source in GitHub per addestrare i modelli con i tuoi dati. Puoi seguire questo tutorial per imparare come utilizzare il toolkit e distribuire modelli addestrati nelle tue applicazioni mobili.
Segui questo tutorial per applicare la stessa tecnica utilizzata qui per addestrare un modello di consigli utilizzando i tuoi set di dati.
Suggerimenti per la personalizzazione del modello con i tuoi dati
Il modello preaddestrato integrato in questa applicazione demo viene addestrato con il set di dati MovieLens , potresti voler modificare la configurazione del modello in base ai tuoi dati, come la dimensione del vocab, l'incorporamento delle dim e la lunghezza del contesto di input. Ecco alcuni suggerimenti:
Lunghezza del contesto di input: la migliore lunghezza del contesto di input varia in base ai set di dati. Suggeriamo di selezionare la lunghezza del contesto di input in base alla correlazione tra gli eventi dell'etichetta e gli interessi a lungo termine rispetto al contesto a breve termine.
Selezione del tipo di codificatore: suggeriamo di selezionare il tipo di codificatore in base alla lunghezza del contesto di input. Il codificatore bag-of-word funziona bene per un contesto di input di breve durata (ad esempio <10), i codificatori CNN e RNN offrono una maggiore capacità di riepilogo per un contesto di input lungo.
L'utilizzo delle funzionalità sottostanti per rappresentare elementi o attività dell'utente potrebbe migliorare le prestazioni del modello, accogliere meglio gli elementi nuovi, possibilmente ridurre gli spazi di incorporamento, quindi ridurre il consumo di memoria e una maggiore compatibilità sul dispositivo.