
Сыграйте в настольную игру против агента, который обучен с использованием обучения с подкреплением и развернут с помощью TensorFlow Lite.
Начать
Если вы новичок в TensorFlow Lite и работаете с Android, мы рекомендуем изучить следующий пример приложения, которое поможет вам начать работу.
Если вы используете платформу, отличную от Android, или уже знакомы с API-интерфейсами TensorFlow Lite , вы можете скачать нашу обученную модель.
Как это работает
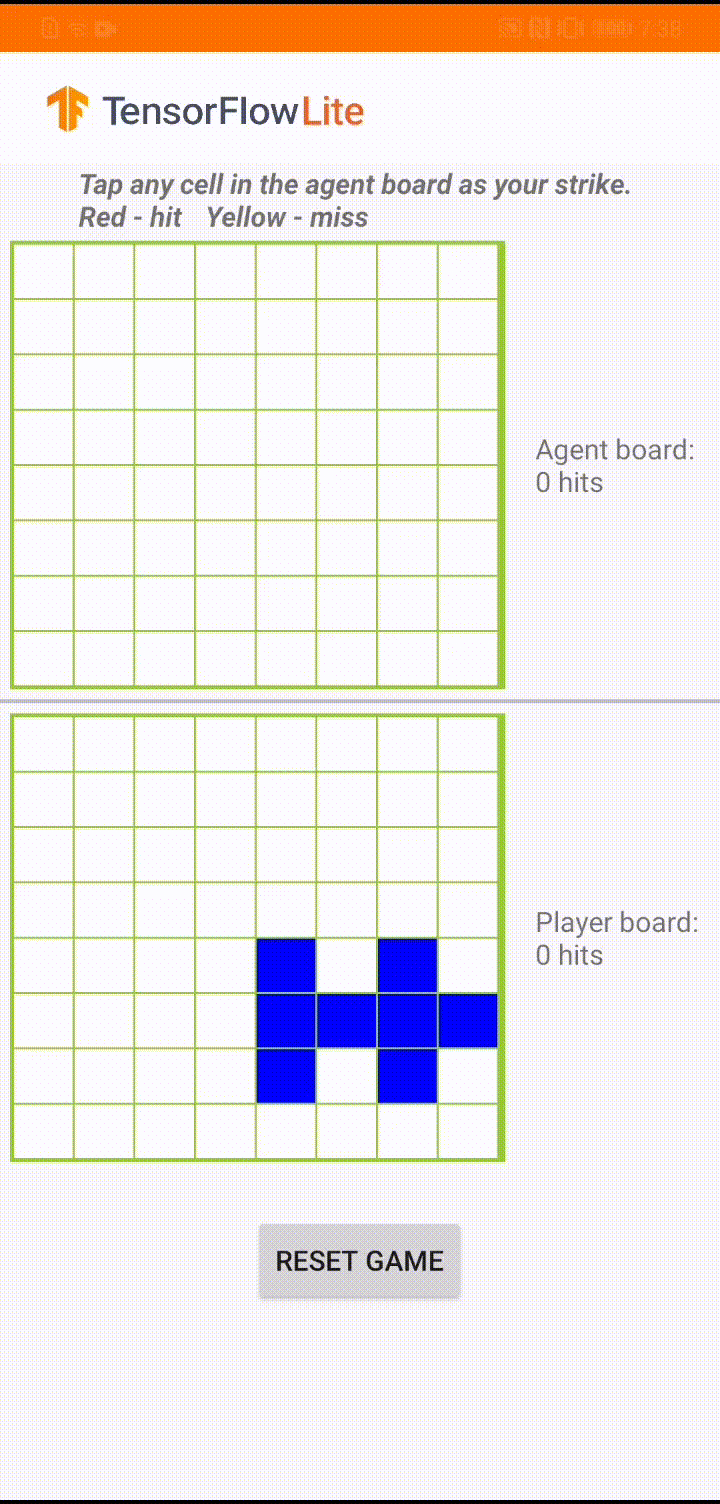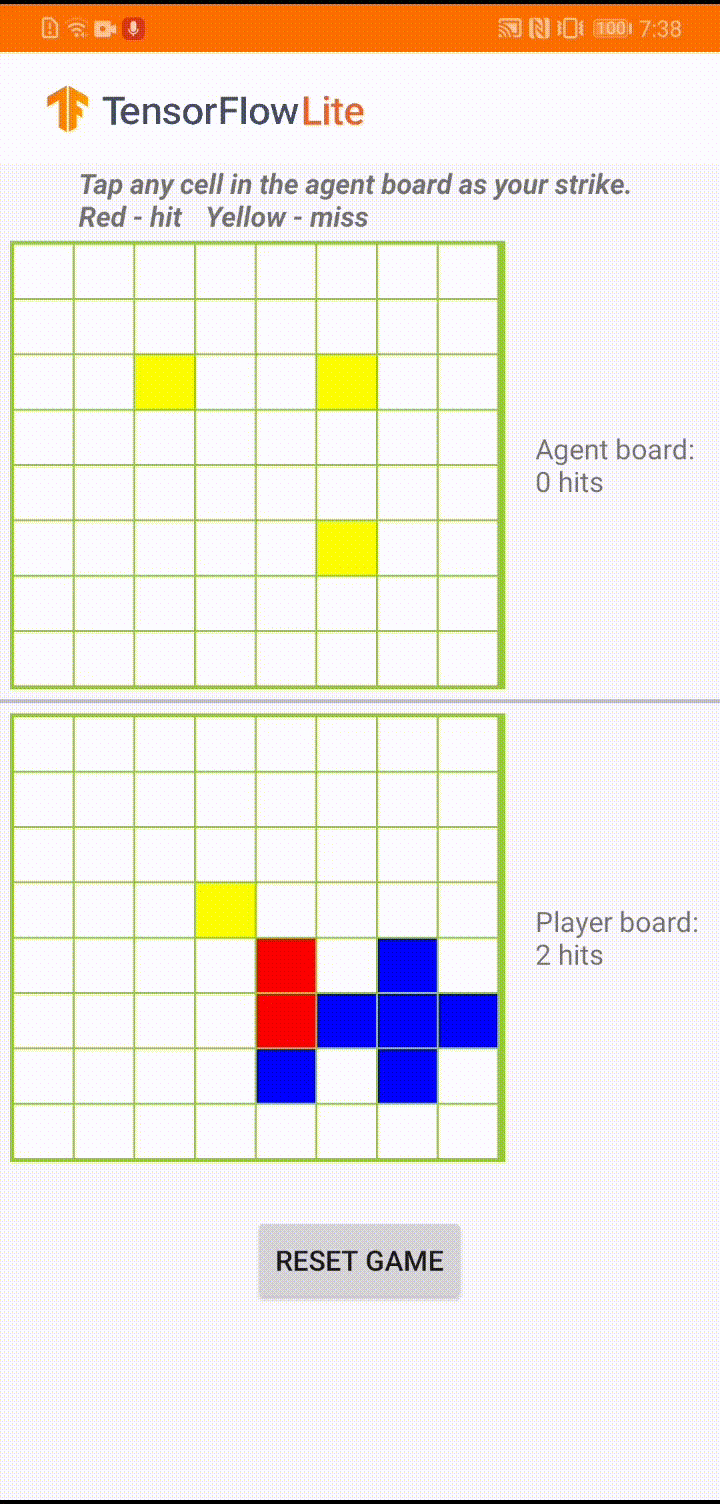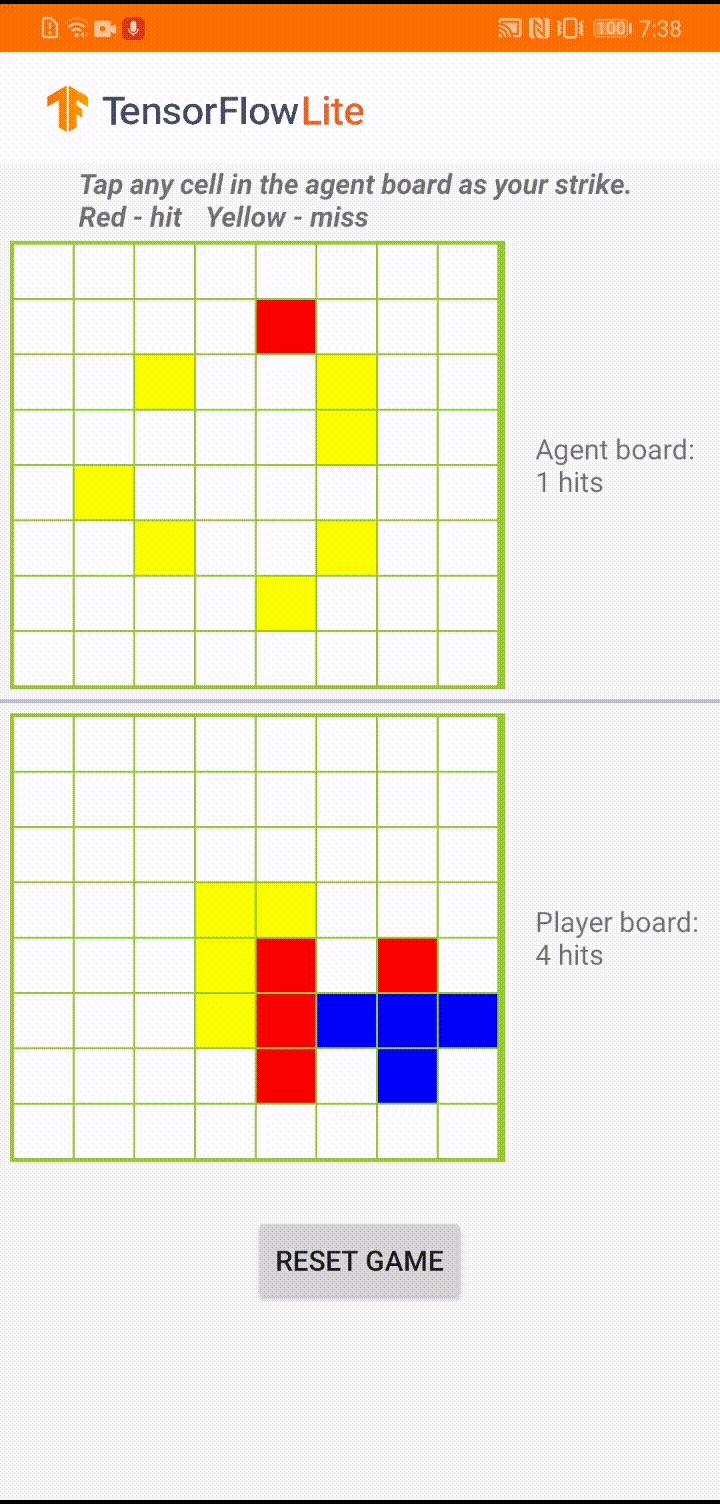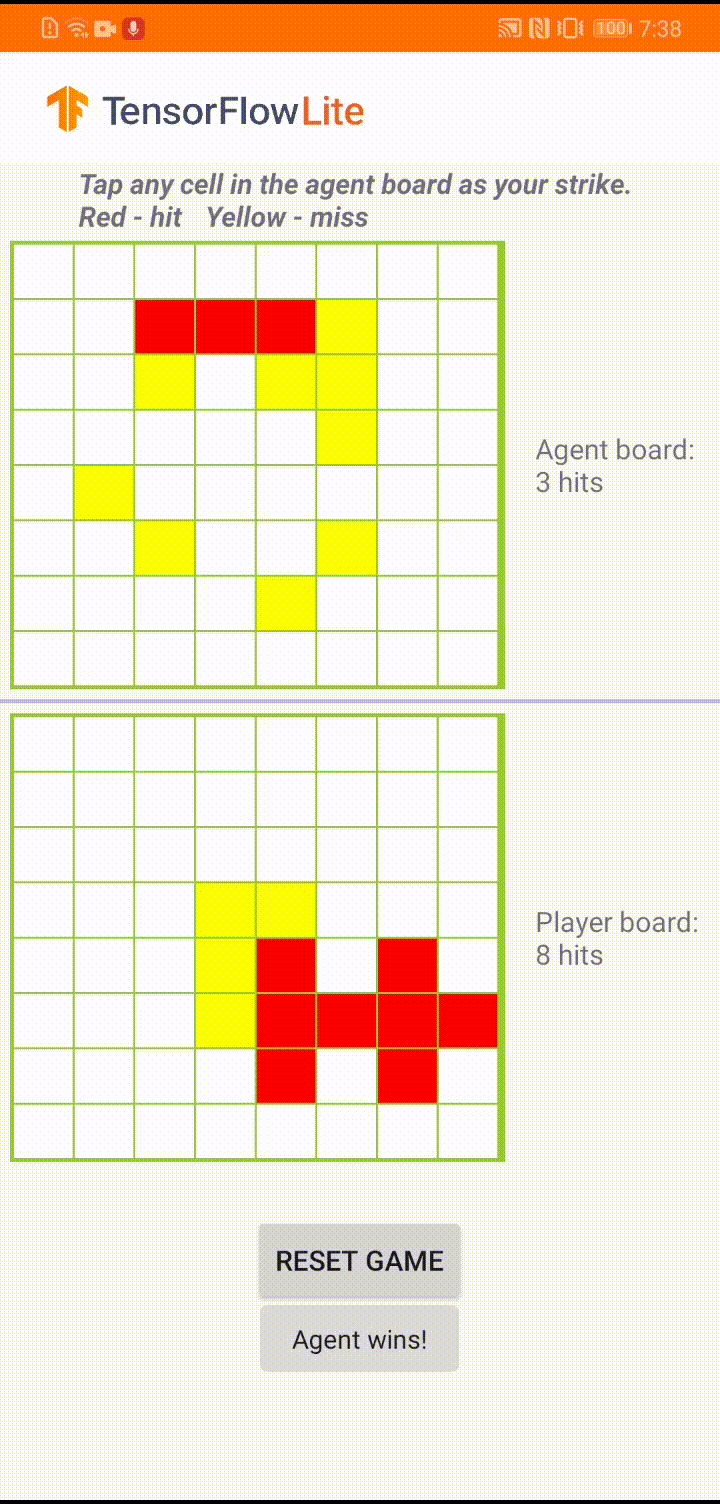
Модель создана для того, чтобы игровой агент мог играть в небольшую настольную игру под названием «Plane Strike». Для быстрого ознакомления с этой игрой и ее правилами обратитесь к этому README .
Под пользовательским интерфейсом приложения мы создали агента, который играет против игрока-человека. Агент представляет собой трехуровневый MLP, который принимает состояние доски в качестве входных данных и выводит прогнозируемую оценку для каждой из 64 возможных ячеек доски. Модель обучается с использованием градиента политики (REINFORCE), а код обучения можно найти здесь . После обучения агента мы преобразуем модель в TFLite и развертываем ее в приложении для Android.
Во время самой игры в приложении Android, когда наступает очередь агента действовать, агент просматривает состояние доски игрока-человека (доска внизу), которое содержит информацию о предыдущих успешных и неудачных ударах (попаданиях и промахах). и использует обученную модель, чтобы предсказать, куда нанести следующий удар, чтобы завершить игру раньше, чем это сделает игрок-человек.
Тесты производительности
Показатели производительности генерируются с помощью инструмента, описанного здесь .
| Название модели | Размер модели | Устройство | Процессор |
|---|---|---|---|
| Градиент политики | 84 Кб | Пиксель 3 (Андроид 10) | 0,01 мс* |
| Пиксель 4 (Андроид 10) | 0,01 мс* |
* Использовано 1 нить.
Входы
Модель принимает трехмерный тензор float32 (1, 8, 8) в качестве состояния доски.
Выходы
Модель возвращает двумерный тензор float32 формы (1,64) в качестве прогнозируемых оценок для каждой из 64 возможных позиций удара.
Обучите свою собственную модель
Вы можете обучить свою собственную модель для платы большего/меньшего размера, изменив параметр BOARD_SIZE в обучающем коде .