
Neural Structured Learning(NSL)은 특성 입력과 함께 구조적 신호(사용 가능한 경우)를 활용하여 심층 신경망 훈련에 중점을 둡니다. Bui et al. (WSDM'18)에서 소개된 구조적 신호는 신경망의 훈련을 정규화하는 데 사용되며, 모델이 정확한 예측값(감독 손실을 최소화함으로써)을 학습하도록 하는 동시에 입력의 구조적 유사성을 유지합니다(이웃 손실 최소화, 아래 그림 참조). 이 기술은 일반적이며 임의의 신경 아키텍처(예: Feed-forward NN, Convolutional NN 및 Recurrent NN)에 적용될 수 있습니다.
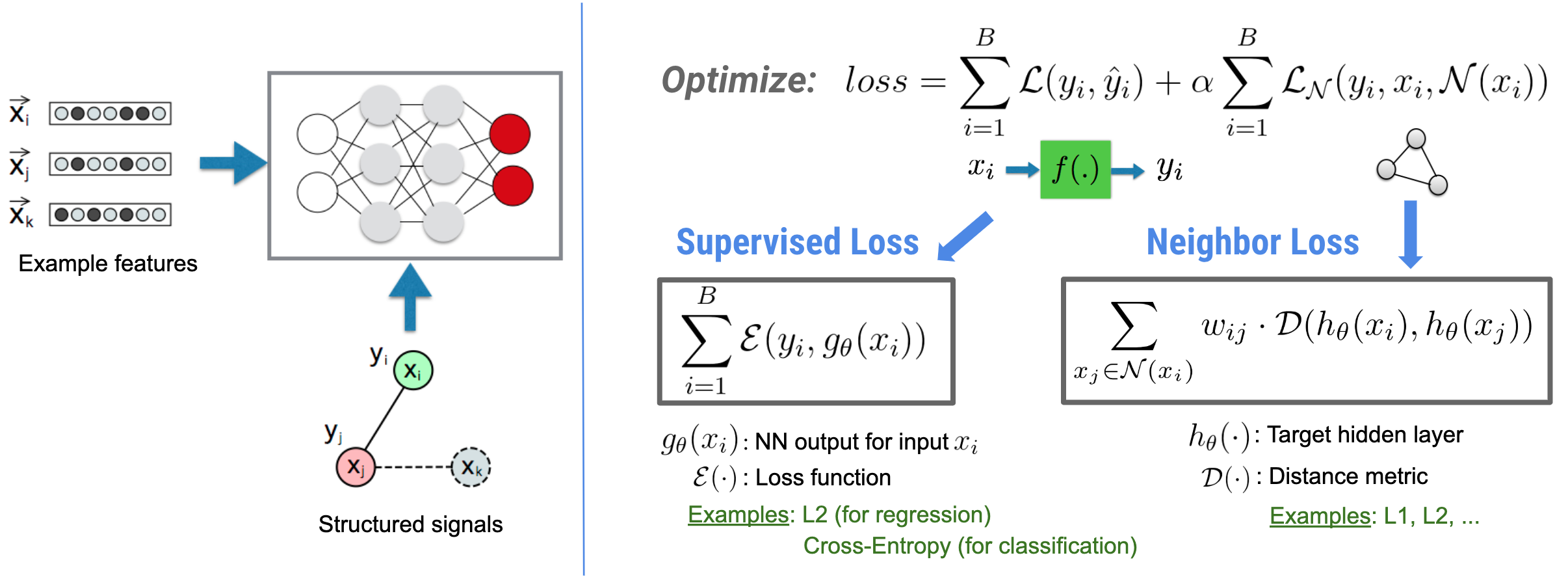
일반화된 이웃 손실 수식은 유연하며 위에 설명된 것과 다른 형태를 가질 수 있습니다. 예를 들어, \(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\)를 이웃 손실로 선택할 수도 있으며, 실제 \(y_i\)과 이웃 \(g_\theta(x_j)\)의 예측 사이의 거리를 계산합니다. 일반적으로 적대적 학습(Goodfellow et al., ICLR'15)에 사용됩니다. 따라서 이웃이 그래프로 명시적으로 표현되는 경우, NSL은 신경 그래프 학습으로 일반화되고, 이웃이 적대적 교란(perturbation)에 의해 암시적으로 유도되는 경우, 적대적 학습으로 일반화됩니다.
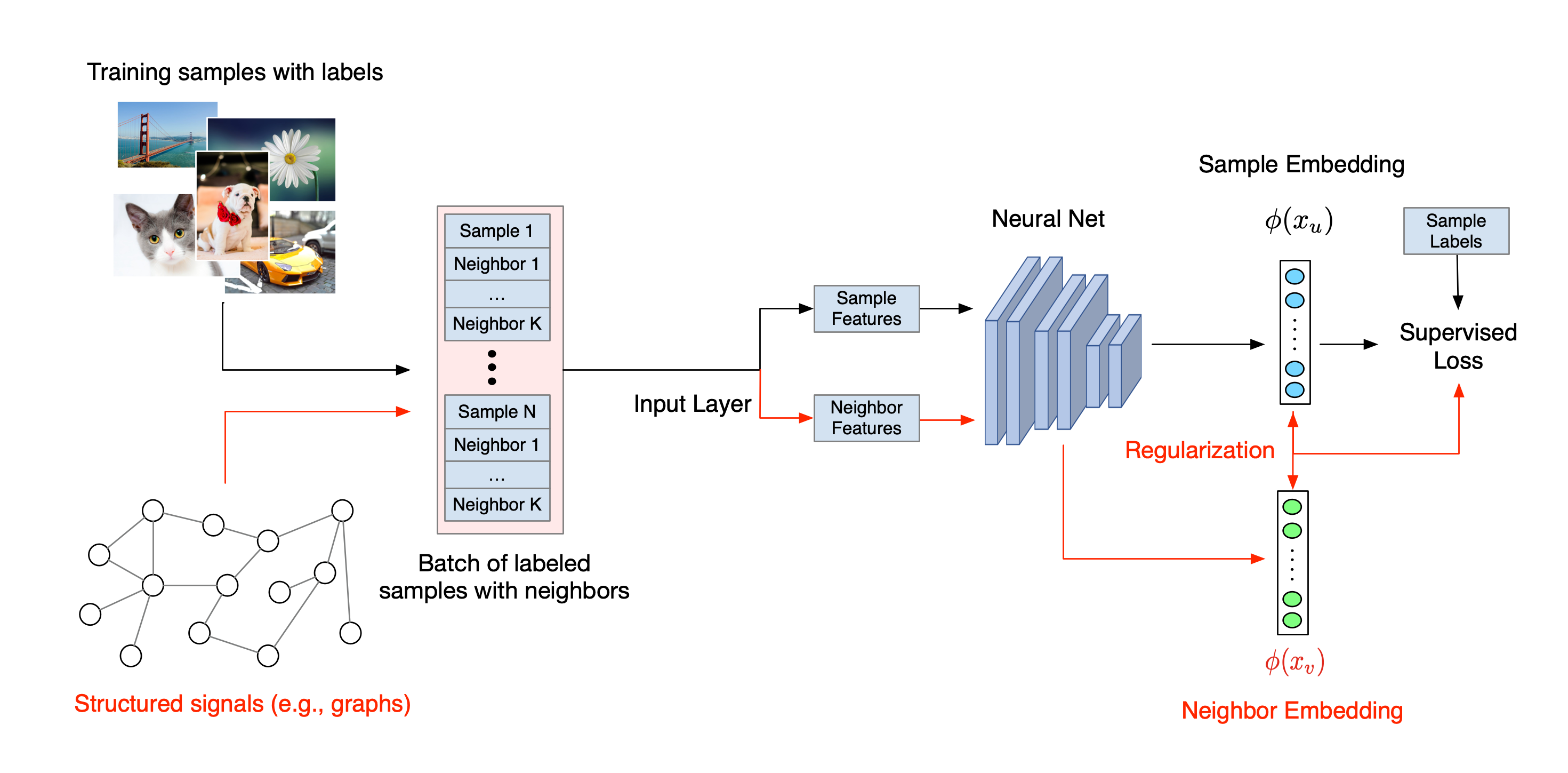
Neural Structured Learning의 전체 워크플로는 다음과 같습니다. 검은색 화살표는 기존 훈련 워크플로를 나타내고, 빨간색 화살표는 구조적 신호를 활용하기 위해 NSL에서 도입한 새로운 워크플로를 나타냅니다. 첫째, 훈련 샘플은 구조적 신호를 포함하도록 확대됩니다. 구조적 신호가 명시적으로 제공되지 않으면 구성되거나 유도될 수 있습니다(후자는 적대적 학습에 적용됨). 다음으로, 증강 훈련 샘플(원래 샘플과 해당 이웃 모두 포함)은 임베딩을 계산하기 위해 신경망에 공급됩니다. 샘플의 임베딩과 이웃 임베딩 사이의 거리가 계산되어 이웃 손실로 사용되며, 이는 정규화 항으로 처리되고 최종 손실에 추가됩니다. 명시적인 이웃 기반 정규화의 경우, 일반적으로 이웃 손실을 샘플의 임베딩과 이웃 임베딩 사이의 거리로 계산합니다. 그러나 신경망의 모든 레이어가 이웃 손실을 계산하는 데 사용될 수 있습니다. 반면에 유도된 이웃 기반 정규화(적대적)의 경우, 유도된 적대적 이웃의 출력 예측과 실제 레이블 사이의 거리로 이웃 손실을 계산합니다.
왜 NSL을 사용하나요?
NSL은 다음과 같은 이점을 제공합니다.
- 더 높은 정확성: 샘플에서 구조적 신호는 특성 입력에서 언제나 사용할 수는 없는 정보를 제공할 수 있습니다. 따라서 문서 분류 및 시맨틱 의도 분류와 같은 광범위한 작업에서 공동 학습 접근 방식(구조적 신호 및 특성 모두 포함)이 기존의 많은 방법(특성만 포함된 훈련에 의존하는 방법)을 능가하는 것으로 나타났습니다(Bui et al., WSDM'18 & Kipf et al., ICLR'17).
- 견고성: 적대적 예제로 훈련된 모델은 모델의 예측 또는 분류를 오도하도록 설계된 적대적 교란에 대해 견고한 것으로 나타났습니다 (Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16). 훈련 샘플의 수가 적을 때 적대적 예제를 사용한 훈련도 모델 정확성을 향상하는 데 도움이 됩니다(Tsipras et al., ICLR'19).
- 레이블이 지정된 필요 데이터 감소: NSL을 사용하면 신경망에서 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터를 모두 활용할 수 있으므로 학습 패러다임이 준감독 학습으로 확장됩니다. 특히 NSL을 사용하면, 네트워크가 감독 설정에서와 같이 레이블이 지정된 데이터를 사용하여 훈련할 수 있으며, 동시에 레이블이 있거나 없을 수 있는 "인접 샘플"에 대해 유사한 숨겨진 표현을 학습하도록 네트워크를 구동합니다. 이 기술은 레이블이 지정된 데이터의 양이 상대적으로 적을 때 모델 정확성을 향상할 수 있는 큰 가능성을 보여주었습니다.(Bui et al., WSDM'18 & Miyato et al., ICLR'16).
단계별 튜토리얼
Neural Structured Learning에 대한 실습 경험을 얻기 위해 구조적 신호를 명시적으로 제공, 유도 또는 구성할 수 있는 다양한 시나리오를 다루는 3가지 튜토리얼이 제공됩니다.
자연 그래프를 사용한, 문서 분류를 위한 그래프 정규화 이 튜토리얼에서는 그래프 정규화를 사용하여 자연(유기적) 그래프를 형성하는 문서를 분류하는 방법을 살펴봅니다.
합성 그래프를 사용한, 감상 분류를 위한 그래프 정규화 이 튜토리얼에서는 그래프 정규화를 사용하여 구조적 신호를 구성(합성)함으로써 영화 리뷰 감상을 분류하는 방법을 보여줍니다.
이미지 분류를 위한 적대적 학습 이 튜토리얼에서는 적대적 학습(구조적 신호가 유도되는 학습)을 사용하여 숫자가 포함된 이미지를 분류하는 방법을 살펴봅니다.