
神经结构学习 (NSL) 侧重于通过利用结构化信号(可用时)和特征输入来训练深度神经网络。如 Bui 等人在 WSDM'18 上提出的那样,这些结构化信号用于对神经网络训练执行正则化,迫使模型学习准确的预测(通过最小化监督损失),同时保持输入的结构相似度(通过最小化近邻损失,请参见下图)。此技术是适用于任意神经网络架构(例如前馈神经网络、卷积神经网络和循环神经网络)的通用型技术。
请注意,泛化的近邻损失方程非常灵活,可具有除上例所示以外的其他形式。例如,我们还可以选择 \(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) 作为近邻损失,用于计算真实 \(y_i\) 与从近邻 \(g_\theta(x_j)\) 预测的值之间的距离。这是对抗学习(Goodfellow 等人在 ICLR'15 上提出)中的常用方法。因此,如果近邻通过计算图显式表示,则 NSL 可泛化到神经计算图学习;如果近邻由对抗扰动隐式诱导,则泛化到对抗学习。
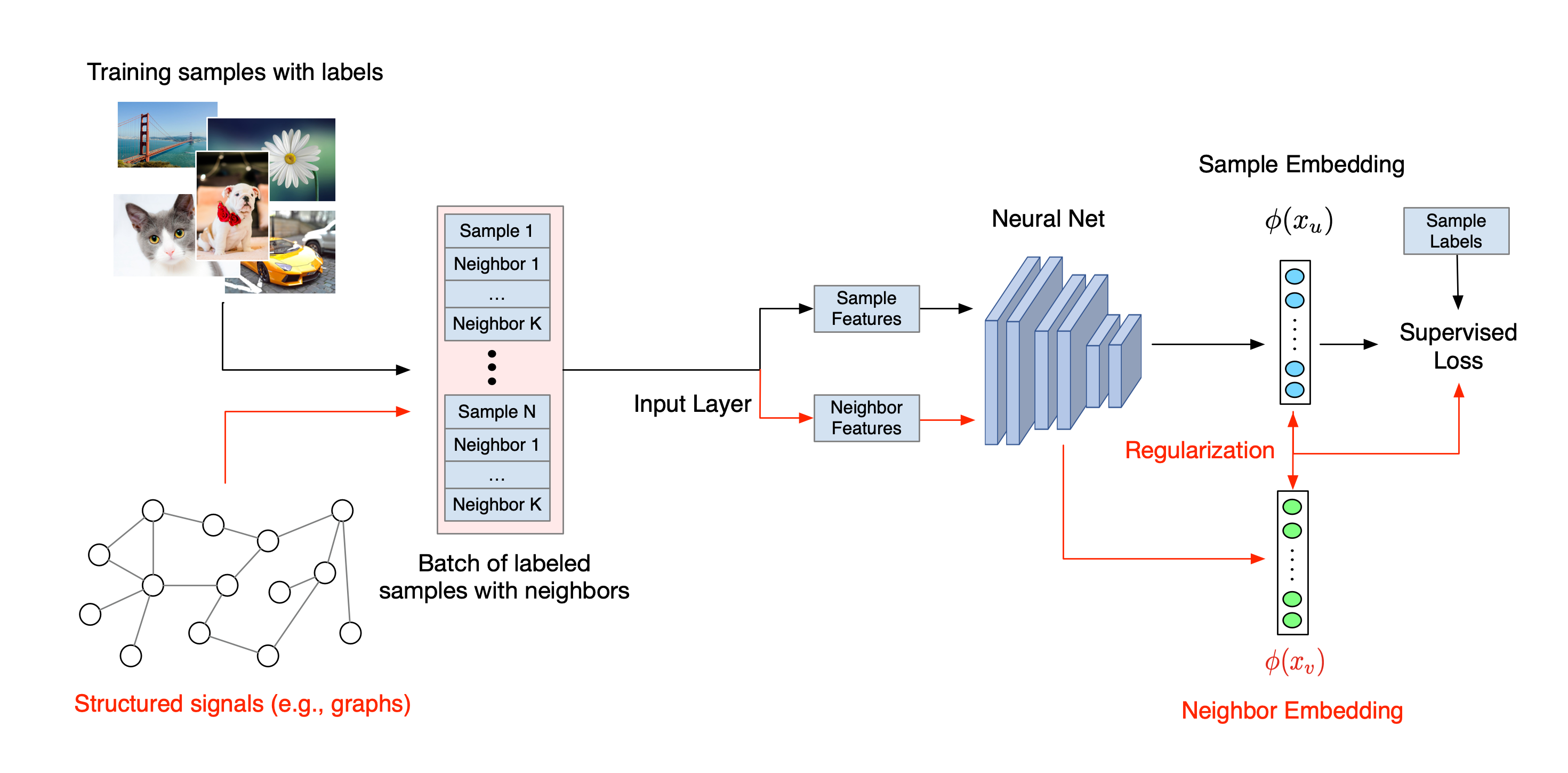
神经结构学习的整体工作流如下所示。黑色箭头代表常规训练工作流,红色箭头代表 NSL 为利用结构化信号而引入的新工作流。首先,对训练样本进行增强以包含结构化信号。如果没有显式提供结构化信号,则可以构造或诱导结构化信号(后者适用于对抗学习)。接下来,将增强的训练样本(包括原始样本及其相应近邻)馈送到神经网络以计算其嵌入向量。计算样本的嵌入向量与其近邻的嵌入向量之间的距离,并用作近邻损失,将其处理为正则化项并添加到最终损失中。对于基于显式近邻的正则化,我们通常将近邻损失计算为样本嵌入向量与近邻嵌入向量之间的距离。但是,神经网络的任一层都可以用来计算近邻损失。另一方面,对于基于诱导近邻的正则化(对抗),我们将近邻损失计算为诱导对抗近邻的输出预测与真实标签之间的距离。
为何使用 NSL?
NSL 可提供以下优势:
- 更高的准确率:样本中的结构化信号可以提供特征输入可能不具备的信息;因此,联合训练方法(同时采用结构化信号和特征)经证实在诸如文档分类和语义意图分类等许多任务中均优于仅依靠特征训练的多种现有方法(Bui 等人在 WSDM'18 以及 Kipf 等人在 ICLR'17 上提出)。
- 鲁棒性:采用对抗样本训练的模型经证实,在面对旨在误导模型预测或分类的对抗扰动时具有更高的鲁棒性(Goodfellow 等人在 ICLR'15 以及 Miyato 等人在 ICLR'16 上提出)。当训练的样本量较少时,使用对抗样本进行训练也有助于提高模型的准确率(Tsipras 等人在 ICLR'19 上提出)。
- 所需的带标签数据更少:NSL 使神经网络能够利用带标签数据和无标签数据,将学习范式扩展到半监督学习。具体而言,NSL 使网络可以像在监督环境中一样使用带标签数据进行训练,同时驱动网络针对可能带或不带标签的“近邻样本”学习相似的隐藏表示。当带标签数据量相对较小时,此技术在提高模型准确率方面已展现出巨大潜力(Bui 等人在 WSDM'18 以及 Miyato 等人在 ICLR'16 上提出)。
分步教程
为了帮助您获得神经结构学习的动手经验,我们提供了各种教程,涵盖显式给定、构造或诱导结构化信号等各种场景。下面是一些示例:
使用计算图正则化实现利用自然计算图的文档分类。在本教程中,我们将了解如何使用计算图正则化对构成自然(有机)计算图的文档进行分类。
使用计算图正则化实现利用合成计算图的情感分类。在本教程中,我们将演示如何使用计算图正则化通过构造(合成)结构化信号对电影评论情感进行分类。
使用对抗正则化实现图像分类。在本教程中,我们将了解如何使用对抗学习(结构化信号为诱导所得)对包含数字的图像进行分类。
可以在我们 GitHub 仓库的示例目录中找到更多示例和教程。