
למידה מובנית עצבית: אימון עם אותות מובנים
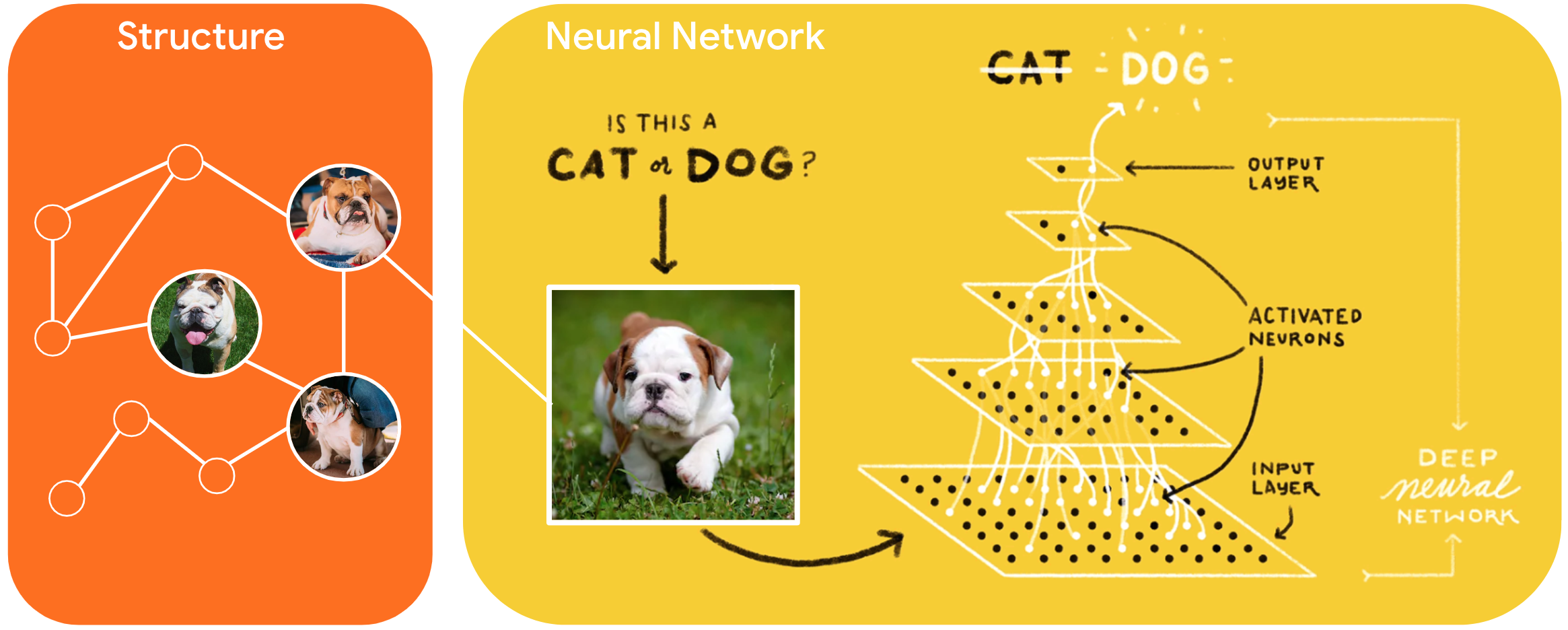
למידה מובנית עצבית (NSL) היא פרדיגמת למידה חדשה לאימון רשתות עצביות על ידי מינוף אותות מובנים בנוסף לכניסות תכונה. מבנה יכול להיות מפורש כפי שמוצג על ידי גרף או מרומז כפי שנגרם על ידי הפרעה אדוורסרית.
אותות מובנים משמשים בדרך כלל לייצוג יחסים או דמיון בין דגימות שעשויות להיות מסומנות או ללא תווית. לכן, מינוף האותות הללו במהלך אימון רשתות עצביות רותם נתונים מסומנים ובלתי מסומנים, מה שיכול לשפר את דיוק המודל, במיוחד כאשר כמות הנתונים המסומנים קטנה יחסית . בנוסף, מודלים שהוכשרו עם דגימות שנוצרו על ידי הוספת הפרעות יריבות הוכחו כעמידים בפני התקפות זדוניות , שנועדו להטעות חיזוי או סיווג של מודל.
NSL מכליל ללמידת גרפים עצביים כמו גם למידה נגדית . מסגרת ה-NSL ב-TensorFlow מספקת את ממשקי ה-API והכלים הקלים לשימוש הבאים למפתחים לאימון מודלים עם אותות מובנים:
- ממשקי API של Keras לאפשר אימון עם גרפים (מבנה מפורש) והפרעות אדוורסריות (מבנה מרומז).
- TF פעולות ופונקציות לאפשר אימון עם מבנה בעת שימוש בממשקי API של TensorFlow ברמה נמוכה יותר
- כלים לבניית גרפים ובניית תשומות גרפים להדרכה
שילוב אותות מובנים נעשה רק במהלך האימון. לכן, הביצועים של זרימת העבודה של הגשה/הסקת מסקנות נשארים ללא שינוי. מידע נוסף על למידה מובנית עצבית ניתן למצוא בתיאור המסגרת שלנו. כדי להתחיל, אנא עיין במדריך ההתקנה שלנו, ולמבוא מעשי ל-NSL, עיין במדריכי הלימוד שלנו.
import tensorflow as tf import neural_structured_learning as nsl # Prepare data. (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # Create a base model -- sequential, functional, or subclass. model = tf.keras.Sequential([ tf.keras.Input((28, 28), name='feature'), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) # Wrap the model with adversarial regularization. adv_config = nsl.configs.make_adv_reg_config(multiplier=0.2, adv_step_size=0.05) adv_model = nsl.keras.AdversarialRegularization(model, adv_config=adv_config) # Compile, train, and evaluate. adv_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) adv_model.fit({'feature': x_train, 'label': y_train}, batch_size=32, epochs=5) adv_model.evaluate({'feature': x_test, 'label': y_test})
