
TensorFlow ランキング ライブラリは、最近の研究で確立されたアプローチと手法を使用して、機械学習モデルをランク付けするためのスケーラブルな学習を構築するのに役立ちます。ランキング モデルは、Web ページなどの類似アイテムのリストを取得し、それらのアイテムの最適化されたリスト (最も関連性の高いページから最も関連性の低いページなど) を生成します。モデルのランク付けを学習すると、検索、質問応答、推奨システム、対話システムに応用できます。このライブラリを使用すると、 Keras APIを使用してアプリケーションのランキング モデルの構築を加速できます。ランキング ライブラリには、分散処理戦略を使用して大規模なデータセットを効率的に操作できるようにモデル実装を簡単にスケールアップできるワークフロー ユーティリティも提供されています。
この概要では、このライブラリを使用してモデルをランク付けする学習の開発について簡単に説明し、ライブラリでサポートされるいくつかの高度なテクニックを紹介し、アプリケーションのランク付けのための分散処理をサポートするために提供されるワークフロー ユーティリティについて説明します。
モデルをランク付けするための学習の開発
TensorFlow ランキング ライブラリを使用してモデルを構築するには、次の一般的な手順に従います。
- Keras レイヤーを使用してスコアリング関数を指定する (
tf.keras.layers) - 評価に使用するメトリクスを定義します (
tfr.keras.metrics.NDCGMetricなど)。 -
tfr.keras.losses.SoftmaxLossなどの損失関数を指定します。 -
tf.keras.Model.compile()でモデルをコンパイルし、データでトレーニングします。
「映画を勧める」チュートリアルでは、このライブラリを使用してランク付け学習モデルを構築する基本を説明します。大規模なランキング モデルの構築の詳細については、 「分散ランキング サポート」セクションを確認してください。
高度なランキング手法
TensorFlow ランキング ライブラリは、Google の研究者やエンジニアによって研究および実装された高度なランキング手法の適用をサポートします。次のセクションでは、これらのテクニックのいくつかの概要と、アプリケーションでそれらのテクニックの使用を開始する方法について説明します。
BERT リストの入力順序
ランキング ライブラリは、 BERTと LTR モデリングを組み合わせてリスト入力の順序を最適化するスコアリング アーキテクチャである TFR-BERT の実装を提供します。このアプローチの応用例として、クエリと、このクエリに応じてランク付けするn 個のドキュメントのリストを考えてみましょう。 <query, document>ペア全体で独立してスコア付けされた BERT 表現を学習する代わりに、LTR モデルはランク付け損失を適用して、グラウンド トゥルース ラベルに関してランク付けされたリスト全体の有用性を最大化する BERT 表現を共同で学習します。次の図は、この手法を示しています。
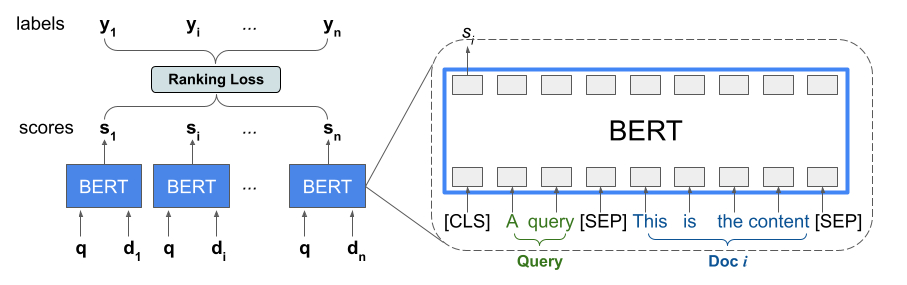
このアプローチでは、クエリに応じてランク付けするドキュメントのリストを<query, document>タプルのリストに平坦化します。これらのタプルは、BERT の事前トレーニング済み言語モデルに入力されます。ドキュメント リスト全体のプールされた BERT 出力は、TensorFlow ランキングで利用できる特殊なランキング損失の 1 つを使用して共同で微調整されます。
このアーキテクチャは、事前トレーニングされた言語モデルのパフォーマンスを大幅に向上させ、特に複数の事前トレーニングされた言語モデルを組み合わせた場合に、いくつかの人気のあるランキング タスクで最先端のパフォーマンスを実現します。この手法の詳細については、関連する研究を参照してください。 TensorFlow ランキングのサンプル コードの簡単な実装から始めることができます。
ニューラルランキング一般化加法モデル (GAM)
ローン適格性の評価、広告のターゲティング、治療の指導など、一部のランキング システムでは、透明性と説明可能性が重要な考慮事項となります。よく理解されている重み付け係数を使用して一般化加算モデル(GAM) を適用すると、ランキング モデルをより説明しやすく、解釈しやすくすることができます。
GAM は回帰タスクと分類タスクに関して広く研究されてきましたが、それらをランキング アプリケーションに適用する方法はあまり明確ではありません。たとえば、GAM を適用してリスト内の個々の項目をモデル化することは簡単ですが、項目の相互作用と、これらの項目がランク付けされるコンテキストの両方をモデル化することは、より困難な問題です。 TensorFlow Rank は、問題のランク付けのために設計された一般化された加算モデルの拡張である、ニューラル ランキング GAMの実装を提供します。 GAM の TensorFlow ランキング実装を使用すると、モデルの特徴に特定の重み付けを追加できます。
次のホテル ランキング システムの図では、主なランキング機能として関連性、価格、距離が使用されています。このモデルは、GAM 技術を適用して、ユーザーのデバイス コンテキストに基づいてこれらのディメンションを異なる方法で重み付けします。たとえば、クエリが電話から来た場合、ユーザーが近くのホテルを探していると想定して、距離がより重み付けされます。
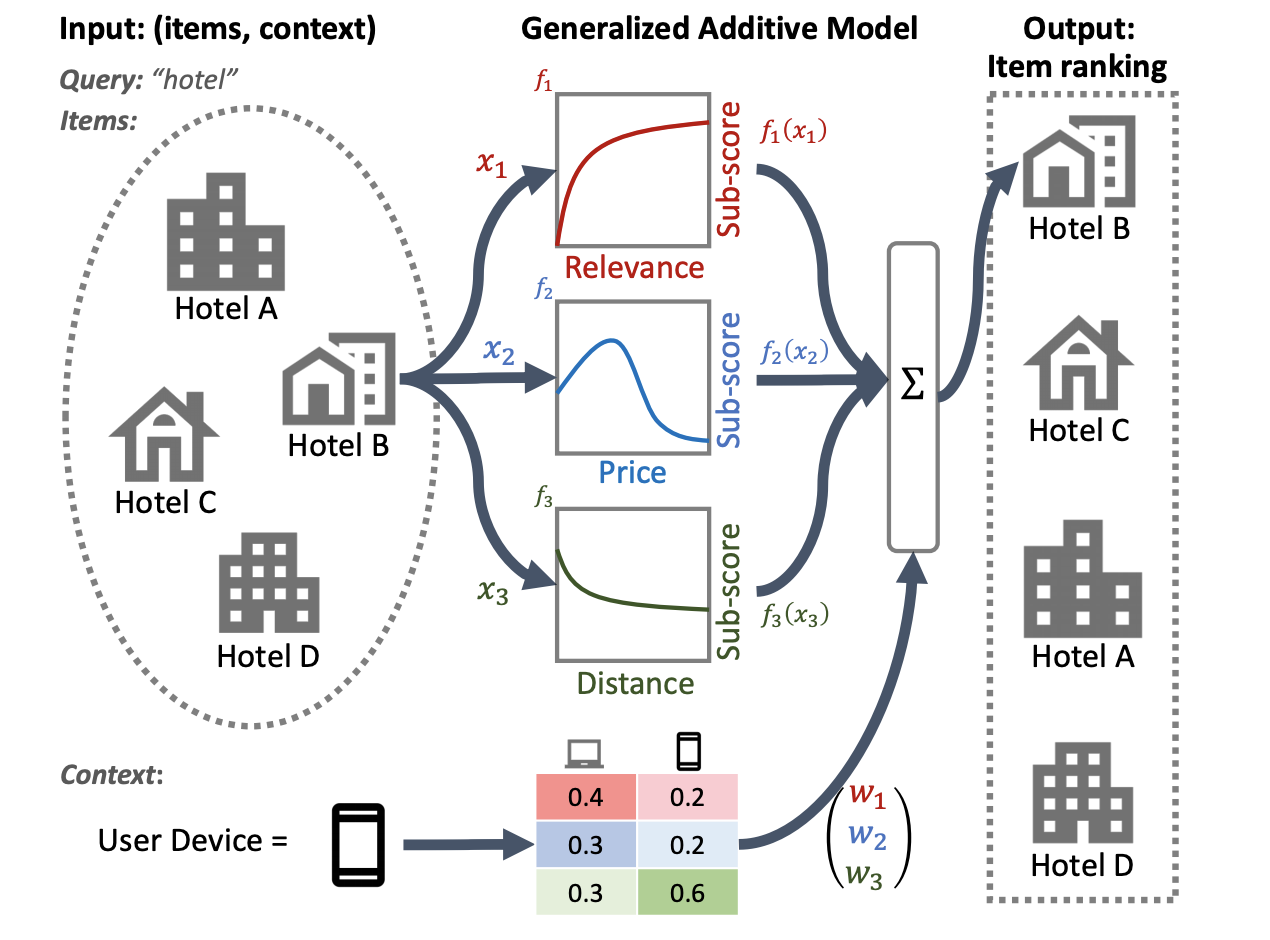
ランキング モデルでの GAM の使用の詳細については、関連する調査を参照してください。 TensorFlow ランキングのサンプル コードで、この手法のサンプル実装を開始できます。
分散型ランキングのサポート
TensorFlow Ranking は、データ処理、モデル構築、評価、本番展開を含む大規模なランキング システムをエンドツーエンドで構築するために設計されています。異種の密な特徴と疎な特徴を処理し、数百万のデータ ポイントまでスケールアップでき、大規模なランキング アプリケーションの分散トレーニングをサポートするように設計されています。
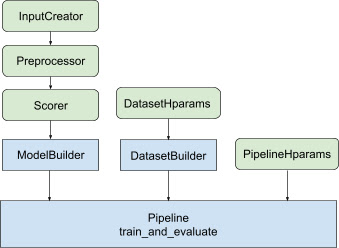
このライブラリは、最適化されたランキング パイプライン アーキテクチャを提供し、反復的な定型コードを回避し、ランキング モデルのトレーニングから提供まで適用できる分散ソリューションを作成します。ランキング パイプラインは、 MirroredStrategy 、 TPUStrategy 、 MultiWorkerMirroredStrategy 、およびParameterServerStrategyを含む TensorFlow の分散戦略のほとんどをサポートします。ランキング パイプラインは、トレーニングされたランキング モデルをtf.saved_model形式でエクスポートできます。これは、いくつかの入力署名をサポートします。さらに、ランキング パイプラインは、 TensorBoardデータ視覚化や、長時間実行時の障害からの回復に役立つBackupAndRestoreのサポートなど、便利なコールバックを提供します。訓練業務。
ランキング ライブラリは、モデル ビルダー、データ ビルダー、およびハイパーパラメーターを入力として受け取るtfr.keras.pipelineクラスのセットを提供することで、分散トレーニング実装の構築を支援します。 Keras ベースのtfr.keras.ModelBuilderクラスを使用すると、分散処理用のモデルを作成でき、拡張可能な InputCreator、Preprocessor、および Scorer クラスと連携できます。
TensorFlow ランキング パイプライン クラスは、 DatasetBuilderと連携して、ハイパーパラメータを組み込むことができるトレーニング データをセットアップすることもできます。最後に、パイプライン自体に、一連のハイパーパラメーターをPipelineHparamsオブジェクトとして含めることができます。
「分散ランキング チュートリアル」を使用して、分散ランキングモデルの構築を開始します。