Alat pemrosesan teks untuk TensorFlow
TensorFlow menyediakan dua pustaka untuk pemrosesan teks dan bahasa alami: KerasNLP dan Teks TensorFlow. KerasNLP adalah pustaka pemrosesan bahasa alami (NLP) tingkat tinggi yang mencakup model berbasis transformator modern serta utilitas tokenisasi tingkat rendah. Ini adalah solusi yang disarankan untuk sebagian besar kasus penggunaan NLP. Dibangun di Teks TensorFlow, KerasNLP mengabstraksi operasi pemrosesan teks tingkat rendah menjadi API yang dirancang untuk kemudahan penggunaan. Namun jika Anda memilih untuk tidak bekerja dengan Keras API, atau Anda memerlukan akses ke operasi pemrosesan teks tingkat rendah, Anda dapat menggunakan Teks TensorFlow secara langsung.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
Cara termudah untuk mulai memproses teks di TensorFlow adalah dengan menggunakan KerasNLP. KerasNLP adalah pustaka pemrosesan bahasa alami yang mendukung alur kerja yang dibangun dari komponen modular yang memiliki bobot dan arsitektur prasetel yang canggih. Anda dapat menggunakan komponen KerasNLP dengan konfigurasi out-of-the-box mereka. Jika Anda membutuhkan lebih banyak kontrol, Anda dapat dengan mudah menyesuaikan komponen. KerasNLP menekankan komputasi dalam grafik untuk semua alur kerja sehingga Anda dapat mengharapkan produksi yang mudah menggunakan ekosistem TensorFlow.
KerasNLP adalah perpanjangan dari inti Keras API, dan semua modul KerasNLP tingkat tinggi adalah Lapisan atau Model. Jika Anda sudah familiar dengan Keras, Anda sudah memahami sebagian besar KerasNLP.
Untuk mempelajari lebih lanjut, lihat KerasNLP .
Teks TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
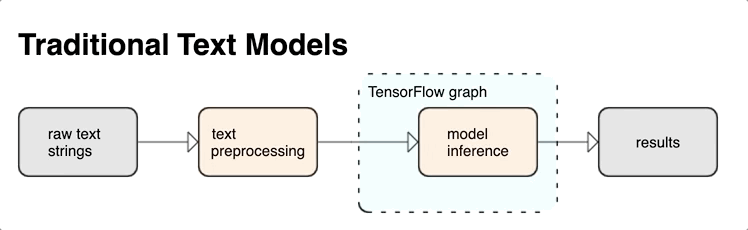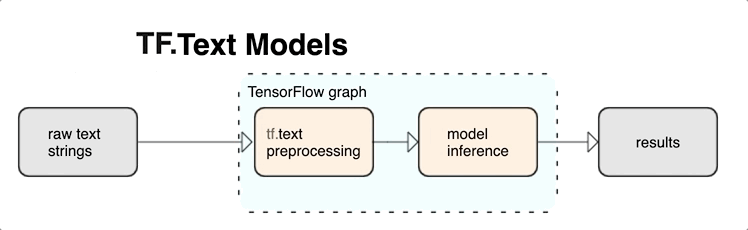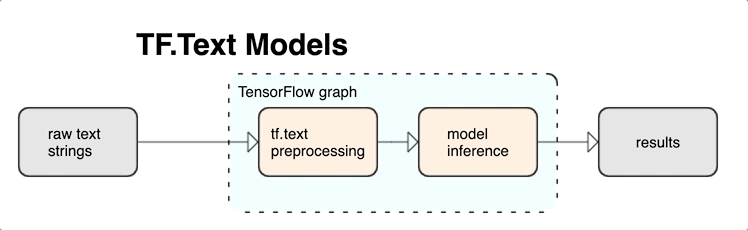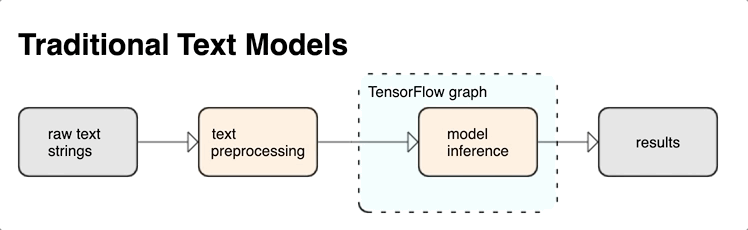
KerasNLP menyediakan modul pemrosesan teks tingkat tinggi yang tersedia sebagai lapisan atau model. Jika memerlukan akses ke alat tingkat rendah, Anda dapat menggunakan Teks TensorFlow. TensorFlow Text memberi Anda banyak koleksi operasi dan pustaka untuk membantu Anda bekerja dengan input dalam bentuk teks seperti string teks mentah atau dokumen. Pustaka ini dapat melakukan preprocessing secara teratur yang diperlukan oleh model berbasis teks, dan menyertakan fitur lain yang berguna untuk pemodelan urutan.
Anda dapat mengekstrak fitur teks sintaksis dan semantik yang kuat dari dalam grafik TensorFlow sebagai input ke jaringan saraf Anda.
Mengintegrasikan prapemrosesan dengan grafik TensorFlow memberikan manfaat berikut:
- Memfasilitasi toolkit besar untuk bekerja dengan teks
- Mengizinkan integrasi dengan rangkaian besar alat TensorFlow untuk mendukung proyek mulai dari definisi masalah hingga pelatihan, evaluasi, dan peluncuran
- Mengurangi kerumitan waktu penyajian dan mencegah kemiringan penyajian pelatihan
Selain hal di atas, Anda tidak perlu khawatir tentang tokenisasi dalam pelatihan yang berbeda dari tokenisasi pada inferensi, atau mengelola skrip prapemrosesan.