
Narzędzia do testów porównawczych
Narzędzia porównawcze TensorFlow Lite obecnie mierzą i obliczają statystyki dla następujących ważnych wskaźników wydajności:
- Czas inicjalizacji
- Czas wnioskowania stanu rozgrzania
- Czas wnioskowania stanu ustalonego
- Użycie pamięci w czasie inicjalizacji
- Ogólne wykorzystanie pamięci
Narzędzia do testów porównawczych są dostępne jako aplikacje testowe dla systemów Android i iOS oraz jako natywne pliki binarne wiersza poleceń i wszystkie mają tę samą podstawową logikę pomiaru wydajności. Należy pamiętać, że dostępne opcje i formaty wyjściowe są nieco inne ze względu na różnice w środowisku wykonawczym.
Aplikacja testowa na Androida
Istnieją dwie możliwości korzystania z narzędzia testowego w systemie Android. Jeden to natywny plik binarny testu porównawczego , a drugi to aplikacja testowa dla systemu Android, która pozwala lepiej ocenić działanie modelu w aplikacji. Tak czy inaczej, liczby z narzędzia porównawczego będą nadal nieznacznie różnić się od wyników wnioskowania na podstawie modelu w rzeczywistej aplikacji.
Ta aplikacja testowa dla systemu Android nie ma interfejsu użytkownika. Zainstaluj i uruchom go za pomocą polecenia adb i pobierz wyniki za pomocą polecenia adb logcat .
Pobierz lub utwórz aplikację
Pobierz gotowe aplikacje do testów porównawczych systemu Android dostępne co wieczór, korzystając z poniższych łączy:
Jeśli chodzi o aplikacje testowe dla systemu Android, które obsługują operacje TF za pośrednictwem delegata Flex , skorzystaj z poniższych łączy:
Możesz także zbudować aplikację ze źródła, postępując zgodnie z tymi instrukcjami .
Przygotuj benchmark
Przed uruchomieniem aplikacji testowej zainstaluj aplikację i wypchnij plik modelu na urządzenie w następujący sposób:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Uruchom benchmark
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph jest wymaganym parametrem.
-
graph:string
Ścieżka do pliku modelu TFLite.
Można określić więcej opcjonalnych parametrów uruchamiania testu porównawczego.
-
num_threads:int(domyślnie=1)
Liczba wątków używanych do uruchamiania interpretera TFLite. -
use_gpu:bool(domyślnie = fałsz)
Użyj delegata GPU . -
use_nnapi:bool(domyślnie = fałsz)
Użyj delegata NNAPI . -
use_xnnpack:bool(domyślnie =false)
Użyj delegata XNNPACK . -
use_hexagon:bool(domyślnie =false)
Użyj delegata Hexagon .
W zależności od używanego urządzenia niektóre z tych opcji mogą być niedostępne lub nie mieć żadnego efektu. Więcej parametrów wydajności, które można uruchomić w aplikacji testowej, można znaleźć w sekcji parametry.
Wyświetl wyniki za pomocą polecenia logcat :
adb logcat | grep "Inference timings"
Wyniki testów porównawczych są raportowane jako:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Natywny plik binarny benchmarku
Narzędzie Benchmark jest również dostępne jako natywny binarny benchmark_model . Możesz uruchomić to narzędzie z wiersza poleceń powłoki na systemach Linux, Mac, urządzeniach wbudowanych i urządzeniach z systemem Android.
Pobierz lub zbuduj plik binarny
Pobierz co wieczór gotowe, natywne pliki binarne wiersza poleceń, korzystając z poniższych łączy:
Jeśli chodzi o gotowe pliki binarne, które obsługują operacje TF za pośrednictwem delegata Flex , skorzystaj z poniższych łączy:
Aby przeprowadzić test porównawczy z delegatem TensorFlow Lite Hexagon , wstępnie zbudowaliśmy również wymagane pliki libhexagon_interface.so (szczegóły na temat tego pliku można znaleźć tutaj ). Po pobraniu pliku odpowiedniej platformy z poniższych łączy zmień nazwę pliku na libhexagon_interface.so .
Możesz także zbudować natywny plik binarny testu porównawczego ze źródła na swoim komputerze.
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
Aby budować za pomocą zestawu narzędzi Android NDK, musisz najpierw skonfigurować środowisko kompilacji, postępując zgodnie z tym przewodnikiem lub użyć obrazu okna dokowanego zgodnie z opisem w tym przewodniku .
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
Uruchom benchmark
Aby uruchomić testy porównawcze na swoim komputerze, uruchom plik binarny z powłoki.
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
Możesz użyć tego samego zestawu parametrów , jak wspomniano powyżej, w natywnym pliku binarnym wiersza poleceń.
Profilowanie operacji modelu
Binarny model porównawczy umożliwia także profilowanie operacji modelu i uzyskiwanie czasów wykonania każdego operatora. Aby to zrobić, podczas wywołania przekaż flagę --enable_op_profiling=true do benchmark_model . Szczegóły wyjaśniono tutaj .
Natywny plik binarny testu porównawczego dla wielu opcji wydajności w jednym przebiegu
Dostępny jest również wygodny i prosty plik binarny C++ umożliwiający porównanie wielu opcji wydajności w jednym przebiegu. Ten plik binarny jest zbudowany w oparciu o wyżej wymienione narzędzie testowe, które może testować tylko jedną opcję wydajności na raz. Dzielą ten sam proces kompilacji/instalacji/uruchamiania, ale docelowa nazwa BUILD tego pliku binarnego to benchmark_model_performance_options i wymaga kilku dodatkowych parametrów. Ważnym parametrem tego pliku binarnego jest:
perf_options_list : string (domyślnie='all')
Rozdzielana przecinkami lista opcji wydajności TFLite do porównania.
Możesz uzyskać co noc gotowe pliki binarne dla tego narzędzia, jak podano poniżej:
Aplikacja testowa na iOS
Aby uruchomić testy porównawcze na urządzeniu z systemem iOS, musisz zbudować aplikację ze źródła . Umieść plik modelu TensorFlow Lite w katalogu benchmark_data drzewa źródłowego i zmodyfikuj plik benchmark_params.json . Pliki te są pakowane w aplikację, która odczytuje dane z katalogu. Aby uzyskać szczegółowe instrukcje, odwiedź aplikację testową systemu iOS .
Testy porównawcze wydajności dla dobrze znanych modeli
W tej sekcji wymieniono testy wydajności TensorFlow Lite podczas uruchamiania dobrze znanych modeli na niektórych urządzeniach z Androidem i iOS.
Testy wydajności Androida
Te numery testów porównawczych wydajności zostały wygenerowane przy użyciu natywnego pliku binarnego testu porównawczego .
W przypadku testów porównawczych Androida powinowactwo procesora jest ustawione tak, aby wykorzystywać duże rdzenie urządzenia w celu zmniejszenia wariancji (zobacz szczegóły ).
Zakłada, że modele zostały pobrane i rozpakowane do katalogu /data/local/tmp/tflite_models . Plik binarny testu porównawczego jest tworzony przy użyciu tych instrukcji i zakłada się, że znajduje się w katalogu /data/local/tmp .
Aby uruchomić test porównawczy:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Aby uruchomić z delegatem nnapi, ustaw --use_nnapi=true . Aby uruchomić z delegatem GPU, ustaw --use_gpu=true .
Poniższe wartości wydajności zostały zmierzone na systemie Android 10.
| Nazwa modelu | Urządzenie | Procesor, 4 wątki | GPU | NNAPI |
|---|---|---|---|---|
| Mobilenet_1.0_224(pływająca) | Piksel 3 | 23,9 ms | 6,45 ms | 13,8 ms |
| Piksel 4 | 14,0 ms | 9,0 ms | 14,8 ms | |
| Mobilenet_1.0_224 (ilość) | Piksel 3 | 13,4 ms | --- | 6,0 ms |
| Piksel 4 | 5,0 ms | --- | 3,2 ms | |
| NASNet komórkowy | Piksel 3 | 56 ms | --- | 102 ms |
| Piksel 4 | 34,5 ms | --- | 99,0 ms | |
| Ściśnij Net | Piksel 3 | 35,8 ms | 9,5 ms | 18,5 ms |
| Piksel 4 | 23,9 ms | 11,1 ms | 19,0 ms | |
| Incepcja_ResNet_V2 | Piksel 3 | 422 ms | 99,8 ms | 201 ms |
| Piksel 4 | 272,6 ms | 87,2 ms | 171,1 ms | |
| Incepcja_V4 | Piksel 3 | 486 ms | 93 ms | 292 ms |
| Piksel 4 | 324,1 ms | 97,6 ms | 186,9 ms |
Testy wydajności iOS
Te wartości porównawcze wydajności zostały wygenerowane za pomocą aplikacji porównawczej na iOS .
Aby uruchomić testy porównawcze iOS, aplikacja testowa została zmodyfikowana w celu uwzględnienia odpowiedniego modelu, a benchmark_params.json został zmodyfikowany w celu ustawienia num_threads na 2. Aby użyć delegata GPU, użyto opcji "use_gpu" : "1" i "gpu_wait_type" : "aggressive" dodano także do benchmark_params.json .
| Nazwa modelu | Urządzenie | Procesor, 2 wątki | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(pływająca) | iPhone’a XS | 14,8 ms | 3,4 ms |
| Mobilenet_1.0_224 (ilość) | iPhone’a XS | 11 ms | --- |
| NASNet komórkowy | iPhone’a XS | 30,4 ms | --- |
| Ściśnij Net | iPhone’a XS | 21,1 ms | 15,5 ms |
| Incepcja_ResNet_V2 | iPhone’a XS | 261,1 ms | 45,7 ms |
| Incepcja_V4 | iPhone’a XS | 309 ms | 54,4 ms |
Śledź elementy wewnętrzne TensorFlow Lite
Śledź elementy wewnętrzne TensorFlow Lite w systemie Android
Zdarzenia wewnętrzne z interpretera TensorFlow Lite aplikacji na Androida mogą być przechwytywane przez narzędzia do śledzenia systemu Android . Są to te same zdarzenia w Android Trace API, więc przechwycone zdarzenia z kodu Java/Kotlin są widoczne razem ze zdarzeniami wewnętrznymi TensorFlow Lite.
Oto kilka przykładów wydarzeń:
- Wywołanie operatora
- Modyfikacja wykresu przez delegata
- Alokacja tensora
Wśród różnych opcji przechwytywania śladów w tym przewodniku omówiono narzędzie Android Studio CPU Profiler i aplikację System Tracing. Aby poznać inne opcje, zobacz Narzędzie wiersza poleceń Perfetto lub Narzędzie wiersza poleceń Systrace .
Dodawanie zdarzeń śledzenia w kodzie Java
To jest fragment kodu z przykładowej aplikacji Klasyfikacja obrazów . Interpreter TensorFlow Lite działa w sekcji recognizeImage/runInference . Ten krok jest opcjonalny, ale przydatny, aby pomóc zauważyć, gdzie następuje wywołanie wnioskowania.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Włącz śledzenie TensorFlow Lite
Aby włączyć śledzenie TensorFlow Lite, przed uruchomieniem aplikacji na Androida ustaw właściwość systemu Android debug.tflite.trace na 1.
adb shell setprop debug.tflite.trace 1
Jeśli ta właściwość została ustawiona podczas inicjowania interpretera TensorFlow Lite, śledzone będą kluczowe zdarzenia (np. wywołanie operatora) z interpretera.
Po przechwyceniu wszystkich śladów wyłącz śledzenie, ustawiając wartość właściwości na 0.
adb shell setprop debug.tflite.trace 0
Profiler procesora Android Studio
Przechwytuj ślady za pomocą narzędzia Android Studio CPU Profiler, wykonując poniższe czynności:
Z górnego menu wybierz opcję Uruchom > Profil „aplikacja” .
Kliknij w dowolnym miejscu na osi czasu procesora, gdy pojawi się okno Profilera.
Wybierz opcję „Śledź wywołania systemowe” spośród trybów profilowania procesora.
Naciśnij przycisk „Nagraj”.
Naciśnij przycisk „Zatrzymaj”.
Zbadaj wynik śledzenia.
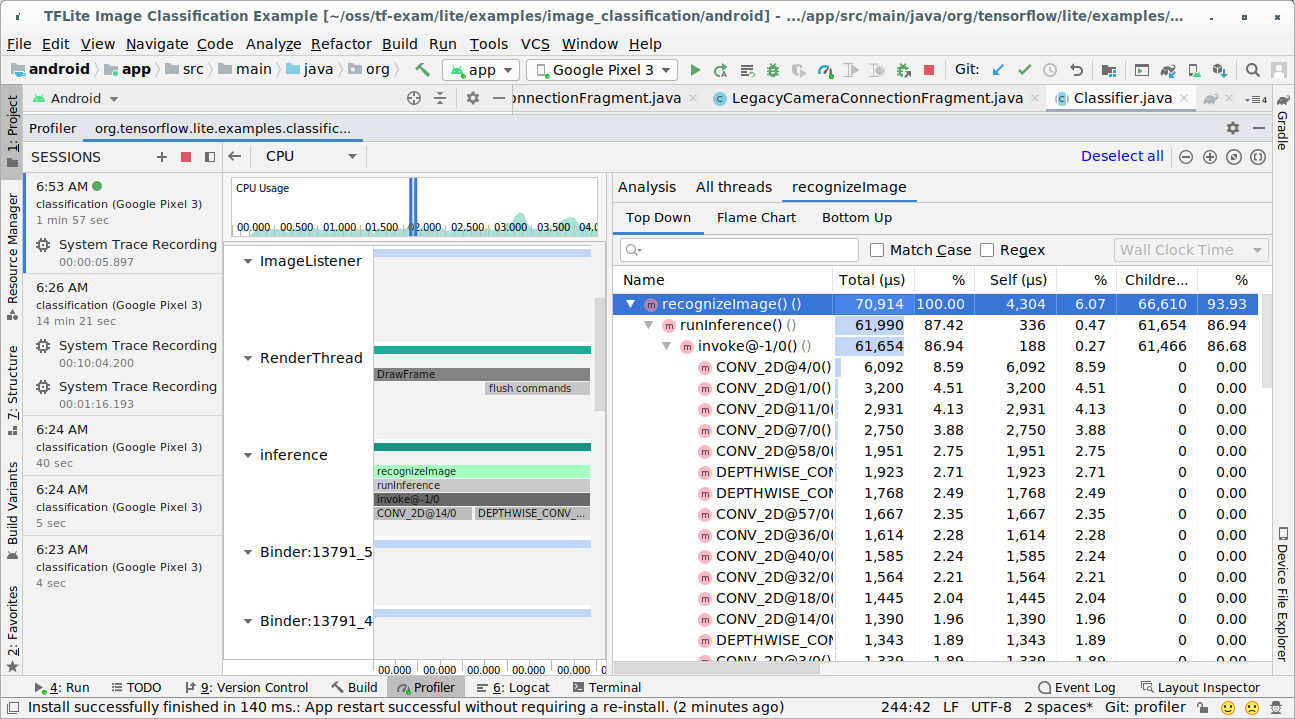
W tym przykładzie możesz zobaczyć hierarchię zdarzeń w wątku i statystyki dla każdego czasu operatora, a także zobaczyć przepływ danych całej aplikacji pomiędzy wątkami.
Aplikacja do śledzenia systemu
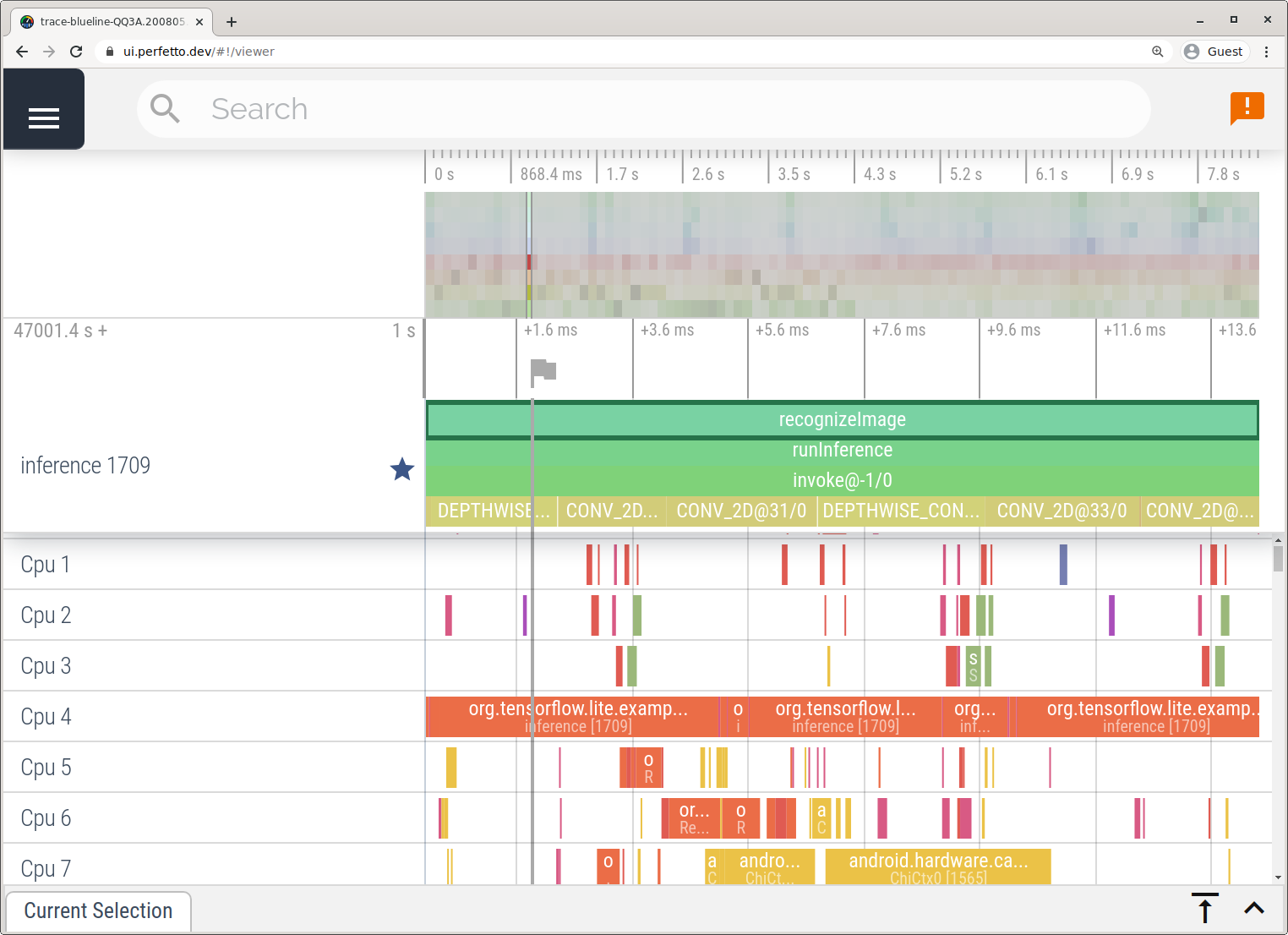
Przechwytuj ślady bez Android Studio, wykonując czynności opisane w aplikacji System Tracing .
W tym przykładzie te same zdarzenia TFLite zostały przechwycone i zapisane w formacie Perfetto lub Systrace w zależności od wersji urządzenia z systemem Android. Przechwycone pliki śledzenia można otworzyć w interfejsie użytkownika Perfetto .
Śledź elementy wewnętrzne TensorFlow Lite w systemie iOS
Zdarzenia wewnętrzne z interpretera TensorFlow Lite aplikacji na iOS można przechwytywać za pomocą narzędzia Instruments dołączonego do Xcode. Są to zdarzenia drogowskazowe dla systemu iOS, więc przechwycone zdarzenia z kodu Swift/Objective-C są widoczne razem ze zdarzeniami wewnętrznymi TensorFlow Lite.
Oto kilka przykładów wydarzeń:
- Wywołanie operatora
- Modyfikacja wykresu przez delegata
- Alokacja tensora
Włącz śledzenie TensorFlow Lite
Ustaw zmienną środowiskową debug.tflite.trace , wykonując poniższe kroki:
Wybierz Produkt > Schemat > Edytuj schemat... z górnych menu Xcode.
Kliknij „Profil” w lewym okienku.
Usuń zaznaczenie pola wyboru „Użyj argumentów i zmiennych środowiskowych akcji Uruchom”.
Dodaj
debug.tflite.tracew sekcji „Zmienne środowiskowe”.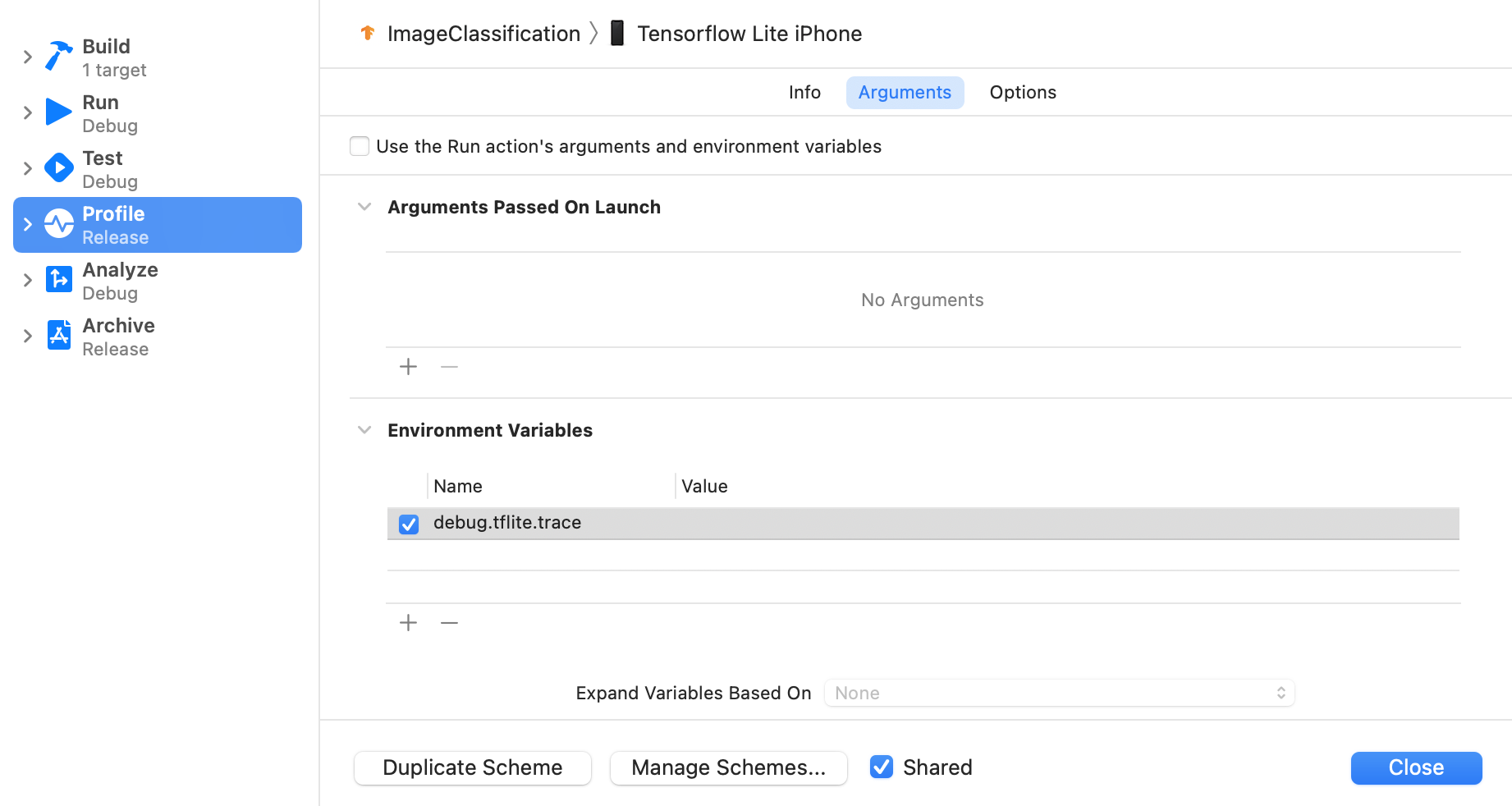
Jeśli chcesz wykluczyć zdarzenia TensorFlow Lite podczas profilowania aplikacji na iOS, wyłącz śledzenie, usuwając zmienną środowiskową.
Instrumenty XCode
Przechwyć ślady, wykonując poniższe czynności:
Wybierz opcję Produkt > Profil z górnego menu Xcode.
Kliknij opcję Rejestrowanie wśród szablonów profilowania po uruchomieniu narzędzia Instrumenty.
Naciśnij przycisk Start.
Naciśnij przycisk „Zatrzymaj”.
Kliknij „os_signpost”, aby rozwinąć elementy podsystemu rejestrowania systemu operacyjnego.
Kliknij podsystem rejestrowania systemu operacyjnego „org.tensorflow.lite”.
Zbadaj wynik śledzenia.
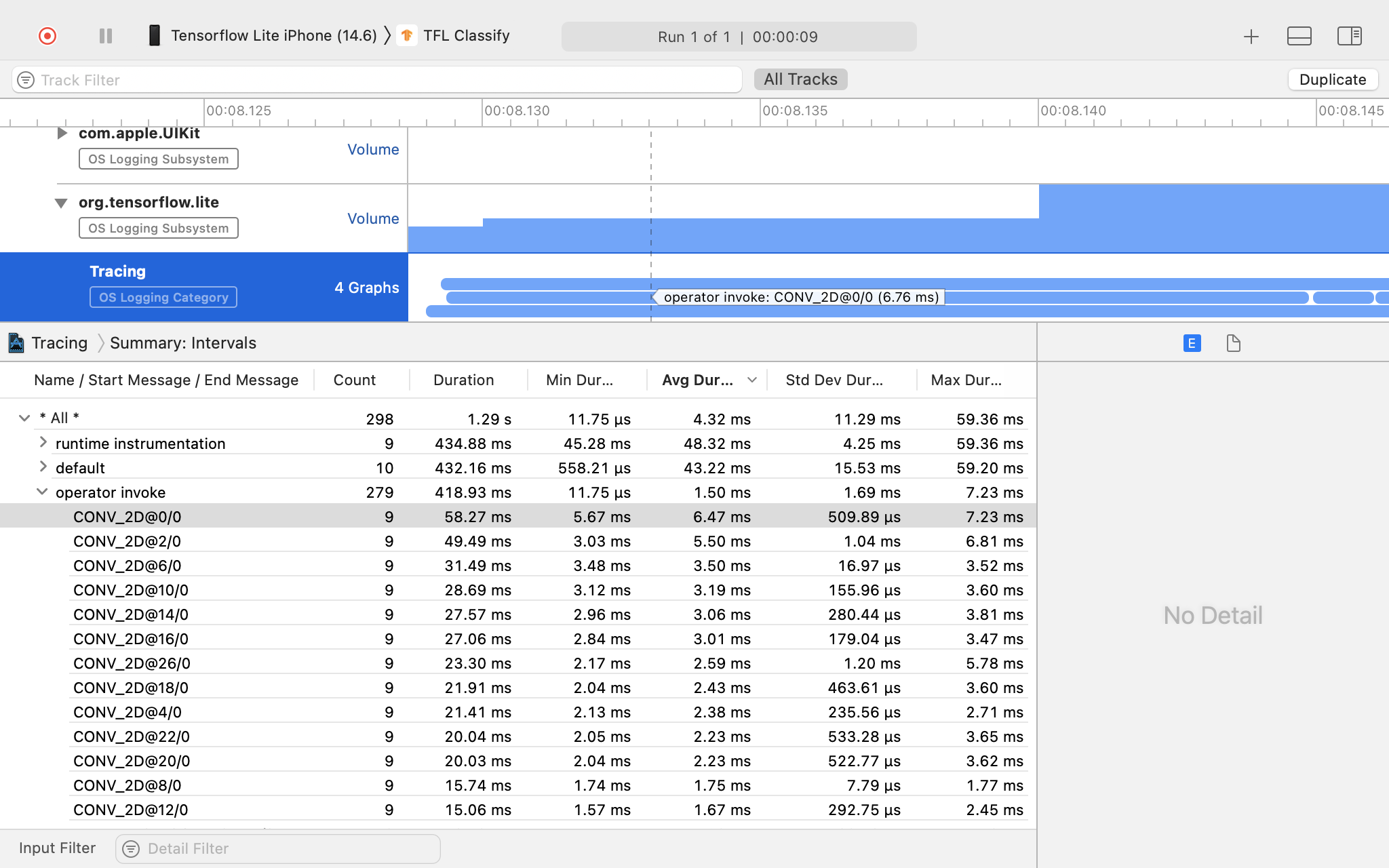
W tym przykładzie możesz zobaczyć hierarchię zdarzeń i statystyki dla każdego czasu operatora.
Korzystanie z danych śledzenia
Dane śledzenia umożliwiają identyfikację wąskich gardeł wydajności.
Oto kilka przykładów spostrzeżeń, które możesz uzyskać od profilera i potencjalnych rozwiązań poprawiających wydajność:
- Jeśli liczba dostępnych rdzeni procesora jest mniejsza niż liczba wątków wnioskowania, narzut planowania procesora może prowadzić do niskiej wydajności. Możesz zmienić harmonogram innych zadań intensywnie obciążających procesor w aplikacji, aby uniknąć nakładania się na wnioski z modelu lub dostosować liczbę wątków interpretera.
- Jeśli operatory nie są w pełni delegowane, niektóre części wykresu modelu są wykonywane na procesorze, a nie na oczekiwanym akceleratorze sprzętowym. Nieobsługiwane operatory można zastąpić podobnymi obsługiwanymi operatorami.