
| |
 在 Github 上查看源代码 在 Github 上查看源代码
|
|
在此 CoLab 笔记本中,您将学习如何使用 TensorFlow Lite Model Maker 训练语音识别模型,该模型可以使用一秒的声音样本对口语单词或短语进行分类。Model Maker 库使用迁移学习用新数据集重新训练现有的 TensorFlow 模型,这样能够减少样本数据量和训练所需的时间。
默认情况下,此笔记本使用语音命令数据集中的一个单词子集(如 “up”、“down”、“Left” 和 “Right”)重新训练模型(来自 TFJS 语音命令识别器的 BrowserFft)。然后会导出一个 TFLite 模型,您可以在移动设备或嵌入式系统(如 Raspberry PI)上运行该模型。它还会将训练好的模型导出为 TensorFlow SavedModel。
此笔记本还设计接受 WAV 文件的自定义数据集,并以 ZIP 文件的形式上传到 Colab。每个类的样本越多,准确率就越高,但由于迁移学习过程使用预训练模型中的特征嵌入向量,因此您仍然可以在每个类中只有几十个样本的情况下获得相当准确的模型。
注:我们将训练的模型针对一秒样本的语音识别进行了优化。如果您想执行更通用的音频分类(例如检测不同类型的音乐),我们建议您改用此 Colab 重新训练音频分类器。
如果要使用默认语音数据集运行笔记本,现在可以通过点击 Colab 工具栏中的 Runtime > Run all 来运行整个数据集。但是,如果您要使用您自己的数据集,请继续向下转至准备数据集部分,然后按照说明进行操作。
导入所需的包
您将需要 TensorFlow、TFLite Model Maker 和一些用于音频操作、回放和可视化的模块。
sudo apt -y install libportaudio2pip install tflite-model-maker
import os
import glob
import random
import shutil
import librosa
import soundfile as sf
from IPython.display import Audio
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import tflite_model_maker as mm
from tflite_model_maker import audio_classifier
from tflite_model_maker.config import ExportFormat
print(f"TensorFlow Version: {tf.__version__}")
print(f"Model Maker Version: {mm.__version__}")
TensorFlow Version: 2.9.1 Model Maker Version: 0.4.0
准备数据集
要使用默认的语音数据集进行训练,只需按原样运行下面的所有代码。
但是,如果您想要使用自己的语音数据集进行训练,请执行以下步骤:
注:您将重新训练的模型预计输入数据大约是 44.1 kHz 的一秒音频。Model Maker 完善了训练数据集的自动重采样,因此如果数据集的采样率不是 44.1 kHz,则无需对其进行重采样。但要注意,超过一秒的音频样本将被分成多个一秒的块,如果最后一个块短于一秒,就会被丢弃。
- 请确保您的数据集中的每个样本都是约一秒长的 WAV 文件格式。然后创建一个包含所有 WAV 文件的 ZIP 文件,并针对每个分类将其组织到单独的子文件夹中。例如,语音命令 “yes” 的每个示例都应位于名为 “yes” 的子文件夹中。即使您只有一个类,也必须将样本保存在一个子目录中,并将类名作为目录名。(此脚本假定您的数据集未拆分为训练集/验证集/测试集,并会为您执行拆分。)
- 点击左侧面板中的 Files 选项卡,只需将您的 ZIP 文件拖放到此处即可上传。
- 使用以下下拉选项将
use_custom_dataset设置为 True。 - 然后跳至准备自定义音频数据集以指定您的 ZIP 文件名和数据集目录名。
use_custom_dataset = False
生成背景噪声数据集
无论您使用的是默认语音数据集还是自定义数据集,您都应该有一组良好的背景噪声,以便您的模型能够将语音与其他噪声(包括静音)区分开来。
因为以下背景样本是在一分钟或更长的 WAV 文件中提供的,所以我们需要将它们分成较小的一秒样本,以便我们可以为测试数据集保留一些样本。我们还将组合两个不同的样本源,以构建一组全面的背景噪声和静音:
tf.keras.utils.get_file('speech_commands_v0.01.tar.gz',
'http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz',
cache_dir='./',
cache_subdir='dataset-speech',
extract=True)
tf.keras.utils.get_file('background_audio.zip',
'https://storage.googleapis.com/download.tensorflow.org/models/tflite/sound_classification/background_audio.zip',
cache_dir='./',
cache_subdir='dataset-background',
extract=True)
Downloading data from http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz 1489096277/1489096277 [==============================] - 8s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/models/tflite/sound_classification/background_audio.zip 1072437/1072437 [==============================] - 0s 0us/step './dataset-background/background_audio.zip'
注:虽然有较新的版本可用,但我们使用的是语音命令数据集的 v0.01,因为它是较小的下载版本。v0.01 包括 30 个命令,而 v0.02 在此基础上添加了五个命令("backward"、"forward"、"follow"、"learn" 和 "visual")。
# Create a list of all the background wav files
files = glob.glob(os.path.join('./dataset-speech/_background_noise_', '*.wav'))
files = files + glob.glob(os.path.join('./dataset-background', '*.wav'))
background_dir = './background'
os.makedirs(background_dir, exist_ok=True)
# Loop through all files and split each into several one-second wav files
for file in files:
filename = os.path.basename(os.path.normpath(file))
print('Splitting', filename)
name = os.path.splitext(filename)[0]
rate = librosa.get_samplerate(file)
length = round(librosa.get_duration(filename=file))
for i in range(length - 1):
start = i * rate
stop = (i * rate) + rate
data, _ = sf.read(file, start=start, stop=stop)
sf.write(os.path.join(background_dir, name + str(i) + '.wav'), data, rate)
Splitting dude_miaowing.wav Splitting pink_noise.wav Splitting doing_the_dishes.wav Splitting exercise_bike.wav Splitting white_noise.wav Splitting running_tap.wav Splitting silence.wav Splitting throat_clearing.wav
准备语音命令数据集
我们已经下载了语音命令数据集,所以现在我们只需为我们的模型修剪类的数量。
此数据集包括 30 多个语音命令分类,其中大多数分类都有超过 2,000 个样本。但因为我们使用的是迁移学习,所以不需要那么多样本。因此,以下代码完成了下面几项操作:
- 指定我们要使用的分类,并删除其余的分类。
- 只为每个类保留 150 个样本用于训练(以证明迁移学习在较小的数据集上效果良好,也是为了减少训练时间)。
- 为测试数据集创建一个单独的目录,以便我们稍后可以轻松地用它们运行推断。
if not use_custom_dataset:
commands = [ "up", "down", "left", "right", "go", "stop", "on", "off", "background"]
dataset_dir = './dataset-speech'
test_dir = './dataset-test'
# Move the processed background samples
shutil.move(background_dir, os.path.join(dataset_dir, 'background'))
# Delete all directories that are not in our commands list
dirs = glob.glob(os.path.join(dataset_dir, '*/'))
for dir in dirs:
name = os.path.basename(os.path.normpath(dir))
if name not in commands:
shutil.rmtree(dir)
# Count is per class
sample_count = 150
test_data_ratio = 0.2
test_count = round(sample_count * test_data_ratio)
# Loop through child directories (each class of wav files)
dirs = glob.glob(os.path.join(dataset_dir, '*/'))
for dir in dirs:
files = glob.glob(os.path.join(dir, '*.wav'))
random.seed(42)
random.shuffle(files)
# Move test samples:
for file in files[sample_count:sample_count + test_count]:
class_dir = os.path.basename(os.path.normpath(dir))
os.makedirs(os.path.join(test_dir, class_dir), exist_ok=True)
os.rename(file, os.path.join(test_dir, class_dir, os.path.basename(file)))
# Delete remaining samples
for file in files[sample_count + test_count:]:
os.remove(file)
准备自定义数据集
如果您想用我们自己的语音数据集训练模型,您需要将样本作为 WAV 文件上传为 ZIP(如上所述),并修改以下变量以指定您的数据集:
if use_custom_dataset:
# Specify the ZIP file you uploaded:
!unzip YOUR-FILENAME.zip
# Specify the unzipped path to your custom dataset
# (this path contains all the subfolders with classification names):
dataset_dir = './YOUR-DIRNAME'
在更改了上面的文件名和路径名之后,您就可以使用您的自定义数据集训练模型了。在 Colab 工具栏中,选择 Runtime > Run all 以运行整个笔记本。
下面的代码会将我们新的背景噪声样本集成到您的数据集中,然后分离所有样本的一部分以创建测试集。
def move_background_dataset(dataset_dir):
dest_dir = os.path.join(dataset_dir, 'background')
if os.path.exists(dest_dir):
files = glob.glob(os.path.join(background_dir, '*.wav'))
for file in files:
shutil.move(file, dest_dir)
else:
shutil.move(background_dir, dest_dir)
if use_custom_dataset:
# Move background samples into custom dataset
move_background_dataset(dataset_dir)
# Now we separate some of the files that we'll use for testing:
test_dir = './dataset-test'
test_data_ratio = 0.2
dirs = glob.glob(os.path.join(dataset_dir, '*/'))
for dir in dirs:
files = glob.glob(os.path.join(dir, '*.wav'))
test_count = round(len(files) * test_data_ratio)
random.seed(42)
random.shuffle(files)
# Move test samples:
for file in files[:test_count]:
class_dir = os.path.basename(os.path.normpath(dir))
os.makedirs(os.path.join(test_dir, class_dir), exist_ok=True)
os.rename(file, os.path.join(test_dir, class_dir, os.path.basename(file)))
print('Moved', test_count, 'images from', class_dir)
播放样本
为了确保数据集看起来正确,我们从测试集中随机抽取一个样本:
def get_random_audio_file(samples_dir):
files = os.path.abspath(os.path.join(samples_dir, '*/*.wav'))
files_list = glob.glob(files)
random_audio_path = random.choice(files_list)
return random_audio_path
def show_sample(audio_path):
audio_data, sample_rate = sf.read(audio_path)
class_name = os.path.basename(os.path.dirname(audio_path))
print(f'Class: {class_name}')
print(f'File: {audio_path}')
print(f'Sample rate: {sample_rate}')
print(f'Sample length: {len(audio_data)}')
plt.title(class_name)
plt.plot(audio_data)
display(Audio(audio_data, rate=sample_rate))
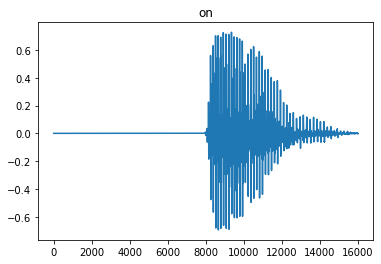
random_audio = get_random_audio_file(test_dir)
show_sample(random_audio)
Class: on File: /tmpfs/src/temp/site/zh-cn/lite/models/modify/model_maker/dataset-test/on/c0445658_nohash_1.wav Sample rate: 16000 Sample length: 16000
定义模型
使用 Model Maker 重新训练任何模型时,必须从定义模型规范开始。该规范定义了基本模型,您的新模型将从中提取特征嵌入向量以开始学习新类。此语音识别器的规范基于预训练的来自 TFJS 的 BrowserFft 模型。
该模型要求输入的音频样本为 44.1 kHz,长度略小于一秒:准确的样本长度必须为 44034 帧。
您不需要对训练数据集进行任何重采样。Model Maker 会帮您完成。但是,当您稍后运行推断时,必须确保您的输入与预期的格式匹配。
您只需在此处实例化 BrowserFftSpec:
spec = audio_classifier.BrowserFftSpec()
INFO:tensorflow:Checkpoints are stored in /tmpfs/tmp/tmpwe5haf8l Downloading data from https://storage.googleapis.com/tfjs-models/tfjs/speech-commands/conversion/sc_preproc_model.tar.gz 18467/18467 [==============================] - 0s 0us/step WARNING:tensorflow:SavedModel saved prior to TF 2.5 detected when loading Keras model. Please ensure that you are saving the model with model.save() or tf.keras.models.save_model(), *NOT* tf.saved_model.save(). To confirm, there should be a file named "keras_metadata.pb" in the SavedModel directory. WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Downloading data from https://storage.googleapis.com/tfjs-models/tfjs/speech-commands/v0.3/browser_fft/18w/metadata.json 203/203 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tfjs-models/tfjs/speech-commands/v0.3/browser_fft/18w/model.json 5466/5466 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tfjs-models/tfjs/speech-commands/v0.3/browser_fft/18w/group1-shard1of2 4194304/4194304 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tfjs-models/tfjs/speech-commands/v0.3/browser_fft/18w/group1-shard2of2 1680432/1680432 [==============================] - 0s 0us/step
加载数据集
现在您需要根据模型规范加载您的数据集。Model Maker 包括 DataLoader API,它将从文件夹加载您的数据集,并确保其格式符合模型规范的预期格式。
我们已经通过将一些测试文件移动到单独的目录来保留它们,这样稍后就更容易对它们运行推断。现在,我们将为每个拆分创建一个 DataLoader:训练集、验证集和测试集。
加载语音命令数据集
if not use_custom_dataset:
train_data_ratio = 0.8
train_data = audio_classifier.DataLoader.from_folder(
spec, dataset_dir, cache=True)
train_data, validation_data = train_data.split(train_data_ratio)
test_data = audio_classifier.DataLoader.from_folder(
spec, test_dir, cache=True)
加载自定义数据集
注:设置 cache=True 对于提高训练速度很重要(尤其是在必须对数据集进行重新采样的情况下),但它也需要更多的 RAM 来保存数据。如果您使用的是非常大的自定义数据集,缓存可能会超出您的 RAM 容量。
if use_custom_dataset:
train_data_ratio = 0.8
train_data = audio_classifier.DataLoader.from_folder(
spec, dataset_dir, cache=True)
train_data, validation_data = train_data.split(train_data_ratio)
test_data = audio_classifier.DataLoader.from_folder(
spec, test_dir, cache=True)
训练模型。
现在,我们将使用 Model Maker create() 函数,基于我们的模型规范和训练数据集创建一个模型,并开始训练。
如果您使用的是自定义数据集,则可能需要根据训练集中的样本数适当地更改批次大小。
注:第一个周期需要更长的时间,因为它必须创建缓存。
# If your dataset has fewer than 100 samples per class,
# you might want to try a smaller batch size
batch_size = 25
epochs = 25
model = audio_classifier.create(train_data, spec, validation_data, batch_size, epochs)
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 42, 225, 8) 136
max_pooling2d_1 (MaxPooling (None, 21, 112, 8) 0
2D)
conv2d_2 (Conv2D) (None, 20, 109, 32) 2080
max_pooling2d_2 (MaxPooling (None, 10, 54, 32) 0
2D)
conv2d_3 (Conv2D) (None, 9, 51, 32) 8224
max_pooling2d_3 (MaxPooling (None, 4, 25, 32) 0
2D)
conv2d_4 (Conv2D) (None, 3, 22, 32) 8224
max_pooling2d_4 (MaxPooling (None, 2, 11, 32) 0
2D)
flatten_1 (Flatten) (None, 704) 0
dropout_1 (Dropout) (None, 704) 0
dense_1 (Dense) (None, 2000) 1410000
dropout_2 (Dropout) (None, 2000) 0
classification_head (Dense) (None, 9) 18009
=================================================================
Total params: 1,446,673
Trainable params: 18,009
Non-trainable params: 1,428,664
_________________________________________________________________
Epoch 1/25
40/40 [==============================] - 78s 2s/step - loss: 2.1725 - acc: 0.4593 - val_loss: 0.3731 - val_acc: 0.8857
Epoch 2/25
40/40 [==============================] - 0s 7ms/step - loss: 0.6046 - acc: 0.7984 - val_loss: 0.2068 - val_acc: 0.9388
Epoch 3/25
40/40 [==============================] - 0s 7ms/step - loss: 0.4418 - acc: 0.8697 - val_loss: 0.1555 - val_acc: 0.9592
Epoch 4/25
40/40 [==============================] - 0s 7ms/step - loss: 0.3671 - acc: 0.8951 - val_loss: 0.1368 - val_acc: 0.9633
Epoch 5/25
40/40 [==============================] - 0s 7ms/step - loss: 0.3326 - acc: 0.8961 - val_loss: 0.1238 - val_acc: 0.9673
Epoch 6/25
40/40 [==============================] - 0s 7ms/step - loss: 0.3106 - acc: 0.9022 - val_loss: 0.1242 - val_acc: 0.9714
Epoch 7/25
40/40 [==============================] - 0s 7ms/step - loss: 0.2398 - acc: 0.9175 - val_loss: 0.1223 - val_acc: 0.9714
Epoch 8/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1958 - acc: 0.9379 - val_loss: 0.1128 - val_acc: 0.9755
Epoch 9/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1638 - acc: 0.9450 - val_loss: 0.1119 - val_acc: 0.9755
Epoch 10/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1694 - acc: 0.9491 - val_loss: 0.1227 - val_acc: 0.9714
Epoch 11/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1540 - acc: 0.9450 - val_loss: 0.1072 - val_acc: 0.9796
Epoch 12/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1359 - acc: 0.9491 - val_loss: 0.1119 - val_acc: 0.9755
Epoch 13/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1185 - acc: 0.9684 - val_loss: 0.1033 - val_acc: 0.9755
Epoch 14/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1254 - acc: 0.9511 - val_loss: 0.1103 - val_acc: 0.9714
Epoch 15/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1297 - acc: 0.9562 - val_loss: 0.1095 - val_acc: 0.9755
Epoch 16/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1104 - acc: 0.9633 - val_loss: 0.1034 - val_acc: 0.9796
Epoch 17/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1069 - acc: 0.9654 - val_loss: 0.1130 - val_acc: 0.9755
Epoch 18/25
40/40 [==============================] - 0s 7ms/step - loss: 0.1054 - acc: 0.9644 - val_loss: 0.0998 - val_acc: 0.9837
Epoch 19/25
40/40 [==============================] - 0s 7ms/step - loss: 0.0779 - acc: 0.9725 - val_loss: 0.1041 - val_acc: 0.9837
Epoch 20/25
40/40 [==============================] - 0s 7ms/step - loss: 0.0866 - acc: 0.9705 - val_loss: 0.1055 - val_acc: 0.9796
Epoch 21/25
40/40 [==============================] - 0s 7ms/step - loss: 0.0815 - acc: 0.9695 - val_loss: 0.1056 - val_acc: 0.9796
Epoch 22/25
40/40 [==============================] - 0s 7ms/step - loss: 0.0737 - acc: 0.9756 - val_loss: 0.1034 - val_acc: 0.9796
Epoch 23/25
40/40 [==============================] - 0s 7ms/step - loss: 0.0728 - acc: 0.9756 - val_loss: 0.1109 - val_acc: 0.9755
Epoch 24/25
40/40 [==============================] - 0s 7ms/step - loss: 0.0935 - acc: 0.9664 - val_loss: 0.1052 - val_acc: 0.9714
Epoch 25/25
40/40 [==============================] - 0s 7ms/step - loss: 0.0665 - acc: 0.9776 - val_loss: 0.0948 - val_acc: 0.9796
查看模型性能
即使上面的训练输出在准确率/损失方面看起来很不错,使用模型尚未见过的测试数据来运行模型仍很重要,这就是 evaluate() 方法在此处的作用:
model.evaluate(test_data)
8/8 [==============================] - 2s 165ms/step - loss: 0.1042 - acc: 0.9837 [0.10416107624769211, 0.9836734533309937]
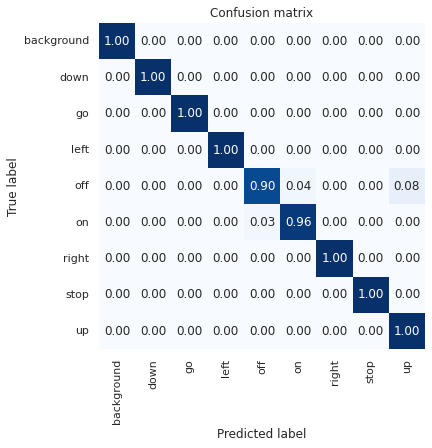
查看混淆矩阵
在训练像这样的分类模型时,检查混淆矩阵也很有用。混淆矩阵能够为您提供详细的可视表示,显示您的分类器在测试数据的每个分类上性能。
def show_confusion_matrix(confusion, test_labels):
"""Compute confusion matrix and normalize."""
confusion_normalized = confusion.astype("float") / confusion.sum(axis=1)
sns.set(rc = {'figure.figsize':(6,6)})
sns.heatmap(
confusion_normalized, xticklabels=test_labels, yticklabels=test_labels,
cmap='Blues', annot=True, fmt='.2f', square=True, cbar=False)
plt.title("Confusion matrix")
plt.ylabel("True label")
plt.xlabel("Predicted label")
confusion_matrix = model.confusion_matrix(test_data)
show_confusion_matrix(confusion_matrix.numpy(), test_data.index_to_label)
1/1 [==============================] - 0s 277ms/step 1/1 [==============================] - 0s 70ms/step 1/1 [==============================] - 0s 47ms/step 1/1 [==============================] - 0s 65ms/step 1/1 [==============================] - 0s 24ms/step 1/1 [==============================] - 0s 23ms/step 1/1 [==============================] - 0s 21ms/step 1/1 [==============================] - 0s 94ms/step
导出模型
最后一步是将模型导出为 TensorFlow Lite 格式以便在移动/嵌入式设备上执行,并导出为 SavedModel 格式以便在其他地方执行。
从 Model Maker 导出 .tflite 文件时,会包括描述各种详细信息的模型元数据,这些信息将在之后的推断过程中提供帮助。它甚至包括分类标签文件的副本,因此您不需要单独的 labels.txt 文件。(在下一部分中,我们将展示如何使用此元数据来运行推断。)
TFLITE_FILENAME = 'browserfft-speech.tflite'
SAVE_PATH = './models'
print(f'Exporing the model to {SAVE_PATH}')
model.export(SAVE_PATH, tflite_filename=TFLITE_FILENAME)
model.export(SAVE_PATH, export_format=[mm.ExportFormat.SAVED_MODEL, mm.ExportFormat.LABEL])
Exporing the model to ./models WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op while saving (showing 4 of 4). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpsrbr3668/assets INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpsrbr3668/assets 2022-08-11 18:49:29.493921: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:362] Ignored output_format. 2022-08-11 18:49:29.493975: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:365] Ignored drop_control_dependency. INFO:tensorflow:TensorFlow Lite model exported successfully: ./models/browserfft-speech.tflite INFO:tensorflow:TensorFlow Lite model exported successfully: ./models/browserfft-speech.tflite WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op while saving (showing 4 of 4). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: ./models/saved_model/assets INFO:tensorflow:Assets written to: ./models/saved_model/assets INFO:tensorflow:Saving labels in ./models/labels.txt INFO:tensorflow:Saving labels in ./models/labels.txt
使用 TF Lite 模型运行推断
现在,您的 TFLite 模型可以使用任何受支持的推断库或新的 TFLite AudioClassifier Task API 来部署和运行。下面的代码展示了如何在 Python 中使用 .tflite 模型运行推断。
# This library provides the TFLite metadata APIpip install -q tflite_support
from tflite_support import metadata
import json
def get_labels(model):
"""Returns a list of labels, extracted from the model metadata."""
displayer = metadata.MetadataDisplayer.with_model_file(model)
labels_file = displayer.get_packed_associated_file_list()[0]
labels = displayer.get_associated_file_buffer(labels_file).decode()
return [line for line in labels.split('\n')]
def get_input_sample_rate(model):
"""Returns the model's expected sample rate, from the model metadata."""
displayer = metadata.MetadataDisplayer.with_model_file(model)
metadata_json = json.loads(displayer.get_metadata_json())
input_tensor_metadata = metadata_json['subgraph_metadata'][0][
'input_tensor_metadata'][0]
input_content_props = input_tensor_metadata['content']['content_properties']
return input_content_props['sample_rate']
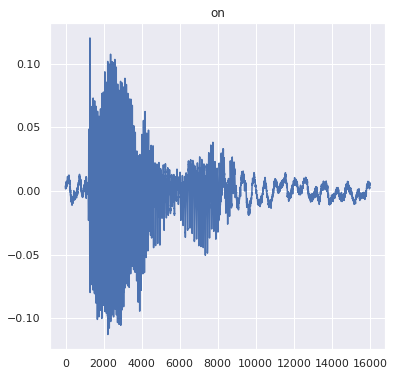
要观察模型在实际样本上的性能,请反复运行以下代码块。每次运行,模型都会获取一个新的测试样本并对其运行推断,您可以收听下面的音频样本。
# Get a WAV file for inference and list of labels from the model
tflite_file = os.path.join(SAVE_PATH, TFLITE_FILENAME)
labels = get_labels(tflite_file)
random_audio = get_random_audio_file(test_dir)
# Ensure the audio sample fits the model input
interpreter = tf.lite.Interpreter(tflite_file)
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_size = input_details[0]['shape'][1]
sample_rate = get_input_sample_rate(tflite_file)
audio_data, _ = librosa.load(random_audio, sr=sample_rate)
if len(audio_data) < input_size:
audio_data.resize(input_size)
audio_data = np.expand_dims(audio_data[:input_size], axis=0)
# Run inference
interpreter.allocate_tensors()
interpreter.set_tensor(input_details[0]['index'], audio_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
# Display prediction and ground truth
top_index = np.argmax(output_data[0])
label = labels[top_index]
score = output_data[0][top_index]
print('---prediction---')
print(f'Class: {label}\nScore: {score}')
print('----truth----')
show_sample(random_audio)
---prediction--- Class: on Score: 0.999117910861969 ----truth---- Class: on File: /tmpfs/src/temp/site/zh-cn/lite/models/modify/model_maker/dataset-test/on/fb2f3242_nohash_0.wav Sample rate: 16000 Sample length: 16000 INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
下载 TF Lite 模型
现在,您可以将 TF Lite 模型部署到您的移动或嵌入式设备。您不需要下载标签文件,因为您可以从 .tflite 文件元数据中检索标签,如前面的推断示例所示。
try:
from google.colab import files
except ImportError:
pass
else:
files.download(tflite_file)