
훈련 후 양자화는 모델 정확성을 거의 저하시키지 않으면서 CPU 및 하드웨어 가속기 지연 시간을 개선하고 모델 크기를 줄일 수 있는 변환 기술입니다. TensorFlow Lite 변환기를 사용하여 TensorFlow Lite 형식으로 변환할 때 이미 훈련된 부동 TensorFlow 모델을 양자화할 수 있습니다.
참고: 해당 페이지의 절차를 따르려면 TensorFlow 1.15 이상이 필요합니다.
최적화 메서드
선택할 수 있는 몇 가지 훈련 후 양자화 옵션이 있습니다. 다음은 선택 항목과 선택 항목이 제공하는 이점에 대한 요약표입니다.
| 기술 | 이점 | 하드웨어 |
|---|---|---|
| 동적 범위 | 4배 작아짐, 2배-3배 속도 향상 | CPU |
| : 양자화 : : : | ||
| 전체 정수 | 4배 더 작게, 3배 이상의 속도 향상 | CPU, 에지 TPU |
| : 양자화 : : 마이크로 컨트롤러 : | ||
| Float16 양자화 | 2배 더 작아진 GPU | CPU, GPU |
| : : 가속 : : |
다음 의사 결정 트리는 사용 사례에 가장 적합한 훈련 후 양자화 메서드를 결정하는 데 도움이 될 수 있습니다.
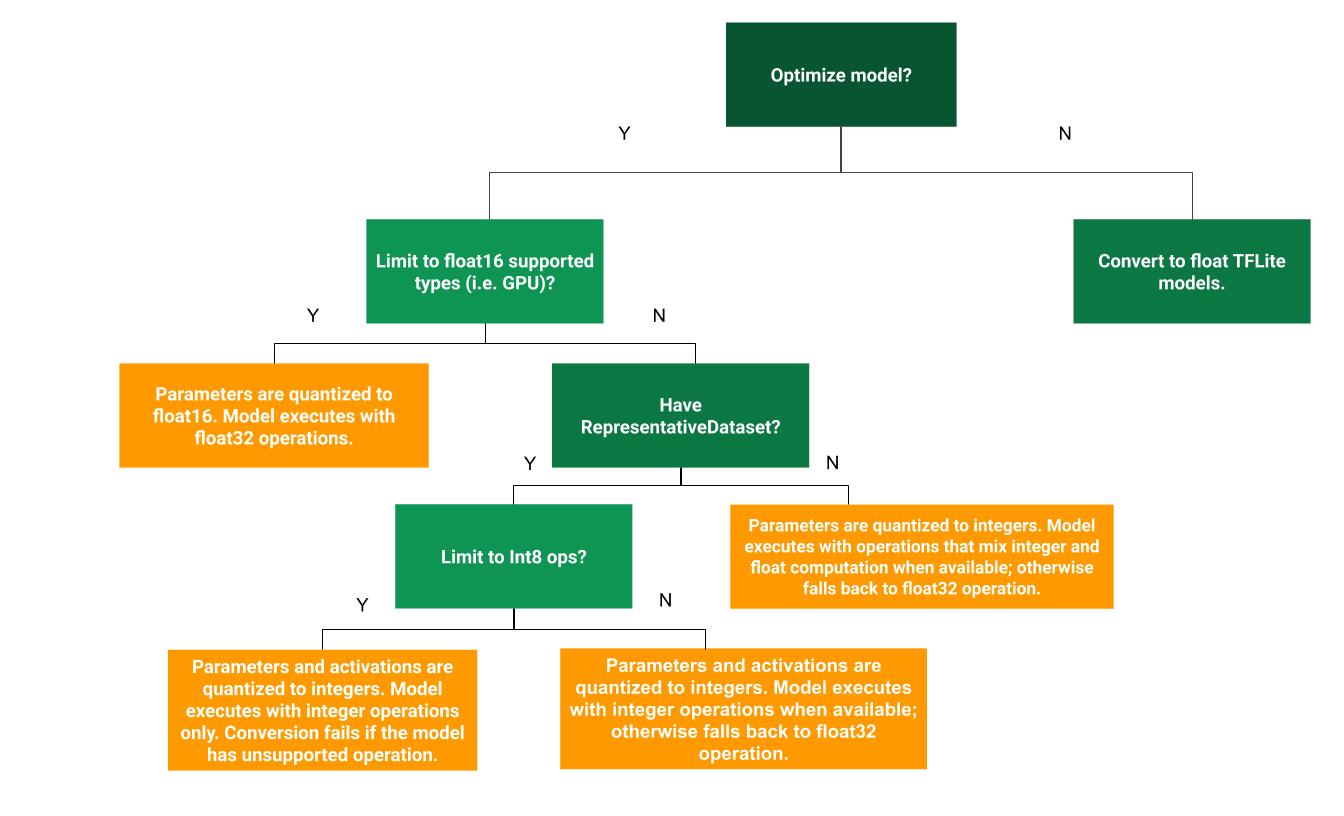
동적 범위 양자화
동적 범위 양자화는 보정을 위한 대표 데이터세트를 제공하지 않아도 메모리 사용량을 줄여주고 더 빠른 컴퓨팅을 할 수 있도록 해주므로 시작 지점으로 좋습니다. 이러한 유형의 양자화는 변환 시 부동 소수점부터 정수까지의 가중치로만 정적으로 양자화하여 8비트의 정밀도를 제공합니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) <b>converter.optimizations = [tf.lite.Optimize.DEFAULT]</b> tflite_quant_model = converter.convert()
지연 시간을 더욱 개선하기 위해 "동적 범위" 연산자는 8비트까지의 범위를 기반으로 활성화를 동적으로 양자화하고 8비트 가중치 및 활성화를 사용하여 계산을 수행합니다. 이 최적화는 전체 고정 소수점 추론에 가까운 지연을 제공합니다. 그러나 출력은 여전히 부동 소수점을 허용하여 저장되므로 향상된 동적 범위 연산 속도는 전체 고정 소수점 계산보다 적습니다.
전체 정수 양자화
모든 모델 수학이 정수 양자화되었는지 확인하여 추가 지연 시간 개선, 최대 메모리 사용량 감소, 정수 전용 하드웨어 기기 또는 가속기와의 호환성을 얻을 수 있습니다.
완전한 정수 양자화의 경우, 모델에 있는 모든 부동 소수점 텐서의 범위, 즉 (최소, 최대)를 보정하거나 추정해야 합니다. 가중치 및 편향과 같은 상수 텐서와 달리 모델 입력, 활성화 (중간 계층의 출력) 및 모델 출력과 같은 가변 텐서는 몇 가지 추론 주기를 실행하지 않는 한 보정할 수 없습니다. 결과적으로, 변환기는 이를 보정하기 위해 대표적 데이터세트가 필요합니다. 이 데이터세트는 훈련 또는 검증 데이터의 작은 하위 집합(약 100 ~ 500개 샘플)일 수 있습니다. 아래의 representative_dataset() 함수를 참조하세요.
TensorFlow 2.7 버전부터 다음 예제와 같이 서명을 통해 대표 데이터세트를 지정할 수 있습니다.
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
주어진 TensorFlow 모델에 둘 이상의 서명이 있는 경우 서명 키를 지정하여 여러 데이터세트를 지정할 수 있습니다.
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
입력 텐서 목록을 제공하여 대표적인 데이터세트를 생성할 수 있습니다.
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 버전부터 입력 텐서 목록 기반 접근 방식보다 서명 기반 접근 방식을 사용하는 것이 좋은데, 입력 텐서 순서를 쉽게 뒤집을 수 있기 때문입니다.
테스트 목적으로 다음과 같이 더미 데이터세트를 사용할 수 있습니다.
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]부동 폴 백이 있는 정수(기본 부동 입력/출력 사용하기)
모델을 완전히 정수로 양자화하지만 정수 구현이 없는 경우 부동 연산자를 사용하려면(원활하게 변환을 수행하기 위해) 다음 단계를 사용합니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) <b>converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset</b> tflite_quant_model = converter.convert()
참고: tflite_quant_model은 정수 전용 기기(예: 8bit 마이크로 컨트롤러) 및 가속기(예: Coral 에지 TPU)와 호환되지 않습니다. 입력 및 출력이 원본 부동 모델과 같은 인터페이스를 갖기 위해 여전히 부동 상태로 남아 있기 때문입니다.
정수 전용
정수 전용 모델을 만드는 것은 마이크로콘트롤러용 TensorFlow Lite 및 Coral Edge TPU의 일반적인 사용 사례입니다.
참고: TensorFlow 2.3.0부터는 inference_input_type 및 inference_output_type 속성을 지원합니다.
또한 정수 전용 기기(예: 8bit 마이크로컨트롤러) 및 가속기(예: Coral Edge TPU)와의 호환성을 보장하기 위해 다음 단계를 사용하여 입력 및 출력을 포함한 모든 연산에 대해 전체 정수 양자화를 적용할 수 있습니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset <b>converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]</b> <b>converter.inference_input_type = tf.int8</b> # or tf.uint8 <b>converter.inference_output_type = tf.int8</b> # or tf.uint8 tflite_quant_model = converter.convert()
참고: 변환기는 현재 양자화할 수 없는 연산이 일어나면 오류를 발생시킵니다.
Float16 양자화
가중치를 16bit 부동 소수점 숫자에 대한 IEEE 표준인 float16으로 양자화하여 부동 소수점 모델의 크기를 줄일 수 있습니다. 가중치의 float16 양자화를 활성화하려면 다음 스탭을 사용합니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) <b>converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16]</b> tflite_quant_model = converter.convert()
float16 양자화의 장점은 다음과 같습니다.
- (모든 가중치가 원래 크기의 절반이되므로) 모델 크기를 최대 절반까지 줄입니다.
- 정확성 손실을 최소화합니다.
- float16 데이터에서 직접 동작할 수 있는 일부 대리자(예: GPU 대리자)를 지원하므로 float32 계산보다 빠른 실행이 가능합니다.
float16 양자화의 단점은 다음과 같습니다.
- 고정 소수점 수학에 대한 양자화만큼 지연 시간을 줄이지 않습니다.
- 기본적으로 float16 양자화된 모델은 CPU에서 실행될 때 가중치 값을 float32로 '역양자화'합니다. (GPU 대리자는 float16 데이터에서 동작할 수 있으므로 이 역양자화를 수행하지 않습니다.)
정수 전용: 8bit 가중치를 사용한 16bit 활성화(실험적)
이것은 실험적인 양자화 체계입니다. 이는 '정수 전용' 방식과 유사하지만 활성화는 16bit 범위에 따라 양자화되고 가중치는 8bit 정수로 양자화되고 바이어스는 64bit 정수로 양자화됩니다. 이를 16x8 양자화라고 합니다.
이 양자화의 주요 장점은 정확성을 크게 향상시키면서도 모델 크기는 아주 약간만 늘릴 수 있다는 것입니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset <b>converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8]</b> tflite_quant_model = converter.convert()
모델의 일부 연산자에 대해 16x8 양자화가 지원되지 않는 경우 모델은 여전히 양자화될 수 있지만 지원되지 않는 연산자는 부동 상태로 유지됩니다. 이를 허용하려면 다음 옵션을 target_spec에 추가해야 합니다.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, <b>tf.lite.OpsSet.TFLITE_BUILTINS</b>] tflite_quant_model = converter.convert()
이 양자화 체계에 의해 정확도가 향상되는 사용 사례의 예는 다음과 같습니다: * 초고해상도, * 노이즈 제거 및 빔포밍과 같은 오디오 신호 처리, * 이미지 노이즈 제거, * 단일 이미지에서 HDR 재구성.
이 양자화의 단점은 다음과 같습니다.
- 현재 추론은 최적화된 커널 구현이 없기 때문에 8bit 정수보다 눈에 띄게 느립니다.
- 현재 기존 하드웨어 가속 TFLite 대리자와 호환되지 않습니다.
참고: 이것은 실험적인 특성입니다.
이 양자화 모드에 대한 튜토리얼은 여기에서 찾을 수 있습니다.
모델 정확성
가중치는 훈련 후에 양자화되기 때문에 특히 소규모 네트워크의 경우 정확성 손실이 있을 수 있습니다. TensorFlow Hub에서 특정 네트워크에 대해 사전 훈련된 전체 양자화 모델이 제공됩니다. 정확성 저하가 허용 가능한 한계 내에 있는지 확인하기 위해 양자화된 모델의 정확성을 확인하는 것이 중요합니다. TensorFlow Lite 모델 정확성을 평가하는 도구가 있습니다.
또는 정확성 저하가 너무 크면 양자화 인식 훈련을 사용해 볼 수 있습니다. 그러나 해당 훈련을 사용하려면 모델 훈련 중에 수정하여 가짜 양자화 노드를 추가해야 하지만, 이 페이지의 훈련 후 양자화 기술은 기존의 사전 훈련된 모델을 사용합니다.
양자화된 텐서 표현
8bit 양자화는 다음 공식을 사용하여 부동 소수점 값을 근사화합니다.
\[real_value = (int8_value - zero_point) \times scale\]
표현에는 두 가지 주요 부분이 있습니다.
축당(일명 채널당) 또는 텐서당 가중치는 0과 같은 영점이 있는 [-127, 127] 범위의 int8 2의 보수 값으로 표시됩니다.
텐서별 활성화/입력은 [-128, 127] 범위의 int8 2의 보수 값으로 표시되며 [-128, 127] 범위의 영점을 포함합니다.
양자화 체계에 대한 자세한 내용은 양자화 사양을 참조하세요. TensorFlow Lite의 대리자 인터페이스에 연결하려는 하드웨어 공급 업체는 여기에 설명된 양자화 체계를 구현해보는 것이 좋습니다.