
TL;DR : сокращение шаблонного кода для создания, обучения и обслуживания моделей ранжирования TensorFlow с помощью конвейеров ранжирования TensorFlow; Используйте правильные распределенные стратегии для крупномасштабных приложений ранжирования с учетом варианта использования и ресурсов.
Введение
Конвейер ранжирования TensorFlow состоит из серии процессов обработки данных, построения моделей, обучения и обслуживания, которые позволяют создавать, обучать и обслуживать масштабируемые модели ранжирования на основе нейронных сетей из журналов данных с минимальными усилиями. Конвейер наиболее эффективен при масштабировании системы. В общем, если запуск вашей модели на одном компьютере занимает 10 или более минут, рассмотрите возможность использования этой структуры конвейера для распределения нагрузки и ускорения обработки.
Конвейер ранжирования TensorFlow постоянно и стабильно использовался в крупномасштабных экспериментах и проектах с большими данными (более терабайт) и большими моделями (более 100 миллионов FLOP) в распределенных системах (более 1 тыс. ЦП и более 100 графических процессоров и TPU). После того как модель TensorFlow проверена с помощью model.fit на небольшой части данных, конвейер рекомендуется использовать для сканирования гиперпараметров, непрерывного обучения и других крупномасштабных ситуаций.
Рейтинговый конвейер
В TensorFlow типичный конвейер построения, обучения и обслуживания модели ранжирования включает следующие типичные шаги.
- Определите структуру модели:
- Создание входов;
- Создание слоев предварительной обработки;
- Создавать архитектуру нейронной сети;
- Модель поезда:
- Создание наборов данных обучения и проверки на основе журналов данных;
- Подготовьте модель с правильными гиперпараметрами:
- Оптимизатор;
- Рейтинговые потери;
- Рейтинговые метрики;
- Настройте распределенные стратегии для обучения на нескольких устройствах.
- Настройте обратные вызовы для различной бухгалтерии.
- Экспортная модель для обслуживания;
- Модель обслуживания:
- Определить формат данных при обслуживании;
- Выбрать и загрузить обученную модель;
- Обработка с загруженной моделью.
Одной из основных целей конвейера ранжирования TensorFlow является сокращение количества шаблонного кода на таких этапах, как загрузка и предварительная обработка набора данных, совместимость списочных данных и функции точечной оценки, а также экспорт модели. Другая важная цель состоит в том, чтобы обеспечить единообразный дизайн многих взаимосвязанных процессов, например, входные данные модели должны быть совместимы как с наборами обучающих данных, так и с форматом данных при обслуживании.
Использование руководства
Учитывая все вышеизложенное, запуск модели ранжирования TF состоит из следующих этапов, как показано на рисунке 1.
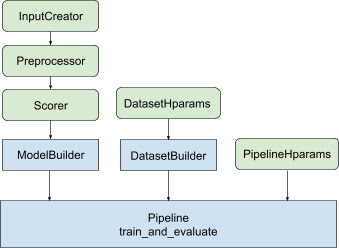
Пример использования распределенной нейронной сети
В этом примере вы будете использовать встроенные tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder и tfr.keras.pipeline.SimplePipeline , которые принимают feature_spec для последовательного определения входных объектов во входных данных модели и сервер набора данных. Версию блокнота с пошаговым руководством можно найти в руководстве по распределенному ранжированию .
Сначала определите feature_spec как для контекста, так и для примеров функций.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Выполните действия, показанные на рисунке 1:
Определите input_creator из feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Затем определите преобразования объектов предварительной обработки для того же набора входных объектов.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Определите бомбардир с помощью встроенной модели DNN с прямой связью.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Создайте model_builder с помощью input_creator , preprocessor и scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Теперь установите гиперпараметры для dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Создайте dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Также установите гиперпараметры для конвейера.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Создайте ranking_pipeline и тренируйтесь.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Проектирование конвейера ранжирования TensorFlow
Конвейер ранжирования TensorFlow помогает сэкономить время разработки с помощью шаблонного кода и в то же время обеспечивает гибкость настройки посредством переопределения и создания подклассов. Для этого в конвейере представлены настраиваемые классы tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder и tfr.keras.pipeline.AbstractPipeline для настройки конвейера ранжирования TensorFlow.

Модельстроитель
Шаблонный код, связанный с построением модели Keras , интегрирован в AbstractModelBuilder , который передается в AbstractPipeline и вызывается внутри конвейера для построения модели в рамках стратегии. Это показано на рисунке 1. Методы класса определены в абстрактном базовом классе.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Вы можете напрямую создать подкласс AbstractModelBuilder и перезаписать его конкретными методами настройки, например
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
В то же время вам следует использовать ModelBuilder с входными функциями, преобразованиями предварительной обработки и функциями оценки, указанными в качестве входных данных функции input_creator , preprocessor и scorer в init класса вместо создания подклассов.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Чтобы уменьшить шаблонность создания этих входных данных, предусмотрены функциональные классы tfr.keras.model.InputCreator для input_creator , tfr.keras.model.Preprocessor для preprocessor и tfr.keras.model.Scorer для scorer вместе с конкретными подклассами tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer и tfr.keras.model.GAMScorer . Они должны охватывать большинство распространенных случаев использования.
Обратите внимание, что эти классы функций являются классами Keras, поэтому сериализация не требуется. Создание подклассов — рекомендуемый способ их настройки.
Построитель наборов данных
Класс DatasetBuilder собирает шаблоны, связанные с набором данных. Данные передаются в Pipeline и вызываются для обслуживания наборов данных обучения и проверки, а также для определения сигнатур обслуживания для сохраненных моделей. Как показано на рисунке 1, методы DatasetBuilder определены в базовом классе tfr.keras.pipeline.AbstractDatasetBuilder .
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
В конкретном классе DatasetBuilder вы должны реализовать build_train_datasets , build_valid_datasets и build_signatures .
Также предоставляется конкретный класс, который создает наборы данных из feature_spec :
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
hparams , используемые в DatasetBuilder , указаны в классе данных tfr.keras.pipeline.DatasetHparams .
Трубопровод
Конвейер ранжирования основан на классе tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Также предоставляется конкретный класс конвейера, который обучает модель с помощью различных tf.distribute.strategy , совместимых с model.fit :
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
hparams , используемые в tfr.keras.pipeline.ModelFitPipeline , указаны в классе данных tfr.keras.pipeline.PipelineHparams . Этого класса ModelFitPipeline достаточно для большинства случаев использования TF Ranking. Клиенты могут легко подклассифицировать его для конкретных целей.
Поддержка распределенной стратегии
Пожалуйста, обратитесь к распределенному обучению для подробного ознакомления с распределенными стратегиями, поддерживаемыми TensorFlow. В настоящее время конвейер ранжирования TensorFlow поддерживает tf.distribute.MirroredStrategy (по умолчанию), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy и tf.distribute.ParameterServerStrategy . Зеркальная стратегия совместима с большинством одномашинных систем. Установите для strategy значение None , чтобы не использовать распределенную стратегию.
В целом MirroredStrategy работает для относительно небольших моделей на большинстве устройств с опциями ЦП и ГП. MultiWorkerMirroredStrategy работает для больших моделей, которые не умещаются в одном воркере. ParameterServerStrategy выполняет асинхронное обучение и требует наличия нескольких рабочих процессов. TPUStrategy идеально подходит для больших моделей и больших данных, когда доступны TPU, однако он менее гибок с точки зрения форм тензоров, которые он может обрабатывать.
Часто задаваемые вопросы
Минимальный набор компонентов для использования
RankingPipeline
См. пример кода выше.Что делать, если у меня есть собственная
modelKeras?
Для обучения с помощью стратегийtf.distributemodelдолжна быть построена со всеми обучаемыми переменными, определенными в Strategy.scope(). Итак, оберните свою модель вModelBuilderследующим образом:
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Затем добавьте этот model_builder в конвейер для дальнейшего обучения.