
Tìm hiểu cách tích hợp các phương pháp thực hành AI có trách nhiệm vào quy trình làm việc ML của bạn bằng TensorFlow
TensorFlow cam kết giúp đạt được tiến bộ trong việc phát triển AI có trách nhiệm bằng cách chia sẻ bộ sưu tập tài nguyên và công cụ với cộng đồng ML.

AI có trách nhiệm là gì?
Sự phát triển của AI đang tạo ra những cơ hội mới để giải quyết các vấn đề đầy thách thức trong thế giới thực. Nó cũng đặt ra những câu hỏi mới về cách tốt nhất để xây dựng hệ thống AI mang lại lợi ích cho mọi người.

Các phương pháp hay nhất được đề xuất cho AI
Việc thiết kế hệ thống AI phải tuân theo các phương pháp hay nhất về phát triển phần mềm đồng thời lấy con người làm trung tâm.
cách tiếp cận ML

Công bằng
Khi tác động của AI ngày càng tăng trên các lĩnh vực và xã hội, điều quan trọng là phải hướng tới các hệ thống công bằng và toàn diện cho tất cả mọi người.

Khả năng giải thích
Hiểu và tin tưởng các hệ thống AI là điều quan trọng để đảm bảo chúng hoạt động như dự định

Sự riêng tư
Các mô hình đào tạo về dữ liệu nhạy cảm cần các biện pháp bảo vệ quyền riêng tư

Bảo vệ
Xác định các mối đe dọa tiềm ẩn có thể giúp giữ cho hệ thống AI an toàn và bảo mật
AI có trách nhiệm trong quy trình làm việc ML của bạn
Các phương pháp thực hành AI có trách nhiệm có thể được kết hợp ở mọi bước của quy trình ML. Dưới đây là một số câu hỏi chính cần xem xét ở từng giai đoạn.
Hệ thống ML của tôi dành cho ai?
Cách người dùng thực tế trải nghiệm hệ thống của bạn là điều cần thiết để đánh giá tác động thực sự của các dự đoán, đề xuất và quyết định của hệ thống. Đảm bảo sớm nhận được ý kiến đóng góp từ nhiều nhóm người dùng khác nhau trong quá trình phát triển của bạn.
Tôi có đang sử dụng tập dữ liệu đại diện không?
Dữ liệu của bạn có được lấy mẫu theo cách đại diện cho người dùng của bạn không (ví dụ: sẽ được sử dụng cho mọi lứa tuổi, nhưng bạn chỉ có dữ liệu đào tạo từ người cao tuổi) và cài đặt trong thế giới thực (ví dụ: sẽ được sử dụng quanh năm, nhưng bạn chỉ được đào tạo dữ liệu từ mùa hè)?
Có sự thiên vị trong thế giới thực/con người trong dữ liệu của tôi không?
Những thành kiến cơ bản trong dữ liệu có thể góp phần tạo ra các vòng phản hồi phức tạp nhằm củng cố các khuôn mẫu hiện có.
Tôi nên sử dụng phương pháp nào để đào tạo mô hình của mình?
Sử dụng các phương pháp đào tạo nhằm xây dựng tính công bằng, khả năng diễn giải, quyền riêng tư và bảo mật trong mô hình.
Mô hình của tôi hoạt động như thế nào?
Đánh giá trải nghiệm người dùng trong các tình huống thực tế trên nhiều loại người dùng, trường hợp sử dụng và bối cảnh sử dụng. Trước tiên, hãy thử nghiệm và lặp lại trong dogfood, sau đó tiếp tục thử nghiệm sau khi ra mắt.
Có vòng phản hồi phức tạp không?
Ngay cả khi mọi thứ trong thiết kế hệ thống tổng thể đều được chế tạo cẩn thận, các mô hình dựa trên ML hiếm khi hoạt động hoàn hảo 100% khi áp dụng cho dữ liệu thực, trực tiếp. Khi một sự cố xảy ra trong một sản phẩm đang hoạt động, hãy cân nhắc xem liệu sự cố đó có phù hợp với bất kỳ nhược điểm xã hội hiện tại nào hay không và sự cố đó sẽ bị ảnh hưởng như thế nào bởi các giải pháp ngắn hạn và dài hạn.
Các công cụ AI có trách nhiệm dành cho TensorFlow
Hệ sinh thái TensorFlow có một bộ công cụ và tài nguyên giúp giải quyết một số câu hỏi trên.
Xác định vấn đề
Sử dụng các tài nguyên sau để thiết kế các mô hình có lưu ý đến AI có trách nhiệm.

Tìm hiểu thêm về quá trình phát triển AI và những cân nhắc chính.
Khám phá, thông qua hình ảnh tương tác, các câu hỏi và khái niệm chính trong lĩnh vực AI có trách nhiệm.
Xây dựng và chuẩn bị dữ liệu
Sử dụng các công cụ sau để kiểm tra dữ liệu về những sai lệch tiềm ẩn.
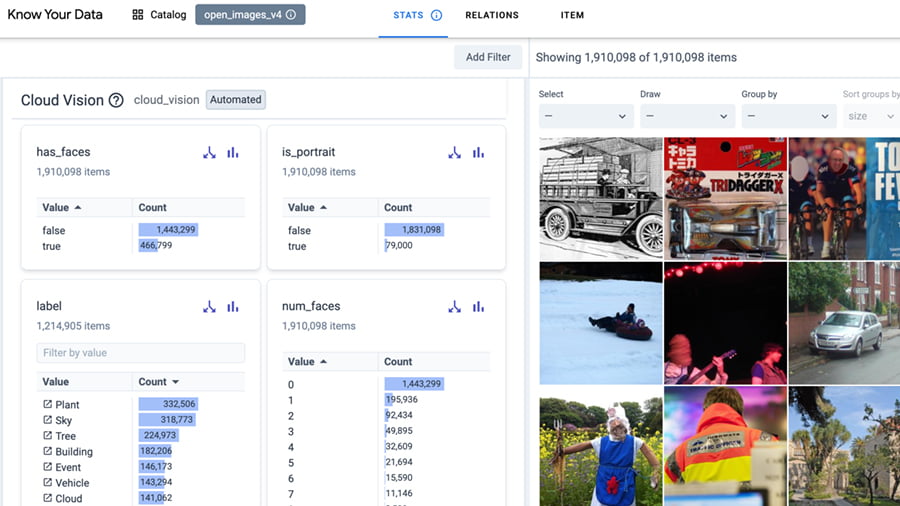
Điều tra tương tác tập dữ liệu của bạn để cải thiện chất lượng dữ liệu và giảm thiểu các vấn đề về tính công bằng và sai lệch.
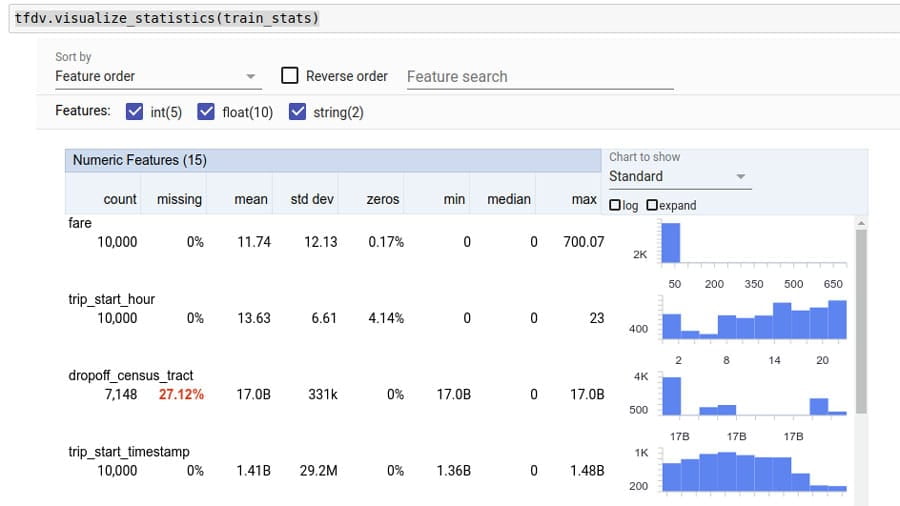
Phân tích và chuyển đổi dữ liệu để phát hiện sự cố và thiết kế các bộ tính năng hiệu quả hơn.


Thang đo tông màu da toàn diện hơn, được cấp phép mở, giúp cho nhu cầu thu thập dữ liệu và xây dựng mô hình của bạn trở nên mạnh mẽ và toàn diện hơn.
Xây dựng và đào tạo mô hình
Sử dụng các công cụ sau để đào tạo mô hình bằng cách sử dụng các kỹ thuật bảo vệ quyền riêng tư, có thể diễn giải, v.v.

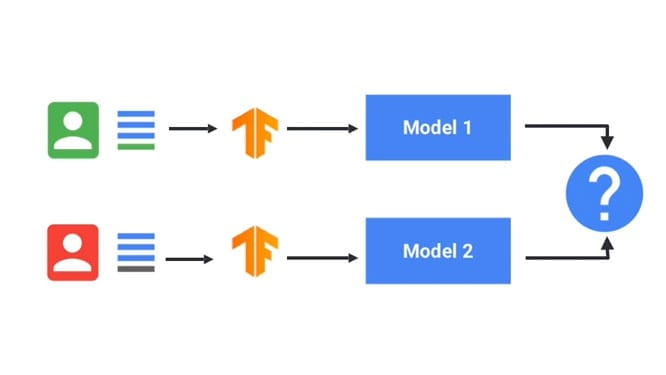
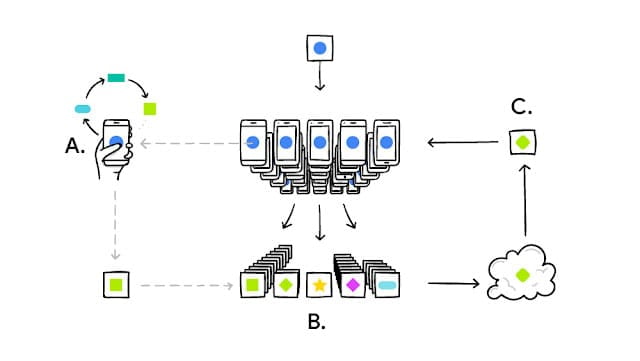
Huấn luyện các mô hình học máy bằng cách sử dụng các kỹ thuật học liên kết.
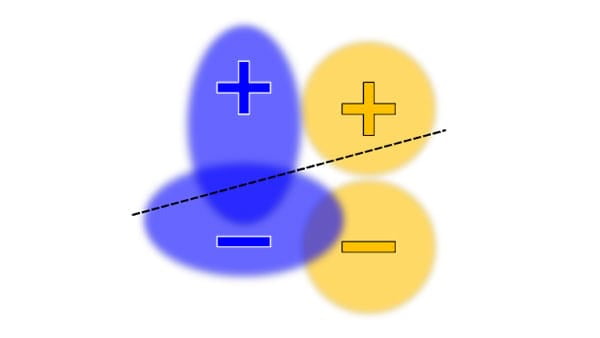
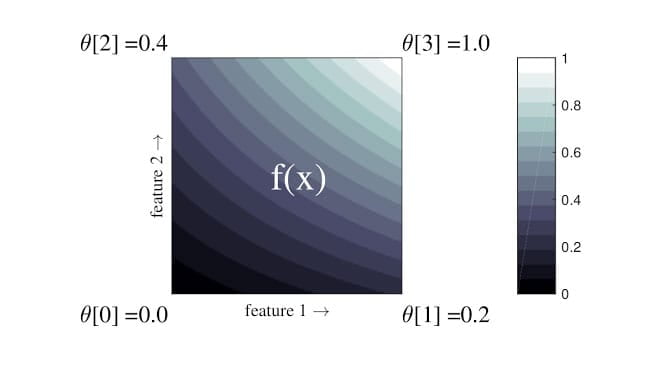
Triển khai các mô hình dựa trên mạng linh hoạt, có kiểm soát và có thể giải thích được.
Đánh giá mô hình
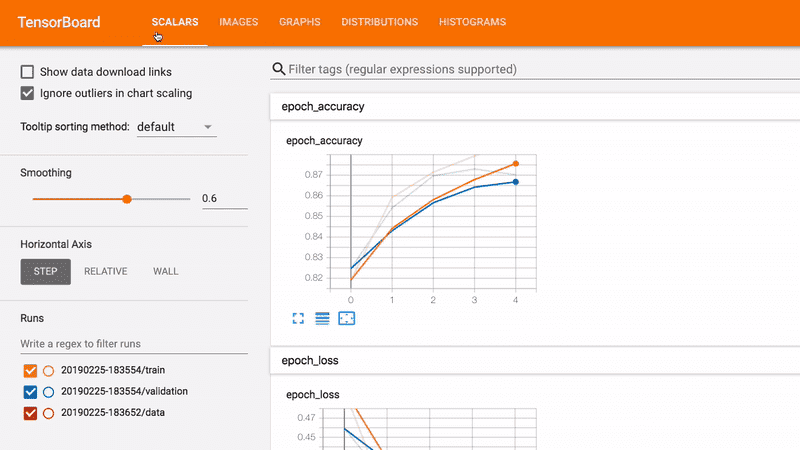
Gỡ lỗi, đánh giá và trực quan hóa hiệu suất của mô hình bằng các công cụ sau.
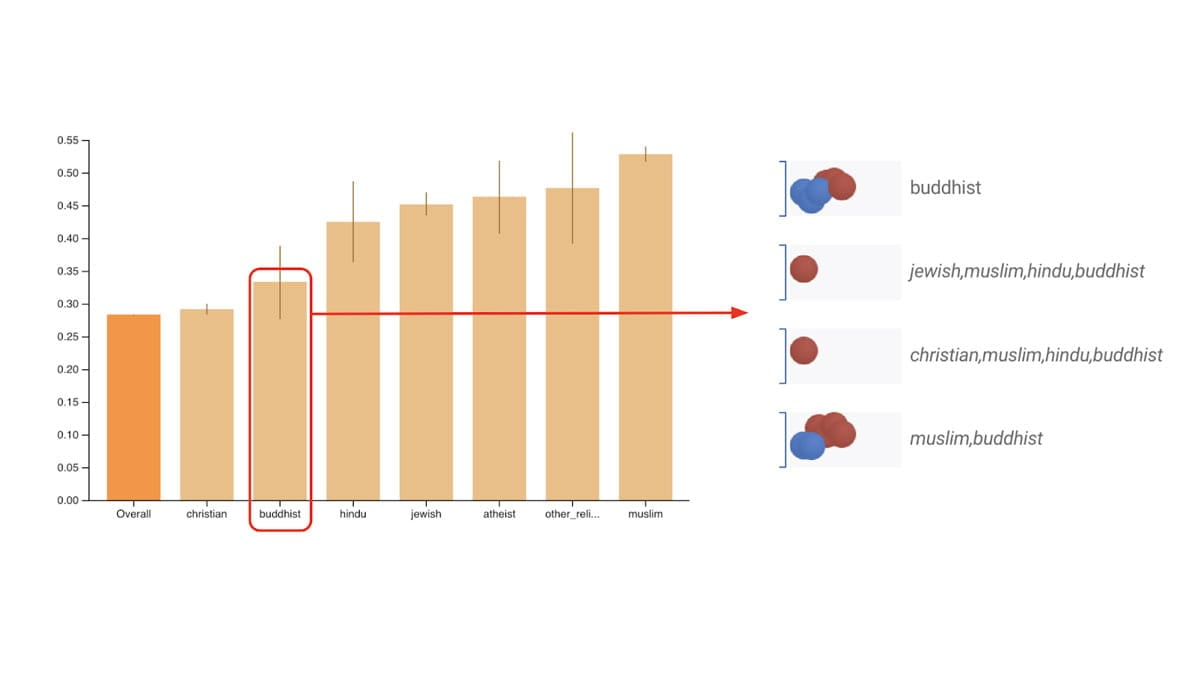
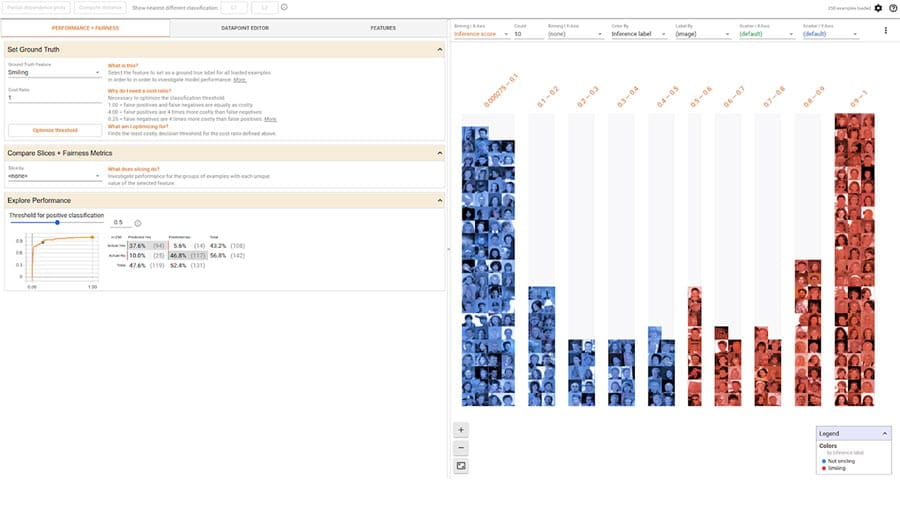
Đánh giá các số liệu công bằng thường được xác định cho các bộ phân loại nhị phân và nhiều lớp.
Đánh giá các mô hình theo cách phân tán và tính toán trên các phần dữ liệu khác nhau.
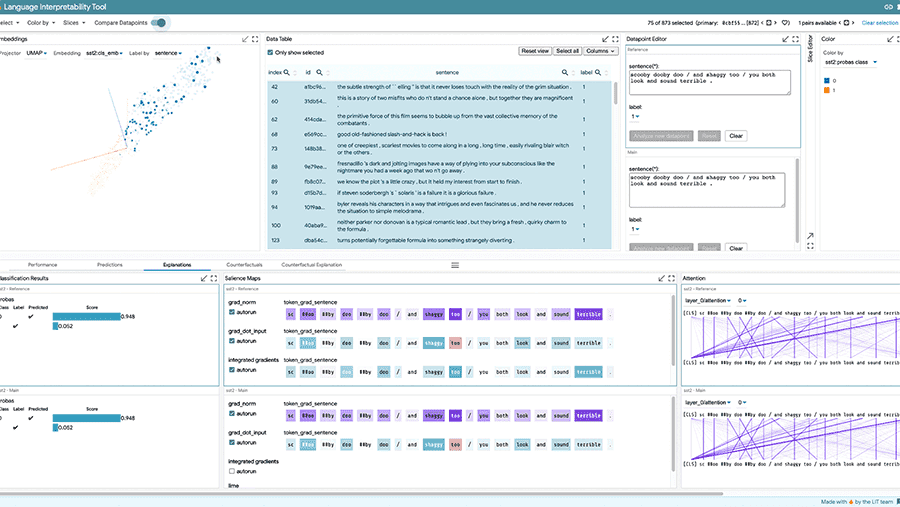
Phát triển các mô hình học máy có thể hiểu được và toàn diện.
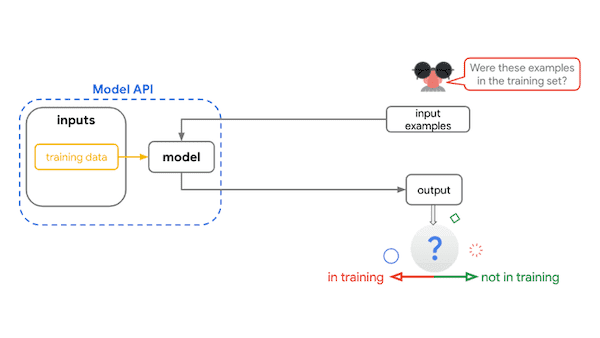
Đánh giá các thuộc tính riêng tư của các mô hình phân loại.
Triển khai và giám sát
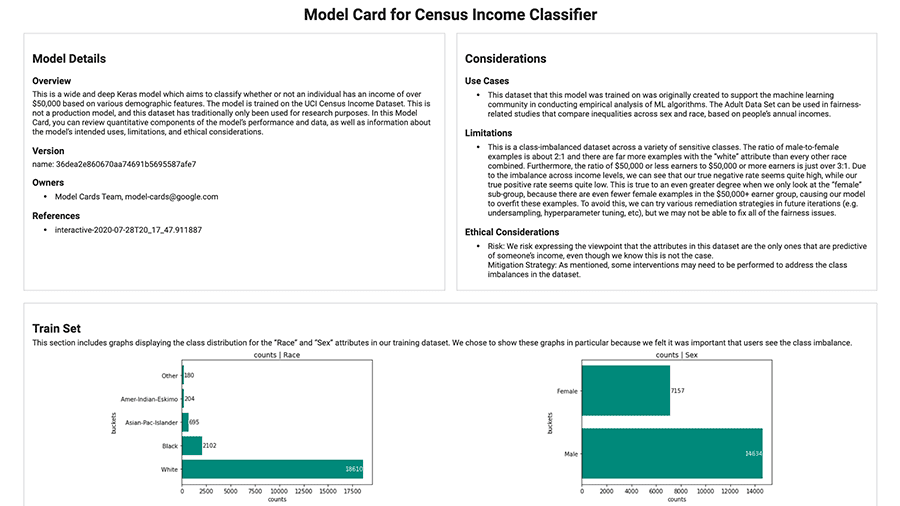
Sử dụng các công cụ sau để theo dõi và trao đổi về bối cảnh và chi tiết của mô hình.
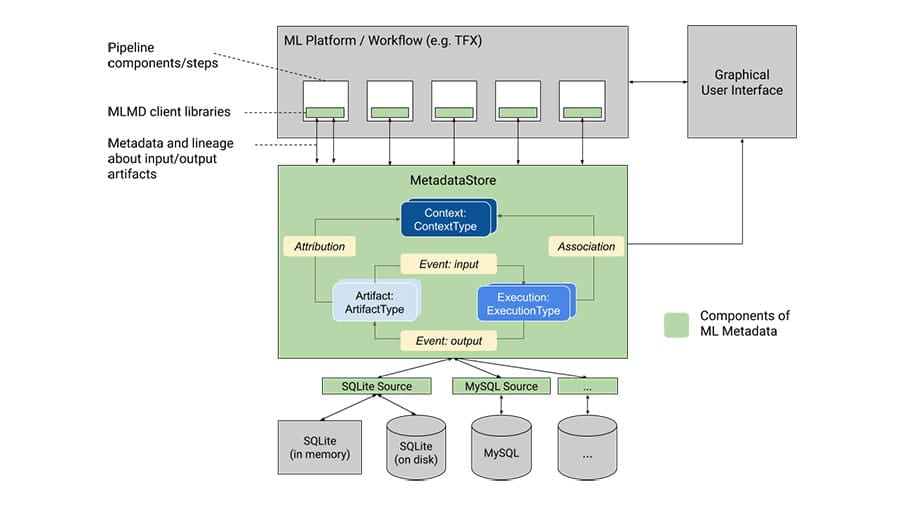
Ghi lại và truy xuất siêu dữ liệu được liên kết với quy trình làm việc của nhà phát triển ML và nhà khoa học dữ liệu.
Nguồn cộng đồng
Tìm hiểu những gì cộng đồng đang làm và khám phá các cách để tham gia.

Giúp các sản phẩm của Google trở nên toàn diện hơn và đại diện cho ngôn ngữ, khu vực và văn hóa của bạn.

Chúng tôi đã yêu cầu những người tham gia sử dụng TensorFlow 2.2 để xây dựng một mô hình hoặc ứng dụng lưu ý đến các nguyên tắc AI có trách nhiệm. Kiểm tra thư viện để xem những người chiến thắng và các dự án tuyệt vời khác.

Giới thiệu một khuôn khổ để suy nghĩ về ML, sự công bằng và quyền riêng tư.
Tìm hiểu cách tích hợp các phương pháp thực hành AI có trách nhiệm vào quy trình làm việc ML của bạn bằng TensorFlow
TensorFlow cam kết giúp đạt được tiến bộ trong việc phát triển AI có trách nhiệm bằng cách chia sẻ bộ sưu tập tài nguyên và công cụ với cộng đồng ML.
AI có trách nhiệm là gì?
Sự phát triển của AI đang tạo ra những cơ hội mới để giải quyết các vấn đề đầy thách thức trong thế giới thực. Nó cũng đặt ra những câu hỏi mới về cách tốt nhất để xây dựng hệ thống AI mang lại lợi ích cho mọi người.
Các phương pháp hay nhất được đề xuất cho AI
Việc thiết kế hệ thống AI phải tuân theo các phương pháp hay nhất về phát triển phần mềm đồng thời lấy con người làm trung tâm.
cách tiếp cận ML
Công bằng
Khi tác động của AI ngày càng tăng trên các lĩnh vực và xã hội, điều quan trọng là phải hướng tới các hệ thống công bằng và toàn diện cho tất cả mọi người.
Khả năng giải thích
Hiểu và tin tưởng các hệ thống AI là điều quan trọng để đảm bảo chúng hoạt động như dự định
Sự riêng tư
Các mô hình đào tạo về dữ liệu nhạy cảm cần các biện pháp bảo vệ quyền riêng tư
Bảo vệ
Xác định các mối đe dọa tiềm ẩn có thể giúp giữ cho hệ thống AI an toàn và bảo mật
AI có trách nhiệm trong quy trình làm việc ML của bạn
Các phương pháp thực hành AI có trách nhiệm có thể được kết hợp ở mọi bước của quy trình ML. Dưới đây là một số câu hỏi chính cần xem xét ở từng giai đoạn.
Hệ thống ML của tôi dành cho ai?
Cách người dùng thực tế trải nghiệm hệ thống của bạn là điều cần thiết để đánh giá tác động thực sự của các dự đoán, đề xuất và quyết định của hệ thống. Đảm bảo sớm nhận được ý kiến đóng góp từ nhiều nhóm người dùng khác nhau trong quá trình phát triển của bạn.
Tôi có đang sử dụng tập dữ liệu đại diện không?
Dữ liệu của bạn có được lấy mẫu theo cách đại diện cho người dùng của bạn không (ví dụ: sẽ được sử dụng cho mọi lứa tuổi, nhưng bạn chỉ có dữ liệu đào tạo từ người cao tuổi) và cài đặt trong thế giới thực (ví dụ: sẽ được sử dụng quanh năm, nhưng bạn chỉ được đào tạo dữ liệu từ mùa hè)?
Có sự thiên vị trong thế giới thực/con người trong dữ liệu của tôi không?
Những thành kiến cơ bản trong dữ liệu có thể góp phần tạo ra các vòng phản hồi phức tạp nhằm củng cố các khuôn mẫu hiện có.
Tôi nên sử dụng phương pháp nào để đào tạo mô hình của mình?
Sử dụng các phương pháp đào tạo nhằm xây dựng tính công bằng, khả năng diễn giải, quyền riêng tư và bảo mật trong mô hình.
Mô hình của tôi hoạt động như thế nào?
Đánh giá trải nghiệm người dùng trong các tình huống thực tế trên nhiều loại người dùng, trường hợp sử dụng và bối cảnh sử dụng. Trước tiên, hãy thử nghiệm và lặp lại trong dogfood, sau đó tiếp tục thử nghiệm sau khi ra mắt.
Có vòng phản hồi phức tạp không?
Ngay cả khi mọi thứ trong thiết kế hệ thống tổng thể đều được chế tạo cẩn thận, các mô hình dựa trên ML hiếm khi hoạt động hoàn hảo 100% khi áp dụng cho dữ liệu thực, trực tiếp. Khi một sự cố xảy ra trong một sản phẩm đang hoạt động, hãy cân nhắc xem liệu sự cố đó có phù hợp với bất kỳ nhược điểm xã hội hiện tại nào hay không và sự cố đó sẽ bị ảnh hưởng như thế nào bởi các giải pháp ngắn hạn và dài hạn.
Các công cụ AI có trách nhiệm dành cho TensorFlow
Hệ sinh thái TensorFlow có một bộ công cụ và tài nguyên giúp giải quyết một số câu hỏi trên.
Xác định vấn đề
Sử dụng các tài nguyên sau để thiết kế các mô hình có lưu ý đến AI có trách nhiệm.
Tìm hiểu thêm về quá trình phát triển AI và những cân nhắc chính.
Khám phá, thông qua hình ảnh tương tác, các câu hỏi và khái niệm chính trong lĩnh vực AI có trách nhiệm.
Xây dựng và chuẩn bị dữ liệu
Sử dụng các công cụ sau để kiểm tra dữ liệu về những sai lệch tiềm ẩn.
Điều tra tương tác tập dữ liệu của bạn để cải thiện chất lượng dữ liệu và giảm thiểu các vấn đề về tính công bằng và sai lệch.
Phân tích và chuyển đổi dữ liệu để phát hiện sự cố và thiết kế các bộ tính năng hiệu quả hơn.
Thang đo tông màu da toàn diện hơn, được cấp phép mở, giúp cho nhu cầu thu thập dữ liệu và xây dựng mô hình của bạn trở nên mạnh mẽ và toàn diện hơn.
Xây dựng và đào tạo mô hình
Sử dụng các công cụ sau để đào tạo mô hình bằng cách sử dụng các kỹ thuật bảo vệ quyền riêng tư, có thể diễn giải, v.v.
Huấn luyện các mô hình học máy bằng cách sử dụng các kỹ thuật học liên kết.
Triển khai các mô hình dựa trên mạng linh hoạt, có kiểm soát và có thể giải thích được.
Đánh giá mô hình
Gỡ lỗi, đánh giá và trực quan hóa hiệu suất của mô hình bằng các công cụ sau.
Đánh giá các số liệu công bằng thường được xác định cho các bộ phân loại nhị phân và nhiều lớp.
Đánh giá các mô hình theo cách phân tán và tính toán trên các phần dữ liệu khác nhau.
Phát triển các mô hình học máy có thể hiểu được và toàn diện.
Đánh giá các thuộc tính riêng tư của các mô hình phân loại.
Triển khai và giám sát
Sử dụng các công cụ sau để theo dõi và trao đổi về bối cảnh và chi tiết của mô hình.
Ghi lại và truy xuất siêu dữ liệu được liên kết với quy trình làm việc của nhà phát triển ML và nhà khoa học dữ liệu.
Nguồn cộng đồng
Tìm hiểu những gì cộng đồng đang làm và khám phá các cách để tham gia.
Giúp các sản phẩm của Google trở nên toàn diện hơn và đại diện cho ngôn ngữ, khu vực và văn hóa của bạn.
Chúng tôi đã yêu cầu những người tham gia sử dụng TensorFlow 2.2 để xây dựng một mô hình hoặc ứng dụng lưu ý đến các nguyên tắc AI có trách nhiệm. Kiểm tra thư viện để xem những người chiến thắng và các dự án tuyệt vời khác.
Giới thiệu một khuôn khổ để suy nghĩ về ML, sự công bằng và quyền riêng tư.