
En los últimos años se ha producido un aumento de las nuevas capas de gráficos diferenciables que se pueden insertar en las arquitecturas de redes neuronales. Desde transformadores espaciales hasta renderizadores de gráficos diferenciables, estas nuevas capas aprovechan el conocimiento adquirido durante años de investigación de gráficos y visión por computadora para construir arquitecturas de red nuevas y más eficientes. El modelado explícito de restricciones y antecedentes geométricos en redes neuronales abre la puerta a arquitecturas que se pueden entrenar de manera sólida, eficiente y, lo que es más importante, de manera autosupervisada.
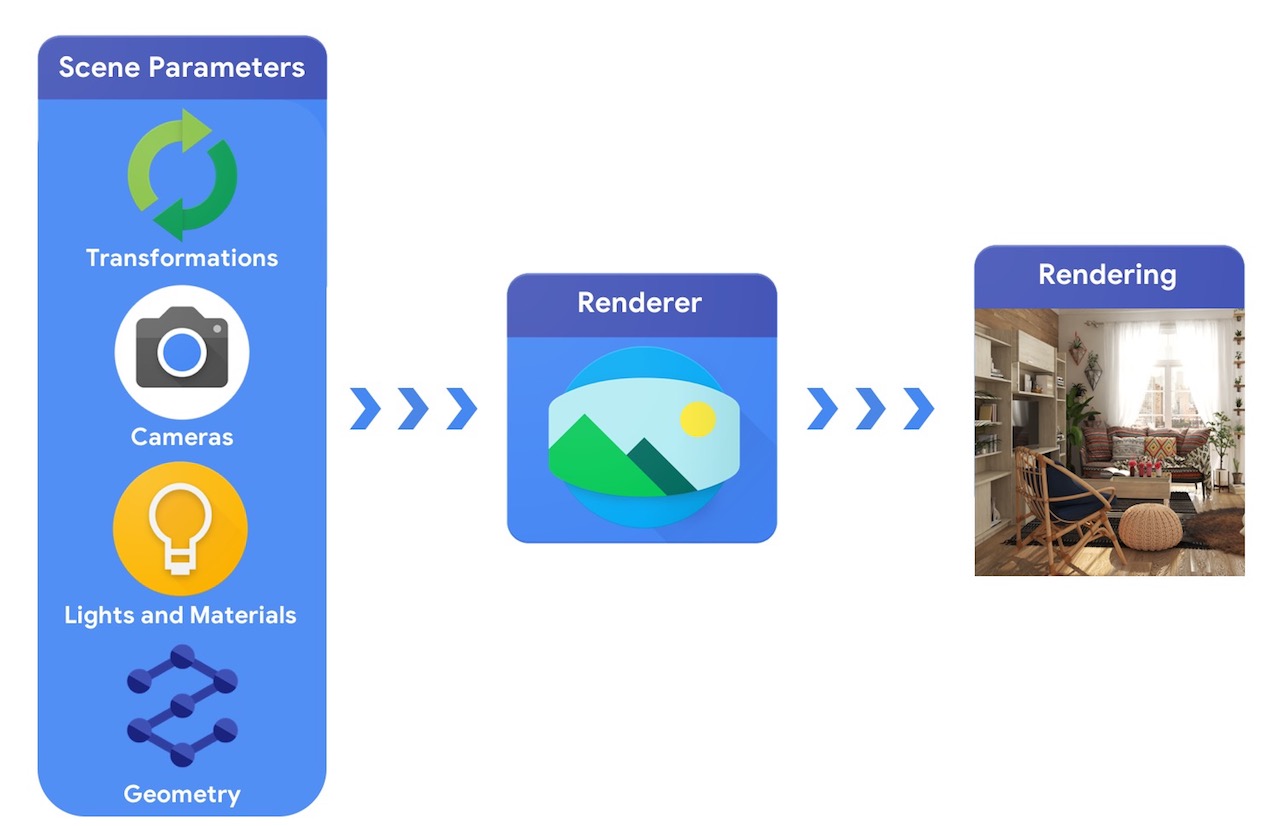
A un alto nivel, una tubería de gráficos por computadora requiere una representación de objetos 3D y su posicionamiento absoluto en la escena, una descripción del material del que están hechos, luces y una cámara. A continuación, un renderizador interpreta esta descripción de la escena para generar una representación sintética.
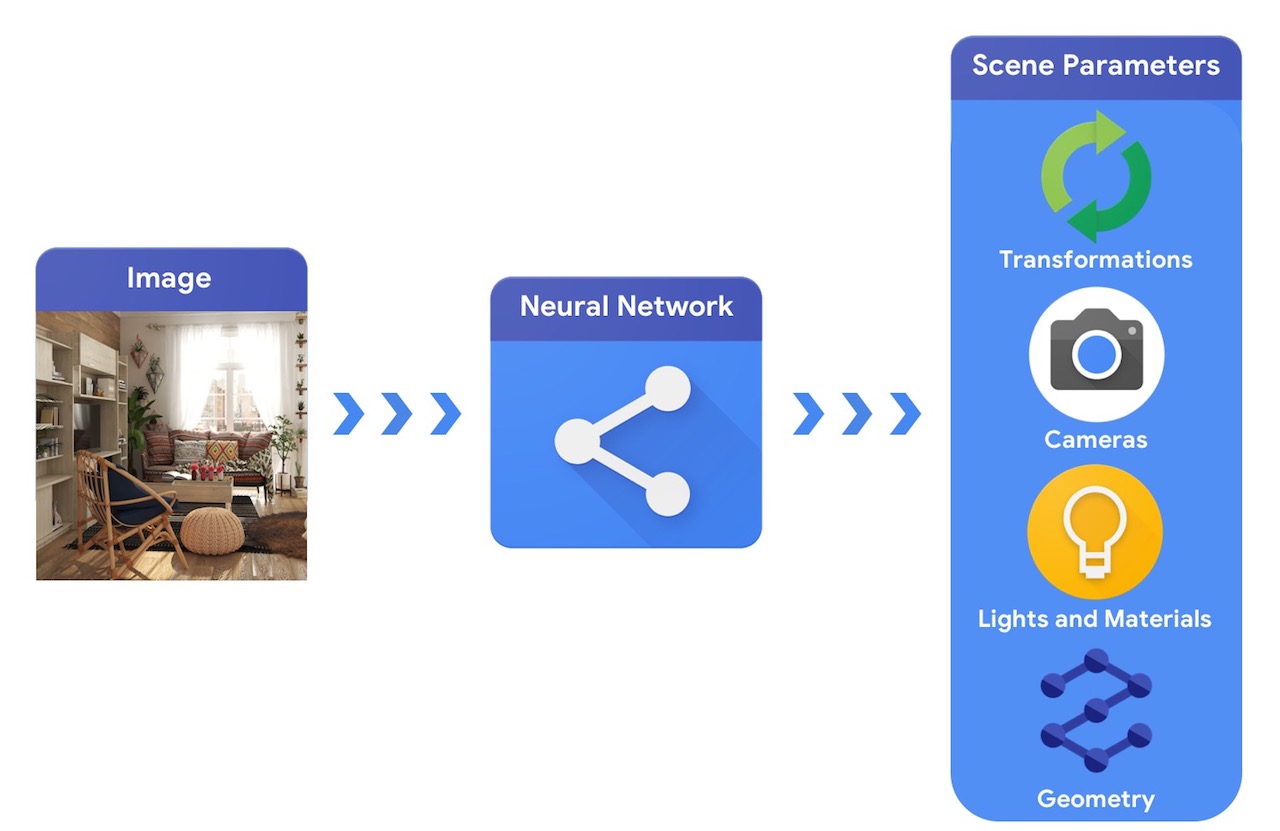
En comparación, un sistema de visión por computadora partiría de una imagen e intentaría inferir los parámetros de la escena. Esto permite predecir qué objetos se encuentran en la escena, de qué materiales están hechos y la posición y orientación tridimensional.
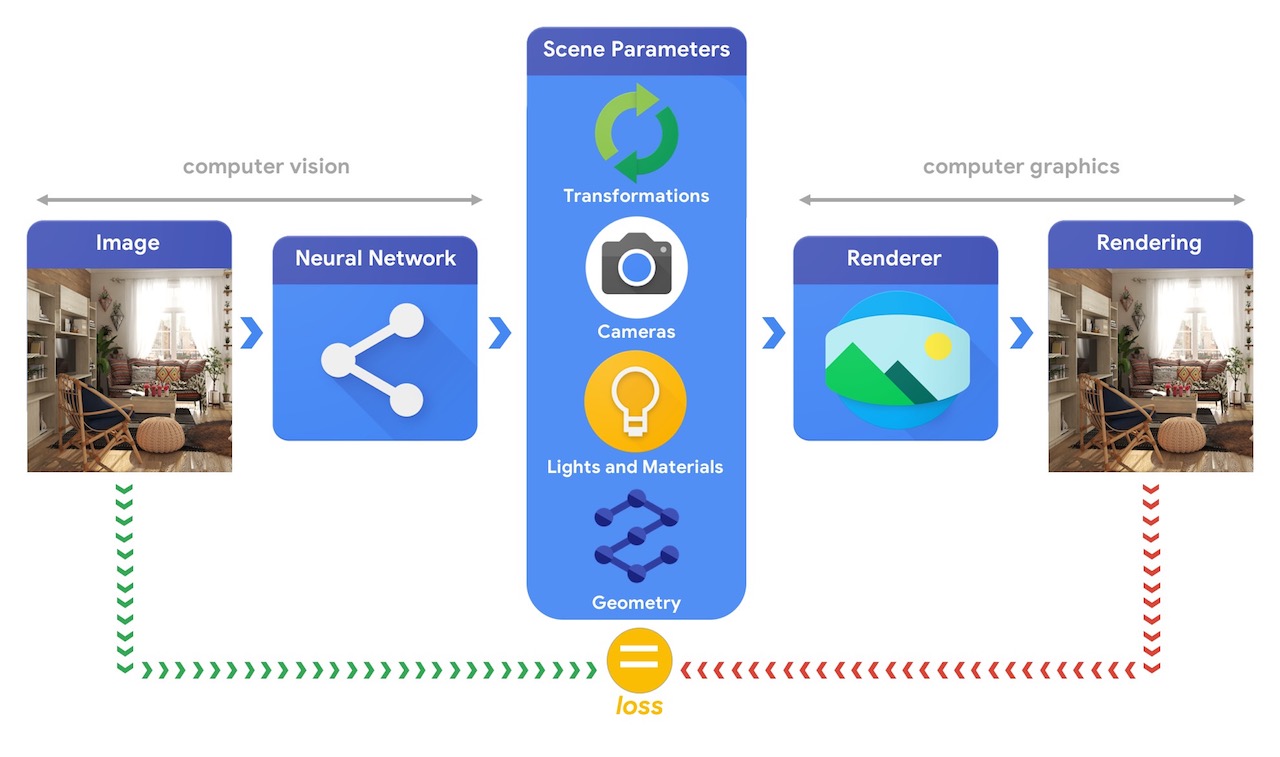
La formación de sistemas de aprendizaje automático capaces de resolver estas complejas tareas de visión 3D suele requerir grandes cantidades de datos. Dado que el etiquetado de datos es un proceso costoso y complejo, es importante contar con mecanismos para diseñar modelos de aprendizaje automático que puedan comprender el mundo tridimensional mientras se entrenan sin mucha supervisión. La combinación de técnicas de visión por computadora y gráficos por computadora brinda una oportunidad única para aprovechar las grandes cantidades de datos no etiquetados fácilmente disponibles. Como se ilustra en la imagen a continuación, esto se puede lograr, por ejemplo, mediante el análisis por síntesis en el que el sistema de visión extrae los parámetros de la escena y el sistema de gráficos genera una imagen basada en ellos. Si la representación coincide con la imagen original, el sistema de visión ha extraído con precisión los parámetros de la escena. En esta configuración, la visión por computadora y los gráficos por computadora van de la mano, formando un solo sistema de aprendizaje automático similar a un codificador automático, que se puede entrenar de manera autosupervisada.
Tensorflow Graphics se está desarrollando para ayudar a abordar este tipo de desafíos y, para hacerlo, proporciona un conjunto de gráficos diferenciables y capas geométricas (por ejemplo, cámaras, modelos de reflectancia, transformaciones espaciales, convoluciones de malla) y funcionalidades de visor 3D (por ejemplo, 3D TensorBoard) que se puede usar para entrenar y depurar sus modelos de aprendizaje automático de elección.