
ในช่วงไม่กี่ปีที่ผ่านมาได้เห็นการเพิ่มขึ้นของเลเยอร์กราฟิกแบบสร้างความแตกต่างได้ ซึ่งสามารถแทรกลงในสถาปัตยกรรมเครือข่ายประสาทเทียมได้ ตั้งแต่ทรานสฟอร์มเมอร์เชิงพื้นที่ไปจนถึงเรนเดอร์กราฟิกแบบแยกส่วน เลเยอร์ใหม่เหล่านี้ใช้ประโยชน์จากความรู้ที่ได้รับจากการวิจัยคอมพิวเตอร์วิทัศน์และกราฟิกเป็นเวลาหลายปี เพื่อสร้างสถาปัตยกรรมเครือข่ายใหม่และมีประสิทธิภาพมากขึ้น การสร้างแบบจำลองทางเรขาคณิตล่วงหน้าและข้อจำกัดในโครงข่ายประสาทเทียมเป็นการเปิดประตูสู่สถาปัตยกรรมที่สามารถฝึกฝนได้อย่างแข็งแกร่ง มีประสิทธิภาพ และที่สำคัญกว่านั้นในรูปแบบการควบคุมตนเอง
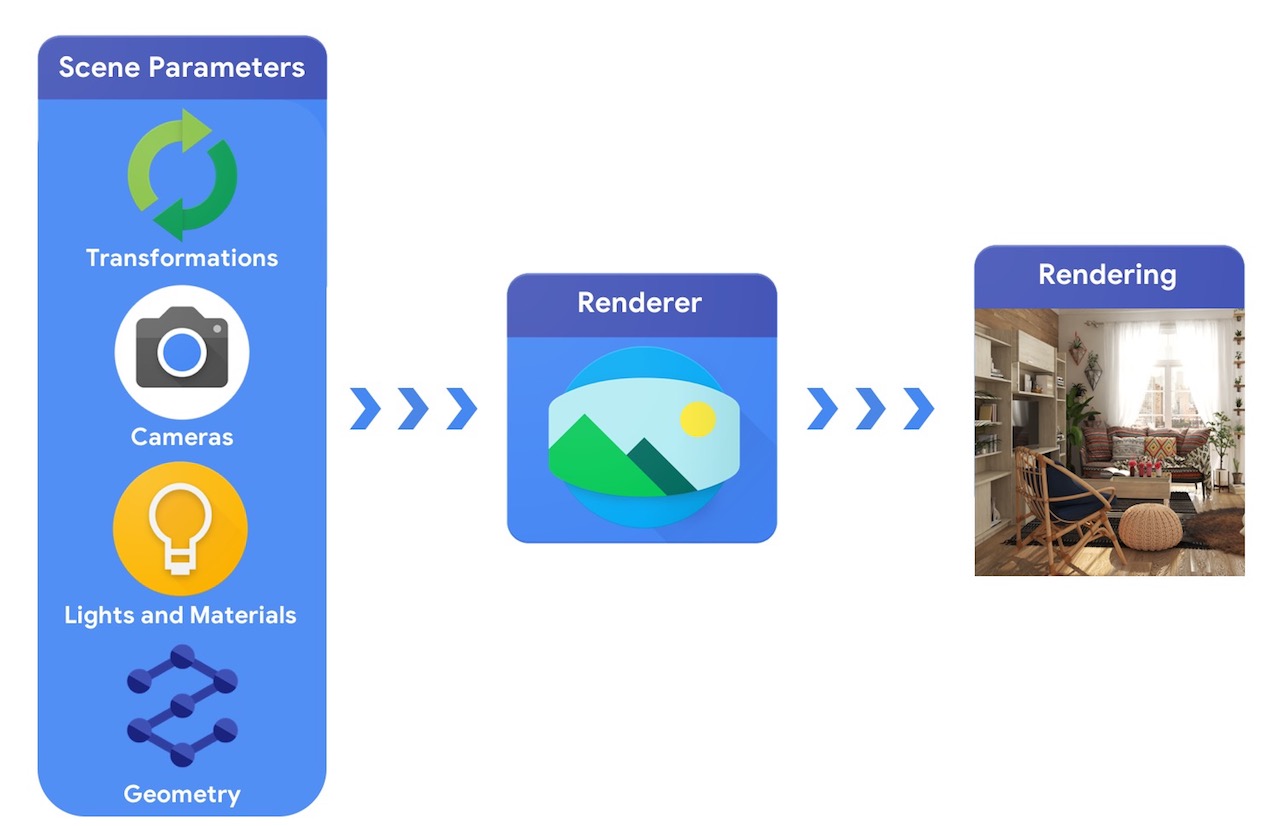
ในระดับสูง ไปป์ไลน์คอมพิวเตอร์กราฟิกต้องการการแสดงวัตถุ 3 มิติและตำแหน่งที่แน่นอนของวัตถุในฉาก คำอธิบายเกี่ยวกับวัสดุที่ทำขึ้น แสงและกล้อง คำอธิบายฉากนี้จะถูกตีความโดยตัวแสดงเพื่อสร้างการเรนเดอร์แบบสังเคราะห์
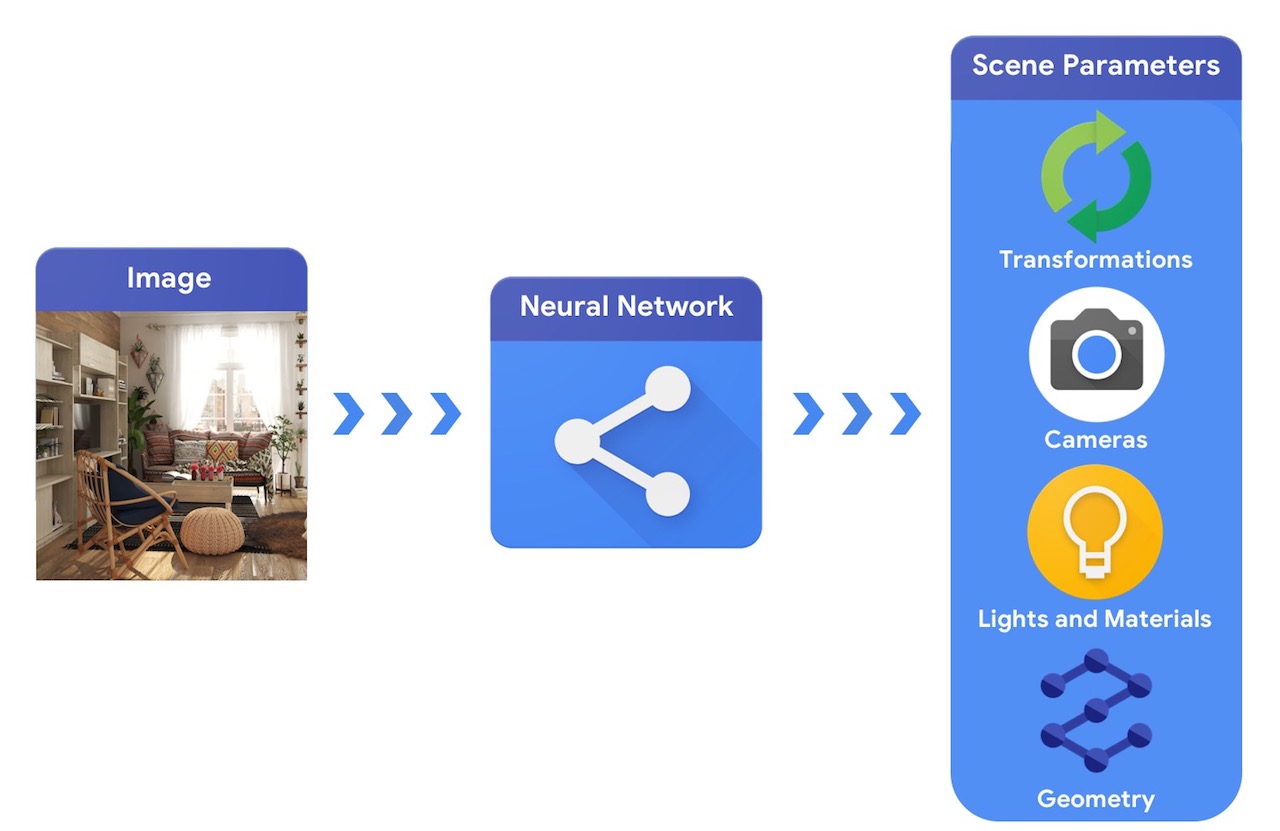
ในการเปรียบเทียบ ระบบคอมพิวเตอร์วิทัศน์จะเริ่มจากภาพและพยายามอนุมานพารามิเตอร์ของฉาก ซึ่งช่วยให้ทำนายได้ว่าวัตถุใดอยู่ในฉาก วัสดุใดบ้าง และตำแหน่งและการวางแนวสามมิติ
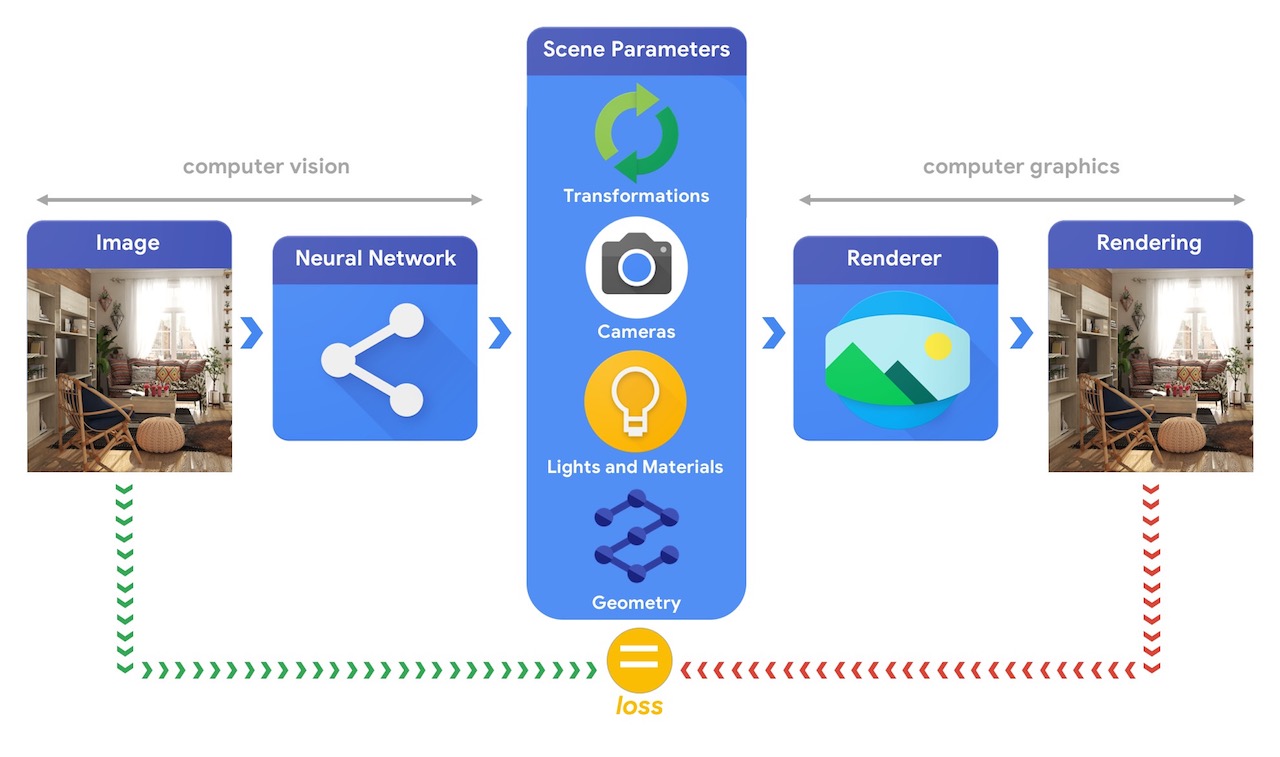
การฝึกอบรมระบบแมชชีนเลิร์นนิงที่สามารถแก้ไขงานด้านการมองเห็น 3 มิติที่ซับซ้อนเหล่านี้ได้ ส่วนใหญ่มักต้องการข้อมูลจำนวนมาก เนื่องจากข้อมูลการติดฉลากเป็นกระบวนการที่มีราคาแพงและซับซ้อน จึงเป็นสิ่งสำคัญที่จะต้องมีกลไกในการออกแบบโมเดลการเรียนรู้ของเครื่องที่สามารถเข้าใจโลกสามมิติในขณะที่ได้รับการฝึกอบรมโดยไม่ต้องมีการควบคุมดูแลมากนัก การผสมผสานเทคนิคคอมพิวเตอร์วิทัศน์และคอมพิวเตอร์กราฟิกทำให้มีโอกาสพิเศษในการใช้ประโยชน์จากข้อมูลที่ไม่มีป้ายกำกับจำนวนมากที่พร้อมใช้งาน ดังที่แสดงในภาพด้านล่าง ตัวอย่างเช่น สามารถทำได้โดยใช้การวิเคราะห์โดยการสังเคราะห์ โดยที่ระบบการมองเห็นจะแยกพารามิเตอร์ของฉาก และระบบกราฟิกจะแสดงภาพกลับโดยอิงจากพารามิเตอร์เหล่านั้น หากการเรนเดอร์ตรงกับภาพต้นฉบับ ระบบการมองเห็นได้แยกพารามิเตอร์ฉากออกมาอย่างแม่นยำ ในการตั้งค่านี้ คอมพิวเตอร์วิทัศน์และคอมพิวเตอร์กราฟิกทำงานร่วมกัน ทำให้เกิดระบบการเรียนรู้ของเครื่องเดียวที่คล้ายกับตัวเข้ารหัสอัตโนมัติ ซึ่งสามารถฝึกในลักษณะที่ควบคุมตนเองได้
กราฟิก Tensorflow ได้รับการพัฒนาเพื่อช่วยจัดการกับความท้าทายประเภทนี้ และเพื่อทำเช่นนั้น กราฟิกดังกล่าวจะมีชุดของเลเยอร์กราฟิกและเรขาคณิตที่ต่างกันได้ (เช่น กล้อง แบบจำลองการสะท้อนแสง การแปลงเชิงพื้นที่ การบิดแบบตาข่าย) และฟังก์ชัน 3D viewer (เช่น 3D TensorBoard) ที่ สามารถใช้ในการฝึกอบรมและดีบักโมเดลการเรียนรู้ของเครื่องที่คุณเลือก