
شهدت السنوات القليلة الماضية ارتفاعًا في طبقات الرسومات الجديدة القابلة للتفاضل والتي يمكن إدراجها في بنيات الشبكات العصبية. من المحولات المكانية إلى عارضين الرسومات التفاضلية ، تستفيد هذه الطبقات الجديدة من المعرفة المكتسبة على مدار سنوات من رؤية الكمبيوتر وأبحاث الرسومات لبناء هياكل شبكات جديدة وأكثر كفاءة. تفتح النمذجة الهندسية المسبقة والقيود في الشبكات العصبية الباب أمام البنى التي يمكن تدريبها بقوة وكفاءة والأهم من ذلك ، بطريقة تخضع للإشراف الذاتي.
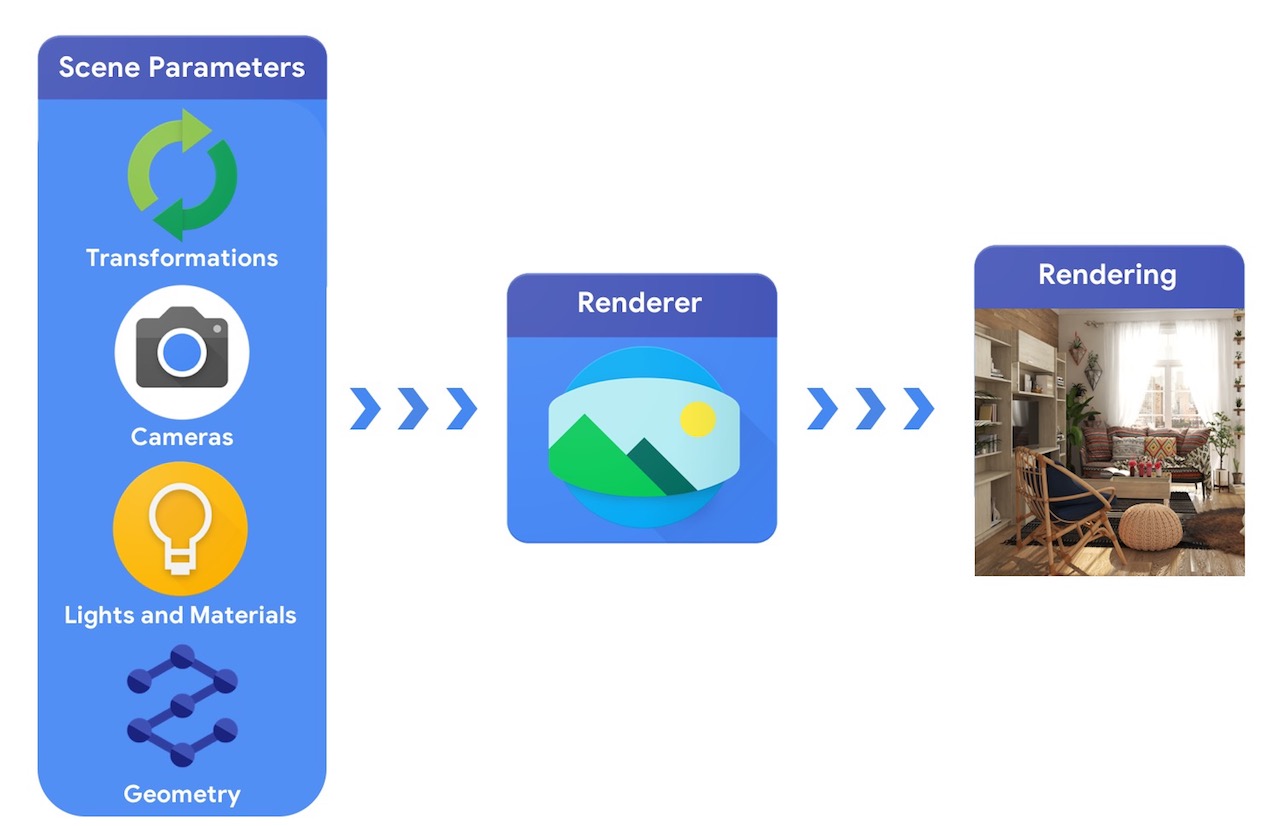
على مستوى عالٍ ، يتطلب خط أنابيب رسومات الكمبيوتر تمثيلًا للأشياء ثلاثية الأبعاد وتحديد موضعها المطلق في المشهد ووصفًا للمادة المكونة منها والأضواء والكاميرا. يتم بعد ذلك تفسير وصف المشهد هذا بواسطة العارض لإنشاء عرض تركيبي.
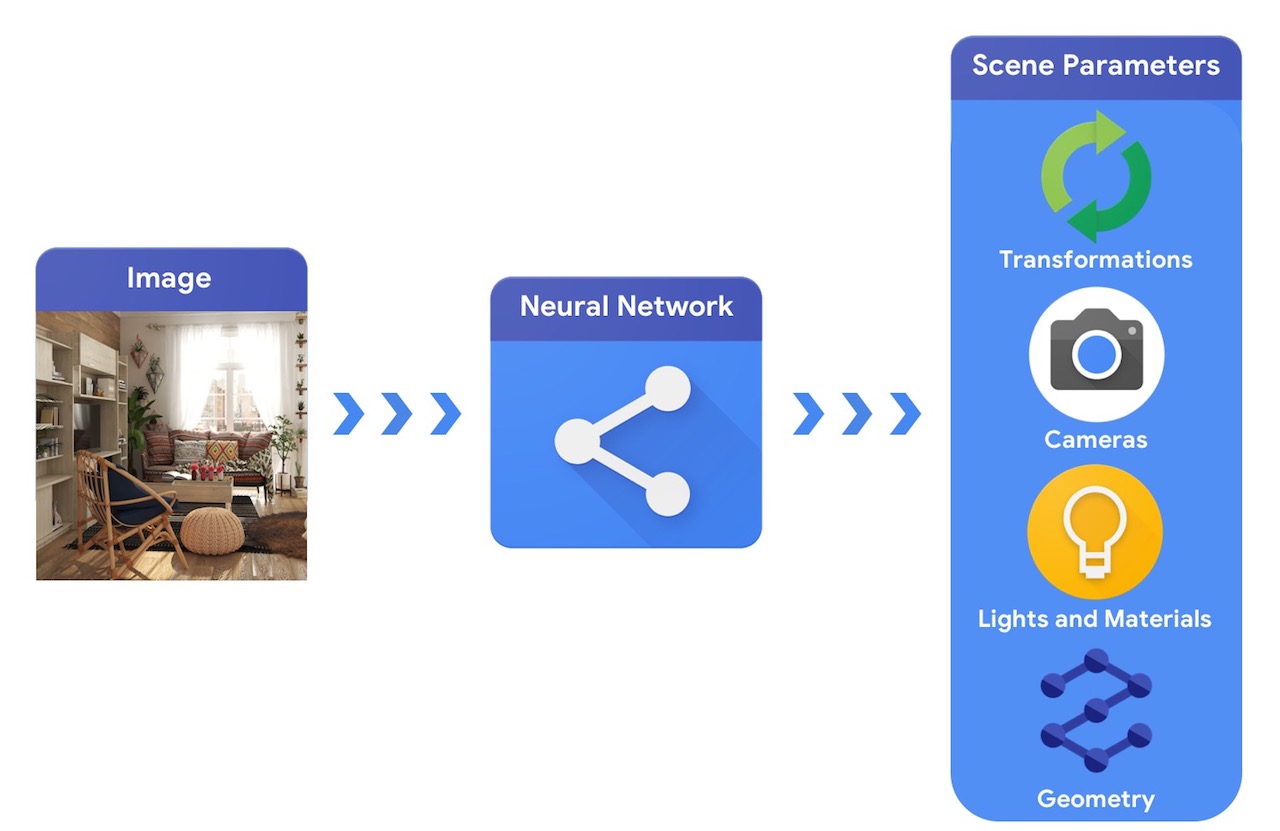
وبالمقارنة ، فإن نظام رؤية الكمبيوتر سيبدأ من صورة ويحاول استنتاج معلمات المشهد. يسمح هذا بالتنبؤ بالأشياء الموجودة في المشهد ، والمواد التي تتكون منها ، والموضع والاتجاه ثلاثي الأبعاد.
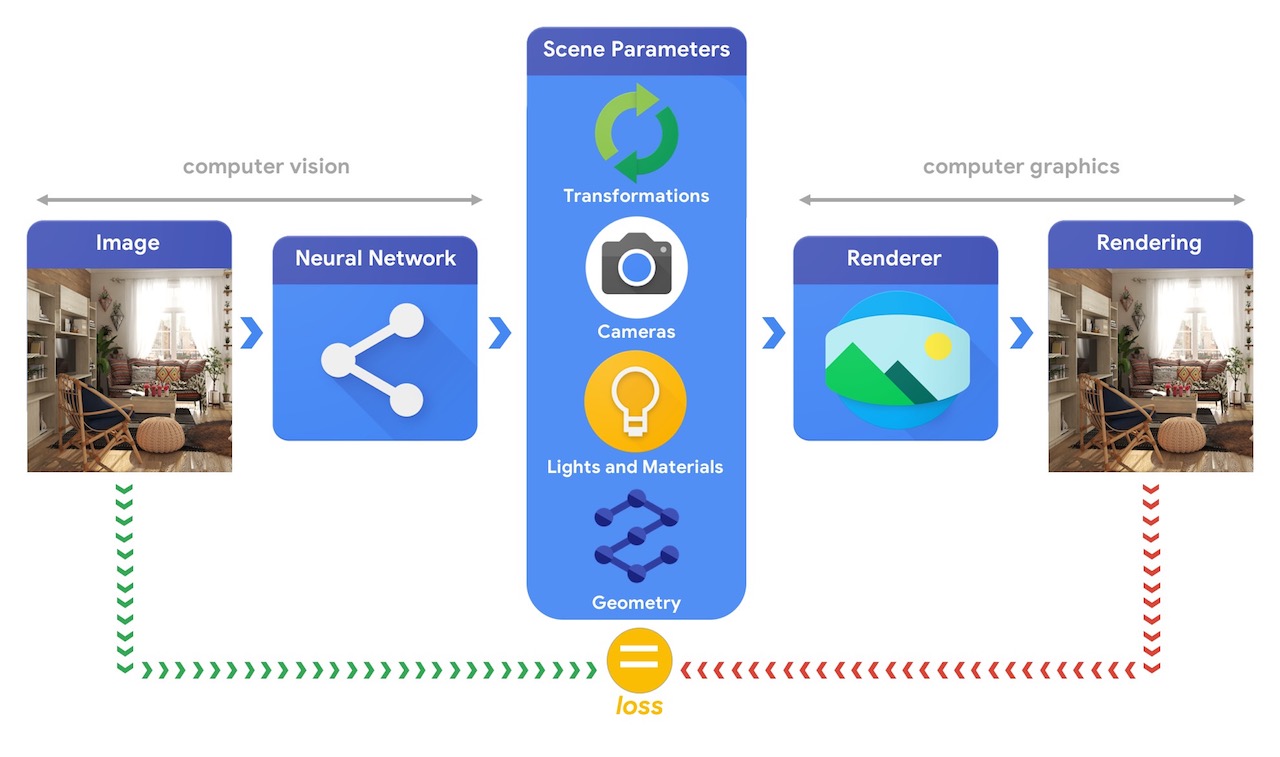
غالبًا ما يتطلب تدريب أنظمة التعلم الآلي القادرة على حل مهام الرؤية ثلاثية الأبعاد المعقدة كميات كبيرة من البيانات. نظرًا لأن تصنيف البيانات عملية مكلفة ومعقدة ، فمن المهم أن يكون لديك آليات لتصميم نماذج التعلم الآلي التي يمكنها فهم العالم ثلاثي الأبعاد أثناء التدريب دون الكثير من الإشراف. يوفر الجمع بين رؤية الكمبيوتر وتقنيات رسومات الكمبيوتر فرصة فريدة للاستفادة من الكميات الهائلة من البيانات غير الموسومة والمتاحة بسهولة. كما هو موضح في الصورة أدناه ، يمكن تحقيق ذلك ، على سبيل المثال ، باستخدام التحليل عن طريق التوليف حيث يستخرج نظام الرؤية معلمات المشهد ويعيد نظام الرسوم صورة بناءً عليها. إذا تطابق العرض مع الصورة الأصلية ، فإن نظام الرؤية قد استخرج بدقة معلمات المشهد. في هذا الإعداد ، تسير رؤية الكمبيوتر ورسومات الكمبيوتر جنبًا إلى جنب ، مما يشكل نظامًا واحدًا للتعلم الآلي مشابهًا لجهاز التشفير التلقائي ، والذي يمكن تدريبه بطريقة ذاتية الإشراف.
يتم تطوير Tensorflow Graphics للمساعدة في معالجة هذه الأنواع من التحديات وللقيام بذلك ، فهي توفر مجموعة من طبقات الرسومات والهندسة المتمايزة (مثل الكاميرات ونماذج الانعكاس والتحولات المكانية والتلافيف الشبكية) ووظائف العارض ثلاثي الأبعاد (مثل 3D TensorBoard) يمكن استخدامها لتدريب نماذج التعلم الآلي التي تختارها وتصحيحها.