
В последние несколько лет наблюдается рост новых дифференцируемых графических слоев, которые можно вставлять в архитектуры нейронных сетей. Эти новые слои, от пространственных преобразователей до дифференцируемых графических рендереров, используют знания, полученные за годы исследований компьютерного зрения и графики, для создания новых и более эффективных сетевых архитектур. Явное моделирование геометрических априорных значений и ограничений в нейронных сетях открывает двери для архитектур, которые можно обучать надежно, эффективно и, что более важно, с самоконтролем.
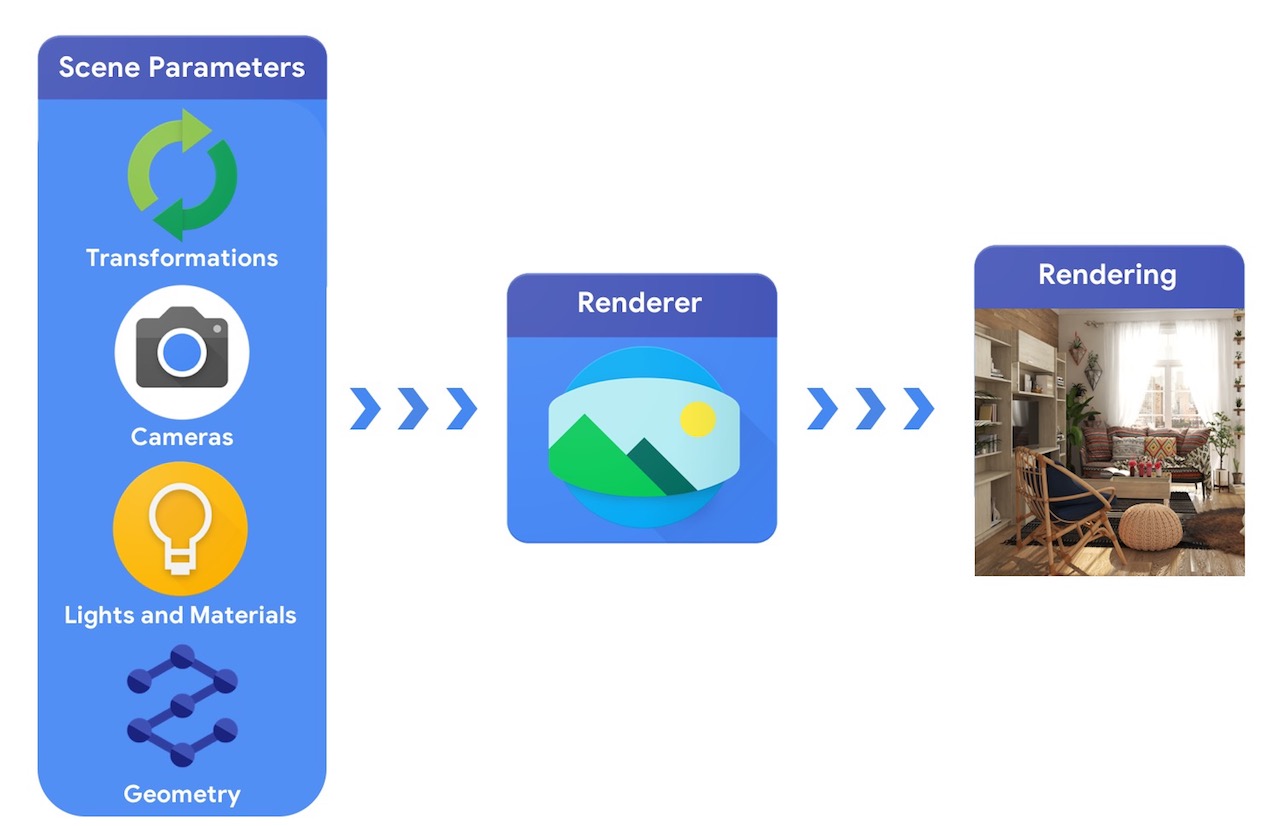
На высоком уровне конвейер компьютерной графики требует представления 3D-объектов и их абсолютного позиционирования в сцене, описания материала, из которого они сделаны, источников света и камеры. Затем это описание сцены интерпретируется модулем визуализации для создания синтетического рендеринга.
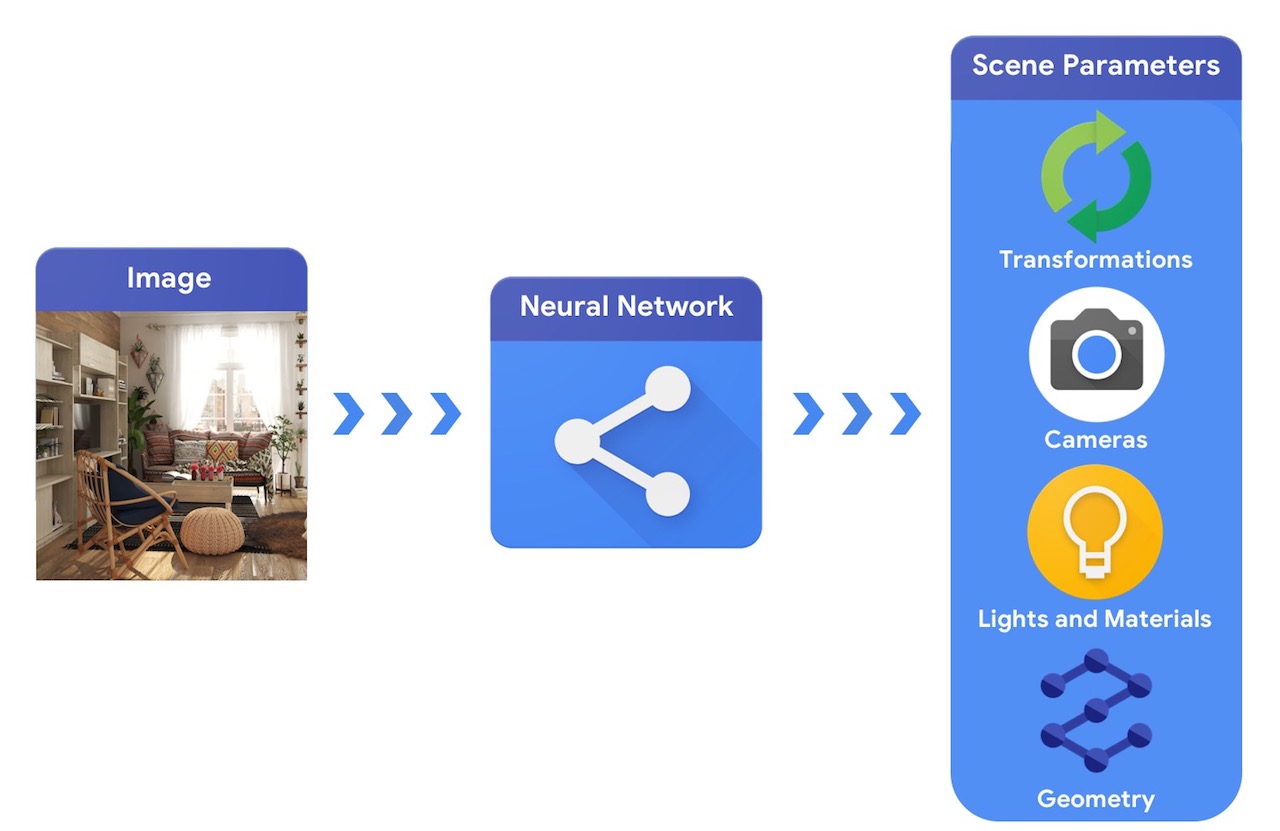
Для сравнения, система компьютерного зрения начнет с изображения и попытается определить параметры сцены. Это позволяет предсказывать, какие объекты находятся на сцене, из каких материалов они сделаны, а также их трехмерное положение и ориентацию.
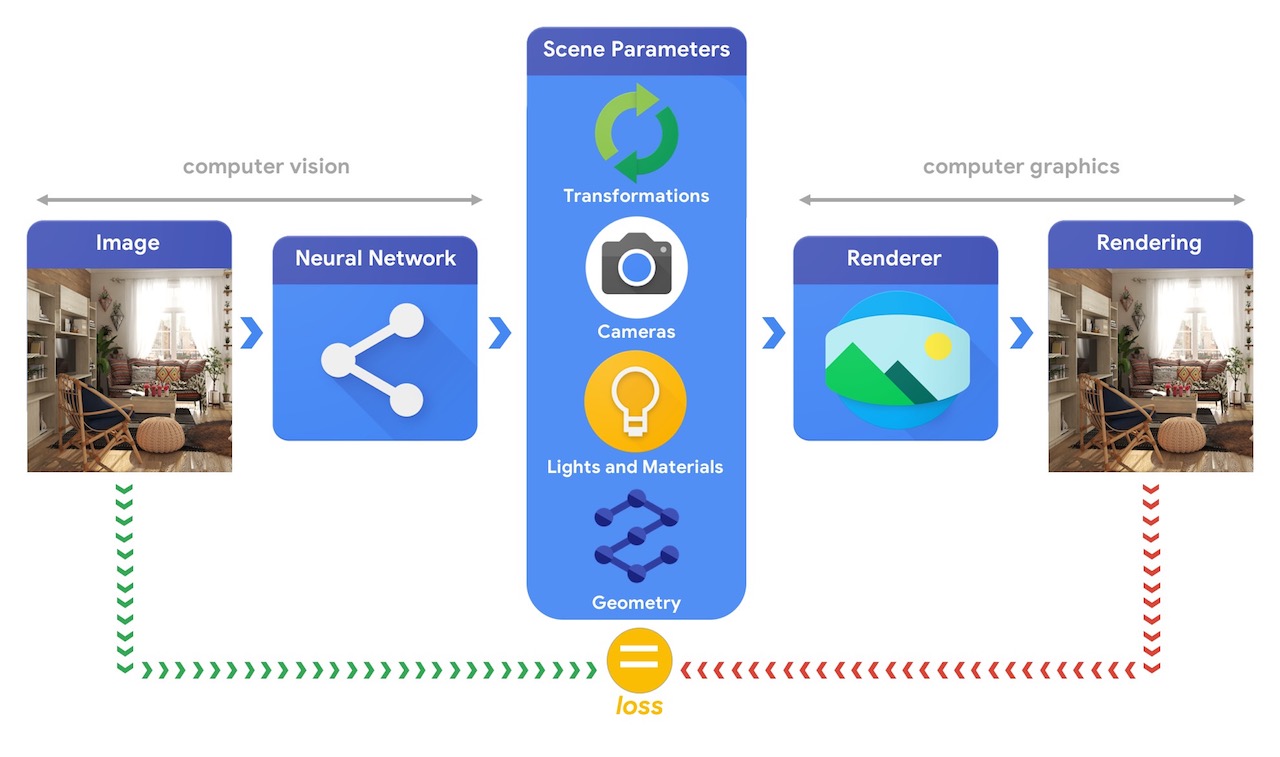
Для обучения систем машинного обучения, способных решать эти сложные задачи трехмерного зрения, чаще всего требуются большие объемы данных. Поскольку маркировка данных является дорогостоящим и сложным процессом, важно иметь механизмы для разработки моделей машинного обучения, которые могут понимать трехмерный мир при обучении без особого контроля. Сочетание методов компьютерного зрения и компьютерной графики дает уникальную возможность использовать огромные объемы легкодоступных неразмеченных данных. Как показано на изображении ниже, это может быть достигнуто, например, с помощью анализа путем синтеза, когда система машинного зрения извлекает параметры сцены, а графическая система воспроизводит изображение на их основе. Если рендеринг соответствует исходному изображению, система технического зрения точно извлекла параметры сцены. В этой установке компьютерное зрение и компьютерная графика идут рука об руку, образуя единую систему машинного обучения, похожую на автоэнкодер, которую можно обучать с самоконтролем.
Tensorflow Graphics разрабатывается, чтобы помочь решить эти типы задач, и для этого он предоставляет набор дифференцируемых графических и геометрических слоев (например, камеры, модели отражения, пространственные преобразования, свертки сетки) и функции просмотра 3D (например, 3D TensorBoard), которые можно использовать для обучения и отладки выбранных вами моделей машинного обучения.