
در چند سال اخیر شاهد افزایش لایههای گرافیکی متمایز جدید بودهایم که میتوان آنها را در معماری شبکههای عصبی درج کرد. از ترانسفورماتورهای فضایی گرفته تا رندرهای گرافیکی متمایز، این لایههای جدید از دانش بهدستآمده در طول سالها تحقیقات گرافیکی و بینایی کامپیوتری برای ساختن معماریهای شبکه جدید و کارآمدتر استفاده میکنند. مدلسازی صریح پیشینها و محدودیتهای هندسی در شبکههای عصبی، دری را به روی معماریهایی باز میکند که میتوان آنها را قوی، کارآمد، و مهمتر، به شیوهای تحت نظارت خود آموزش داد.
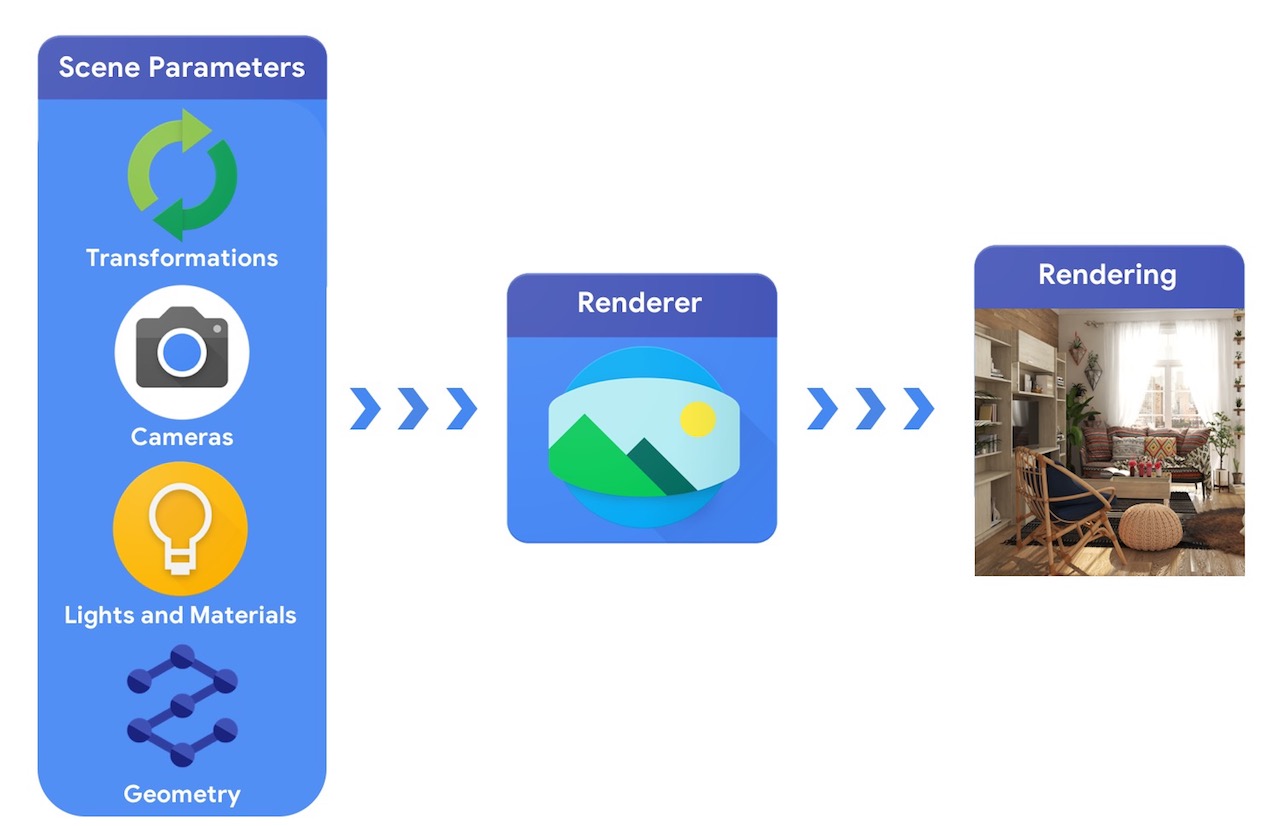
در سطح بالایی، خط لوله گرافیک کامپیوتری به نمایش اجسام سه بعدی و موقعیت مطلق آنها در صحنه، توصیف موادی که از آنها ساخته شدهاند، چراغها و دوربین نیاز دارد. این توصیف صحنه سپس توسط یک رندر برای ایجاد یک رندر مصنوعی تفسیر می شود.
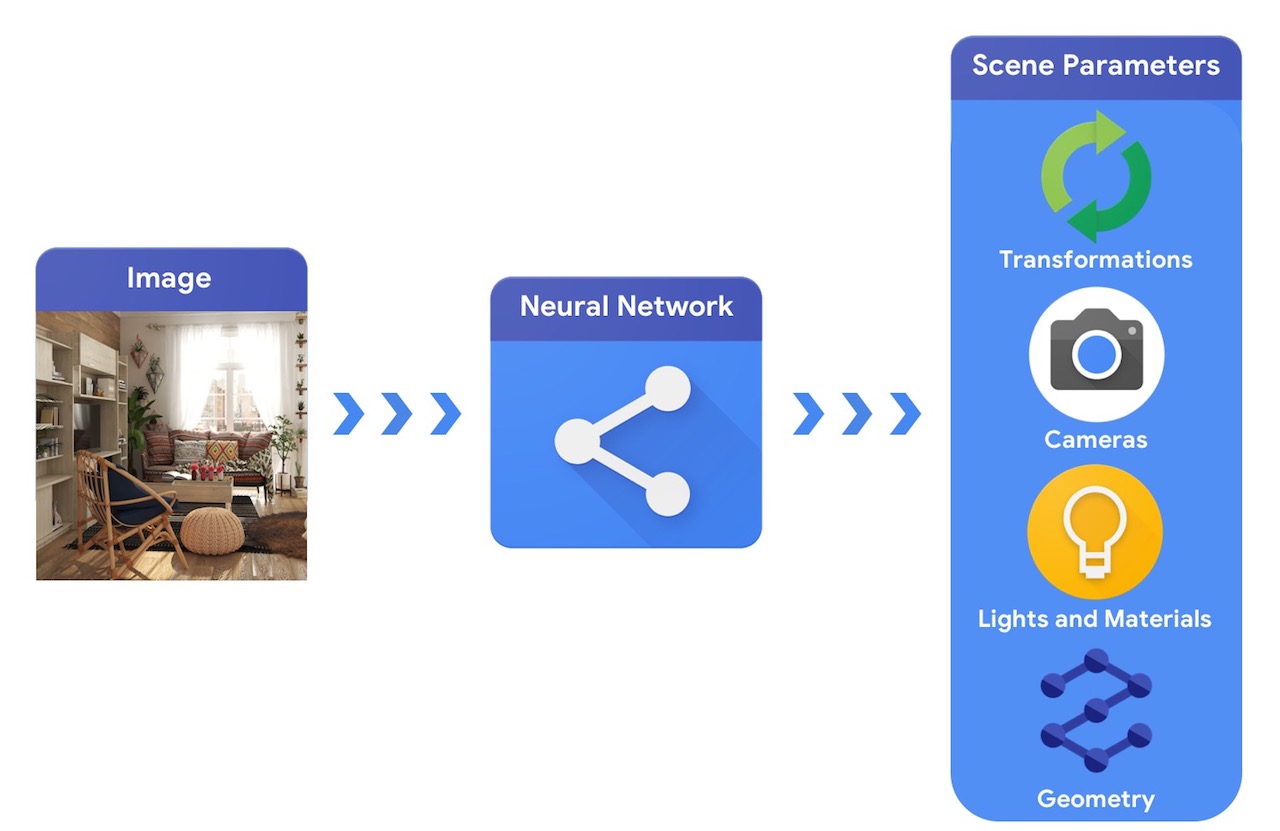
در مقایسه، یک سیستم بینایی کامپیوتری از یک تصویر شروع میشود و سعی میکند پارامترهای صحنه را استنتاج کند. این اجازه می دهد تا پیش بینی اینکه کدام اشیاء در صحنه هستند، از چه موادی ساخته شده اند و موقعیت و جهت سه بعدی.
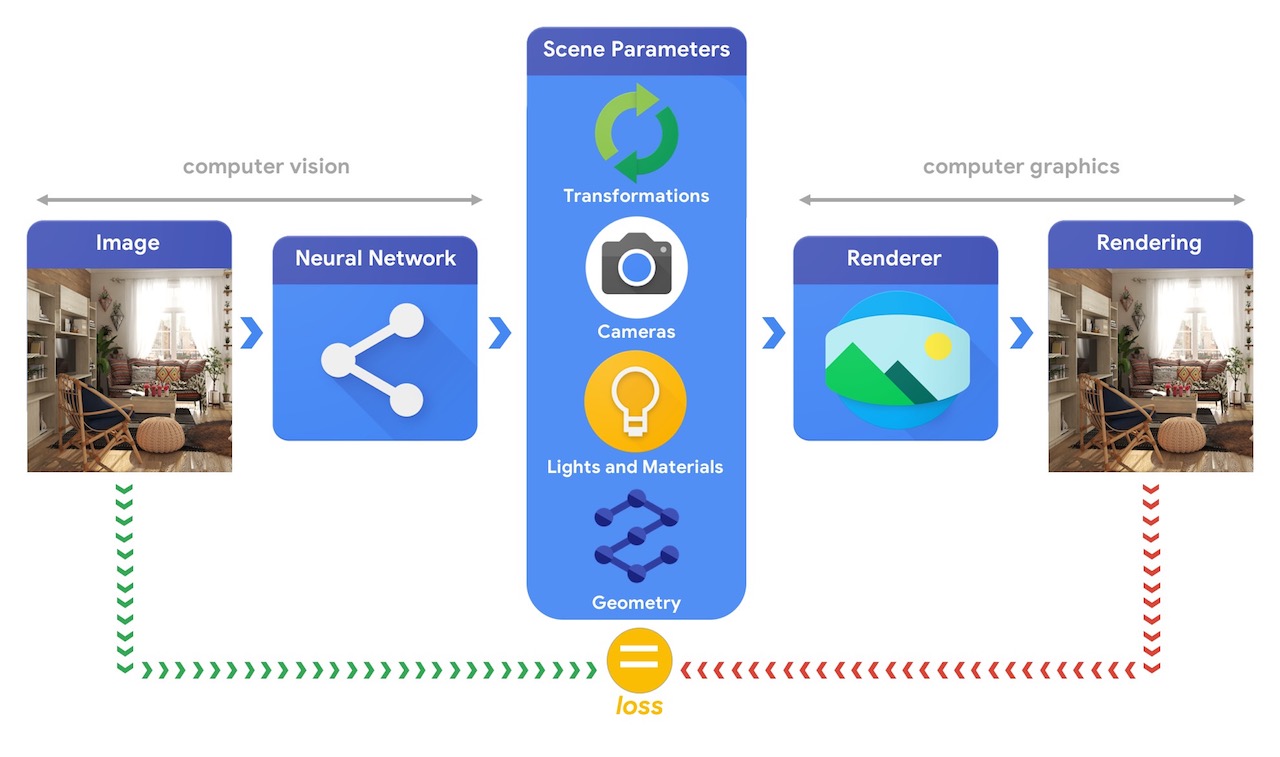
آموزش سیستم های یادگیری ماشینی که قادر به حل این وظایف پیچیده بینایی سه بعدی هستند اغلب به مقادیر زیادی داده نیاز دارد. از آنجایی که برچسبگذاری دادهها فرآیندی پرهزینه و پیچیده است، داشتن مکانیسمهایی برای طراحی مدلهای یادگیری ماشینی که میتوانند دنیای سه بعدی را درک کنند و در عین حال بدون نظارت زیاد آموزش ببینند، مهم است. ترکیب بینایی کامپیوتر و تکنیکهای گرافیک کامپیوتری فرصتی منحصربهفرد برای بهرهبرداری از حجم وسیعی از دادههای بدون برچسب در دسترس است. همانطور که در تصویر زیر نشان داده شده است، برای مثال، می توان با استفاده از تجزیه و تحلیل از طریق سنتز که در آن سیستم بینایی پارامترهای صحنه را استخراج می کند و سیستم گرافیکی یک تصویر را بر اساس آنها بازگرداند. اگر رندر با تصویر اصلی مطابقت داشته باشد، سیستم بینایی به دقت پارامترهای صحنه را استخراج کرده است. در این راهاندازی، بینایی کامپیوتر و گرافیک کامپیوتری دست به دست هم داده و یک سیستم یادگیری ماشینی شبیه به رمزگذار خودکار را تشکیل میدهند که میتوان آن را به شیوهای تحت نظارت خود آموزش داد.
Tensorflow Graphics برای کمک به مقابله با این نوع چالشها توسعه مییابد و برای انجام این کار، مجموعهای از لایههای گرافیکی و هندسی قابل تمایز (مانند دوربینها، مدلهای بازتابی، تبدیلهای فضایی، پیچشهای مش) و عملکردهای بیننده سهبعدی (مانند 3D TensorBoard) را ارائه میکند. می تواند برای آموزش و اشکال زدایی مدل های یادگیری ماشین انتخابی شما استفاده شود.