
El aprendizaje estructurado neuronal (NSL) se centra en entrenar redes neuronales profundas aprovechando señales estructuradas (cuando estén disponibles) junto con entradas de funciones. Como lo presentaron Bui et al. (WSDM'18) , estas señales estructuradas se utilizan para regularizar el entrenamiento de una red neuronal, lo que obliga al modelo a aprender predicciones precisas (minimizando la pérdida supervisada), mientras que al mismo tiempo mantiene la similitud estructural de entrada (minimizando la pérdida de vecino). , consulte la figura siguiente). Esta técnica es genérica y se puede aplicar en arquitecturas neuronales arbitrarias (como NN de retroalimentación, NN convolucionales y NN recurrentes).
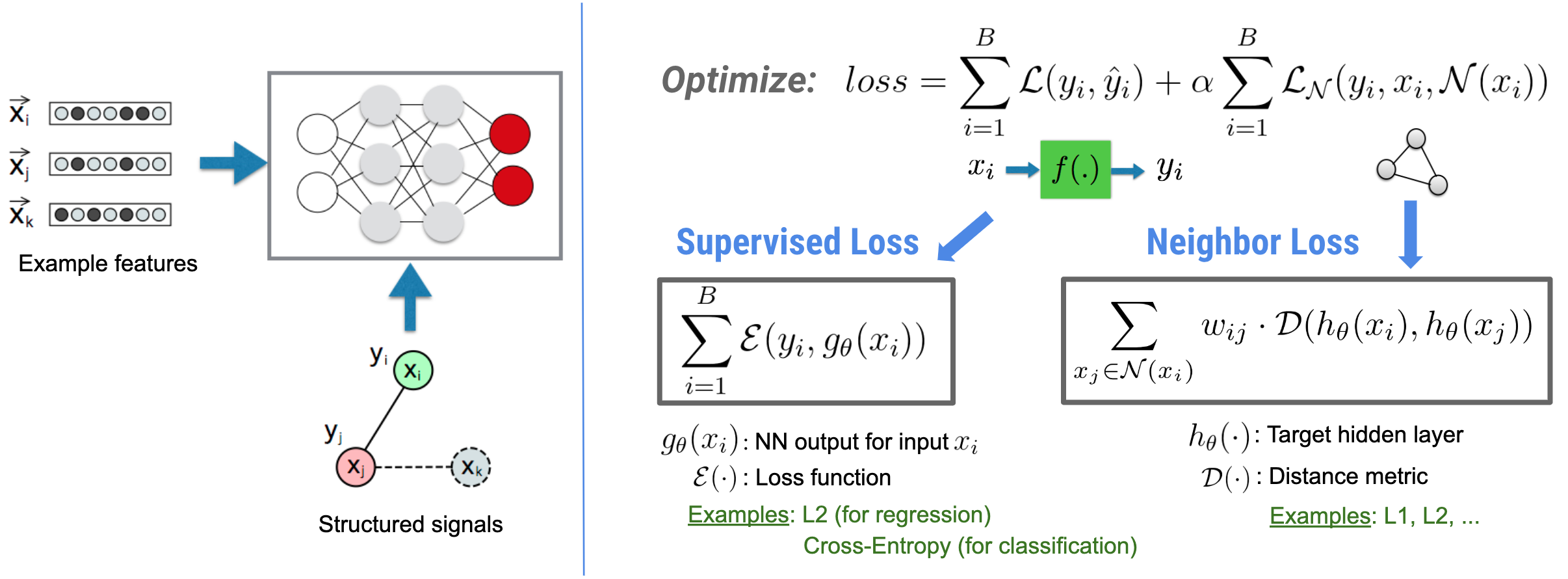
Tenga en cuenta que la ecuación de pérdida de vecinos generalizada es flexible y puede tener otras formas además de la ilustrada anteriormente. Por ejemplo, también podemos seleccionar\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ser la pérdida de vecino, que calcula la distancia entre la verdad del terreno \(y_i\)y la predicción del vecino \(g_\theta(x_j)\). Esto se usa comúnmente en el aprendizaje adversario (Goodfellow et al., ICLR'15) . Por lo tanto, NSL se generaliza al aprendizaje de gráficos neuronales si los vecinos están representados explícitamente por un gráfico, y al aprendizaje adversario si los vecinos son inducidos implícitamente por una perturbación adversaria.
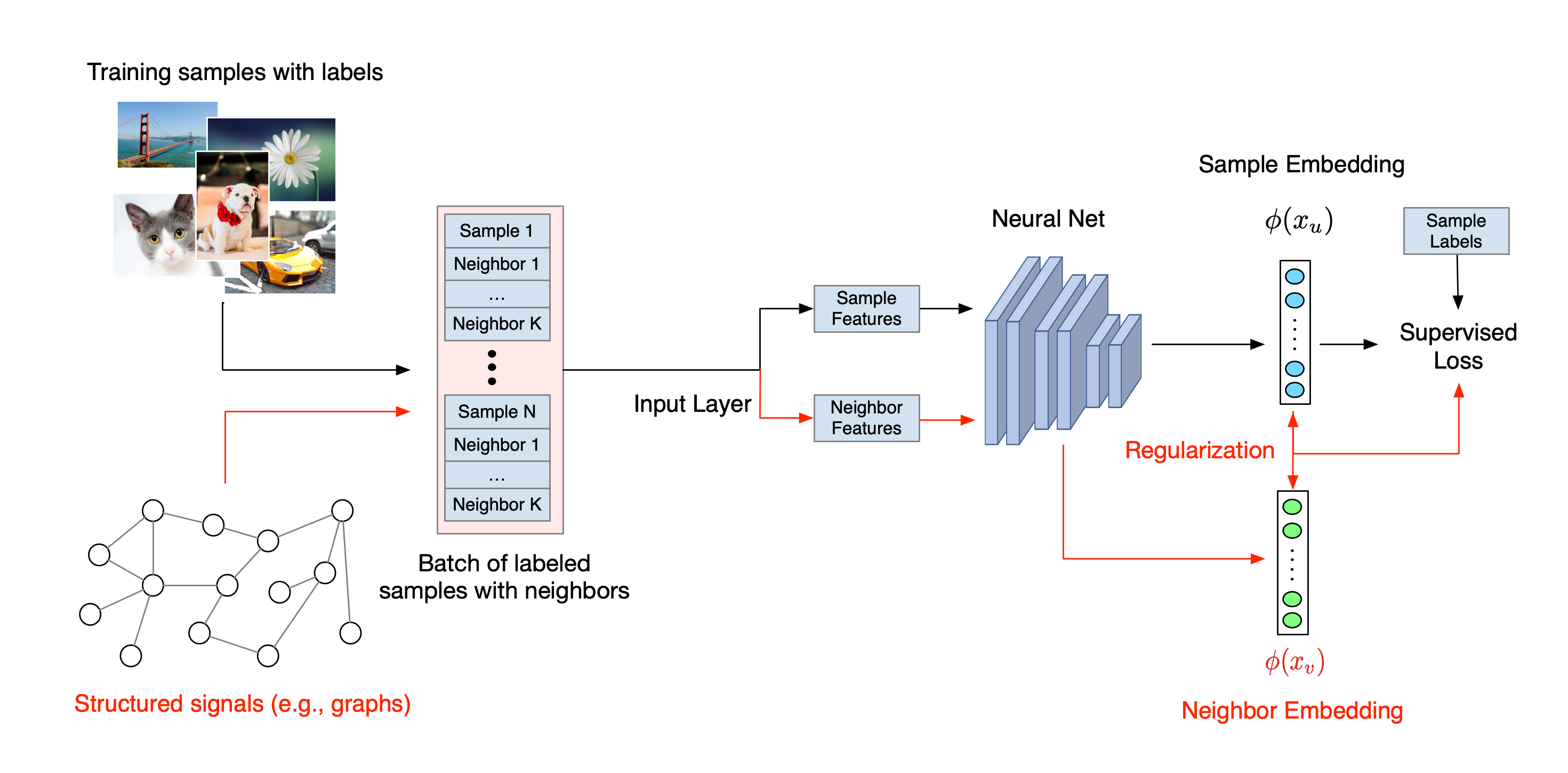
El flujo de trabajo general para el aprendizaje estructurado neuronal se ilustra a continuación. Las flechas negras representan el flujo de trabajo de capacitación convencional y las flechas rojas representan el nuevo flujo de trabajo introducido por NSL para aprovechar las señales estructuradas. Primero, las muestras de entrenamiento se aumentan para incluir señales estructuradas. Cuando las señales estructuradas no se proporcionan explícitamente, pueden construirse o inducirse (esto último se aplica al aprendizaje adversario). A continuación, las muestras de entrenamiento aumentadas (incluidas las muestras originales y sus vecinos correspondientes) se introducen en la red neuronal para calcular sus incorporaciones. La distancia entre la incrustación de una muestra y la incrustación de su vecino se calcula y se utiliza como pérdida de vecino, que se trata como un término de regularización y se suma a la pérdida final. Para la regularización explícita basada en vecinos, normalmente calculamos la pérdida de vecinos como la distancia entre la incrustación de la muestra y la incrustación del vecino. Sin embargo, se puede utilizar cualquier capa de la red neuronal para calcular la pérdida de vecino. Por otro lado, para la regularización inducida basada en vecinos (adversario), calculamos la pérdida de vecino como la distancia entre la predicción de salida del vecino adversario inducido y la etiqueta de verdad fundamental.
¿Por qué utilizar NSL?
NSL trae las siguientes ventajas:
- Mayor precisión : las señales estructuradas entre muestras pueden proporcionar información que no siempre está disponible en las entradas de funciones; por lo tanto, se ha demostrado que el enfoque de entrenamiento conjunto (con características y señales estructuradas) supera a muchos métodos existentes (que se basan únicamente en el entrenamiento con características) en una amplia gama de tareas, como la clasificación de documentos y la clasificación de intenciones semánticas ( Bui et al. ., WSDM'18 y Kipf et al., ICLR'17 ).
- Robustez : se ha demostrado que los modelos entrenados con ejemplos contradictorios son robustos contra perturbaciones adversas diseñadas para engañar en la predicción o clasificación de un modelo ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). Cuando el número de muestras de entrenamiento es pequeño, el entrenamiento con ejemplos contradictorios también ayuda a mejorar la precisión del modelo ( Tsipras et al., ICLR'19 ).
- Se requieren menos datos etiquetados : NSL permite que las redes neuronales aprovechen datos etiquetados y no etiquetados, lo que extiende el paradigma de aprendizaje al aprendizaje semisupervisado . Específicamente, NSL permite que la red se entrene utilizando datos etiquetados como en la configuración supervisada y, al mismo tiempo, impulsa a la red a aprender representaciones ocultas similares para las "muestras vecinas" que pueden tener o no etiquetas. Esta técnica ha demostrado ser muy prometedora para mejorar la precisión del modelo cuando la cantidad de datos etiquetados es relativamente pequeña ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutoriales paso a paso
Para obtener experiencia práctica con el aprendizaje estructurado neuronal, contamos con tutoriales que cubren varios escenarios en los que se pueden dar, construir o inducir explícitamente señales estructuradas. Aquí hay algunos:
Regularización de gráficos para clasificación de documentos mediante gráficos naturales . En este tutorial, exploramos el uso de la regularización de gráficos para clasificar documentos que forman un gráfico natural (orgánico).
Regularización de gráficos para clasificación de sentimientos mediante gráficos sintetizados . En este tutorial, demostramos el uso de la regularización de gráficos para clasificar los sentimientos de reseñas de películas mediante la construcción (sintetización) de señales estructuradas.
Aprendizaje adversario para la clasificación de imágenes . En este tutorial, exploramos el uso del aprendizaje adversario (donde se inducen señales estructuradas) para clasificar imágenes que contienen dígitos numéricos.
Puede encontrar más ejemplos y tutoriales en el directorio de ejemplos de nuestro repositorio de GitHub.
,El aprendizaje estructurado neuronal (NSL) se centra en entrenar redes neuronales profundas aprovechando señales estructuradas (cuando estén disponibles) junto con entradas de funciones. Como lo presentaron Bui et al. (WSDM'18) , estas señales estructuradas se utilizan para regularizar el entrenamiento de una red neuronal, lo que obliga al modelo a aprender predicciones precisas (minimizando la pérdida supervisada), mientras que al mismo tiempo mantiene la similitud estructural de entrada (minimizando la pérdida de vecino). , consulte la figura siguiente). Esta técnica es genérica y se puede aplicar en arquitecturas neuronales arbitrarias (como NN de retroalimentación, NN convolucionales y NN recurrentes).
Tenga en cuenta que la ecuación de pérdida de vecino generalizada es flexible y puede tener otras formas además de la ilustrada anteriormente. Por ejemplo, también podemos seleccionar\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ser la pérdida de vecino, que calcula la distancia entre la verdad del terreno \(y_i\)y la predicción del vecino \(g_\theta(x_j)\). Esto se usa comúnmente en el aprendizaje adversario (Goodfellow et al., ICLR'15) . Por lo tanto, NSL se generaliza al aprendizaje de gráficos neuronales si los vecinos están representados explícitamente por un gráfico, y al aprendizaje adversario si los vecinos son inducidos implícitamente por una perturbación adversaria.
El flujo de trabajo general para el aprendizaje estructurado neuronal se ilustra a continuación. Las flechas negras representan el flujo de trabajo de capacitación convencional y las flechas rojas representan el nuevo flujo de trabajo introducido por NSL para aprovechar las señales estructuradas. Primero, las muestras de entrenamiento se aumentan para incluir señales estructuradas. Cuando las señales estructuradas no se proporcionan explícitamente, pueden construirse o inducirse (esto último se aplica al aprendizaje adversario). A continuación, las muestras de entrenamiento aumentadas (incluidas las muestras originales y sus vecinos correspondientes) se introducen en la red neuronal para calcular sus incorporaciones. La distancia entre la incrustación de una muestra y la incrustación de su vecino se calcula y se utiliza como pérdida de vecino, que se trata como un término de regularización y se suma a la pérdida final. Para la regularización explícita basada en vecinos, normalmente calculamos la pérdida de vecinos como la distancia entre la incrustación de la muestra y la incrustación del vecino. Sin embargo, se puede utilizar cualquier capa de la red neuronal para calcular la pérdida de vecino. Por otro lado, para la regularización inducida basada en vecinos (adversario), calculamos la pérdida de vecino como la distancia entre la predicción de salida del vecino adversario inducido y la etiqueta de verdad fundamental.
¿Por qué utilizar NSL?
NSL trae las siguientes ventajas:
- Mayor precisión : las señales estructuradas entre muestras pueden proporcionar información que no siempre está disponible en las entradas de funciones; por lo tanto, se ha demostrado que el enfoque de entrenamiento conjunto (con características y señales estructuradas) supera a muchos métodos existentes (que se basan únicamente en el entrenamiento con características) en una amplia gama de tareas, como la clasificación de documentos y la clasificación de intenciones semánticas ( Bui et al. ., WSDM'18 y Kipf et al., ICLR'17 ).
- Robustez : se ha demostrado que los modelos entrenados con ejemplos contradictorios son robustos contra perturbaciones adversas diseñadas para engañar en la predicción o clasificación de un modelo ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). Cuando el número de muestras de entrenamiento es pequeño, el entrenamiento con ejemplos contradictorios también ayuda a mejorar la precisión del modelo ( Tsipras et al., ICLR'19 ).
- Se requieren menos datos etiquetados : NSL permite que las redes neuronales aprovechen datos etiquetados y no etiquetados, lo que extiende el paradigma de aprendizaje al aprendizaje semisupervisado . Específicamente, NSL permite que la red se entrene utilizando datos etiquetados como en la configuración supervisada y, al mismo tiempo, impulsa a la red a aprender representaciones ocultas similares para las "muestras vecinas" que pueden tener o no etiquetas. Esta técnica ha demostrado ser muy prometedora para mejorar la precisión del modelo cuando la cantidad de datos etiquetados es relativamente pequeña ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutoriales paso a paso
Para obtener experiencia práctica con el aprendizaje estructurado neuronal, contamos con tutoriales que cubren varios escenarios en los que se pueden dar, construir o inducir explícitamente señales estructuradas. Aquí hay algunos:
Regularización de gráficos para clasificación de documentos mediante gráficos naturales . En este tutorial, exploramos el uso de la regularización de gráficos para clasificar documentos que forman un gráfico natural (orgánico).
Regularización de gráficos para clasificación de sentimientos mediante gráficos sintetizados . En este tutorial, demostramos el uso de la regularización de gráficos para clasificar los sentimientos de reseñas de películas mediante la construcción (sintetización) de señales estructuradas.
Aprendizaje adversario para la clasificación de imágenes . En este tutorial, exploramos el uso del aprendizaje adversario (donde se inducen señales estructuradas) para clasificar imágenes que contienen dígitos numéricos.
Puede encontrar más ejemplos y tutoriales en el directorio de ejemplos de nuestro repositorio de GitHub.
,El aprendizaje estructurado neuronal (NSL) se centra en entrenar redes neuronales profundas aprovechando señales estructuradas (cuando estén disponibles) junto con entradas de funciones. Como lo presentaron Bui et al. (WSDM'18) , estas señales estructuradas se utilizan para regularizar el entrenamiento de una red neuronal, lo que obliga al modelo a aprender predicciones precisas (minimizando la pérdida supervisada), mientras que al mismo tiempo mantiene la similitud estructural de entrada (minimizando la pérdida de vecino). , consulte la figura siguiente). Esta técnica es genérica y se puede aplicar en arquitecturas neuronales arbitrarias (como NN de retroalimentación, NN convolucionales y NN recurrentes).
Tenga en cuenta que la ecuación de pérdida de vecino generalizada es flexible y puede tener otras formas además de la ilustrada anteriormente. Por ejemplo, también podemos seleccionar\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ser la pérdida de vecino, que calcula la distancia entre la verdad del terreno \(y_i\)y la predicción del vecino \(g_\theta(x_j)\). Esto se usa comúnmente en el aprendizaje adversario (Goodfellow et al., ICLR'15) . Por lo tanto, NSL se generaliza al aprendizaje de gráficos neuronales si los vecinos están representados explícitamente por un gráfico, y al aprendizaje adversario si los vecinos son inducidos implícitamente por una perturbación adversaria.
El flujo de trabajo general para el aprendizaje estructurado neuronal se ilustra a continuación. Las flechas negras representan el flujo de trabajo de capacitación convencional y las flechas rojas representan el nuevo flujo de trabajo introducido por NSL para aprovechar las señales estructuradas. Primero, las muestras de entrenamiento se aumentan para incluir señales estructuradas. Cuando las señales estructuradas no se proporcionan explícitamente, pueden construirse o inducirse (esto último se aplica al aprendizaje adversario). A continuación, las muestras de entrenamiento aumentadas (incluidas las muestras originales y sus vecinos correspondientes) se introducen en la red neuronal para calcular sus incorporaciones. La distancia entre la incrustación de una muestra y la incrustación de su vecino se calcula y se utiliza como pérdida de vecino, que se trata como un término de regularización y se suma a la pérdida final. Para la regularización explícita basada en vecinos, normalmente calculamos la pérdida de vecinos como la distancia entre la incrustación de la muestra y la incrustación del vecino. Sin embargo, se puede utilizar cualquier capa de la red neuronal para calcular la pérdida de vecino. Por otro lado, para la regularización inducida basada en vecinos (adversario), calculamos la pérdida de vecino como la distancia entre la predicción de salida del vecino adversario inducido y la etiqueta de verdad fundamental.
¿Por qué utilizar NSL?
NSL trae las siguientes ventajas:
- Mayor precisión : las señales estructuradas entre muestras pueden proporcionar información que no siempre está disponible en las entradas de funciones; por lo tanto, se ha demostrado que el enfoque de entrenamiento conjunto (con características y señales estructuradas) supera a muchos métodos existentes (que se basan únicamente en el entrenamiento con características) en una amplia gama de tareas, como la clasificación de documentos y la clasificación de intenciones semánticas ( Bui et al. ., WSDM'18 y Kipf et al., ICLR'17 ).
- Robustez : se ha demostrado que los modelos entrenados con ejemplos contradictorios son robustos contra perturbaciones adversas diseñadas para engañar en la predicción o clasificación de un modelo ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ). Cuando el número de muestras de entrenamiento es pequeño, el entrenamiento con ejemplos contradictorios también ayuda a mejorar la precisión del modelo ( Tsipras et al., ICLR'19 ).
- Se requieren menos datos etiquetados : NSL permite que las redes neuronales aprovechen datos etiquetados y no etiquetados, lo que extiende el paradigma de aprendizaje al aprendizaje semisupervisado . Específicamente, NSL permite que la red se entrene utilizando datos etiquetados como en la configuración supervisada y, al mismo tiempo, impulsa a la red a aprender representaciones ocultas similares para las "muestras vecinas" que pueden tener o no etiquetas. Esta técnica ha demostrado ser muy prometedora para mejorar la precisión del modelo cuando la cantidad de datos etiquetados es relativamente pequeña ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 ).
Tutoriales paso a paso
Para obtener experiencia práctica con el aprendizaje estructurado neuronal, contamos con tutoriales que cubren varios escenarios en los que se pueden dar, construir o inducir explícitamente señales estructuradas. Aquí hay algunos:
Regularización de gráficos para clasificación de documentos mediante gráficos naturales . En este tutorial, exploramos el uso de la regularización de gráficos para clasificar documentos que forman un gráfico natural (orgánico).
Regularización de gráficos para clasificación de sentimientos mediante gráficos sintetizados . En este tutorial, demostramos el uso de la regularización de gráficos para clasificar los sentimientos de reseñas de películas mediante la construcción (sintetización) de señales estructuradas.
Aprendizaje adversario para la clasificación de imágenes . En este tutorial, exploramos el uso del aprendizaje adversario (donde se inducen señales estructuradas) para clasificar imágenes que contienen dígitos numéricos.
Puede encontrar más ejemplos y tutoriales en el directorio de ejemplos de nuestro repositorio de GitHub.