
নিউরাল স্ট্রাকচার্ড লার্নিং (NSL) ফিচার ইনপুট সহ স্ট্রাকচার্ড সিগন্যাল (যখন উপলব্ধ) ব্যবহার করে গভীর নিউরাল নেটওয়ার্ককে প্রশিক্ষণের উপর ফোকাস করে। বুই এট আল দ্বারা প্রবর্তিত হিসাবে। (WSDM'18) , এই কাঠামোগত সংকেতগুলি একটি নিউরাল নেটওয়ার্কের প্রশিক্ষণকে নিয়মিত করতে ব্যবহৃত হয়, মডেলটিকে সঠিক ভবিষ্যদ্বাণী শিখতে বাধ্য করে (তত্ত্বাবধানে থাকা ক্ষতি কমিয়ে), একই সময়ে ইনপুট কাঠামোগত মিল বজায় রাখে (প্রতিবেশীর ক্ষতি কমিয়ে) , নীচের চিত্র দেখুন)। এই কৌশলটি জেনেরিক এবং নির্বিচারে নিউরাল আর্কিটেকচারে প্রয়োগ করা যেতে পারে (যেমন ফিড-ফরোয়ার্ড এনএন, কনভোলিউশনাল এনএন এবং পুনরাবৃত্ত এনএন)।
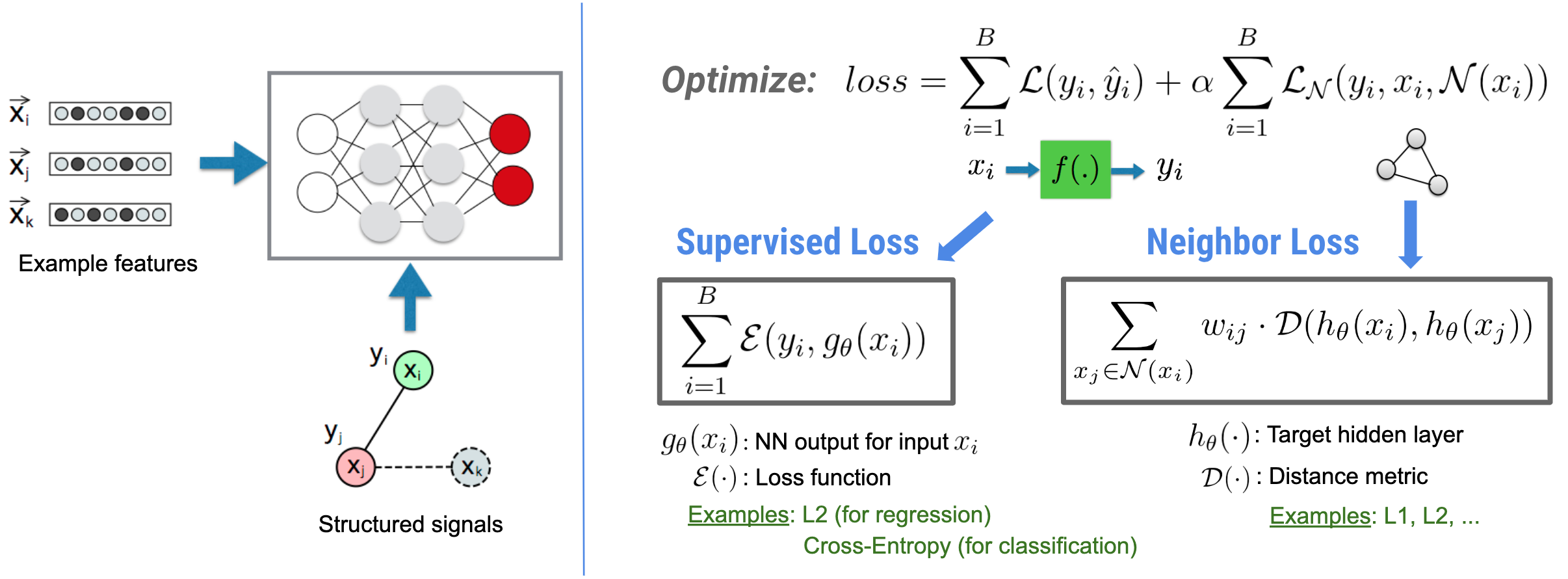
মনে রাখবেন যে সাধারণীকৃত প্রতিবেশী ক্ষতির সমীকরণটি নমনীয় এবং উপরে চিত্রিত একটি ছাড়াও অন্যান্য রূপ থাকতে পারে। উদাহরণস্বরূপ, আমরাও নির্বাচন করতে পারি\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) প্রতিবেশী ক্ষতি হতে হবে, যা স্থল সত্যের মধ্যে দূরত্ব গণনা করে \(y_i\)এবং প্রতিবেশীর কাছ থেকে ভবিষ্যদ্বাণী \(g_\theta(x_j)\). এটি সাধারণত প্রতিপক্ষ শিক্ষায় ব্যবহৃত হয় (গুডফেলো এট আল।, ICLR'15) । অতএব, এনএসএল নিউরাল গ্রাফ লার্নিংকে সাধারণীকরণ করে যদি প্রতিবেশীদের একটি গ্রাফ দ্বারা স্পষ্টভাবে প্রতিনিধিত্ব করা হয় এবং প্রতিবেশীরা যদি প্রতিকূলভাবে প্রতিকূলতা দ্বারা প্ররোচিত হয় তবে প্রতিপক্ষের শিক্ষার জন্য।
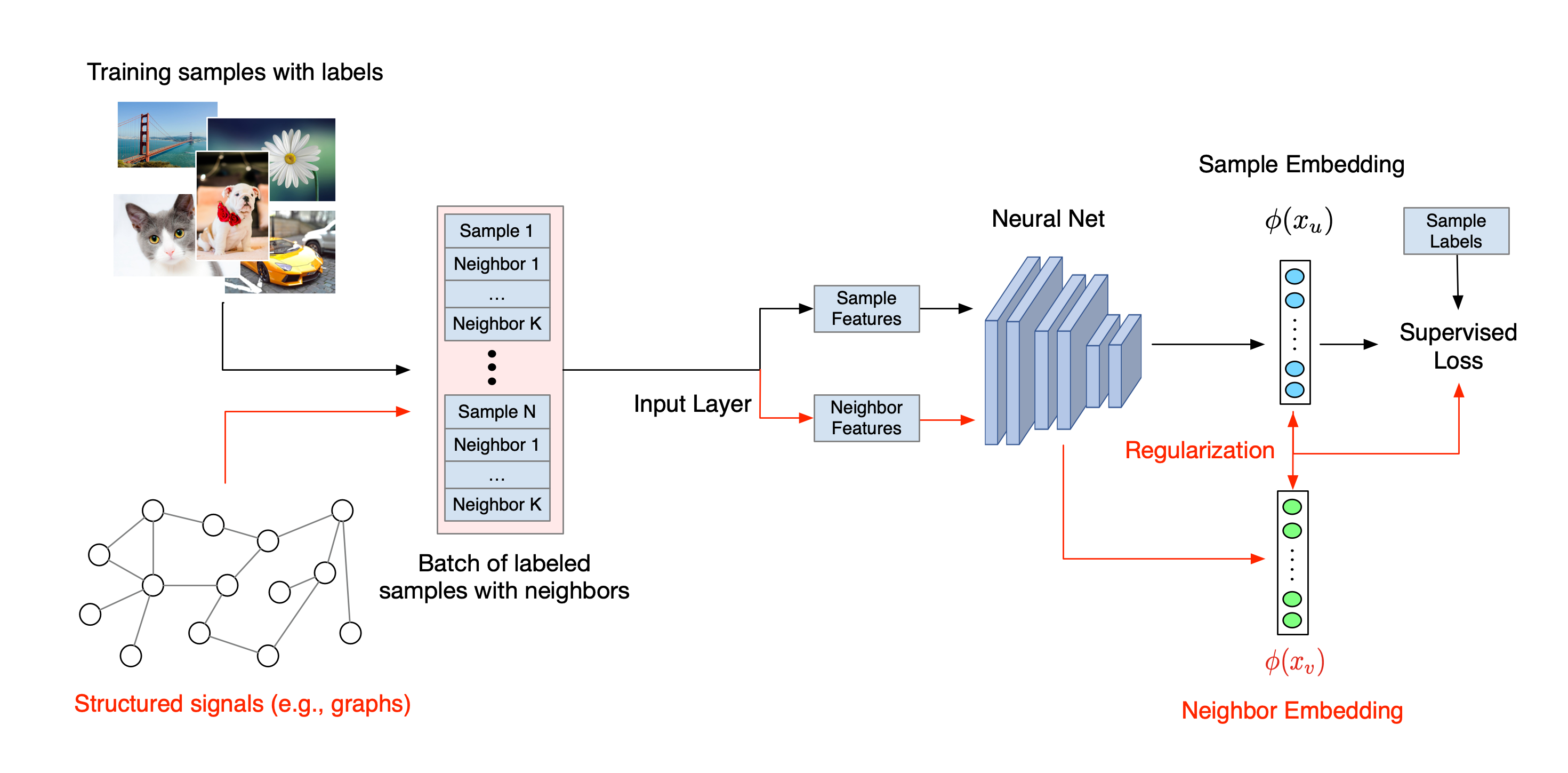
নিউরাল স্ট্রাকচার্ড লার্নিং এর সামগ্রিক কর্মপ্রবাহ নীচে চিত্রিত করা হয়েছে। কালো তীরগুলি প্রচলিত প্রশিক্ষণ কর্মপ্রবাহকে উপস্থাপন করে এবং লাল তীরগুলি কাঠামোগত সংকেতগুলিকে লিভারেজ করার জন্য NSL দ্বারা প্রবর্তিত নতুন কর্মপ্রবাহকে উপস্থাপন করে। প্রথমত, প্রশিক্ষণের নমুনাগুলিকে কাঠামোগত সংকেত অন্তর্ভুক্ত করার জন্য বর্ধিত করা হয়। যখন কাঠামোগত সংকেতগুলি স্পষ্টভাবে প্রদান করা হয় না, তখন সেগুলি হয় নির্মাণ বা প্ররোচিত করা যেতে পারে (পরবর্তীটি প্রতিপক্ষ শিক্ষার ক্ষেত্রে প্রযোজ্য)। এরপরে, বর্ধিত প্রশিক্ষণের নমুনাগুলি (মূল নমুনা এবং তাদের সংশ্লিষ্ট প্রতিবেশী উভয় সহ) তাদের এমবেডিং গণনা করার জন্য নিউরাল নেটওয়ার্কে খাওয়ানো হয়। একটি নমুনার এম্বেডিং এবং এর প্রতিবেশীর এম্বেডিংয়ের মধ্যে দূরত্ব গণনা করা হয় এবং প্রতিবেশীর ক্ষতি হিসাবে ব্যবহৃত হয়, যা একটি নিয়মিতকরণ শব্দ হিসাবে বিবেচিত হয় এবং চূড়ান্ত ক্ষতিতে যোগ করা হয়। সুস্পষ্ট প্রতিবেশী-ভিত্তিক নিয়মিতকরণের জন্য, আমরা সাধারণত প্রতিবেশীর ক্ষতিকে নমুনার এম্বেডিং এবং প্রতিবেশীর এম্বেডিংয়ের মধ্যে দূরত্ব হিসাবে গণনা করি। যাইহোক, নিউরাল নেটওয়ার্কের যে কোন স্তর প্রতিবেশী ক্ষতি গণনা করতে ব্যবহার করা যেতে পারে। অন্যদিকে, প্ররোচিত প্রতিবেশী-ভিত্তিক নিয়মিতকরণের জন্য (প্রতিপক্ষের), আমরা প্রতিবেশী ক্ষতিকে প্ররোচিত প্রতিপক্ষ প্রতিবেশীর আউটপুট পূর্বাভাস এবং গ্রাউন্ড ট্রুথ লেবেলের মধ্যে দূরত্ব হিসাবে গণনা করি।
কেন NSL ব্যবহার করবেন?
NSL নিম্নলিখিত সুবিধা নিয়ে আসে:
- উচ্চতর নির্ভুলতা : নমুনাগুলির মধ্যে কাঠামোগত সংকেত(গুলি) এমন তথ্য প্রদান করতে পারে যা বৈশিষ্ট্য ইনপুটগুলিতে সবসময় পাওয়া যায় না; তাই, যৌথ প্রশিক্ষণের পদ্ধতি (গঠিত সংকেত এবং বৈশিষ্ট্য উভয়ের সাথে) অনেকগুলি বিদ্যমান পদ্ধতিকে (যেগুলি শুধুমাত্র বৈশিষ্ট্যগুলির সাথে প্রশিক্ষণের উপর নির্ভর করে) বিস্তৃত কাজগুলিতে, যেমন নথির শ্রেণিবিন্যাস এবং শব্দার্থিক অভিপ্রায় শ্রেণীবিভাগ ( বুই এট আল ., WSDM'18 এবং Kipf et al., ICLR'17 )।
- দৃঢ়তা : প্রতিকূল উদাহরণ সহ প্রশিক্ষিত মডেলগুলি একটি মডেলের ভবিষ্যদ্বাণী বা শ্রেণীবিভাগকে বিভ্রান্ত করার জন্য ডিজাইন করা প্রতিকূল বিরক্তির বিরুদ্ধে শক্তিশালী বলে দেখানো হয়েছে ( Goodfellow et al., ICLR'15 এবং Miyato et al., ICLR'16 )। যখন প্রশিক্ষণের নমুনার সংখ্যা কম হয়, তখন প্রতিকূল উদাহরণ সহ প্রশিক্ষণও মডেলের নির্ভুলতা উন্নত করতে সাহায্য করে ( Tsipras et al., ICLR'19 )।
- কম লেবেলযুক্ত ডেটার প্রয়োজন : NSL নিউরাল নেটওয়ার্কগুলিকে লেবেলযুক্ত এবং লেবেলবিহীন উভয় ডেটা ব্যবহার করতে সক্ষম করে, যা শেখার দৃষ্টান্তকে আধা-তত্ত্বাবধানে শিক্ষার জন্য প্রসারিত করে। বিশেষভাবে, NSL নেটওয়ার্কটিকে তত্ত্বাবধানে থাকা সেটিং-এর মতো লেবেলযুক্ত ডেটা ব্যবহার করে প্রশিক্ষণের অনুমতি দেয় এবং একই সময়ে নেটওয়ার্কটিকে "প্রতিবেশী নমুনা" এর জন্য অনুরূপ লুকানো উপস্থাপনা শিখতে চালিত করে যেগুলির লেবেল থাকতে পারে বা নাও থাকতে পারে৷ এই কৌশলটি মডেল নির্ভুলতা উন্নত করার জন্য দুর্দান্ত প্রতিশ্রুতি দেখিয়েছে যখন লেবেলযুক্ত ডেটার পরিমাণ তুলনামূলকভাবে কম হয় ( Bui et al., WSDM'18 এবং Miyato et al., ICLR'16 )।
ধাপে ধাপে টিউটোরিয়াল
নিউরাল স্ট্রাকচার্ড লার্নিং এর সাথে অভিজ্ঞতা অর্জনের জন্য, আমাদের কাছে টিউটোরিয়াল রয়েছে যা বিভিন্ন পরিস্থিতিতে কভার করে যেখানে কাঠামোগত সংকেতগুলি স্পষ্টভাবে দেওয়া, তৈরি করা বা প্ররোচিত করা যেতে পারে। এখানে কয়েকটি আছে:
প্রাকৃতিক গ্রাফ ব্যবহার করে নথি শ্রেণীবিভাগের জন্য গ্রাফ নিয়মিতকরণ । এই টিউটোরিয়ালে, আমরা প্রাকৃতিক (জৈব) গ্রাফ তৈরি করে এমন নথিগুলিকে শ্রেণিবদ্ধ করতে গ্রাফ নিয়মিতকরণের ব্যবহার অন্বেষণ করি।
সংশ্লেষিত গ্রাফ ব্যবহার করে অনুভূতি শ্রেণীবিভাগের জন্য গ্রাফ নিয়মিতকরণ । এই টিউটোরিয়ালে, আমরা কাঠামোগত সংকেত নির্মাণ (সংশ্লেষণ) দ্বারা চলচ্চিত্র পর্যালোচনা অনুভূতি শ্রেণীবদ্ধ করতে গ্রাফ নিয়মিতকরণের ব্যবহার প্রদর্শন করি।
চিত্র শ্রেণীবিভাগের জন্য প্রতিকূল শিক্ষা । এই টিউটোরিয়ালে, আমরা সাংখ্যিক সংখ্যাযুক্ত চিত্রগুলিকে শ্রেণীবদ্ধ করতে প্রতিকূল শিক্ষার (যেখানে কাঠামোগত সংকেত প্ররোচিত হয়) এর ব্যবহার অন্বেষণ করি।
আরও উদাহরণ এবং টিউটোরিয়াল আমাদের GitHub সংগ্রহস্থলের উদাহরণ ডিরেক্টরিতে পাওয়া যাবে।