
Авторские права 2021 Авторы TF-Agents.
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Вступление
Этот пример показывает , как тренироваться REINFORCE агента на окружающей среде Cartpole с использованием библиотеки TF-агенты, похожую на DQN учебник .

Мы проведем вас через все компоненты конвейера обучения с подкреплением (RL) для обучения, оценки и сбора данных.
Настраивать
Если вы не установили следующие зависимости, запустите:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Гиперпараметры
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
Среда
Среды в RL представляют собой задачу или проблему, которую мы пытаемся решить. Стандартные среды могут быть легко созданы в TF-агентах с использованием suites . У нас есть различные suites для загрузки среды из таких источников, как OpenAI тренажерный зал, Атари, DM управления и т.д., учитывая имя строки среды.
Теперь давайте загрузим среду CartPole из пакета OpenAI Gym.
env = suite_gym.load(env_name)
Мы можем визуализировать эту среду, чтобы посмотреть, как она выглядит. К тележке прикреплен свободно качающийся шест. Цель состоит в том, чтобы переместить тележку вправо или влево, чтобы столб оставался направленным вверх.
env.reset()
PIL.Image.fromarray(env.render())
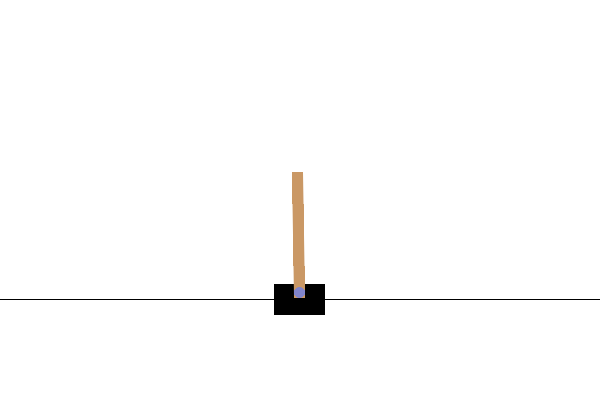
time_step = environment.step(action) оператор принимает action в окружающей среде. TimeStep кортеж вернулся содержит следующее наблюдение окружающей среды в и награду за это действие. time_step_spec() и action_spec() методы в среде вернуть спецификации (типы, формы, ограничивающей) на time_step и action соответственно.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Итак, мы видим, что наблюдение представляет собой набор из 4 поплавков: положение и скорость тележки, а также угловое положение и скорость полюса. Так как только два действия возможны (движение влево или движение вправо), то action_spec является скаляром , где 0 означает «движение влево» и 1 означает «двигаться вправо» .
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Обычно мы создаем две среды: одну для обучения, а другую - для оценки. Большинство сред написаны на чистом Python, но они могут быть легко преобразованы в TensorFlow с использованием TFPyEnvironment обертки. API исходной среды использует Numpy массивов, то TFPyEnvironment преобразует их в / из Tensors для более легко взаимодействовать с политиками и агентами TensorFlow.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Агент
Алгоритм , который мы используем , чтобы решить проблему RL представляется как Agent . В дополнении к REINFORCE агенту, TF-агенты обеспечивают стандартные реализации различных Agents , такие как DQN , DDPG , TD3 , PPO и SAC .
Для создания REINFORCE агента, сначала нужен Actor Network , который может научиться предсказывать действие данного наблюдение из окружающей среды.
Мы можем легко создать Actor Network , используя спецификации наблюдений и действий. Мы можем указать слои в сети , который, в этом примере, является fc_layer_params множества аргументов в кортеж из ints , представляющих размеры каждого скрытого слоя (смотрите раздел гиперпараметров выше).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
Нам также необходима optimizer для подготовки сети мы только что создали, и train_step_counter переменного , чтобы отслеживать , сколько раз была обновлена сеть.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
Политики
В TF-агентов, политика представляют собой стандартное понятие политики в RL: дан time_step произвести действие или распределение по действиям. Основной метод policy_step = policy.action(time_step) где policy_step именованный кортеж PolicyStep(action, state, info) . policy_step.action этого action для применения в среду, state представляет собой состояние для сохраняющего состояния (РННЫ) политики и info может содержать вспомогательную информацию , такие как бревенчатые вероятности действий.
Агенты содержат две политики: основную политику, которая используется для оценки / развертывания (agent.policy), и другую политику, которая используется для сбора данных (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
Метрики и оценка
Наиболее распространенный показатель, используемый для оценки политики, - это средний доход. Возврат - это сумма вознаграждений, полученных при выполнении политики в среде для эпизода, и мы обычно усредняем ее для нескольких эпизодов. Мы можем вычислить метрику средней доходности следующим образом.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
Буфер воспроизведения
Для того , чтобы отслеживать данные , собранные из окружающей среды, мы будем использовать Reverb , эффективный, расширяемый и простой в использовании системы воспроизведения с помощью Deepmind. Он хранит данные об опыте, когда мы собираем траектории, и потребляется во время обучения.
Этот повтор буфера строится с помощью функции , описывающие тензоры, которые должны быть сохранены, которые могут быть получены от агента с помощью tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
Для большинства агентов, то collect_data_spec является Trajectory имени кортежа , содержащего наблюдение, действия, вознаграждение и т.д.
Сбор данных
Поскольку REINFORCE извлекает уроки из целых эпизодов, мы определяем функцию для сбора эпизода, используя заданную политику сбора данных, и сохраняем данные (наблюдения, действия, награды и т. Д.) Как траектории в буфере воспроизведения. Здесь мы используем PyDriver для запуска цикла сбора опыта. Вы можете узнать больше о драйвере ТФА агентов в нашем водителях учебнике .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
Обучение агента
Цикл обучения включает как сбор данных из среды, так и оптимизацию агентских сетей. Попутно мы будем время от времени оценивать политику агента, чтобы увидеть, как у нас дела.
Выполнение следующего займет ~ 3 минуты.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
Визуализация
Сюжеты
Мы можем построить график возврата к глобальным шагам, чтобы увидеть производительность нашего агента. В Cartpole-v0 , среда дает награду +1 за каждый шаг времени полюсных пребывания, и так как максимальное число шагов 200, максимально возможный возврат также 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)

Видео
Полезно визуализировать производительность агента, визуализируя среду на каждом этапе. Прежде чем мы это сделаем, давайте сначала создадим функцию для встраивания видео в эту колабу.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Следующий код визуализирует политику агента для нескольких эпизодов:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss