
Авторские права 2021 Авторы TF-Agents.
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Вступление
Этот пример показывает , как дрессировать Soft Актер Критик агента на Minitaur среде.
Если вы работали через DQN Colab это должно чувствовать себя очень хорошо знакомы. Заметные изменения включают:
- Смена агента с DQN на SAC.
- Обучение на Minitaur, который представляет собой гораздо более сложную среду, чем CartPole. Среда Minitaur предназначена для обучения четвероногого робота движению вперед.
- Использование TF-Agents Actor-Learner API для распределенного обучения с подкреплением.
API поддерживает как распределенный сбор данных с использованием буфера воспроизведения опыта и контейнера переменных (сервер параметров), так и распределенное обучение на нескольких устройствах. API разработан очень простым и модульным. Мы используем Reverb как для воспроизведения буфера и переменной емкости и TF DistributionStrategy API для распределенного обучения на графических процессорах и ТПУ.
Если вы не установили следующие зависимости, запустите:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Настраивать
Сначала мы импортируем различные инструменты, которые нам нужны.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Гиперпараметры
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Среда
Среды в RL представляют собой задачу или проблему, которую мы пытаемся решить. Стандартные среды могут быть легко созданы в TF-агентах с использованием suites . У нас есть различные suites для загрузки среды из таких источников, как OpenAI тренажерный зал, Атари, DM управления и т.д., учитывая имя строки среды.
Теперь загрузим среду Minituar из пакета Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

В этой среде цель состоит в том, чтобы агент обучил политику, которая будет управлять роботом Minitaur и заставлять его двигаться вперед как можно быстрее. Эпизоды длятся 1000 шагов, и возврат будет суммой наград на протяжении всего эпизода.
Давайте посмотрим на информацию среда обеспечивает как observation , которое политика будет использовать для создания actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
Наблюдение довольно сложное. Мы получаем 28 значений, представляющих углы, скорости и крутящие моменты для всех двигателей. В свою очередь среда ожидает , 8 значения для действий между [-1, 1] . Это желаемые углы двигателя.
Обычно мы создаем две среды: одну для сбора данных во время обучения и одну для оценки. Среды написаны на чистом питоне и используют несколько массивов, которые напрямую использует Actor Learner API.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Стратегия распространения
Мы используем API DistributionStrategy, чтобы включить выполнение вычисления шага поезда на нескольких устройствах, таких как несколько графических процессоров или TPU, с использованием параллелизма данных. Шаг поезда:
- Получает пакет обучающих данных
- Распределяет его по устройствам
- Вычисляет шаг вперед
- Агрегирует и вычисляет СРЕДНЕЕ значение убытка.
- Вычисляет шаг назад и выполняет обновление градиентной переменной
С помощью TF-Agents Learner API и DistributionStrategy API довольно легко переключаться между запуском шага поезда на графических процессорах (с использованием MirroredStrategy) на TPU (с помощью TPUStrategy) без изменения какой-либо логики обучения ниже.
Включение графического процессора
Если вы хотите попробовать работать на графическом процессоре, вам сначала нужно включить графические процессоры для ноутбука:
- Перейдите в Edit → Notebook Settings.
- В раскрывающемся списке «Аппаратный ускоритель» выберите графический процессор.
Выбор стратегии
Используйте strategy_utils для создания стратегии. Под капотом передача параметра:
-
use_gpu = Falseвозвращаетсяtf.distribute.get_strategy(), который использует процессор -
use_gpu = Trueвозвращаетtf.distribute.MirroredStrategy(), который использует все графические процессоры, которые видны TensorFlow на одной машине
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Все переменные и агенты должны быть созданы под strategy.scope() , как вы увидите ниже.
Агент
Чтобы создать агента SAC, нам сначала нужно создать сети, которые он будет обучать. SAC - это агент-критик, поэтому нам понадобятся две сети.
Критик даст нам оценку значений для Q(s,a) . То есть он получит в качестве входных данных наблюдение и действие и даст нам оценку того, насколько хорошо это действие было для данного состояния.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Мы будем использовать эти критики , чтобы обучить actor сеть , которая позволит нам произвести действия , данные наблюдения.
ActorNetwork будет предсказывать параметры для Тань-сжато MultivariateNormalDiag распределения. Затем это распределение будет выбрано в зависимости от текущего наблюдения всякий раз, когда нам нужно сгенерировать действия.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Имея под рукой эти сети, мы можем создать экземпляр агента.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Буфер воспроизведения
Для того , чтобы отслеживать данные , собранные из окружающей среды, мы будем использовать Reverb , эффективный, расширяемый и простой в использовании системы воспроизведения с помощью Deepmind. В нем хранятся данные об опыте, собранные Актерами и потребленные Учащимся во время обучения.
В этом учебнике, это менее важно , чем max_size - но в распределенной установке с коллекцией асинхронной и обучением, вы, вероятно , хотите поэкспериментировать с rate_limiters.SampleToInsertRatio , используя samples_per_insert где - то между 2 и 1000. Например:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
Буфера воспроизведения строится с помощью функции , описывающие тензоры, которые должны быть сохранены, которые могут быть получены от агента с помощью tf_agent.collect_data_spec .
Поскольку САК агент необходим как текущий и следующее наблюдение для вычисления потерь, мы устанавливаем sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Теперь мы генерируем набор данных TensorFlow из буфера воспроизведения Reverb. Мы передадим это Учащемуся, чтобы он попробовал опыт для обучения.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Политики
В TF-агентов, политика представляют собой стандартное понятие политики в RL: дан time_step произвести действие или распределение по действиям. Основной метод policy_step = policy.step(time_step) где policy_step именованный кортеж PolicyStep(action, state, info) . policy_step.action этого action для применения в среду, state представляет собой состояние для сохраняющего состояния (РННЫ) политики и info может содержать вспомогательную информацию , такие как бревенчатые вероятности действий.
Агенты содержат две политики:
-
agent.policy- Основная политика , которая используется для оценки и развертывания. -
agent.collect_policy- Вторая политика , которая используется для сбора данных.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
Политики можно создавать независимо от агентов. Например, можно использовать tf_agents.policies.random_py_policy создать политику , которая будет случайным образом выбрать действие для каждого time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Актеры
Актер управляет взаимодействием между политикой и средой.
- Компоненты Actor содержит экземпляр среды (как
py_environment) и копию переменной политики. - Каждый работник Actor выполняет последовательность шагов по сбору данных с учетом локальных значений переменных политики.
- Переменные обновления сделаны явно с помощью переменного экземпляра контейнера клиента в тренировочном сценарии перед вызовом
actor.run(). - Наблюдаемый опыт записывается в буфер воспроизведения на каждом этапе сбора данных.
Когда Актеры выполняют шаги сбора данных, они передают траектории (состояние, действие, награда) наблюдателю, который кэширует и записывает их в систему воспроизведения Reverb.
Мы хранение траектории для кадров [(t0, t1) (t1, t2) (t2, t3), ...] , потому что stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Мы создаем Актера со случайной политикой и собираем опыт для заполнения буфера воспроизведения.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Создайте актера с политикой сбора, чтобы собрать больше опыта во время обучения.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Создайте Актера, который будет использоваться для оценки политики во время обучения. Переходим в actor.eval_metrics(num_eval_episodes) позже войти метрики.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
Учащиеся
Компонент Learner содержит агент и выполняет градиентные обновления переменных политики, используя данные опыта из буфера воспроизведения. После одного или нескольких шагов обучения обучающийся может отправить новый набор значений переменных в контейнер переменных.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Метрики и оценка
Мы инстанцирован в Eval Актер с actor.eval_metrics выше, что создает наиболее часто используемых показателей при оценке политики:
- Средняя доходность. Возврат - это сумма вознаграждений, полученных при выполнении политики в среде для эпизода, и мы обычно усредняем ее для нескольких эпизодов.
- Средняя продолжительность серии.
Мы запускаем Актера, чтобы сгенерировать эти показатели.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Проверьте модуль метрик для других стандартных реализаций различных метрик.
Обучение агента
Цикл обучения включает как сбор данных из среды, так и оптимизацию агентских сетей. Попутно мы будем время от времени оценивать политику агента, чтобы увидеть, как у нас дела.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
Визуализация
Сюжеты
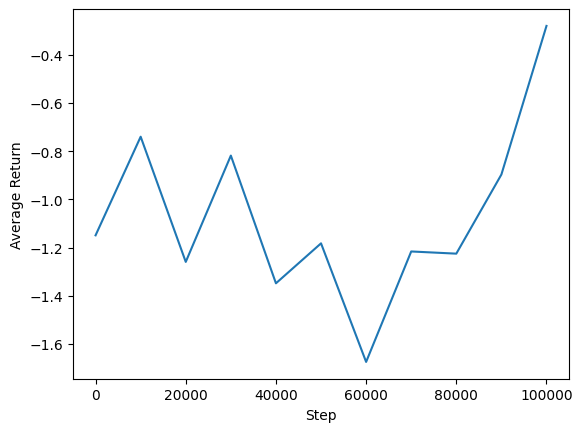
Мы можем построить график зависимости средней доходности от глобальных шагов, чтобы увидеть производительность нашего агента. В Minitaur функция награды основана на том , как далеко minitaur прогулки в 1000 шагов и наказывает расход энергии.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Видео
Полезно визуализировать производительность агента, визуализируя среду на каждом этапе. Прежде чем мы это сделаем, давайте сначала создадим функцию для встраивания видео в эту колабу.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Следующий код визуализирует политику агента для нескольких эпизодов:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)