
이 튜토리얼은 TensorFlow Lite를 사용하여 자연어 텍스트를 분류하는 Android 애플리케이션을 구축하는 방법을 여러분에게 보여줍니다. 이 애플리케이션은 실제 Android 기기를 위해 설계되었지만 기기 에뮬레이터에서도 실행이 가능합니다.
예제 애플리케이션은 TensorFlow Lite를 사용하여 텍스트를 긍정(positive) 또는 부정(negative)으로 분류하고, 자연어(NL)를 위한 작업 라이브러리를 사용해 텍스트 분류 머신러닝 모델을 실행할 수 있도록 합니다.
기존 프로젝트를 업데이트하는 중이라면 예제 애플리케이션을 참조 또는 템플릿으로 사용할 수 있습니다. 기존 애플리케이션에 텍스트 분류를 추가하는 방법에 대한 지침은 애플리케이션 업데이트 및 수정을 참조하세요.
텍스트 분류 개요
텍스트 분류는 일련의 사전 정의된 카테고리를 개방형 텍스트에 할당하는 머신러닝 작업입니다. 텍스트 분류 모델은 단어 또는 구절이 수동으로 분류된 자연어 텍스트 말뭉치에서 훈련됩니다.
훈련된 모델은 텍스트를 입력으로 받고 분류를 위해 훈련된 알려진 클래스의 집합에 따라 텍스트를 범주화하려고 합니다. 예를 들어, 예제의 모델은 텍스트의 (코드)조각을 받아들이고 텍스트의 감성이 긍정(positive)인지 부정(negative)인지 결정합니다. 각 텍스트 (코드)조각의 경우, 텍스트 분류 모델은 긍정(positive) 또는 부정(negative)으로 텍스트가 올바르게 분류되었는지 신뢰도를 나타내는 점수를 출력합니다.
이 튜토리얼의 모델이 만들어진 방법에 대한 더 자세한 정보는 TensorFlow Lite Model Maker를 이용한 텍스트 분류를 참조하세요.
모델 및 데이터세트
이 튜토리얼은 SST-2(Stanford Sentiment Treebank) 데이터세트를 사용해 훈련된 모델을 사용합니다. SST-2에는 각 리뷰가 긍정(positive) 또는 부정(negative)으로 범주화된 훈련을 위한 67,349개의 영화 리뷰와 테스트를 위한 872개의 영화 리뷰가 있습니다. 이 앱에 사용된 모델은 TensorFlow Lite Model Maker 도구를 사용해 훈련되었습니다.
예제 애플리케이션은 다음과 같은 사전 훈련된 모델을 사용합니다.
Average Word Vector (
NLClassifier) - 작업 라이브러리의NLClassifier는 입력 텍스트를 여러 범주로 분류하며 대부분의 텍스트 분류 모델을 다룰 수 있습니다.MobileBERT (
BertNLClassifier) - 작업 라이브러리의BertNLClassifier는 NLClassifier와 유사하지만, 철자 외 Wordpiece및 Sentencepiece 토큰화가 필요한 경우에 맞춰 만들어졌습니다.
설치 및 예제 앱 실행
텍스트 분류 애플리케이션을 설치하려면 GitHub에서 예제 앱을 다운로드하고 Android Studio를 사용하여 실행합니다.
시스템 요구 사항
- Android Studio 버전 2021.1.1(Bumblebee) 이상
- Android SDK 버전 31 이상
- 개발자 모드가 활성화된 상태로 최소 OS 버전의 SDK 21(Android 7.0 - Nougat)가 설치된 Android 기기 또는 Android Emulator.
예제 코드 가져오기
예제 코드의 로컬 복사본을 만듭니다. 이 코드를 사용하여 Android Studio에서 프로젝트를 만들고 예제 애플리케이션을 실행합니다.
예제 코드를 복제하고 설정하려면:
- git 리포지토리를 복제합니다.
git clone https://github.com/tensorflow/examples.git - 선택적으로, 스파스 체크아웃을 사용하도록 git 인스턴스를 구성합니다. 그러면 텍스트 분류 예제 앱에 대한 파일만 남게 됩니다.
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
프로젝트 가져오기 및 실행하기
다운로드한 예제 코드에서 프로젝트를 생성하고 프로젝트를 빌드한 후 실행합니다.
예제 코드 프로젝트를 가져오고 빌드하려면:
- Android Studio를 시작합니다.
- Android 스튜디오에서 File(파일) > New(새로 만들기) > Import Project(프로젝트 가져오기)를 선택합니다.
- build.gradle 파일(
.../examples/lite/examples/text_classification/android/build.gradle)이 포함된 예제 코드 디렉터리로 이동하여 해당 디렉터리를 선택합니다. - Android Studio에서 Gradle 동기화를 요청하면 OK(확인)를 선택합니다.
- Android 기기가 컴퓨터에 연결되어 있고 개발자 모드가 활성화되어 있는지 확인합니다. 녹색
Run화살표를 클릭합니다.
올바른 디렉터리를 선택하면 Android Studio에서 새 프로젝트를 만들고 빌드합니다. 이 프로세스는 컴퓨터 속도와 다른 프로젝트에 Android Studio를 사용했는지 여부에 따라 몇 분이 소요될 수 있습니다. 빌드가 완료되면 Android Studio가 빌드 출력 상태 패널에 BUILD SUCCESSFUL 메시지를 표시합니다.
프로젝트를 실행하려면:
- Android Studio에서 Run(실행) > Run(실행)…을 선택하여 프로젝트를 실행합니다.
- 연결된 Android 기기(또는 에뮬레이터)를 선택하여 앱을 테스트합니다.
애플리케이션 사용하기
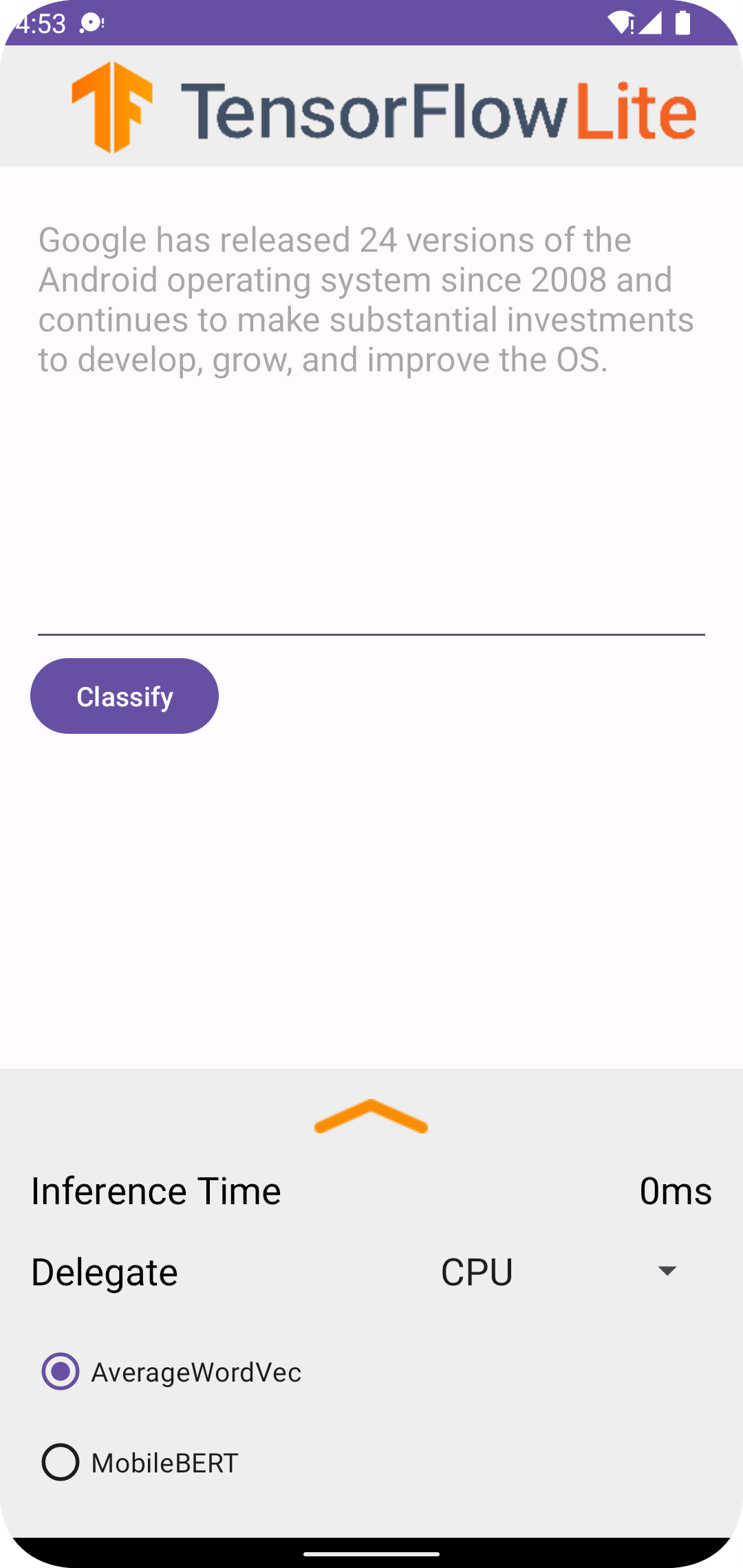
Android Studio에서 프로젝트를 실행한 후, 애플리케이션은 연결된 기기 또는 기기 에뮬레이터에서 자동으로 열립니다.
텍스트 분류자를 사용하려면 다음을 수행합니다.
- 텍스트 상자의 텍스트 (코드) 조각을 입력하세요.
- Delegate(대리자) 드롭다운에서
CPU또는NNAPI를 선택하세요. AverageWordVec또는MobileBERT를 선택하여 모델을 지정합니다.- Classify(분류)를 선택하세요.
애플리케이션은 긍정(positive) 점수와 부정(negative) 점수를 출력합니다. 이러한 두 점수는 합계가 1이 되며 입력 텍스트의 감정이 긍정(positive) 또는 부정(negative)인지 가능성을 측정합니다. 높은 숫자는 신뢰도 수준이 높다는 것을 의미합니다.
이제 작동하는 텍스트 분류 애플리케이션이 있습니다. 예제 애플리케이션이 작동하는 방법과 텍스트 분류 기능을 여러분의 프로덕션 애플리케이션에 구현하는 방법에 대해 더 잘 이해하기 위해 다음 섹션을 사용하세요.
애플리케이션 작동 방법 - 예제 애플리케이션의 전체 구조 및 주요 파일에 대한 간략한 설명입니다.
애플리케이션 수정 - 기존의 애플리케이션에 텍스트 분류를 추가하는 것에 대한 지침입니다.
예재 앱 작동 방법
애플리케이션은 자연어(NL)를 위한 작업 라이브러리를 사용하여 텍스트 분류 모델을 구현합니다. Average Word Vector와 MobileBERT 두 모델은 TensorFlow Lite Model Maker를 사용해 훈련되었습니다. 애플리케이션은 NNAPI 대리자를 사용하는 하드웨어 가속 옵션을 통해 기본으로 CPU에서 실행됩니다.
다음 파일과 디렉터리는 이 텍스트 분류 애플리케이션을 위한 주요 코드를 포함합니다.
- TextClassificationHelper.kt - 텍스트 분류자를 초기화하고 모델 및 대리자 선택을 처리합니다.
- MainActivity.kt -
TextClassificationHelper및ResultsAdapter호출을 포함하여 애플리케이션을 구현합니다. - ResultsAdapter.kt - 결과를 처리하고 포맷합니다.
애플리케이션 수정
다음 섹션은 예제 앱에 표시된 모델을 실행하도록 자신의 Android 앱을 수정하는 주요 단계를 설명합니다. 이러한 지침은 예제 앱을 참조 포인트로 사용합니다. 자신의 앱에 필요한 특정 변경 사항은 예제 앱과 다를 수 있습니다.
Android 프로젝트 열기 또는 만들기
나머지 지침을 따르려면 Android Studio의 Android 개발 프로젝트가 필요합니다. 아래 지침을 따라 기존의 프로젝트를 열거나 새로운 프로젝트를 만드세요.
기존 Android 개발 프로젝트 열기
- Android Studio에서 File(파일) > Open(열기)를 선택하고 기존 프로젝트를 선택합니다.
기본 Android 개발 프로젝트 만들기
- Android Studio의 지침을 따라 기본 프로젝트를 만듭니다.
Android Studio를 사용에 대한 더 자세한 정보는 Android Studio 설명서를 참조하세요.
프로젝트 종속성 추가
자신의 애플리케이션에서 TensorFlow Lite 머신 러닝 모델을 실행하고 문자열과 같은 데이터를 사용 중인 모델에서 처리할 수 있는 텐서 데이터 형식으로 변환하는 유틸리티 기능에 액세스하려면 특정 프로젝트 종속성을 추가해야 합니다.
다음 지침은 필요한 프로젝트 및 모듈 종속성을 자신의 Android 앱 프로젝트에 추가하는 방법을 설명합니다.
모듈 종속성을 추가하려면:
TensorFlow Lite를 사용하는 모듈에서 모듈의
build.gradle파일을 다음 종속성을 포함하도록 업데이트하세요.예제 애플리케이션에서, 종속성은 app/build.gradle에 있습니다.
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }프로젝트는 텍스트 작업 라이브러리(
tensorflow-lite-task-text)를 포함해야 합니다.이 앱을 그래픽 처리 장치(GPU)가 실행되도록 수정하려면, GPU 라이브러리(
tensorflow-lite-gpu-delegate-plugin)는 GPU에서 앱을 실행할 수 있는 인프라를 제공하고 대리자(tensorflow-lite-gpu)는 호환성 목록을 제공합니다. GPU에서 이 앱을 실행하는 것은 이 튜토리얼 범위를 넘어섭니다.Android Studio에서 File(파일) > Sync Project with Gradle Files(프로젝트를 Gradle 파일과 동기화)를 선택하여 프로젝트 종속성을 동기화합니다.
ML 모델 초기화하기
Android 앱에서, 모델로 예측을 실행하기 전에 매개변수를 사용해 TensorFlow Lite 머신러닝 모델을 초기화해야 합니다.
TensorFlow Lite 모델은 *.tflite 파일로 저장됩니다. 모델 파일은 예측 논리가 포함되며 일반적으로 예측 클래스 이름과 같은 예측 결과를 해석하는 방법에 대한 메타데이터가 포함됩니다. 일반적으로, 모델 파일은 코드 예제와 같이 개발 프로젝트의 src/main/assets 디렉터리에 저장됩니다.
<project>/src/main/assets/mobilebert.tflite<project>/src/main/assets/wordvec.tflite
참고: 예제 앱은 [download_model.gradle](https://github.com/tensorflow/examples/blob/master/lite/examples/text_classification/android/app/download_model.gradle) 파일을 사용하여 구축 시 Average Word Vector와 MobileBERT 모델을 다운로드합니다. 이 접근 방법은 프로덕션 앱에 필요하지 않거나 권장되지 않습니다.
편의와 코드 가독성을 위해 이 예제에서는 모델에 대한 설정을 정의하는 컴패니언 객체를 선언합니다.
앱에서 모델을 초기화하려면:
동반 객체를 만들어 모델에 대한 설정을 정의하세요. 예제 애플리케이션에서 이 객체는 TextClassificationHelper.kt에 있습니다.
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }분류자 객체를 구축해 모델에 대한 설정을 만들고
BertNLClassifier또는NLClassifier를 사용하여 TensorFlow Lite 객체를 구성합니다.예제 애플리케이션에서, 이것은 TextClassificationHelper.kt의
initClassifier함수에 있습니다.fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }참고: 텍스트 분류를 사용하는 대부분의 프로덕션 앱은
BertNLClassifier또는NLClassifier를 사용합니다(두 가지 모두는 아님).
하드웨어 가속 사용(선택 사항)
앱에서 TensorFlow Lite 모델을 초기화할 때 하드웨어 가속 기능을 사용하여 모델의 예측 계산 속도를 높이는 것을 고려해야 합니다. TensorFlow Lite 대리자는 GPU(그래픽 처리 장치) 또는 TPU(텐서 처리 장치)와 같은 모바일 장치의 특수 처리 하드웨어를 사용하여 머신 러닝 모델의 실행을 가속하는 소프트웨어 모듈입니다.
앱에서 하드웨어 가속 사용하기
변수를 만들어 애플리케이션이 사용할 대리자를 정의하세요. 예제 애플리케이션에서, 이 변수는 TextClassificationHelper.kt의 초기에 있습니다.
var currentDelegate: Int = 0대리자 선택자를 만듭니다. 예제 애플리케이션에서, 대리자 선택자는 TextClassificationHelper.kt의
initClassifier함수에 있습니다.val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
참고: 이 앱을 수정하여 GPU 대리자를 사용하는 것은 가능하지만 이 방법은 분류자를 사용하는 같은 스레드에서 생성된 분류자가 필요합니다. 이것은 이 튜토리얼의 범위에서 벗어납니다.
TensorFlow Lite 모델 실행에 대리자를 사용하는 것이 권장되지만 필수는 아닙니다. TensorFlow Lite에서 대리자를 사용하는 방법에 대한 자세한 내용은 TensorFlow Lite 대리자를 참조하세요.
모델에 대한 데이터 준비하기
Android 앱에서 코드는 로우 텍스트와 같은 기존 데이터를 모델에서 처리할 수 있는 텐서 데이터 형식으로 변환하여 해석을 수행할 수 있게 모델에 데이터를 제공합니다. 모델로 전달되는 텐서의 데이터에는 모델 훈련에 사용되는 데이터 형식과 일치하는 특정 차원 또는 형상이 있어야 합니다.
이 텍스트 분류 앱은 입력으로 문자열을 받아들이고 모델은 영어 말뭉치에서 전적으로 훈련됩니다. 특수 문자와 비영어 단어는 추론 중 무시됩니다.
모델에 텍스트 데이터 제공하기
initClassifier함수가 ML 모델 초기화 및 하드웨어 가속 사용 섹션에서 설명된 대로 대리자와 모델에 대한 코드를 포함하도록 합니다.init블록을 사용해initClassifier함수를 호출합니다. 예제 애플리케이션에서,init은 TextClassificationHelper.kt에 있습니다.init { initClassifier() }
예측 실행하기
Android 앱에서, BertNLClassifier 또는 NLClassifier 객체를 실행하면 모델에 입력 텍스트를 입력하기 시작하여 "긍정(positive)" 또는 "부정(negative)"으로 모델을 범주화할 수 있습니다.
예측 실행하기
선택된 분류자 (
currentModel)을 사용하고 입력 텍스트를 분류하는 데 걸린 시간(inferenceTime)을 측정하는classify함수를 만드세요. 예제 애플리케이션에서,classify함수는 TextClassificationHelper.kt에 있습니다.fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }classify의 결과를 리스너 객체로 전달하세요.fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
모델 출력 처리하기
텍스트 줄을 입력하면, 모델은 '긍정(positive)'과 '부정(negative)' 범주로 0과 1 사이에서 부동으로 표현하는 예측 점수를 생성합니다.
모델에서 예측 결과를 얻으려면:
리스너 객체애 대한
onResult함수를 만들어 출력을 처리하세요. 예제 애플리케이션에서 리스너 객체는 MainActivity.kt에 있습니다private val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }오류를 처리하기 위해
onError함수를 리스너 객체에 다음과 같이 추가합니다.private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
모델이 일련의 예측 결과를 반환하면 애플리케이션은 결과를 사용자에게 제공하거나 추가 논리를 실행하여 이러한 예측에 따라 조치를 취할 수 있습니다. 예제 애플리케이션은 사용자 인터페이스에서 예측 점수를 나열합니다.
다음 단계
- TensorFlow Lite Model Maker를 이용한 텍스트 분류 튜토리얼을 통해 처음부터 모델을 훈련하고 구현하세요.
- TensorFlow를 위한 텍스트 처리 도구를 더 살펴봅니다.
- TensorFlow Hub에서 기타 BERT 모델을 다운로드합니다.
- 예제에서 TensorFlow Lite의 다양한 용도를 살펴봅니다.
- 모델 섹션에서 TensorFlow Lite와 함께 머신 러닝 모델을 사용하는 방법에 대해 자세히 알아봅니다.
- TensorFlow Lite 개발자 가이드에서 모바일 애플리케이션에서 머신 러닝을 구현하는 방법에 대해 자세히 알아봅니다.