
| |
Introdução
Grandes modelos de linguagem (LLMs) são uma classe de modelos de aprendizado de máquina treinados para gerar texto com base em grandes conjuntos de dados. Eles podem ser usados para tarefas de processamento de linguagem natural (PNL), incluindo geração de texto, resposta a perguntas e tradução automática. Eles são baseados na arquitetura Transformer e são treinados em grandes quantidades de dados de texto, muitas vezes envolvendo bilhões de palavras. Mesmo LLMs de menor escala, como o GPT-2, podem ter um desempenho impressionante. A conversão de modelos do TensorFlow em um modelo mais leve, rápido e de baixo consumo de energia nos permite executar modelos generativos de IA no dispositivo, com benefícios de melhor segurança do usuário, pois os dados nunca sairão do dispositivo.
Este runbook mostra como criar um aplicativo Android com TensorFlow Lite para executar um Keras LLM e fornece sugestões para otimização de modelo usando técnicas de quantização, que de outra forma exigiriam uma quantidade muito maior de memória e maior poder computacional para serem executadas.
Abrimos o código-fonte de nossa estrutura de aplicativo Android à qual qualquer TFLite LLMs compatível pode ser conectado. Aqui estão duas demonstrações:
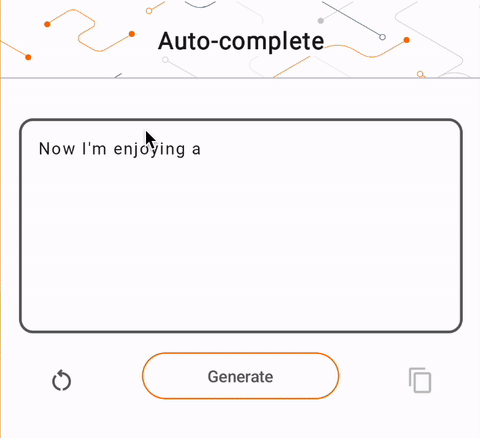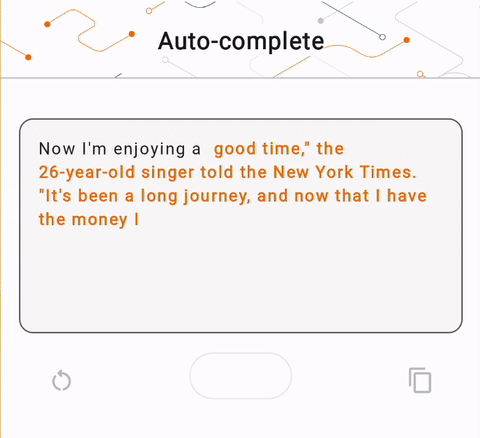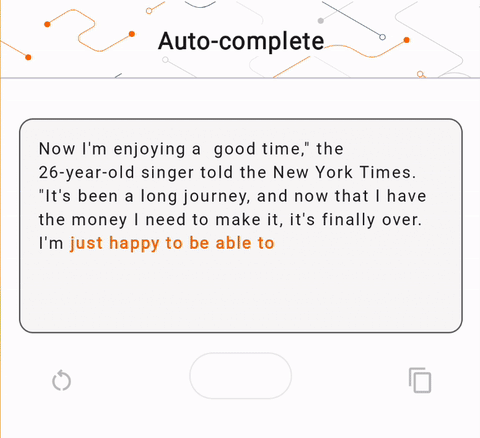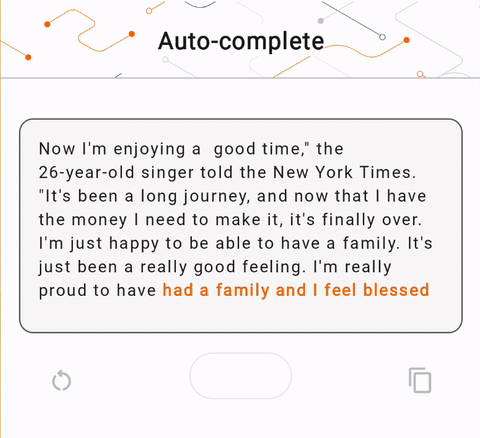
- Na Figura 1, usamos um modelo Keras GPT-2 para realizar tarefas de preenchimento de texto no dispositivo.
- Na Figura 2, convertemos uma versão do modelo PaLM ajustado por instrução (1,5 bilhão de parâmetros) para TFLite e executamos através do tempo de execução do TFLite.
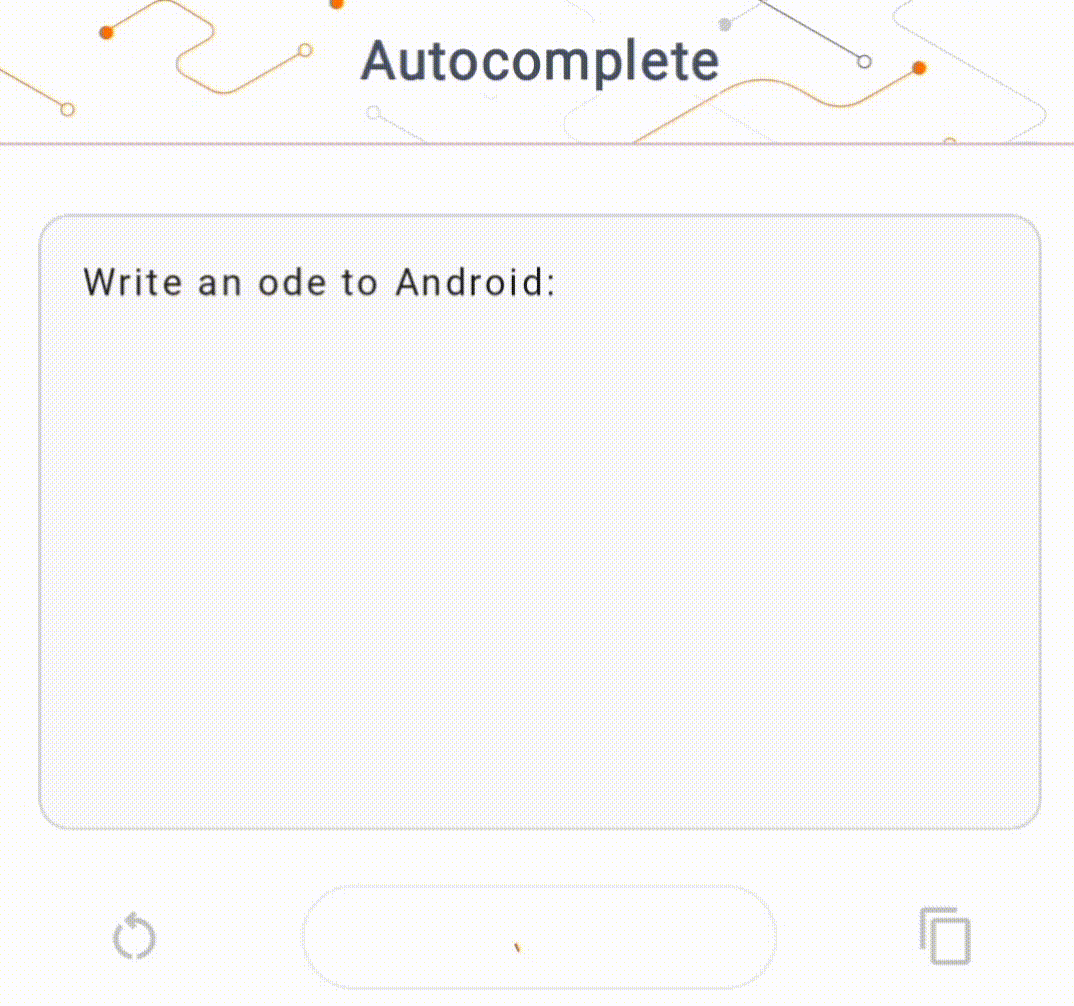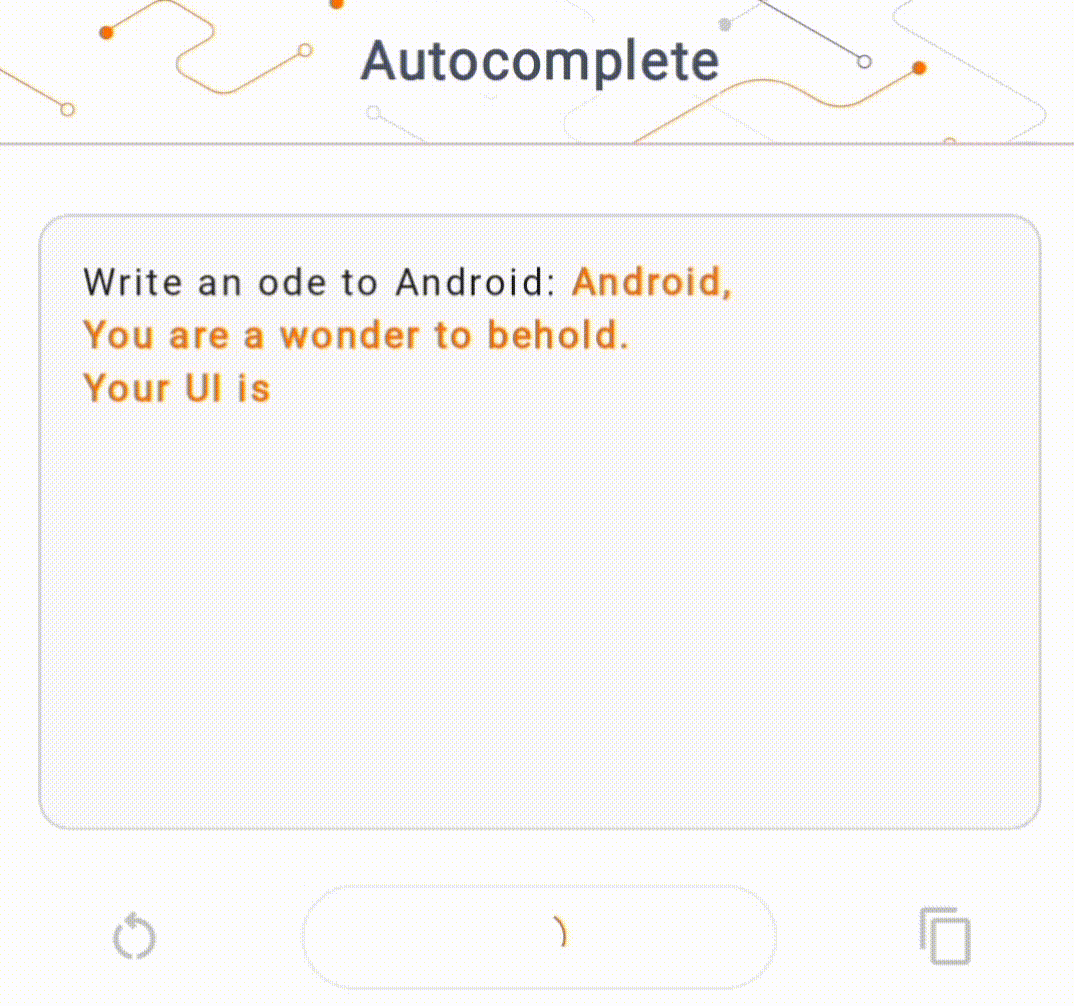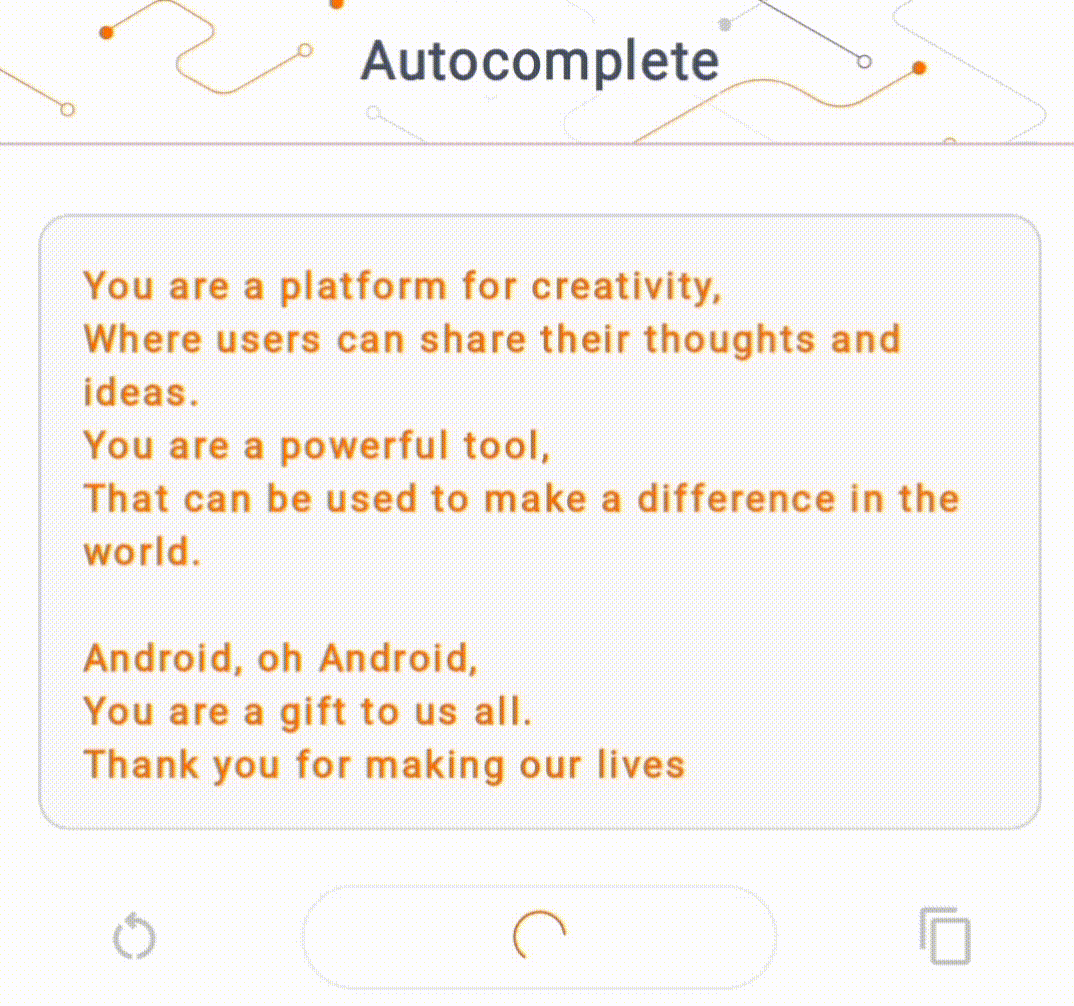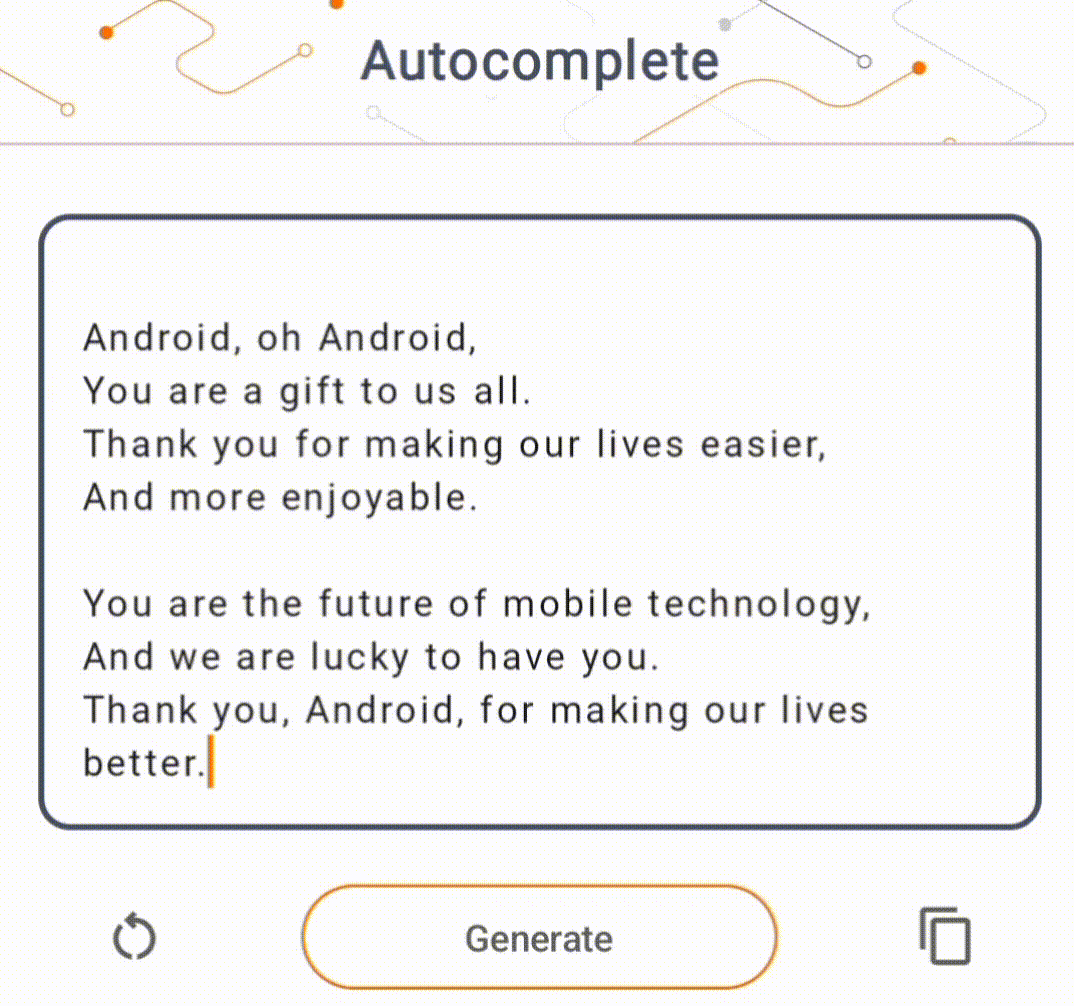
Guias
Autoria de modelo
Para esta demonstração, usaremos KerasNLP para obter o modelo GPT-2. KerasNLP é uma biblioteca que contém modelos pré-treinados de última geração para tarefas de processamento de linguagem natural e pode oferecer suporte aos usuários durante todo o ciclo de desenvolvimento. Você pode ver a lista de modelos disponíveis no repositório KerasNLP . Os fluxos de trabalho são construídos a partir de componentes modulares que possuem arquiteturas e pesos predefinidos de última geração quando usados imediatamente e são facilmente personalizáveis quando é necessário mais controle. A criação do modelo GPT-2 pode ser feita com as seguintes etapas:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Um ponto em comum entre essas três linhas de código é o método from_preset() , que instanciará a parte da API Keras a partir de uma arquitetura e/ou pesos predefinidos, carregando assim o modelo pré-treinado. A partir deste trecho de código, você também notará três componentes modulares:
Tokenizer : converte uma entrada de string bruta em IDs de token inteiros adequados para uma camada Keras Embedding. GPT-2 usa especificamente o tokenizer de codificação de pares de bytes (BPE).
Pré-processador : camada para tokenizar e empacotar entradas a serem alimentadas em um modelo Keras. Aqui, o pré-processador preencherá o tensor de IDs de token até um comprimento especificado (256) após a tokenização.
Backbone : Modelo Keras que segue a arquitetura de backbone do transformador SoTA e possui os pesos predefinidos.
Além disso, você pode conferir a implementação completa do modelo GPT-2 no GitHub .
Conversão de modelo
TensorFlow Lite é uma biblioteca móvel para implantação de métodos em dispositivos móveis, microcontroladores e outros dispositivos de borda. A primeira etapa é converter um modelo Keras para um formato TensorFlow Lite mais compacto usando o conversor TensorFlow Lite e, em seguida, usar o interpretador TensorFlow Lite, que é altamente otimizado para dispositivos móveis, para executar o modelo convertido.
 Comece com a função
Comece com a função generate() do GPT2CausalLM que realiza a conversão. Envolva a função generate() para criar uma função TensorFlow concreta:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Observe que você também pode usar from_keras_model() do TFLiteConverter para realizar a conversão.
Agora defina uma função auxiliar que executará inferência com uma entrada e um modelo TFLite. As operações de texto do TensorFlow não são operações integradas no tempo de execução do TFLite, portanto, você precisará adicionar essas operações personalizadas para que o intérprete faça inferências neste modelo. Esta função auxiliar aceita uma entrada e uma função que realiza a conversão, nomeadamente a função generator() definida acima.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Você pode converter o modelo agora:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Quantização
O TensorFlow Lite implementou uma técnica de otimização chamada quantização , que pode reduzir o tamanho do modelo e acelerar a inferência. Através do processo de quantização, os floats de 32 bits são mapeados para inteiros menores de 8 bits, reduzindo assim o tamanho do modelo por um fator de 4 para uma execução mais eficiente em hardwares modernos. Existem várias maneiras de fazer quantização no TensorFlow. Você pode visitar as páginas de otimização do modelo TFLite e do TensorFlow Model Optimization Toolkit para obter mais informações. Os tipos de quantizações são explicados brevemente abaixo.
Aqui, você usará a quantização de faixa dinâmica pós-treinamento no modelo GPT-2 definindo o sinalizador de otimização do conversor como tf.lite.Optimize.DEFAULT e o restante do processo de conversão será o mesmo detalhado anteriormente. Testamos que com esta técnica de quantização a latência é de cerca de 6,7 segundos no Pixel 7 com comprimento máximo de saída definido como 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Faixa Dinâmica
A quantização de faixa dinâmica é o ponto de partida recomendado para otimizar modelos no dispositivo. Ele pode atingir uma redução de cerca de 4x no tamanho do modelo e é um ponto de partida recomendado, pois fornece uso reduzido de memória e computação mais rápida sem a necessidade de fornecer um conjunto de dados representativo para calibração. Este tipo de quantização quantiza estaticamente apenas os pesos do ponto flutuante para o número inteiro de 8 bits no momento da conversão.
FP16
Os modelos de ponto flutuante também podem ser otimizados quantizando os pesos para o tipo float16. As vantagens da quantização float16 são reduzir o tamanho do modelo em até metade (já que todos os pesos ficam com metade do seu tamanho), causando perda mínima de precisão e suportando delegados de GPU que podem operar diretamente nos dados float16 (o que resulta em computação mais rápida do que em float32 dados). Um modelo convertido para pesos float16 ainda pode ser executado na CPU sem modificações adicionais. Os pesos float16 são aumentados para float32 antes da primeira inferência, o que permite uma redução no tamanho do modelo em troca de um impacto mínimo na latência e na precisão.
Quantização Inteira Completa
A quantização de inteiros completos converte os números de ponto flutuante de 32 bits, incluindo pesos e ativações, para os inteiros de 8 bits mais próximos. Esse tipo de quantização resulta em um modelo menor com maior velocidade de inferência, o que é extremamente valioso ao usar microcontroladores. Este modo é recomendado quando as ativações são sensíveis à quantização.
Integração de aplicativos Android
Você pode seguir este exemplo do Android para integrar seu modelo TFLite em um aplicativo Android.
Pré-requisitos
Se ainda não o fez, instale o Android Studio , seguindo as instruções do site.
- Android Studio 2022.2.1 ou superior.
- Um dispositivo Android ou emulador de Android com mais de 4G de memória
Construindo e executando com Android Studio
- Abra o Android Studio e, na tela de boas-vindas, selecione Abrir um projeto existente do Android Studio .
- Na janela Abrir arquivo ou projeto que aparece, navegue e selecione o diretório
lite/examples/generative_ai/androidde onde você clonou o repositório GitHub de amostra do TensorFlow Lite. - Você também pode precisar instalar várias plataformas e ferramentas de acordo com as mensagens de erro.
- Renomeie o modelo .tflite convertido para
autocomplete.tflitee copie-o para a pastaapp/src/main/assets/. - Selecione o menu Construir -> Criar Projeto para construir o aplicativo. (Ctrl+F9, dependendo da sua versão).
- Clique no menu Executar -> Executar 'app' . (Shift+F10, dependendo da sua versão)
Alternativamente, você também pode usar o gradle wrapper para construí-lo na linha de comando. Consulte a documentação do Gradle para obter mais informações.
(Opcional) Construindo o arquivo .aar
Por padrão, o aplicativo baixa automaticamente os arquivos .aar necessários. Mas se você quiser criar o seu próprio, mude para app/libs/build_aar/ pasta run ./build_aar.sh . Este script extrairá as operações necessárias do TensorFlow Text e criará o aar para operadores Select TF.
Após a compilação, um novo arquivo tftext_tflite_flex.aar é gerado. Substitua o arquivo .aar na pasta app/libs/ e reconstrua o aplicativo.
Observe que você ainda precisa incluir o aar tensorflow-lite padrão em seu arquivo gradle.
Tamanho da janela de contexto
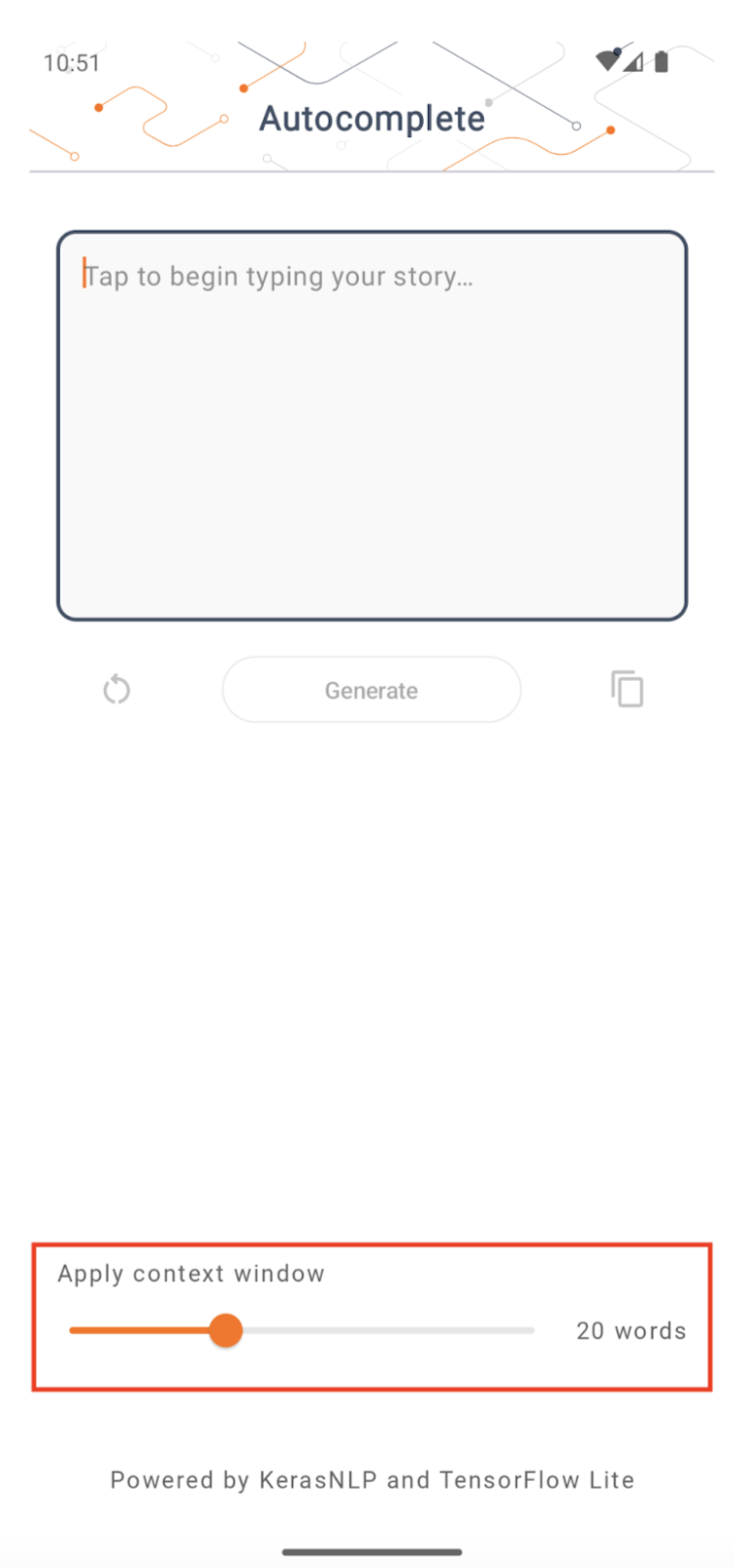
O aplicativo tem um parâmetro alterável 'tamanho da janela de contexto', que é necessário porque os LLMs hoje geralmente têm um tamanho de contexto fixo que limita quantas palavras/tokens podem ser inseridos no modelo como 'prompt' (observe que 'palavra' não é necessariamente equivalente a 'token' neste caso, devido aos diferentes métodos de tokenização). Este número é importante porque:
- Definindo-o como muito pequeno, o modelo não terá contexto suficiente para gerar resultados significativos
- Definindo-o muito grande, o modelo não terá espaço suficiente para trabalhar (já que a sequência de saída inclui o prompt)
Você pode experimentar, mas configurá-lo para aproximadamente 50% do comprimento da sequência de saída é um bom começo.
Segurança e IA responsável
Conforme observado no anúncio original do OpenAI GPT-2 , existem advertências e limitações notáveis com o modelo GPT-2. Na verdade, os LLMs hoje geralmente enfrentam alguns desafios bem conhecidos, como alucinações, justiça e preconceito; isso ocorre porque esses modelos são treinados em dados do mundo real, o que os faz refletir questões do mundo real.
Este codelab foi criado apenas para demonstrar como criar um aplicativo com tecnologia LLMs com ferramentas do TensorFlow. O modelo produzido neste codelab é apenas para fins educacionais e não se destina ao uso em produção.
O uso da produção do LLM requer uma seleção criteriosa de conjuntos de dados de treinamento e mitigações de segurança abrangentes. Uma dessas funcionalidades oferecidas neste aplicativo Android é o filtro de palavrões, que rejeita entradas de usuário ou saídas de modelo incorretas. Se qualquer linguagem inadequada for detectada, o aplicativo rejeitará essa ação. Para saber mais sobre IA responsável no contexto de LLMs, assista à sessão técnica Desenvolvimento seguro e responsável com modelos de linguagem generativa no Google I/O 2023 e confira o Kit de ferramentas de IA responsável .