
 View source on GitHub
View source on GitHubIn this notebook-based tutorial, we will create and run TFX pipelines to validate input data and create an ML model. This notebook is based on the TFX pipeline we built in Simple TFX Pipeline Tutorial. If you have not read that tutorial yet, you should read it before proceeding with this notebook.
The first task in any data science or ML project is to understand and clean the data, which includes:
- Understanding the data types, distributions, and other information (e.g., mean value, or number of uniques) about each feature
- Generating a preliminary schema that describes the data
- Identifying anomalies and missing values in the data with respect to given schema
In this tutorial, we will create two TFX pipelines.
First, we will create a pipeline to analyze the dataset and generate a
preliminary schema of the given dataset. This pipeline will include two new
components, StatisticsGen and SchemaGen.
Once we have a proper schema of the data, we will create a pipeline to train
an ML classification model based on the pipeline from the previous tutorial.
In this pipeline, we will use the schema from the first pipeline and a
new component, ExampleValidator, to validate the input data.
The three new components, StatisticsGen, SchemaGen and ExampleValidator, are TFX components for data analysis and validation, and they are implemented using the TensorFlow Data Validation library.
Please see Understanding TFX Pipelines to learn more about various concepts in TFX.
Set Up
We first need to install the TFX Python package and download the dataset which we will use for our model.
Upgrade Pip
To avoid upgrading Pip in a system when running locally, check to make sure that we are running in Colab. Local systems can of course be upgraded separately.
try:
import colab
!pip install --upgrade pip
except:
pass
Install TFX
pip install -U tfxDid you restart the runtime?
If you are using Google Colab, the first time that you run the cell above, you must restart the runtime by clicking above "RESTART RUNTIME" button or using "Runtime > Restart runtime ..." menu. This is because of the way that Colab loads packages.
Check the TensorFlow and TFX versions.
import tensorflow as tf
print('TensorFlow version: {}'.format(tf.__version__))
from tfx import v1 as tfx
print('TFX version: {}'.format(tfx.__version__))
2024-05-08 09:36:04.670322: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-05-08 09:36:04.670389: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-05-08 09:36:04.671916: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered TensorFlow version: 2.15.1 TFX version: 1.15.0
Set up variables
There are some variables used to define a pipeline. You can customize these variables as you want. By default all output from the pipeline will be generated under the current directory.
import os
# We will create two pipelines. One for schema generation and one for training.
SCHEMA_PIPELINE_NAME = "penguin-tfdv-schema"
PIPELINE_NAME = "penguin-tfdv"
# Output directory to store artifacts generated from the pipeline.
SCHEMA_PIPELINE_ROOT = os.path.join('pipelines', SCHEMA_PIPELINE_NAME)
PIPELINE_ROOT = os.path.join('pipelines', PIPELINE_NAME)
# Path to a SQLite DB file to use as an MLMD storage.
SCHEMA_METADATA_PATH = os.path.join('metadata', SCHEMA_PIPELINE_NAME,
'metadata.db')
METADATA_PATH = os.path.join('metadata', PIPELINE_NAME, 'metadata.db')
# Output directory where created models from the pipeline will be exported.
SERVING_MODEL_DIR = os.path.join('serving_model', PIPELINE_NAME)
from absl import logging
logging.set_verbosity(logging.INFO) # Set default logging level.
Prepare example data
We will download the example dataset for use in our TFX pipeline. The dataset we are using is Palmer Penguins dataset which is also used in other TFX examples.
There are four numeric features in this dataset:
- culmen_length_mm
- culmen_depth_mm
- flipper_length_mm
- body_mass_g
All features were already normalized to have range [0,1]. We will build a
classification model which predicts the species of penguins.
Because the TFX ExampleGen component reads inputs from a directory, we need to create a directory and copy the dataset to it.
import urllib.request
import tempfile
DATA_ROOT = tempfile.mkdtemp(prefix='tfx-data') # Create a temporary directory.
_data_url = 'https://raw.githubusercontent.com/tensorflow/tfx/master/tfx/examples/penguin/data/labelled/penguins_processed.csv'
_data_filepath = os.path.join(DATA_ROOT, "data.csv")
urllib.request.urlretrieve(_data_url, _data_filepath)
('/tmpfs/tmp/tfx-dataj_6ovg52/data.csv',
<http.client.HTTPMessage at 0x7ff39cac30a0>)
Take a quick look at the CSV file.
head {_data_filepath}species,culmen_length_mm,culmen_depth_mm,flipper_length_mm,body_mass_g 0,0.2545454545454545,0.6666666666666666,0.15254237288135594,0.2916666666666667 0,0.26909090909090905,0.5119047619047618,0.23728813559322035,0.3055555555555556 0,0.29818181818181805,0.5833333333333334,0.3898305084745763,0.1527777777777778 0,0.16727272727272732,0.7380952380952381,0.3559322033898305,0.20833333333333334 0,0.26181818181818167,0.892857142857143,0.3050847457627119,0.2638888888888889 0,0.24727272727272717,0.5595238095238096,0.15254237288135594,0.2569444444444444 0,0.25818181818181823,0.773809523809524,0.3898305084745763,0.5486111111111112 0,0.32727272727272727,0.5357142857142859,0.1694915254237288,0.1388888888888889 0,0.23636363636363636,0.9642857142857142,0.3220338983050847,0.3055555555555556
You should be able to see five feature columns. species is one of 0, 1 or 2,
and all other features should have values between 0 and 1. We will create a TFX
pipeline to analyze this dataset.
Generate a preliminary schema
TFX pipelines are defined using Python APIs. We will create a pipeline to generate a schema from the input examples automatically. This schema can be reviewed by a human and adjusted as needed. Once the schema is finalized it can be used for training and example validation in later tasks.
In addition to CsvExampleGen which is used in
Simple TFX Pipeline Tutorial,
we will use StatisticsGen and SchemaGen:
- StatisticsGen calculates statistics for the dataset.
- SchemaGen examines the statistics and creates an initial data schema.
See the guides for each component or TFX components tutorial to learn more on these components.
Write a pipeline definition
We define a function to create a TFX pipeline. A Pipeline object
represents a TFX pipeline which can be run using one of pipeline
orchestration systems that TFX supports.
def _create_schema_pipeline(pipeline_name: str,
pipeline_root: str,
data_root: str,
metadata_path: str) -> tfx.dsl.Pipeline:
"""Creates a pipeline for schema generation."""
# Brings data into the pipeline.
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# NEW: Computes statistics over data for visualization and schema generation.
statistics_gen = tfx.components.StatisticsGen(
examples=example_gen.outputs['examples'])
# NEW: Generates schema based on the generated statistics.
schema_gen = tfx.components.SchemaGen(
statistics=statistics_gen.outputs['statistics'], infer_feature_shape=True)
components = [
example_gen,
statistics_gen,
schema_gen,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components)
Run the pipeline
We will use LocalDagRunner as in the previous tutorial.
tfx.orchestration.LocalDagRunner().run(
_create_schema_pipeline(
pipeline_name=SCHEMA_PIPELINE_NAME,
pipeline_root=SCHEMA_PIPELINE_ROOT,
data_root=DATA_ROOT,
metadata_path=SCHEMA_METADATA_PATH))
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Using deployment config:
executor_specs {
key: "CsvExampleGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.example_gen.csv_example_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "SchemaGen"
value {
python_class_executable_spec {
class_path: "tfx.components.schema_gen.executor.Executor"
}
}
}
executor_specs {
key: "StatisticsGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.statistics_gen.executor.Executor"
}
}
}
}
custom_driver_specs {
key: "CsvExampleGen"
value {
python_class_executable_spec {
class_path: "tfx.components.example_gen.driver.FileBasedDriver"
}
}
}
metadata_connection_config {
database_connection_config {
sqlite {
filename_uri: "metadata/penguin-tfdv-schema/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
}
}
INFO:absl:Using connection config:
sqlite {
filename_uri: "metadata/penguin-tfdv-schema/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
INFO:absl:Component CsvExampleGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmpfs/tmp/tfx-dataj_6ovg52"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:[CsvExampleGen] Resolved inputs: ({},)
INFO:absl:select span and version = (0, None)
INFO:absl:latest span and version = (0, None)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 1
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=1, input_dict={}, output_dict=defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]}), exec_properties={'output_data_format': 6, 'output_file_format': 5, 'input_config': '{\n "splits": [\n {\n "name": "single_split",\n "pattern": "*"\n }\n ]\n}', 'output_config': '{\n "split_config": {\n "splits": [\n {\n "hash_buckets": 2,\n "name": "train"\n },\n {\n "hash_buckets": 1,\n "name": "eval"\n }\n ]\n }\n}', 'input_base': '/tmpfs/tmp/tfx-dataj_6ovg52', 'span': 0, 'version': None, 'input_fingerprint': 'split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970'}, execution_output_uri='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/executor_execution/1/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/stateful_working_dir/d65151e8-a6c7-4b12-8076-f56938dd89f4', tmp_dir='pipelines/penguin-tfdv-schema/CsvExampleGen/.system/executor_execution/1/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmpfs/tmp/tfx-dataj_6ovg52"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2024-05-08T09:36:10.555564', top_level_pipeline_run_id=None, frontend_url=None)
INFO:absl:Generating examples.
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features.
INFO:absl:Processing input csv data /tmpfs/tmp/tfx-dataj_6ovg52/* to TFExample.
WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be.
INFO:absl:Examples generated.
INFO:absl:Value type <class 'NoneType'> of key version in exec_properties is not supported, going to drop it
INFO:absl:Value type <class 'list'> of key _beam_pipeline_args in exec_properties is not supported, going to drop it
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 1 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv-schema/CsvExampleGen/.system/stateful_working_dir/d65151e8-a6c7-4b12-8076-f56938dd89f4
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]}) for execution 1
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component CsvExampleGen is finished.
INFO:absl:Component StatisticsGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
base_type: PROCESS
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
base_type: DATASET
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "SchemaGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING:absl:ArtifactQuery.property_predicate is not supported.
INFO:absl:[StatisticsGen] Resolved inputs: ({'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Examples"
create_time_since_epoch: 1715160971690
last_update_time_since_epoch: 1715160971690
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]},)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 2
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=2, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv-schema/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Examples"
create_time_since_epoch: 1715160971690
last_update_time_since_epoch: 1715160971690
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]}, output_dict=defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv-schema/StatisticsGen/.system/executor_execution/2/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/StatisticsGen/.system/stateful_working_dir/3dc1ed50-c155-41f6-8457-b71a0b0ebe51', tmp_dir='pipelines/penguin-tfdv-schema/StatisticsGen/.system/executor_execution/2/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
base_type: PROCESS
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
base_type: DATASET
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "SchemaGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2024-05-08T09:36:10.555564', top_level_pipeline_run_id=None, frontend_url=None)
INFO:absl:Generating statistics for split train.
INFO:absl:Statistics for split train written to pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2/Split-train.
INFO:absl:Generating statistics for split eval.
INFO:absl:Statistics for split eval written to pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2/Split-eval.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 2 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv-schema/StatisticsGen/.system/stateful_working_dir/3dc1ed50-c155-41f6-8457-b71a0b0ebe51
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]}) for execution 2
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component StatisticsGen is finished.
INFO:absl:Component SchemaGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.schema_gen.component.SchemaGen"
base_type: PROCESS
}
id: "SchemaGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.SchemaGen"
}
}
}
}
inputs {
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
base_type: STATISTICS
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "schema"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
parameters {
key: "infer_feature_shape"
value {
field_value {
int_value: 1
}
}
}
}
upstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING:absl:ArtifactQuery.property_predicate is not supported.
INFO:absl:[SchemaGen] Resolved inputs: ({'statistics': [Artifact(artifact: id: 2
type_id: 17
uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
properties {
key: "span"
value {
int_value: 0
}
}
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "stats_dashboard_link"
value {
string_value: ""
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "ExampleStatistics"
create_time_since_epoch: 1715160975131
last_update_time_since_epoch: 1715160975131
, artifact_type: id: 17
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]},)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 3
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=3, input_dict={'statistics': [Artifact(artifact: id: 2
type_id: 17
uri: "pipelines/penguin-tfdv-schema/StatisticsGen/statistics/2"
properties {
key: "span"
value {
int_value: 0
}
}
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "stats_dashboard_link"
value {
string_value: ""
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "ExampleStatistics"
create_time_since_epoch: 1715160975131
last_update_time_since_epoch: 1715160975131
, artifact_type: id: 17
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]}, output_dict=defaultdict(<class 'list'>, {'schema': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/SchemaGen/schema/3"
, artifact_type: name: "Schema"
)]}), exec_properties={'infer_feature_shape': 1, 'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv-schema/SchemaGen/.system/executor_execution/3/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv-schema/SchemaGen/.system/stateful_working_dir/9cb63ad1-17a3-4aaa-a3d3-5059f958bf6f', tmp_dir='pipelines/penguin-tfdv-schema/SchemaGen/.system/executor_execution/3/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.schema_gen.component.SchemaGen"
base_type: PROCESS
}
id: "SchemaGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.SchemaGen"
}
}
}
}
inputs {
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv-schema"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:10.555564"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv-schema.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
base_type: STATISTICS
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "schema"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
parameters {
key: "infer_feature_shape"
value {
field_value {
int_value: 1
}
}
}
}
upstream_nodes: "StatisticsGen"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv-schema"
, pipeline_run_id='2024-05-08T09:36:10.555564', top_level_pipeline_run_id=None, frontend_url=None)
INFO:absl:Processing schema from statistics for split train.
INFO:absl:Processing schema from statistics for split eval.
INFO:absl:Schema written to pipelines/penguin-tfdv-schema/SchemaGen/schema/3/schema.pbtxt.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 3 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv-schema/SchemaGen/.system/stateful_working_dir/9cb63ad1-17a3-4aaa-a3d3-5059f958bf6f
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'schema': [Artifact(artifact: uri: "pipelines/penguin-tfdv-schema/SchemaGen/schema/3"
, artifact_type: name: "Schema"
)]}) for execution 3
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component SchemaGen is finished.
You should see "INFO:absl:Component SchemaGen is finished." if the pipeline finished successfully.
We will examine the output of the pipeline to understand our dataset.
Review outputs of the pipeline
As explained in the previous tutorial, a TFX pipeline produces two kinds of
outputs, artifacts and a
metadata DB(MLMD) which contains
metadata of artifacts and pipeline executions. We defined the location of
these outputs in the above cells. By default, artifacts are stored under
the pipelines directory and metadata is stored as a sqlite database
under the metadata directory.
You can use MLMD APIs to locate these outputs programatically. First, we will define some utility functions to search for the output artifacts that were just produced.
from ml_metadata.proto import metadata_store_pb2
# Non-public APIs, just for showcase.
from tfx.orchestration.portable.mlmd import execution_lib
# TODO(b/171447278): Move these functions into the TFX library.
def get_latest_artifacts(metadata, pipeline_name, component_id):
"""Output artifacts of the latest run of the component."""
context = metadata.store.get_context_by_type_and_name(
'node', f'{pipeline_name}.{component_id}')
executions = metadata.store.get_executions_by_context(context.id)
latest_execution = max(executions,
key=lambda e:e.last_update_time_since_epoch)
return execution_lib.get_output_artifacts(metadata, latest_execution.id)
# Non-public APIs, just for showcase.
from tfx.orchestration.experimental.interactive import visualizations
def visualize_artifacts(artifacts):
"""Visualizes artifacts using standard visualization modules."""
for artifact in artifacts:
visualization = visualizations.get_registry().get_visualization(
artifact.type_name)
if visualization:
visualization.display(artifact)
from tfx.orchestration.experimental.interactive import standard_visualizations
standard_visualizations.register_standard_visualizations()
Now we can examine the outputs from the pipeline execution.
# Non-public APIs, just for showcase.
from tfx.orchestration.metadata import Metadata
from tfx.types import standard_component_specs
metadata_connection_config = tfx.orchestration.metadata.sqlite_metadata_connection_config(
SCHEMA_METADATA_PATH)
with Metadata(metadata_connection_config) as metadata_handler:
# Find output artifacts from MLMD.
stat_gen_output = get_latest_artifacts(metadata_handler, SCHEMA_PIPELINE_NAME,
'StatisticsGen')
stats_artifacts = stat_gen_output[standard_component_specs.STATISTICS_KEY]
schema_gen_output = get_latest_artifacts(metadata_handler,
SCHEMA_PIPELINE_NAME, 'SchemaGen')
schema_artifacts = schema_gen_output[standard_component_specs.SCHEMA_KEY]
INFO:absl:MetadataStore with DB connection initialized
It is time to examine the outputs from each component. As described above,
Tensorflow Data Validation(TFDV)
is used in StatisticsGen and SchemaGen, and TFDV also
provides visualization of the outputs from these components.
In this tutorial, we will use the visualization helper methods in TFX which use TFDV internally to show the visualization.
Examine the output from StatisticsGen
# docs-infra: no-execute
visualize_artifacts(stats_artifacts)
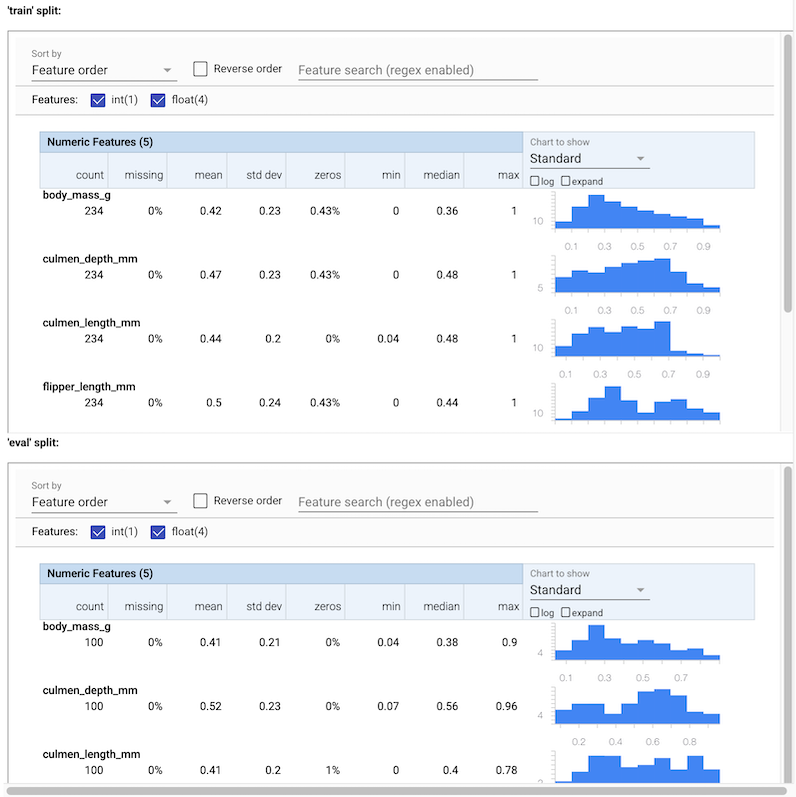
You can see various stats for the input data. These statistics are supplied to
SchemaGen to construct an initial schema of data automatically.
Examine the output from SchemaGen
visualize_artifacts(schema_artifacts)
This schema is automatically inferred from the output of StatisticsGen. You should be able to see 4 FLOAT features and 1 INT feature.
Export the schema for future use
We need to review and refine the generated schema. The reviewed schema needs to be persisted to be used in subsequent pipelines for ML model training. In other words, you might want to add the schema file to your version control system for actual use cases. In this tutorial, we will just copy the schema to a predefined filesystem path for simplicity.
import shutil
_schema_filename = 'schema.pbtxt'
SCHEMA_PATH = 'schema'
os.makedirs(SCHEMA_PATH, exist_ok=True)
_generated_path = os.path.join(schema_artifacts[0].uri, _schema_filename)
# Copy the 'schema.pbtxt' file from the artifact uri to a predefined path.
shutil.copy(_generated_path, SCHEMA_PATH)
'schema/schema.pbtxt'
The schema file uses Protocol Buffer text format and an instance of TensorFlow Metadata Schema proto.
print(f'Schema at {SCHEMA_PATH}-----')
!cat {SCHEMA_PATH}/*
Schema at schema-----
feature {
name: "body_mass_g"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "culmen_depth_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "culmen_length_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "flipper_length_mm"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "species"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
You should be sure to review and possibly edit the schema definition as needed. In this tutorial, we will just use the generated schema unchanged.
Validate input examples and train an ML model
We will go back to the pipeline that we created in Simple TFX Pipeline Tutorial, to train an ML model and use the generated schema for writing the model training code.
We will also add an ExampleValidator component which will look for anomalies and missing values in the incoming dataset with respect to the schema.
Write model training code
We need to write the model code as we did in Simple TFX Pipeline Tutorial.
The model itself is the same as in the previous tutorial, but this time we will use the schema generated from the previous pipeline instead of specifying features manually. Most of the code was not changed. The only difference is that we do not need to specify the names and types of features in this file. Instead, we read them from the schema file.
_trainer_module_file = 'penguin_trainer.py'
%%writefile {_trainer_module_file}
from typing import List
from absl import logging
import tensorflow as tf
from tensorflow import keras
from tensorflow_transform.tf_metadata import schema_utils
from tfx import v1 as tfx
from tfx_bsl.public import tfxio
from tensorflow_metadata.proto.v0 import schema_pb2
# We don't need to specify _FEATURE_KEYS and _FEATURE_SPEC any more.
# Those information can be read from the given schema file.
_LABEL_KEY = 'species'
_TRAIN_BATCH_SIZE = 20
_EVAL_BATCH_SIZE = 10
def _input_fn(file_pattern: List[str],
data_accessor: tfx.components.DataAccessor,
schema: schema_pb2.Schema,
batch_size: int = 200) -> tf.data.Dataset:
"""Generates features and label for training.
Args:
file_pattern: List of paths or patterns of input tfrecord files.
data_accessor: DataAccessor for converting input to RecordBatch.
schema: schema of the input data.
batch_size: representing the number of consecutive elements of returned
dataset to combine in a single batch
Returns:
A dataset that contains (features, indices) tuple where features is a
dictionary of Tensors, and indices is a single Tensor of label indices.
"""
return data_accessor.tf_dataset_factory(
file_pattern,
tfxio.TensorFlowDatasetOptions(
batch_size=batch_size, label_key=_LABEL_KEY),
schema=schema).repeat()
def _build_keras_model(schema: schema_pb2.Schema) -> tf.keras.Model:
"""Creates a DNN Keras model for classifying penguin data.
Returns:
A Keras Model.
"""
# The model below is built with Functional API, please refer to
# https://www.tensorflow.org/guide/keras/overview for all API options.
# ++ Changed code: Uses all features in the schema except the label.
feature_keys = [f.name for f in schema.feature if f.name != _LABEL_KEY]
inputs = [keras.layers.Input(shape=(1,), name=f) for f in feature_keys]
# ++ End of the changed code.
d = keras.layers.concatenate(inputs)
for _ in range(2):
d = keras.layers.Dense(8, activation='relu')(d)
outputs = keras.layers.Dense(3)(d)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(
optimizer=keras.optimizers.Adam(1e-2),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
model.summary(print_fn=logging.info)
return model
# TFX Trainer will call this function.
def run_fn(fn_args: tfx.components.FnArgs):
"""Train the model based on given args.
Args:
fn_args: Holds args used to train the model as name/value pairs.
"""
# ++ Changed code: Reads in schema file passed to the Trainer component.
schema = tfx.utils.parse_pbtxt_file(fn_args.schema_path, schema_pb2.Schema())
# ++ End of the changed code.
train_dataset = _input_fn(
fn_args.train_files,
fn_args.data_accessor,
schema,
batch_size=_TRAIN_BATCH_SIZE)
eval_dataset = _input_fn(
fn_args.eval_files,
fn_args.data_accessor,
schema,
batch_size=_EVAL_BATCH_SIZE)
model = _build_keras_model(schema)
model.fit(
train_dataset,
steps_per_epoch=fn_args.train_steps,
validation_data=eval_dataset,
validation_steps=fn_args.eval_steps)
# The result of the training should be saved in `fn_args.serving_model_dir`
# directory.
model.save(fn_args.serving_model_dir, save_format='tf')
Writing penguin_trainer.py
Now you have completed all preparation steps to build a TFX pipeline for model training.
Write a pipeline definition
We will add two new components, Importer and ExampleValidator. Importer
brings an external file into the TFX pipeline. In this case, it is a file
containing schema definition. ExampleValidator will examine
the input data and validate whether all input data conforms the data schema
we provided.
def _create_pipeline(pipeline_name: str, pipeline_root: str, data_root: str,
schema_path: str, module_file: str, serving_model_dir: str,
metadata_path: str) -> tfx.dsl.Pipeline:
"""Creates a pipeline using predefined schema with TFX."""
# Brings data into the pipeline.
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# Computes statistics over data for visualization and example validation.
statistics_gen = tfx.components.StatisticsGen(
examples=example_gen.outputs['examples'])
# NEW: Import the schema.
schema_importer = tfx.dsl.Importer(
source_uri=schema_path,
artifact_type=tfx.types.standard_artifacts.Schema).with_id(
'schema_importer')
# NEW: Performs anomaly detection based on statistics and data schema.
example_validator = tfx.components.ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_importer.outputs['result'])
# Uses user-provided Python function that trains a model.
trainer = tfx.components.Trainer(
module_file=module_file,
examples=example_gen.outputs['examples'],
schema=schema_importer.outputs['result'], # Pass the imported schema.
train_args=tfx.proto.TrainArgs(num_steps=100),
eval_args=tfx.proto.EvalArgs(num_steps=5))
# Pushes the model to a filesystem destination.
pusher = tfx.components.Pusher(
model=trainer.outputs['model'],
push_destination=tfx.proto.PushDestination(
filesystem=tfx.proto.PushDestination.Filesystem(
base_directory=serving_model_dir)))
components = [
example_gen,
# NEW: Following three components were added to the pipeline.
statistics_gen,
schema_importer,
example_validator,
trainer,
pusher,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components)
Run the pipeline
tfx.orchestration.LocalDagRunner().run(
_create_pipeline(
pipeline_name=PIPELINE_NAME,
pipeline_root=PIPELINE_ROOT,
data_root=DATA_ROOT,
schema_path=SCHEMA_PATH,
module_file=_trainer_module_file,
serving_model_dir=SERVING_MODEL_DIR,
metadata_path=METADATA_PATH))
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Excluding no splits because exclude_splits is not set.
INFO:absl:Generating ephemeral wheel package for '/tmpfs/src/temp/docs/tutorials/tfx/penguin_trainer.py' (including modules: ['penguin_trainer']).
INFO:absl:User module package has hash fingerprint version 000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.
INFO:absl:Executing: ['/tmpfs/src/tf_docs_env/bin/python', '/tmpfs/tmp/tmpw96a2pj7/_tfx_generated_setup.py', 'bdist_wheel', '--bdist-dir', '/tmpfs/tmp/tmp42iap5mu', '--dist-dir', '/tmpfs/tmp/tmpx8p04zcg']
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/setuptools/_distutils/cmd.py:66: SetuptoolsDeprecationWarning: setup.py install is deprecated.
!!
********************************************************************************
Please avoid running ``setup.py`` directly.
Instead, use pypa/build, pypa/installer or other
standards-based tools.
See https://blog.ganssle.io/articles/2021/10/setup-py-deprecated.html for details.
********************************************************************************
!!
self.initialize_options()
INFO:absl:Successfully built user code wheel distribution at 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'; target user module is 'penguin_trainer'.
INFO:absl:Full user module path is 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'
INFO:absl:Using deployment config:
executor_specs {
key: "CsvExampleGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.example_gen.csv_example_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "ExampleValidator"
value {
python_class_executable_spec {
class_path: "tfx.components.example_validator.executor.Executor"
}
}
}
executor_specs {
key: "Pusher"
value {
python_class_executable_spec {
class_path: "tfx.components.pusher.executor.Executor"
}
}
}
executor_specs {
key: "StatisticsGen"
value {
beam_executable_spec {
python_executor_spec {
class_path: "tfx.components.statistics_gen.executor.Executor"
}
}
}
}
executor_specs {
key: "Trainer"
value {
python_class_executable_spec {
class_path: "tfx.components.trainer.executor.GenericExecutor"
}
}
}
custom_driver_specs {
key: "CsvExampleGen"
value {
python_class_executable_spec {
class_path: "tfx.components.example_gen.driver.FileBasedDriver"
}
}
}
metadata_connection_config {
database_connection_config {
sqlite {
filename_uri: "metadata/penguin-tfdv/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
}
}
INFO:absl:Using connection config:
sqlite {
filename_uri: "metadata/penguin-tfdv/metadata.db"
connection_mode: READWRITE_OPENCREATE
}
INFO:absl:Component CsvExampleGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmpfs/tmp/tfx-dataj_6ovg52"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:[CsvExampleGen] Resolved inputs: ({},)
running bdist_wheel
running build
running build_py
creating build
creating build/lib
copying penguin_trainer.py -> build/lib
installing to /tmpfs/tmp/tmp42iap5mu
running install
running install_lib
copying build/lib/penguin_trainer.py -> /tmpfs/tmp/tmp42iap5mu
running install_egg_info
running egg_info
creating tfx_user_code_Trainer.egg-info
writing tfx_user_code_Trainer.egg-info/PKG-INFO
writing dependency_links to tfx_user_code_Trainer.egg-info/dependency_links.txt
writing top-level names to tfx_user_code_Trainer.egg-info/top_level.txt
writing manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
reading manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
writing manifest file 'tfx_user_code_Trainer.egg-info/SOURCES.txt'
Copying tfx_user_code_Trainer.egg-info to /tmpfs/tmp/tmp42iap5mu/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3.9.egg-info
running install_scripts
creating /tmpfs/tmp/tmp42iap5mu/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/WHEEL
creating '/tmpfs/tmp/tmpx8p04zcg/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl' and adding '/tmpfs/tmp/tmp42iap5mu' to it
adding 'penguin_trainer.py'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/METADATA'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/WHEEL'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/top_level.txt'
adding 'tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2.dist-info/RECORD'
removing /tmpfs/tmp/tmp42iap5mu
INFO:absl:select span and version = (0, None)
INFO:absl:latest span and version = (0, None)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 1
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=1, input_dict={}, output_dict=defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]}), exec_properties={'output_file_format': 5, 'input_config': '{\n "splits": [\n {\n "name": "single_split",\n "pattern": "*"\n }\n ]\n}', 'output_data_format': 6, 'output_config': '{\n "split_config": {\n "splits": [\n {\n "hash_buckets": 2,\n "name": "train"\n },\n {\n "hash_buckets": 1,\n "name": "eval"\n }\n ]\n }\n}', 'input_base': '/tmpfs/tmp/tfx-dataj_6ovg52', 'span': 0, 'version': None, 'input_fingerprint': 'split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970'}, execution_output_uri='pipelines/penguin-tfdv/CsvExampleGen/.system/executor_execution/1/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/CsvExampleGen/.system/stateful_working_dir/0858d568-1a97-401a-afc6-a9932ff9a1e3', tmp_dir='pipelines/penguin-tfdv/CsvExampleGen/.system/executor_execution/1/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_gen.csv_example_gen.component.CsvExampleGen"
}
id: "CsvExampleGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
}
outputs {
outputs {
key: "examples"
value {
artifact_spec {
type {
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
}
}
}
}
}
parameters {
parameters {
key: "input_base"
value {
field_value {
string_value: "/tmpfs/tmp/tfx-dataj_6ovg52"
}
}
}
parameters {
key: "input_config"
value {
field_value {
string_value: "{\n \"splits\": [\n {\n \"name\": \"single_split\",\n \"pattern\": \"*\"\n }\n ]\n}"
}
}
}
parameters {
key: "output_config"
value {
field_value {
string_value: "{\n \"split_config\": {\n \"splits\": [\n {\n \"hash_buckets\": 2,\n \"name\": \"train\"\n },\n {\n \"hash_buckets\": 1,\n \"name\": \"eval\"\n }\n ]\n }\n}"
}
}
}
parameters {
key: "output_data_format"
value {
field_value {
int_value: 6
}
}
}
parameters {
key: "output_file_format"
value {
field_value {
int_value: 5
}
}
}
}
downstream_nodes: "StatisticsGen"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2024-05-08T09:36:15.816321', top_level_pipeline_run_id=None, frontend_url=None)
INFO:absl:Generating examples.
INFO:absl:Processing input csv data /tmpfs/tmp/tfx-dataj_6ovg52/* to TFExample.
INFO:absl:Examples generated.
INFO:absl:Value type <class 'NoneType'> of key version in exec_properties is not supported, going to drop it
INFO:absl:Value type <class 'list'> of key _beam_pipeline_args in exec_properties is not supported, going to drop it
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 1 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv/CsvExampleGen/.system/stateful_working_dir/0858d568-1a97-401a-afc6-a9932ff9a1e3
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'examples': [Artifact(artifact: uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
, artifact_type: name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]}) for execution 1
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component CsvExampleGen is finished.
INFO:absl:Component schema_importer is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.dsl.components.common.importer.Importer"
}
id: "schema_importer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
}
outputs {
outputs {
key: "result"
value {
artifact_spec {
type {
name: "Schema"
}
}
}
}
}
parameters {
parameters {
key: "artifact_uri"
value {
field_value {
string_value: "schema"
}
}
}
parameters {
key: "output_key"
value {
field_value {
string_value: "result"
}
}
}
parameters {
key: "reimport"
value {
field_value {
int_value: 0
}
}
}
}
downstream_nodes: "ExampleValidator"
downstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:Running as an importer node.
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Processing source uri: schema, properties: {}, custom_properties: {}
INFO:absl:Component schema_importer is finished.
INFO:absl:Component StatisticsGen is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
base_type: PROCESS
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
base_type: DATASET
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "ExampleValidator"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING:absl:ArtifactQuery.property_predicate is not supported.
INFO:absl:[StatisticsGen] Resolved inputs: ({'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Examples"
create_time_since_epoch: 1715160976759
last_update_time_since_epoch: 1715160976759
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]},)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 3
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=3, input_dict={'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Examples"
create_time_since_epoch: 1715160976759
last_update_time_since_epoch: 1715160976759
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]}, output_dict=defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv/StatisticsGen/.system/executor_execution/3/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/StatisticsGen/.system/stateful_working_dir/110d150d-d7b8-4a54-9e4b-de96d2f275fe', tmp_dir='pipelines/penguin-tfdv/StatisticsGen/.system/executor_execution/3/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.statistics_gen.component.StatisticsGen"
base_type: PROCESS
}
id: "StatisticsGen"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
base_type: DATASET
}
}
output_key: "examples"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "statistics"
value {
artifact_spec {
type {
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "CsvExampleGen"
downstream_nodes: "ExampleValidator"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2024-05-08T09:36:15.816321', top_level_pipeline_run_id=None, frontend_url=None)
INFO:absl:Generating statistics for split train.
INFO:absl:Statistics for split train written to pipelines/penguin-tfdv/StatisticsGen/statistics/3/Split-train.
INFO:absl:Generating statistics for split eval.
INFO:absl:Statistics for split eval written to pipelines/penguin-tfdv/StatisticsGen/statistics/3/Split-eval.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 3 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv/StatisticsGen/.system/stateful_working_dir/110d150d-d7b8-4a54-9e4b-de96d2f275fe
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'statistics': [Artifact(artifact: uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
, artifact_type: name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]}) for execution 3
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component StatisticsGen is finished.
INFO:absl:Component Trainer is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.trainer.component.Trainer"
base_type: TRAIN
}
id: "Trainer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
base_type: DATASET
}
}
output_key: "examples"
}
min_count: 1
}
}
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
}
}
}
outputs {
outputs {
key: "model"
value {
artifact_spec {
type {
name: "Model"
base_type: MODEL
}
}
}
}
outputs {
key: "model_run"
value {
artifact_spec {
type {
name: "ModelRun"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "eval_args"
value {
field_value {
string_value: "{\n \"num_steps\": 5\n}"
}
}
}
parameters {
key: "module_path"
value {
field_value {
string_value: "penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl"
}
}
}
parameters {
key: "train_args"
value {
field_value {
string_value: "{\n \"num_steps\": 100\n}"
}
}
}
}
upstream_nodes: "CsvExampleGen"
upstream_nodes: "schema_importer"
downstream_nodes: "Pusher"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING:absl:ArtifactQuery.property_predicate is not supported.
WARNING:absl:ArtifactQuery.property_predicate is not supported.
INFO:absl:[Trainer] Resolved inputs: ({'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "is_external"
value {
int_value: 1
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Schema"
create_time_since_epoch: 1715160976782
last_update_time_since_epoch: 1715160976782
, artifact_type: id: 17
name: "Schema"
)], 'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Examples"
create_time_since_epoch: 1715160976759
last_update_time_since_epoch: 1715160976759
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]},)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 4
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=4, input_dict={'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "is_external"
value {
int_value: 1
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Schema"
create_time_since_epoch: 1715160976782
last_update_time_since_epoch: 1715160976782
, artifact_type: id: 17
name: "Schema"
)], 'examples': [Artifact(artifact: id: 1
type_id: 15
uri: "pipelines/penguin-tfdv/CsvExampleGen/examples/1"
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "file_format"
value {
string_value: "tfrecords_gzip"
}
}
custom_properties {
key: "input_fingerprint"
value {
string_value: "split:single_split,num_files:1,total_bytes:25648,xor_checksum:1715160970,sum_checksum:1715160970"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "payload_format"
value {
string_value: "FORMAT_TF_EXAMPLE"
}
}
custom_properties {
key: "span"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Examples"
create_time_since_epoch: 1715160976759
last_update_time_since_epoch: 1715160976759
, artifact_type: id: 15
name: "Examples"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
properties {
key: "version"
value: INT
}
base_type: DATASET
)]}, output_dict=defaultdict(<class 'list'>, {'model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model/4"
, artifact_type: name: "Model"
base_type: MODEL
)], 'model_run': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model_run/4"
, artifact_type: name: "ModelRun"
)]}), exec_properties={'custom_config': 'null', 'train_args': '{\n "num_steps": 100\n}', 'eval_args': '{\n "num_steps": 5\n}', 'module_path': 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'}, execution_output_uri='pipelines/penguin-tfdv/Trainer/.system/executor_execution/4/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/Trainer/.system/stateful_working_dir/d3fcfa17-7c4e-4e63-a48c-deb3cc064ab5', tmp_dir='pipelines/penguin-tfdv/Trainer/.system/executor_execution/4/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.trainer.component.Trainer"
base_type: TRAIN
}
id: "Trainer"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
}
inputs {
inputs {
key: "examples"
value {
channels {
producer_node_query {
id: "CsvExampleGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.CsvExampleGen"
}
}
}
artifact_query {
type {
name: "Examples"
base_type: DATASET
}
}
output_key: "examples"
}
min_count: 1
}
}
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
}
}
}
outputs {
outputs {
key: "model"
value {
artifact_spec {
type {
name: "Model"
base_type: MODEL
}
}
}
}
outputs {
key: "model_run"
value {
artifact_spec {
type {
name: "ModelRun"
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "eval_args"
value {
field_value {
string_value: "{\n \"num_steps\": 5\n}"
}
}
}
parameters {
key: "module_path"
value {
field_value {
string_value: "penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl"
}
}
}
parameters {
key: "train_args"
value {
field_value {
string_value: "{\n \"num_steps\": 100\n}"
}
}
}
}
upstream_nodes: "CsvExampleGen"
upstream_nodes: "schema_importer"
downstream_nodes: "Pusher"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2024-05-08T09:36:15.816321', top_level_pipeline_run_id=None, frontend_url=None)
INFO:absl:Train on the 'train' split when train_args.splits is not set.
INFO:absl:Evaluate on the 'eval' split when eval_args.splits is not set.
INFO:absl:udf_utils.get_fn {'custom_config': 'null', 'train_args': '{\n "num_steps": 100\n}', 'eval_args': '{\n "num_steps": 5\n}', 'module_path': 'penguin_trainer@pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'} 'run_fn'
INFO:absl:Installing 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl' to a temporary directory.
INFO:absl:Executing: ['/tmpfs/src/tf_docs_env/bin/python', '-m', 'pip', 'install', '--target', '/tmpfs/tmp/tmp8javf_ly', 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl']
Processing ./pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl
INFO:absl:Successfully installed 'pipelines/penguin-tfdv/_wheels/tfx_user_code_Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2-py3-none-any.whl'.
INFO:absl:Training model.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
Installing collected packages: tfx-user-code-Trainer
Successfully installed tfx-user-code-Trainer-0.0+000876a22093ec764e3751d5a3ed939f1b107d1d6ade133f954ea2a767b8dfb2
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tfx_bsl/tfxio/tf_example_record.py:343: parse_example_dataset (from tensorflow.python.data.experimental.ops.parsing_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.data.Dataset.map(tf.io.parse_example(...))` instead.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tfx_bsl/tfxio/tf_example_record.py:343: parse_example_dataset (from tensorflow.python.data.experimental.ops.parsing_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.data.Dataset.map(tf.io.parse_example(...))` instead.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature body_mass_g has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_depth_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature culmen_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature flipper_length_mm has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Feature species has a shape dim {
size: 1
}
. Setting to DenseTensor.
INFO:absl:Model: "model"
INFO:absl:__________________________________________________________________________________________________
INFO:absl: Layer (type) Output Shape Param # Connected to
INFO:absl:==================================================================================================
INFO:absl: body_mass_g (InputLayer) [(None, 1)] 0 []
INFO:absl:
INFO:absl: culmen_depth_mm (InputLaye [(None, 1)] 0 []
INFO:absl: r)
INFO:absl:
INFO:absl: culmen_length_mm (InputLay [(None, 1)] 0 []
INFO:absl: er)
INFO:absl:
INFO:absl: flipper_length_mm (InputLa [(None, 1)] 0 []
INFO:absl: yer)
INFO:absl:
INFO:absl: concatenate (Concatenate) (None, 4) 0 ['body_mass_g[0][0]',
INFO:absl: 'culmen_depth_mm[0][0]',
INFO:absl: 'culmen_length_mm[0][0]',
INFO:absl: 'flipper_length_mm[0][0]']
INFO:absl:
INFO:absl: dense (Dense) (None, 8) 40 ['concatenate[0][0]']
INFO:absl:
INFO:absl: dense_1 (Dense) (None, 8) 72 ['dense[0][0]']
INFO:absl:
INFO:absl: dense_2 (Dense) (None, 3) 27 ['dense_1[0][0]']
INFO:absl:
INFO:absl:==================================================================================================
INFO:absl:Total params: 139 (556.00 Byte)
INFO:absl:Trainable params: 139 (556.00 Byte)
INFO:absl:Non-trainable params: 0 (0.00 Byte)
INFO:absl:__________________________________________________________________________________________________
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1715160986.539652 29188 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
100/100 [==============================] - 2s 5ms/step - loss: 0.5183 - sparse_categorical_accuracy: 0.8225 - val_loss: 0.1883 - val_sparse_categorical_accuracy: 0.9000
INFO:absl:Function `_wrapped_model` contains input name(s) resource with unsupported characters which will be renamed to model_dense_2_biasadd_readvariableop_resource in the SavedModel.
INFO:tensorflow:Assets written to: pipelines/penguin-tfdv/Trainer/model/4/Format-Serving/assets
INFO:tensorflow:Assets written to: pipelines/penguin-tfdv/Trainer/model/4/Format-Serving/assets
INFO:absl:Writing fingerprint to pipelines/penguin-tfdv/Trainer/model/4/Format-Serving/fingerprint.pb
INFO:absl:Training complete. Model written to pipelines/penguin-tfdv/Trainer/model/4/Format-Serving. ModelRun written to pipelines/penguin-tfdv/Trainer/model_run/4
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 4 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv/Trainer/.system/stateful_working_dir/d3fcfa17-7c4e-4e63-a48c-deb3cc064ab5
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model/4"
, artifact_type: name: "Model"
base_type: MODEL
)], 'model_run': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Trainer/model_run/4"
, artifact_type: name: "ModelRun"
)]}) for execution 4
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component Trainer is finished.
INFO:absl:Component ExampleValidator is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.example_validator.component.ExampleValidator"
}
id: "ExampleValidator"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.ExampleValidator"
}
}
}
}
inputs {
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
min_count: 1
}
}
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
base_type: STATISTICS
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "anomalies"
value {
artifact_spec {
type {
name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "StatisticsGen"
upstream_nodes: "schema_importer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING:absl:ArtifactQuery.property_predicate is not supported.
WARNING:absl:ArtifactQuery.property_predicate is not supported.
INFO:absl:[ExampleValidator] Resolved inputs: ({'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "is_external"
value {
int_value: 1
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Schema"
create_time_since_epoch: 1715160976782
last_update_time_since_epoch: 1715160976782
, artifact_type: id: 17
name: "Schema"
)], 'statistics': [Artifact(artifact: id: 3
type_id: 19
uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
properties {
key: "span"
value {
int_value: 0
}
}
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "stats_dashboard_link"
value {
string_value: ""
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "ExampleStatistics"
create_time_since_epoch: 1715160979570
last_update_time_since_epoch: 1715160979570
, artifact_type: id: 19
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]},)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 5
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=5, input_dict={'schema': [Artifact(artifact: id: 2
type_id: 17
uri: "schema"
custom_properties {
key: "is_external"
value {
int_value: 1
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Schema"
create_time_since_epoch: 1715160976782
last_update_time_since_epoch: 1715160976782
, artifact_type: id: 17
name: "Schema"
)], 'statistics': [Artifact(artifact: id: 3
type_id: 19
uri: "pipelines/penguin-tfdv/StatisticsGen/statistics/3"
properties {
key: "span"
value {
int_value: 0
}
}
properties {
key: "split_names"
value {
string_value: "[\"train\", \"eval\"]"
}
}
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "stats_dashboard_link"
value {
string_value: ""
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "ExampleStatistics"
create_time_since_epoch: 1715160979570
last_update_time_since_epoch: 1715160979570
, artifact_type: id: 19
name: "ExampleStatistics"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
base_type: STATISTICS
)]}, output_dict=defaultdict(<class 'list'>, {'anomalies': [Artifact(artifact: uri: "pipelines/penguin-tfdv/ExampleValidator/anomalies/5"
, artifact_type: name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}), exec_properties={'exclude_splits': '[]'}, execution_output_uri='pipelines/penguin-tfdv/ExampleValidator/.system/executor_execution/5/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/ExampleValidator/.system/stateful_working_dir/37093a55-ba7a-42c7-a4fc-388b5f69b7d8', tmp_dir='pipelines/penguin-tfdv/ExampleValidator/.system/executor_execution/5/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.example_validator.component.ExampleValidator"
}
id: "ExampleValidator"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.ExampleValidator"
}
}
}
}
inputs {
inputs {
key: "schema"
value {
channels {
producer_node_query {
id: "schema_importer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.schema_importer"
}
}
}
artifact_query {
type {
name: "Schema"
}
}
output_key: "result"
}
min_count: 1
}
}
inputs {
key: "statistics"
value {
channels {
producer_node_query {
id: "StatisticsGen"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.StatisticsGen"
}
}
}
artifact_query {
type {
name: "ExampleStatistics"
base_type: STATISTICS
}
}
output_key: "statistics"
}
min_count: 1
}
}
}
outputs {
outputs {
key: "anomalies"
value {
artifact_spec {
type {
name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
}
}
}
}
}
parameters {
parameters {
key: "exclude_splits"
value {
field_value {
string_value: "[]"
}
}
}
}
upstream_nodes: "StatisticsGen"
upstream_nodes: "schema_importer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2024-05-08T09:36:15.816321', top_level_pipeline_run_id=None, frontend_url=None)
INFO:absl:Validating schema against the computed statistics for split train.
INFO:absl:Anomalies alerts created for split train.
INFO:absl:Validation complete for split train. Anomalies written to pipelines/penguin-tfdv/ExampleValidator/anomalies/5/Split-train.
INFO:absl:Validating schema against the computed statistics for split eval.
INFO:absl:Anomalies alerts created for split eval.
INFO:absl:Validation complete for split eval. Anomalies written to pipelines/penguin-tfdv/ExampleValidator/anomalies/5/Split-eval.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 5 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv/ExampleValidator/.system/stateful_working_dir/37093a55-ba7a-42c7-a4fc-388b5f69b7d8
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'anomalies': [Artifact(artifact: uri: "pipelines/penguin-tfdv/ExampleValidator/anomalies/5"
, artifact_type: name: "ExampleAnomalies"
properties {
key: "span"
value: INT
}
properties {
key: "split_names"
value: STRING
}
)]}) for execution 5
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component ExampleValidator is finished.
INFO:absl:Component Pusher is running.
INFO:absl:Running launcher for node_info {
type {
name: "tfx.components.pusher.component.Pusher"
base_type: DEPLOY
}
id: "Pusher"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Pusher"
}
}
}
}
inputs {
inputs {
key: "model"
value {
channels {
producer_node_query {
id: "Trainer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
artifact_query {
type {
name: "Model"
base_type: MODEL
}
}
output_key: "model"
}
}
}
}
outputs {
outputs {
key: "pushed_model"
value {
artifact_spec {
type {
name: "PushedModel"
base_type: MODEL
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "push_destination"
value {
field_value {
string_value: "{\n \"filesystem\": {\n \"base_directory\": \"serving_model/penguin-tfdv\"\n }\n}"
}
}
}
}
upstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
INFO:absl:MetadataStore with DB connection initialized
WARNING:absl:ArtifactQuery.property_predicate is not supported.
INFO:absl:[Pusher] Resolved inputs: ({'model': [Artifact(artifact: id: 4
type_id: 21
uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Model"
create_time_since_epoch: 1715160988205
last_update_time_since_epoch: 1715160988205
, artifact_type: id: 21
name: "Model"
base_type: MODEL
)]},)
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Going to run a new execution 6
INFO:absl:Going to run a new execution: ExecutionInfo(execution_id=6, input_dict={'model': [Artifact(artifact: id: 4
type_id: 21
uri: "pipelines/penguin-tfdv/Trainer/model/4"
custom_properties {
key: "is_external"
value {
int_value: 0
}
}
custom_properties {
key: "tfx_version"
value {
string_value: "1.15.0"
}
}
state: LIVE
type: "Model"
create_time_since_epoch: 1715160988205
last_update_time_since_epoch: 1715160988205
, artifact_type: id: 21
name: "Model"
base_type: MODEL
)]}, output_dict=defaultdict(<class 'list'>, {'pushed_model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Pusher/pushed_model/6"
, artifact_type: name: "PushedModel"
base_type: MODEL
)]}), exec_properties={'custom_config': 'null', 'push_destination': '{\n "filesystem": {\n "base_directory": "serving_model/penguin-tfdv"\n }\n}'}, execution_output_uri='pipelines/penguin-tfdv/Pusher/.system/executor_execution/6/executor_output.pb', stateful_working_dir='pipelines/penguin-tfdv/Pusher/.system/stateful_working_dir/5146eed9-4c4d-4bef-b849-ce87e44956ad', tmp_dir='pipelines/penguin-tfdv/Pusher/.system/executor_execution/6/.temp/', pipeline_node=node_info {
type {
name: "tfx.components.pusher.component.Pusher"
base_type: DEPLOY
}
id: "Pusher"
}
contexts {
contexts {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
contexts {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
contexts {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Pusher"
}
}
}
}
inputs {
inputs {
key: "model"
value {
channels {
producer_node_query {
id: "Trainer"
}
context_queries {
type {
name: "pipeline"
}
name {
field_value {
string_value: "penguin-tfdv"
}
}
}
context_queries {
type {
name: "pipeline_run"
}
name {
field_value {
string_value: "2024-05-08T09:36:15.816321"
}
}
}
context_queries {
type {
name: "node"
}
name {
field_value {
string_value: "penguin-tfdv.Trainer"
}
}
}
artifact_query {
type {
name: "Model"
base_type: MODEL
}
}
output_key: "model"
}
}
}
}
outputs {
outputs {
key: "pushed_model"
value {
artifact_spec {
type {
name: "PushedModel"
base_type: MODEL
}
}
}
}
}
parameters {
parameters {
key: "custom_config"
value {
field_value {
string_value: "null"
}
}
}
parameters {
key: "push_destination"
value {
field_value {
string_value: "{\n \"filesystem\": {\n \"base_directory\": \"serving_model/penguin-tfdv\"\n }\n}"
}
}
}
}
upstream_nodes: "Trainer"
execution_options {
caching_options {
}
}
, pipeline_info=id: "penguin-tfdv"
, pipeline_run_id='2024-05-08T09:36:15.816321', top_level_pipeline_run_id=None, frontend_url=None)
WARNING:absl:Pusher is going to push the model without validation. Consider using Evaluator or InfraValidator in your pipeline.
INFO:absl:Model version: 1715160988
INFO:absl:Model written to serving path serving_model/penguin-tfdv/1715160988.
INFO:absl:Model pushed to pipelines/penguin-tfdv/Pusher/pushed_model/6.
INFO:absl:Cleaning up stateless execution info.
INFO:absl:Execution 6 succeeded.
INFO:absl:Cleaning up stateful execution info.
INFO:absl:Deleted stateful_working_dir pipelines/penguin-tfdv/Pusher/.system/stateful_working_dir/5146eed9-4c4d-4bef-b849-ce87e44956ad
INFO:absl:Publishing output artifacts defaultdict(<class 'list'>, {'pushed_model': [Artifact(artifact: uri: "pipelines/penguin-tfdv/Pusher/pushed_model/6"
, artifact_type: name: "PushedModel"
base_type: MODEL
)]}) for execution 6
INFO:absl:MetadataStore with DB connection initialized
INFO:absl:Component Pusher is finished.
You should see "INFO:absl:Component Pusher is finished." if the pipeline finished successfully.
Examine outputs of the pipeline
We have trained the classification model for penguins, and we also have validated the input examples in the ExampleValidator component. We can analyze the output from ExampleValidator as we did with the previous pipeline.
metadata_connection_config = tfx.orchestration.metadata.sqlite_metadata_connection_config(
METADATA_PATH)
with Metadata(metadata_connection_config) as metadata_handler:
ev_output = get_latest_artifacts(metadata_handler, PIPELINE_NAME,
'ExampleValidator')
anomalies_artifacts = ev_output[standard_component_specs.ANOMALIES_KEY]
INFO:absl:MetadataStore with DB connection initialized
ExampleAnomalies from the ExampleValidator can be visualized as well.
visualize_artifacts(anomalies_artifacts)
You should see "No anomalies found" for each split of examples. Because we used the same data which was used for the schema generation in this pipeline, no anomaly is expected here. If you run this pipeline repeatedly with new incoming data, ExampleValidator should be able to find any discrepancies between the new data and the existing schema.
If any anomalies were found, you may review your data to check to see if any examples do not follow your assumptions. Outputs from other components like StatisticsGen might be useful. However, any anomalies which are found will NOT block further pipeline executions.
Next steps
You can find more resources on https://www.tensorflow.org/tfx/tutorials
Please see Understanding TFX Pipelines to learn more about various concepts in TFX.