
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
Este notebook demonstrará como usar a função TripletSemiHardLoss nos complementos do TensorFlow.
Recursos:
- FaceNet: uma incorporação unificada para reconhecimento facial e agrupamento
- O blog de Oliver Moindrot faz um excelente trabalho ao descrever o algoritmo em detalhes
TripletLoss
Conforme apresentado pela primeira vez no artigo FaceNet, TripletLoss é uma função de perda que treina uma rede neural para incorporar recursos da mesma classe enquanto maximiza a distância entre embeddings de classes diferentes. Para fazer isso, uma âncora é escolhida junto com uma amostra negativa e uma positiva. 
A função de perda é descrita como uma função de distância euclidiana:
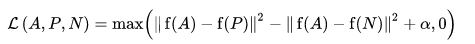
Onde A é a nossa entrada âncora, P é a entrada da amostra positiva, N é a entrada da amostra negativa e alfa é alguma margem que você usa para especificar quando um trio se tornou muito "fácil" e você não deseja mais ajustar os pesos dele .
SemiHard Online Learning
Conforme mostrado no artigo, os melhores resultados são de trigêmeos conhecidos como "Semi-Hard". Eles são definidos como trigêmeos em que o negativo está mais longe da âncora do que o positivo, mas ainda produz uma perda positiva. Para encontrar com eficiência esses trigêmeos, você utiliza o aprendizado online e treina apenas com os exemplos Semi-Hard em cada lote.
Configurar
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
Prepare os dados
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
Construir o modelo

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
Treinar e avaliar
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Projetor de incorporação
Os arquivos vetoriais e metadados podem ser carregados e visualizados aqui: https://projector.tensorflow.org/
Você pode ver os resultados de nossos dados de teste incorporados quando visualizados com UMAP: 