
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
מדריך זה מדגים את השימוש בקצב למידה מחזורי מחבילת ההרחבות.
שיעורי למידה מחזוריים
הוכח שמועיל להתאים את קצב הלמידה עם התקדמות האימון עבור רשת עצבית. יש לו יתרונות רבים, החל מהתאוששות של נקודת אוכף ועד למניעת אי יציבות מספרית שעלולה להתעורר במהלך התפשטות לאחור. אבל איך אפשר לדעת כמה להתאים ביחס לחותמת זמן מסוימת לאימון? בשנת 2015, לסלי סמית' שמה לב שהיית רוצה להגדיל את קצב הלמידה כדי לעבור מהר יותר על פני נוף האובדן, אבל תרצה גם להפחית את קצב הלמידה כאשר אתה מתקרב להתכנסות. כדי לממש את הרעיון הזה, הוא הציע מחירים למיידה מחזוריים (CLR) איפה היית להתאים את קצב הלמידה ביחס המחזורים של פונקציה. להדגמה ויזואלית, אתה יכול לבדוק את הבלוג הזה . CLR זמין כעת כ- TensorFlow API. לפרטים נוספים, לבדוק את המאמר המקורי כאן .
להכין
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
טען והכן מערך נתונים
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
הגדרת היפרפרמטרים
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
הגדירו כלי עזר לבניית מודלים ואימון מודלים
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
למען יכולת השחזור, משקולות המודל הראשוניות מסודרות בהן תשתמש לביצוע הניסויים שלנו.
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
אימון דגם ללא CLR
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
הגדר לוח זמנים של CLR
tfa.optimizers.CyclicalLearningRate מודול לחזור לוח זמנים ישירים כי ניתן להעביר מייעל. לוח הזמנים לוקח שלב כקלט שלו ומוציא ערך המחושב באמצעות נוסחת CLR כפי שנקבע בעיתון.
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
הנה, אתה קובע את הגבולות עליונים והתחתונים של קצב הלמידה ואת לוח הזמנים יהיה להתנדנד בין המגוון ([1E-4, 1E-2] במקרה זה). scale_fn משמש להגדרת הפונקציה כי היה בהיקף של עד להקטין את שיעור הלמידה תוך מחזור נתון. step_size מגדיר את משך מחזור אחד. step_size של 2 אומר שאתה צריך בסך הכל 4 חזרות כדי להשלים מחזור אחד. הערך המומלץ עבור step_size הוא כדלקמן:
factor * steps_per_epoch שבו שקרים גורמים בתוך [2, 8] הטווח.
באותו נייר CLR , לסלי גם הציגה פשוט שיטה אלגנטית לבחור את הגבולות ללימוד שיעור. אתה מוזמן לבדוק את זה גם כן. פוסט בבלוג זה מספק הקדמה נחמדה על השיטה.
להלן, אתם מדמיינים איך clr נראה לוח הזמנים אוהבים.
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
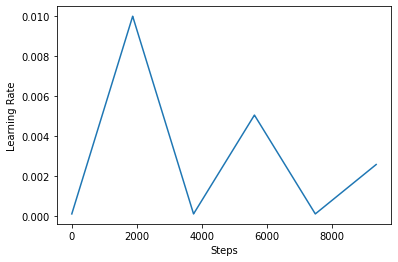
על מנת לדמיין טוב יותר את ההשפעה של CLR, אתה יכול לשרטט את לוח הזמנים עם מספר מוגבר של שלבים.
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
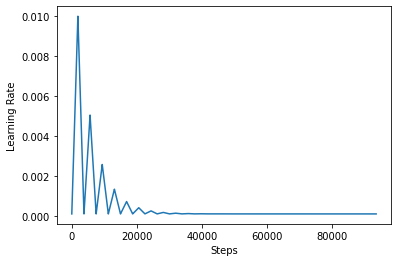
הפונקציה אתה משתמש במדריך זה איננו המכונית triangular2 השיטה בעיתון CLR. ישנן שתי פונקציות אחרות יש נחקרו כלומר triangular ו exp (קיצור של מעריכים).
אימון דגם עם CLR
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
כצפוי ההפסד מתחיל גבוה מהרגיל ואז הוא מתייצב ככל שהמחזורים מתקדמים. אתה יכול לאשר זאת חזותית עם העלילות למטה.
דמיינו הפסדים
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
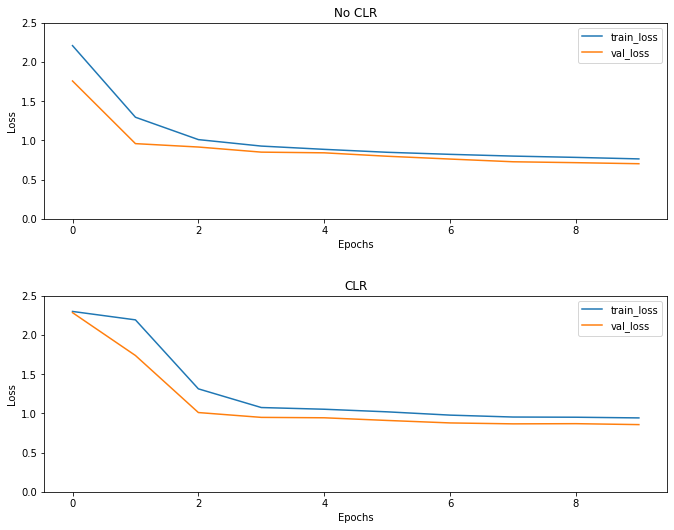
למרות למשל הצעצוע הזה, אתה לא רואה את ההשפעות של CLR הרבה אבל לציין שזה אחד המרכיבים העיקריים מאחורי סופר התכנסות ואת יכול להיות השפעה ממש טובה כאשר מתאמן במסגרות בקנה מידה גדולה.