
Ce didacticiel vous montre comment créer une application Android à l'aide de TensorFlow Lite pour classer du texte en langage naturel. Cette application est conçue pour un appareil Android physique mais peut également fonctionner sur un émulateur d'appareil.
L' exemple d'application utilise TensorFlow Lite pour classer le texte comme positif ou négatif, à l'aide de la bibliothèque de tâches pour le langage naturel (NL) pour permettre l'exécution des modèles d'apprentissage automatique de classification de texte.
Si vous mettez à jour un projet existant, vous pouvez utiliser l'exemple d'application comme référence ou modèle. Pour obtenir des instructions sur la façon d'ajouter une classification de texte à une application existante, reportez-vous à Mise à jour et modification de votre application .
Aperçu de la classification du texte
La classification de texte est la tâche d'apprentissage automatique consistant à attribuer un ensemble de catégories prédéfinies à un texte ouvert. Un modèle de classification de texte est formé sur un corpus de texte en langage naturel, dans lequel des mots ou des expressions sont classés manuellement.
Le modèle entraîné reçoit du texte en entrée et tente de catégoriser le texte en fonction de l'ensemble de classes connues pour lesquelles il a été entraîné. Par exemple, les modèles de cet exemple acceptent un extrait de texte et déterminent si le sentiment du texte est positif ou négatif. Pour chaque extrait de texte, le modèle de classification de texte génère un score qui indique la confiance dans le fait que le texte est correctement classé comme positif ou négatif.
Pour plus d'informations sur la façon dont les modèles de ce didacticiel sont générés, reportez-vous au didacticiel Classification de texte avec TensorFlow Lite Model Maker .
Modèles et ensemble de données
Ce didacticiel utilise des modèles qui ont été formés à l'aide de l'ensemble de données SST-2 (Stanford Sentiment Treebank). SST-2 contient 67 349 critiques de films pour la formation et 872 critiques de films pour les tests, chaque critique étant classée comme positive ou négative. Les modèles utilisés dans cette application ont été formés à l'aide de l'outil TensorFlow Lite Model Maker .
L'exemple d'application utilise les modèles pré-entraînés suivants :
Vecteur de mots moyen (
NLClassifier) - LeNLClassifierde la bibliothèque de tâches classe le texte d'entrée en différentes catégories et peut gérer la plupart des modèles de classification de texte.MobileBERT (
BertNLClassifier) - LeBertNLClassifierde la bibliothèque de tâches est similaire au NLClassifier mais est adapté aux cas qui nécessitent des tokenisations Wordpiece et Sentencepiece hors graphique.
Configurer et exécuter l'exemple d'application
Pour configurer l'application de classification de texte, téléchargez l'exemple d'application depuis GitHub et exécutez-la à l'aide d' Android Studio .
Configuration requise
- Android Studio version 2021.1.1 (Bumblebee) ou supérieure.
- SDK Android version 31 ou supérieure
- Appareil Android avec une version minimale du système d'exploitation du SDK 21 (Android 7.0 - Nougat) avec le mode développeur activé ou un émulateur Android.
Obtenez l'exemple de code
Créez une copie locale de l'exemple de code. Vous utiliserez ce code pour créer un projet dans Android Studio et exécuter l'exemple d'application.
Pour cloner et configurer l'exemple de code :
- Cloner le dépôt git
git clone https://github.com/tensorflow/examples.git
- Vous pouvez éventuellement configurer votre instance git pour utiliser une extraction fragmentée, afin de disposer uniquement des fichiers pour l'exemple d'application de classification de texte :
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
Importer et exécuter le projet
Créez un projet à partir de l'exemple de code téléchargé, générez le projet, puis exécutez-le.
Pour importer et créer l'exemple de projet de code :
- Démarrez Android Studio .
- Depuis Android Studio, sélectionnez Fichier > Nouveau > Importer un projet .
- Accédez au répertoire de code d'exemple contenant le fichier build.gradle (
.../examples/lite/examples/text_classification/android/build.gradle) et sélectionnez ce répertoire. - Si Android Studio demande une synchronisation Gradle, choisissez OK.
- Assurez-vous que votre appareil Android est connecté à votre ordinateur et que le mode développeur est activé. Cliquez sur la flèche verte
Run.
Si vous sélectionnez le bon répertoire, Android Studio crée un nouveau projet et le construit. Ce processus peut prendre quelques minutes, selon la vitesse de votre ordinateur et si vous avez utilisé Android Studio pour d'autres projets. Une fois la construction terminée, Android Studio affiche un message BUILD SUCCESSFUL dans le panneau d'état de sortie de construction .
Pour exécuter le projet :
- Depuis Android Studio, exécutez le projet en sélectionnant Exécuter > Exécuter… .
- Sélectionnez un appareil Android connecté (ou un émulateur) pour tester l'application.
Utilisation de l'application
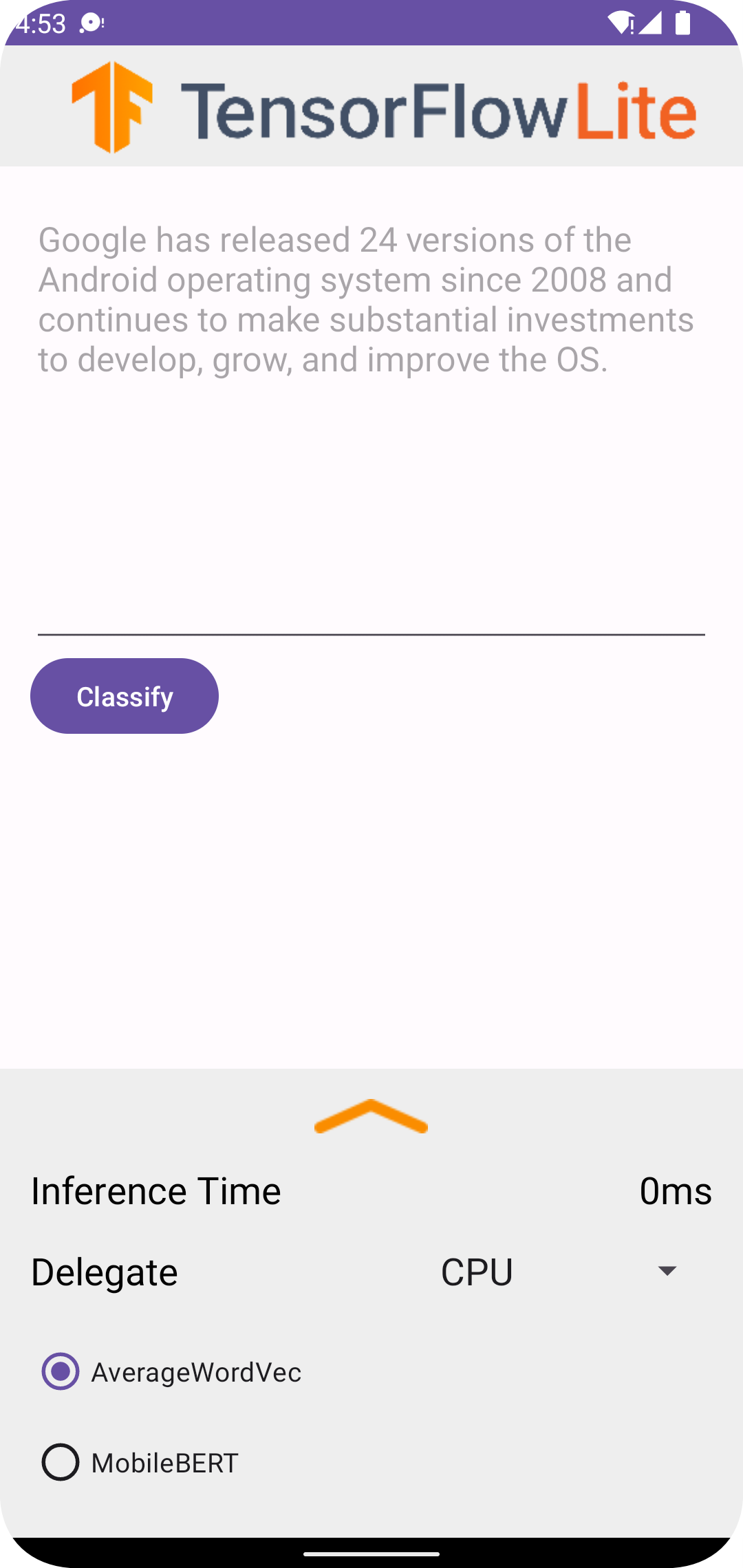
Après avoir exécuté le projet dans Android Studio, l'application s'ouvrira automatiquement sur l'appareil connecté ou l'émulateur d'appareil.
Pour utiliser le classificateur de texte :
- Saisissez un extrait de texte dans la zone de texte.
- Dans la liste déroulante Délégué , choisissez
CPUouNNAPI. - Spécifiez un modèle en choisissant
AverageWordVecouMobileBERT. - Choisissez Classer .
L'application génère un score positif et un score négatif . La somme de ces deux scores sera égale à 1 et mesurera la probabilité que le sentiment du texte saisi soit positif ou négatif. Un nombre plus élevé indique un niveau de confiance plus élevé.
Vous disposez désormais d’une application de classification de texte fonctionnelle. Utilisez les sections suivantes pour mieux comprendre le fonctionnement de l'exemple d'application et comment implémenter des fonctionnalités de classification de texte dans vos applications de production :
Comment fonctionne l'application - Une présentation pas à pas de la structure et des fichiers clés de l'exemple d'application.
Modifier votre application - Instructions pour ajouter une classification de texte à une application existante.
Comment fonctionne l'exemple d'application
L'application utilise le package Task Library for Natural Language (NL) pour implémenter les modèles de classification de texte. Les deux modèles, Average Word Vector et MobileBERT, ont été formés à l'aide de TensorFlow Lite Model Maker . L'application s'exécute sur CPU par défaut, avec l'option d'accélération matérielle à l'aide du délégué NNAPI.
Les fichiers et répertoires suivants contiennent le code crucial pour cette application de classification de texte :
- TextClassificationHelper.kt - Initialise le classificateur de texte et gère la sélection du modèle et du délégué.
- MainActivity.kt - Implémente l'application, notamment en appelant
TextClassificationHelperetResultsAdapter. - ResultsAdapter.kt - Gère et formate les résultats.
Modifier votre candidature
Les sections suivantes expliquent les étapes clés pour modifier votre propre application Android afin d'exécuter le modèle présenté dans l'exemple d'application. Ces instructions utilisent l'exemple d'application comme point de référence. Les modifications spécifiques nécessaires pour votre propre application peuvent différer de l’exemple d’application.
Ouvrir ou créer un projet Android
Vous avez besoin d'un projet de développement Android dans Android Studio pour suivre le reste de ces instructions. Suivez les instructions ci-dessous pour ouvrir un projet existant ou en créer un nouveau.
Pour ouvrir un projet de développement Android existant :
- Dans Android Studio, sélectionnez Fichier > Ouvrir et sélectionnez un projet existant.
Pour créer un projet de développement Android de base :
- Suivez les instructions dans Android Studio pour créer un projet de base .
Pour plus d'informations sur l'utilisation d'Android Studio, reportez-vous à la documentation d'Android Studio .
Ajouter des dépendances de projet
Dans votre propre application, vous devez ajouter des dépendances de projet spécifiques pour exécuter des modèles d'apprentissage automatique TensorFlow Lite et accéder aux fonctions utilitaires qui convertissent des données telles que des chaînes dans un format de données tensoriel pouvant être traité par le modèle que vous utilisez.
Les instructions suivantes expliquent comment ajouter les dépendances de projet et de module requises à votre propre projet d'application Android.
Pour ajouter des dépendances de module :
Dans le module qui utilise TensorFlow Lite, mettez à jour le fichier
build.gradledu module pour inclure les dépendances suivantes.Dans l'exemple d'application, les dépendances se trouvent dans app/build.gradle :
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }Le projet doit inclure la bibliothèque de tâches Texte (
tensorflow-lite-task-text).Si vous souhaitez modifier cette application pour qu'elle s'exécute sur une unité de traitement graphique (GPU), la bibliothèque GPU (
tensorflow-lite-gpu-delegate-plugin) fournit l'infrastructure nécessaire pour exécuter l'application sur GPU, et Déléguer (tensorflow-lite-gpu) fournit la liste de compatibilité. L'exécution de cette application sur GPU sort du cadre de ce didacticiel.Dans Android Studio, synchronisez les dépendances du projet en sélectionnant : Fichier > Synchroniser le projet avec les fichiers Gradle .
Initialiser les modèles ML
Dans votre application Android, vous devez initialiser le modèle de machine learning TensorFlow Lite avec des paramètres avant d'exécuter des prédictions avec le modèle.
Un modèle TensorFlow Lite est stocké sous forme de fichier *.tflite . Le fichier modèle contient la logique de prédiction et inclut généralement des métadonnées sur la manière d'interpréter les résultats de prédiction, telles que les noms des classes de prédiction. Généralement, les fichiers de modèle sont stockés dans le répertoire src/main/assets de votre projet de développement, comme dans l'exemple de code :
-
<project>/src/main/assets/mobilebert.tflite -
<project>/src/main/assets/wordvec.tflite
Pour plus de commodité et de lisibilité du code, l'exemple déclare un objet compagnon qui définit les paramètres du modèle.
Pour initialiser le modèle dans votre application :
Créez un objet compagnon pour définir les paramètres du modèle. Dans l'exemple d'application, cet objet se trouve dans TextClassificationHelper.kt :
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }Créez les paramètres du modèle en créant un objet classificateur et construisez un objet TensorFlow Lite à l'aide de
BertNLClassifierouNLClassifier.Dans l'exemple d'application, cela se trouve dans la fonction
initClassifierdans TextClassificationHelper.kt :fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }
Activer l'accélération matérielle (facultatif)
Lors de l'initialisation d'un modèle TensorFlow Lite dans votre application, vous devez envisager d'utiliser les fonctionnalités d'accélération matérielle pour accélérer les calculs de prédiction du modèle. Les délégués TensorFlow Lite sont des modules logiciels qui accélèrent l'exécution de modèles d'apprentissage automatique à l'aide de matériel de traitement spécialisé sur un appareil mobile, tel qu'une unité de traitement graphique (GPU) ou des unités de traitement tensoriel (TPU).
Pour activer l'accélération matérielle dans votre application :
Créez une variable pour définir le délégué que l'application utilisera. Dans l'exemple d'application, cette variable se trouve au début de TextClassificationHelper.kt :
var currentDelegate: Int = 0Créez un sélecteur de délégués. Dans l'exemple d'application, le sélecteur de délégué se trouve dans la fonction
initClassifierdans TextClassificationHelper.kt :val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
L'utilisation de délégués pour exécuter des modèles TensorFlow Lite est recommandée, mais pas obligatoire. Pour plus d'informations sur l'utilisation de délégués avec TensorFlow Lite, consultez Délégués TensorFlow Lite .
Préparer les données pour le modèle
Dans votre application Android, votre code fournit des données au modèle à des fins d'interprétation en transformant les données existantes telles que le texte brut en un format de données Tensor pouvant être traité par votre modèle. Les données d'un Tensor que vous transmettez à un modèle doivent avoir des dimensions ou une forme spécifiques qui correspondent au format des données utilisées pour entraîner le modèle.
Cette application de classification de texte accepte une chaîne en entrée et les modèles sont formés exclusivement sur un corpus en langue anglaise. Les caractères spéciaux et les mots non anglais sont ignorés lors de l'inférence.
Pour fournir des données textuelles au modèle :
Assurez-vous que la fonction
initClassifiercontient le code du délégué et des modèles, comme expliqué dans les sections Initialiser les modèles ML et Activer l'accélération matérielle .Utilisez le bloc
initpour appeler la fonctioninitClassifier. Dans l'exemple d'application, l'initse trouve dans TextClassificationHelper.kt :init { initClassifier() }
Exécuter des prédictions
Dans votre application Android, une fois que vous avez initialisé un objet BertNLClassifier ou NLClassifier , vous pouvez commencer à alimenter le texte d'entrée pour que le modèle soit classé comme « positif » ou « négatif ».
Pour exécuter des prédictions :
Créez une fonction
classify, qui utilise le classificateur sélectionné (currentModel) et mesure le temps nécessaire pour classer le texte d'entrée (inferenceTime). Dans l'exemple d'application, la fonctionclassifyse trouve dans TextClassificationHelper.kt :fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }Transmettez les résultats de
classifyà l’objet écouteur.fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
Gérer la sortie du modèle
Après avoir saisi une ligne de texte, le modèle produit un score de prédiction, exprimé sous forme de Float, compris entre 0 et 1 pour les catégories « positives » et « négatives ».
Pour obtenir les résultats de prédiction du modèle :
Créez une fonction
onResultpour que l'objet écouteur gère la sortie. Dans l'exemple d'application, l'objet écouteur se trouve dans MainActivity.ktprivate val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }Ajoutez une fonction
onErrorà l'objet écouteur pour gérer les erreurs :private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
Une fois que le modèle a renvoyé un ensemble de résultats de prédiction, votre application peut agir sur ces prédictions en présentant le résultat à votre utilisateur ou en exécutant une logique supplémentaire. L'exemple d'application répertorie les scores de prédiction dans l'interface utilisateur.
Prochaines étapes
- Entraînez et implémentez les modèles à partir de zéro avec le didacticiel Classification de texte avec TensorFlow Lite Model Maker .
- Découvrez d'autres outils de traitement de texte pour TensorFlow .
- Téléchargez d'autres modèles BERT sur TensorFlow Hub .
- Découvrez diverses utilisations de TensorFlow Lite dans les exemples .
- Apprenez-en davantage sur l'utilisation de modèles de machine learning avec TensorFlow Lite dans la section Modèles .
- Apprenez-en davantage sur la mise en œuvre du machine learning dans votre application mobile dans le Guide du développeur TensorFlow Lite .