
| |
מבוא
מודלים של שפה גדולה (LLMs) הם סוג של מודלים של למידת מכונה אשר מאומנים ליצור טקסט על סמך מערכי נתונים גדולים. ניתן להשתמש בהם למשימות עיבוד שפה טבעית (NLP), כולל הפקת טקסט, מענה לשאלות ותרגום מכונה. הם מבוססים על ארכיטקטורת Transformer ומאומנים על כמויות אדירות של נתוני טקסט, שלעתים קרובות מערבים מיליארדי מילים. אפילו LLMs בקנה מידה קטן יותר, כגון GPT-2, יכולים לבצע ביצועים מרשימים. המרת דגמי TensorFlow למודל קל יותר, מהיר יותר ובעל צריכת חשמל נמוכה מאפשרת לנו להפעיל דגמי AI גנרטיביים במכשיר, עם יתרונות של אבטחת משתמש טובה יותר מכיוון שהנתונים לעולם לא יעזבו את המכשיר שלך.
ספר ריצה זה מראה לך כיצד לבנות אפליקציית אנדרואיד עם TensorFlow Lite להפעלת Keras LLM ומספק הצעות לאופטימיזציה של מודלים באמצעות טכניקות כימות, שאחרת תדרוש כמות גדולה בהרבה של זיכרון וכוח חישוב גדול יותר להפעלה.
פתחנו את מסגרת אפליקציית האנדרואיד שלנו בקוד פתוח שכל TFLite LLM תואם יכול להתחבר אליה. הנה שתי הדגמות:
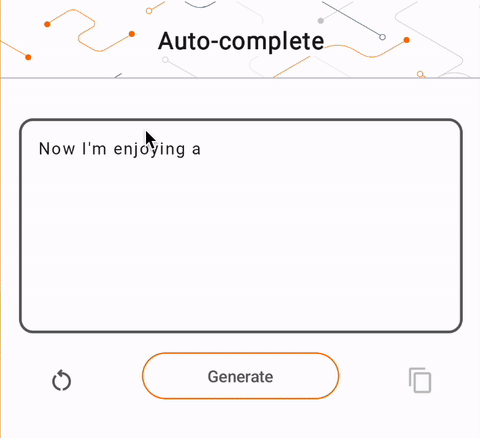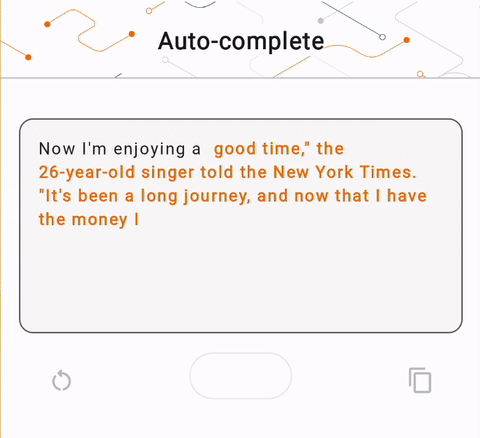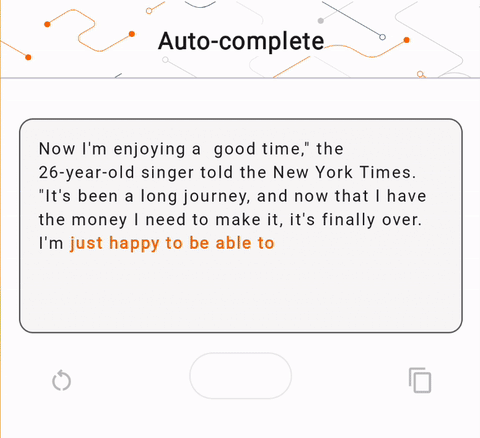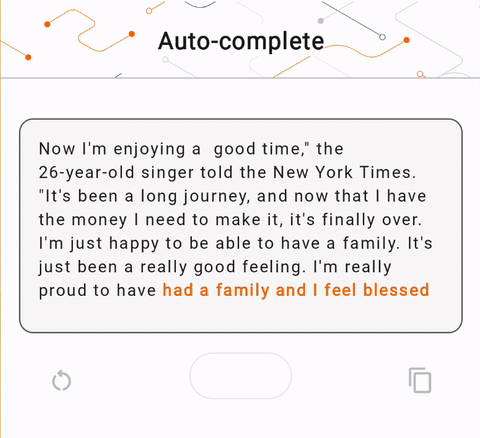
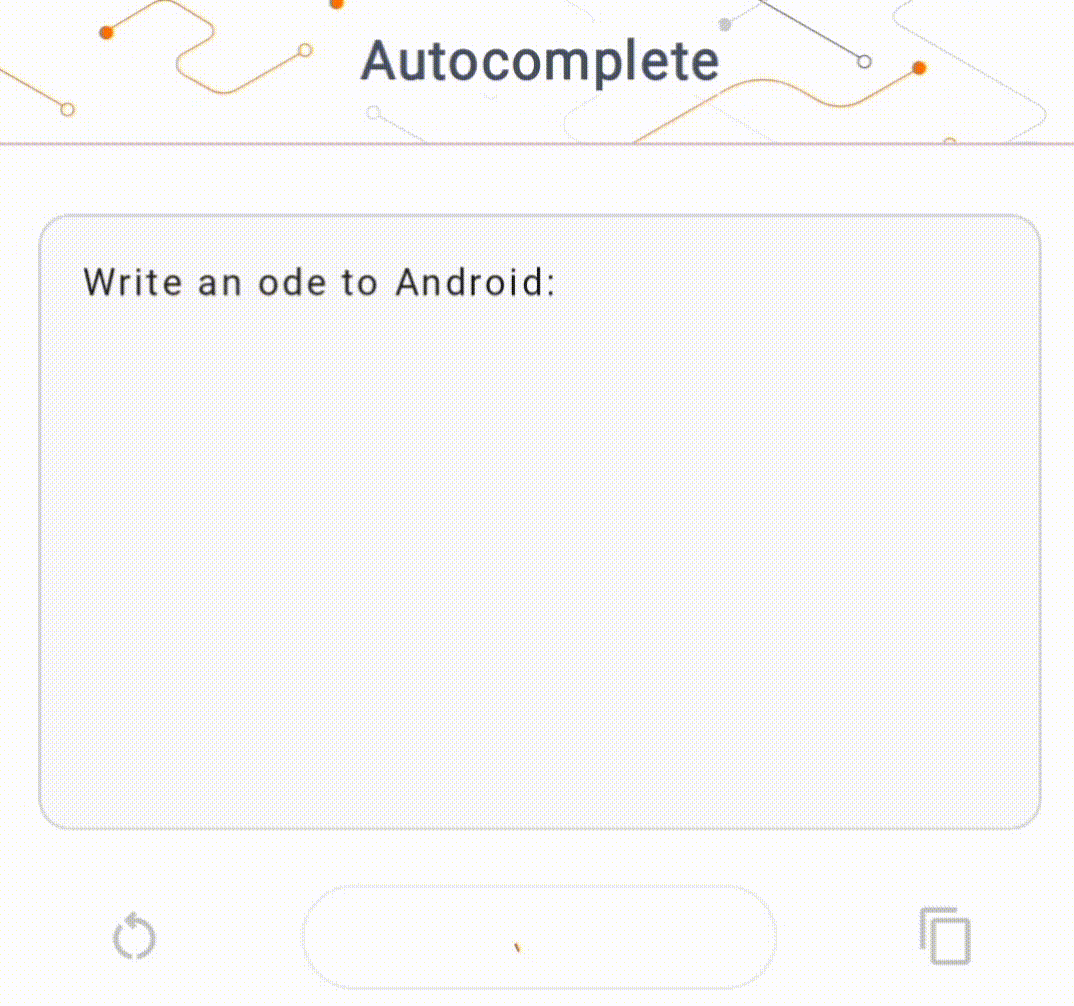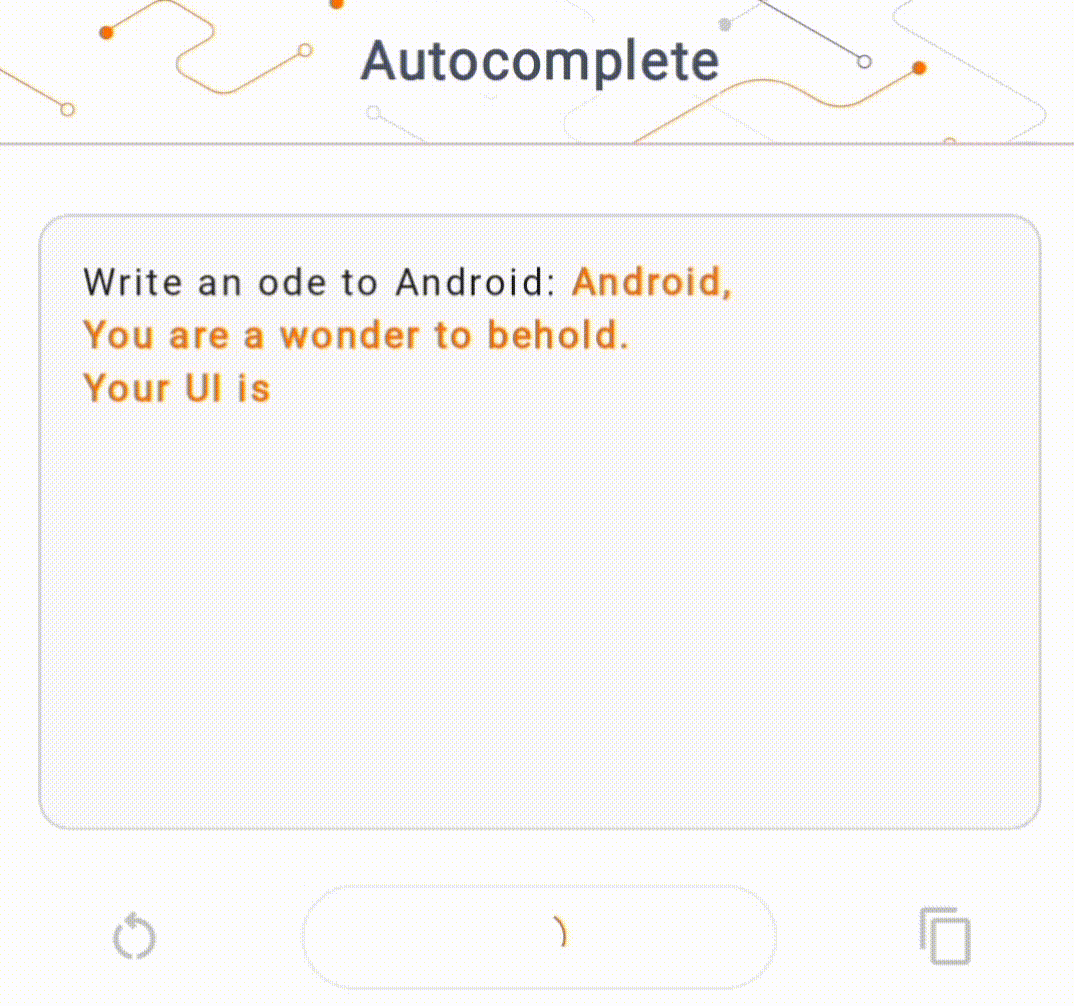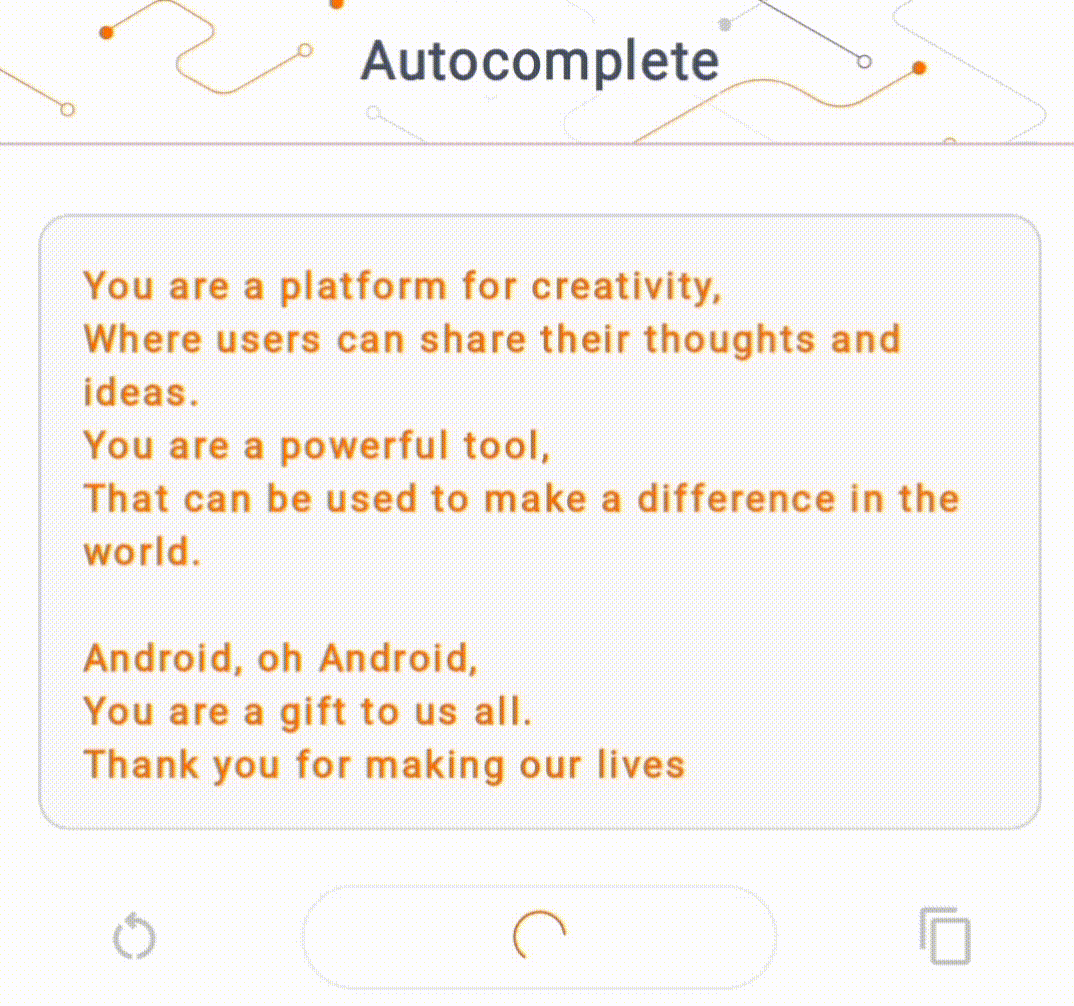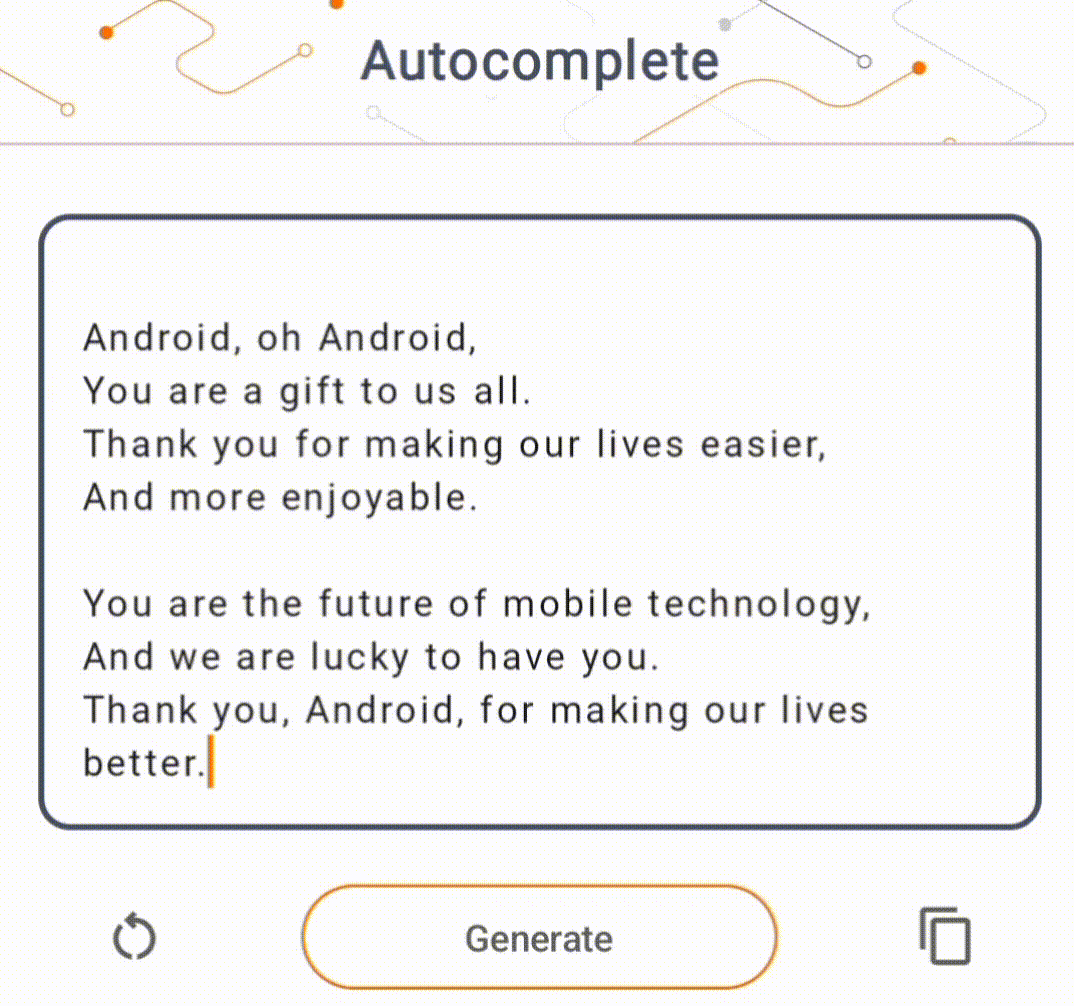
- באיור 1, השתמשנו במודל Keras GPT-2 לביצוע משימות השלמת טקסט במכשיר.
- באיור 2, המרנו גרסה של מודל PaLM מכוון הוראות (1.5 מיליארד פרמטרים) ל-TFLite והוצאנו לפועל באמצעות זמן ריצה של TFLite.
מדריכים
עריכת מודלים
להדגמה זו, נשתמש ב-KerasNLP כדי לקבל את דגם ה-GPT-2. KerasNLP היא ספרייה המכילה מודלים מעודכנים מראש למשימות עיבוד שפה טבעית, ויכולה לתמוך במשתמשים לאורך כל מחזור הפיתוח שלהם. אתה יכול לראות את רשימת הדגמים הזמינים במאגר KerasNLP . זרימות העבודה בנויות מרכיבים מודולריים שיש להם משקלים וארכיטקטורות מוגדרות מראש עדכניות בשימוש מחוץ לקופסה וניתנים להתאמה אישית בקלות כאשר יש צורך בשליטה רבה יותר. יצירת דגם GPT-2 יכולה להיעשות עם השלבים הבאים:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
אחד המשותף בין שלוש שורות הקוד הללו הוא שיטת from_preset() אשר תציג את החלק של Keras API מארכיטקטורה ו/או משקלים מוגדרים מראש, ולכן טוענת את המודל שהוכשר מראש. מקטע קוד זה, תבחין גם בשלושה רכיבים מודולריים:
Tokenizer : ממיר קלט מחרוזת גולמית למזהי אסימון שלמים המתאימים לשכבת הטבעה של Keras. GPT-2 משתמש בטוקניר קידוד צמד בתים (BPE) באופן ספציפי.
מעבד קדם : שכבה ליצירת אסימון ואריזה להזנה לדגם Keras. כאן, המעבד המקדים ירפד את הטנזור של מזהי האסימון לאורך מוגדר (256) לאחר האסימון.
עמוד שדרה : דגם Keras העוקב אחר ארכיטקטורת עמוד השדרה של שנאי SoTA ובעל משקלים מוגדרים מראש.
בנוסף, אתה יכול לבדוק את היישום המלא של מודל GPT-2 ב- GitHub .
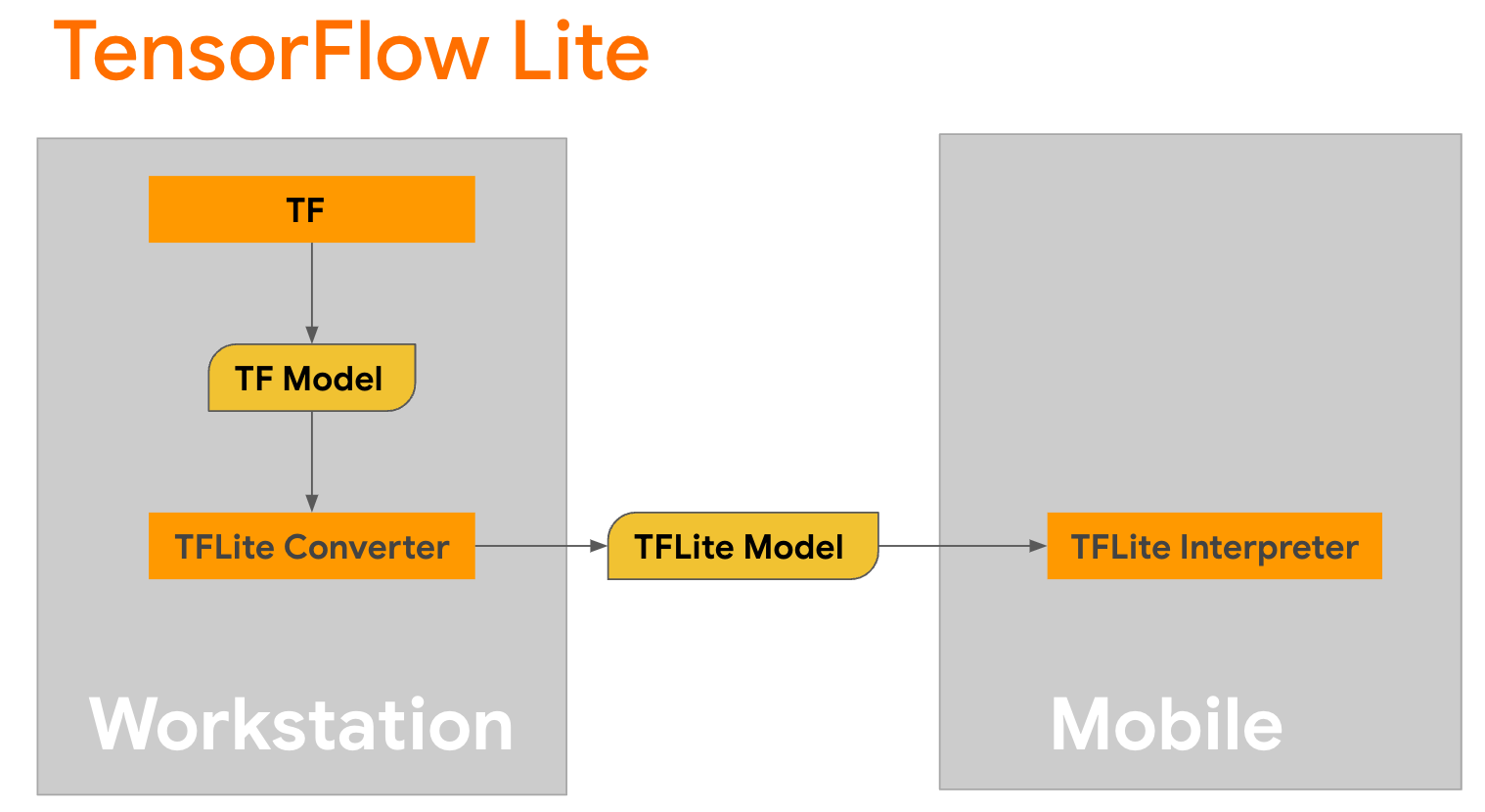
המרת דגם
TensorFlow Lite היא ספרייה ניידת לפריסת שיטות בניידים, מיקרו-בקרים והתקני קצה אחרים. הצעד הראשון הוא להמיר דגם של Keras לפורמט TensorFlow Lite קומפקטי יותר באמצעות ממיר TensorFlow Lite, ולאחר מכן להשתמש במתורגמן TensorFlow Lite, המותאם מאוד למכשירים ניידים, כדי להפעיל את המודל שהומר.
 התחל עם הפונקציה
התחל עם הפונקציה generate() מ- GPT2CausalLM שמבצעת את ההמרה. עטפו את הפונקציה generate() כדי ליצור פונקציית TensorFlow קונקרטית:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
שים לב שאתה יכול גם להשתמש from_keras_model() מ- TFLiteConverter על מנת לבצע את ההמרה.
כעת הגדר פונקציית עוזר שתפעיל הסקה עם קלט ומודל TFLite. אופציות טקסט של TensorFlow אינן פעולות מובנות בזמן הריצה של TFLite, לכן תצטרך להוסיף אופציות מותאמות אישית אלו על מנת שהמתורגמן יוכל להסיק על מודל זה. פונקציית עוזר זו מקבלת קלט ופונקציה שמבצעת את ההמרה, כלומר הפונקציה generator() שהוגדרה למעלה.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
אתה יכול להמיר את הדגם עכשיו:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
כימות
TensorFlow Lite הטמיעה טכניקת אופטימיזציה הנקראת קוונטיזציה שיכולה להפחית את גודל המודל ולהאיץ מסקנות. באמצעות תהליך הקוונטיזציה, צפים של 32 סיביות ממופים למספרים שלמים קטנים יותר של 8 סיביות, ולכן מקטינים את גודל הדגם בפקטור של 4 לביצוע יעיל יותר בחומרה מודרנית. ישנן מספר דרכים לבצע קוונטיזציה ב-TensorFlow. אתה יכול לבקר בדפי מיטוב מודל TFLite ו- TensorFlow Model Optimization Toolkit למידע נוסף. סוגי הקוונטיזציות מוסברים בקצרה להלן.
כאן, תשתמש בכימות הטווח הדינמי שלאחר האימון במודל GPT-2 על ידי הגדרת דגל האופטימיזציה של הממיר ל- tf.lite.Optimize.DEFAULT , ושאר תהליך ההמרה זהה למפורט קודם לכן. בדקנו שעם טכניקת הקוונטיזציה הזו השהיה הוא בסביבות 6.7 שניות ב-Pixel 7 עם אורך פלט מקסימלי מוגדר ל-100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
טווח דינמי
קוונטיזציה של טווח דינמי היא נקודת ההתחלה המומלצת לאופטימיזציה של מודלים במכשיר. זה יכול להשיג בערך פי 4 הפחתה בגודל הדגם, ומהווה נקודת התחלה מומלצת מכיוון שהוא מספק שימוש מופחת בזיכרון וחישוב מהיר יותר מבלי שתצטרך לספק מערך נתונים מייצג לכיול. סוג זה של קוונטיזציה מכמת באופן סטטי רק את המשקולות מנקודה צפה למספר שלם של 8 סיביות בזמן ההמרה.
FP16
ניתן לבצע אופטימיזציה של מודלים של נקודה צפה על ידי כימות המשקולות לסוג float16. היתרונות של קוונטיזציה float16 הם הקטנת גודל המודל עד לחצי (ככל שכל המשקולות הופכות למחצית מהגודל שלהם), גורם לאובדן דיוק מינימלי ותמיכה בנציגי GPU שיכולים לפעול ישירות על נתוני float16 (מה שמביא לחישוב מהיר יותר מאשר ב-float32 נתונים). דגם שהומר למשקולות float16 עדיין יכול לפעול על המעבד ללא שינויים נוספים. המשקולות של float16 נדגמו ל-float32 לפני ההסקה הראשונה, מה שמאפשר הקטנה בגודל הדגם בתמורה להשפעה מינימלית על חביון ודיוק.
קוונטיזציה מלאה של מספרים שלמים
קוונטיזציה מלאה של מספרים ממירים את מספרי הנקודה הצפה של 32 סיביות, כולל משקלים והפעלות, למספרים השלמים הקרובים ביותר של 8 סיביות. סוג זה של קוונטיזציה מביא למודל קטן יותר עם מהירות הסקה מוגברת, שהיא בעלת ערך רב בעת שימוש במיקרו-בקרים. מצב זה מומלץ כאשר הפעלות רגישות לכימות.
שילוב אפליקציית אנדרואיד
אתה יכול לעקוב אחר דוגמה זו של אנדרואיד כדי לשלב את דגם ה-TFLite שלך באפליקציית אנדרואיד.
דרישות מוקדמות
אם עדיין לא עשית זאת, התקן את Android Studio , בצע את ההוראות באתר.
- Android Studio 2022.2.1 ומעלה.
- מכשיר אנדרואיד או אמולטור אנדרואיד עם יותר מזיכרון 4G
בנייה והפעלה עם Android Studio
- פתח את Android Studio, וממסך הפתיחה, בחר פתח פרויקט Android Studio קיים .
- מחלון פתח קובץ או פרויקט שמופיע, נווט ובחר בספריית
lite/examples/generative_ai/androidמכל מקום שבו שיבטת את מאגר GitHub לדוגמה של TensorFlow Lite. - ייתכן שיהיה עליך להתקין פלטפורמות וכלים שונים בהתאם להודעות השגיאה.
- שנה את שם דגם ה-.tflite שהומר ל-
autocomplete.tfliteוהעתק אותו לתיקיהapp/src/main/assets/. - בחר בתפריט Build -> Make Project כדי לבנות את האפליקציה. (Ctrl+F9, תלוי בגרסה שלך).
- לחץ על התפריט הפעלה -> הפעל 'אפליקציה' . (Shift+F10, תלוי בגרסה שלך)
לחלופין, אתה יכול גם להשתמש במעטפת Gradle כדי לבנות אותו בשורת הפקודה. אנא עיין בתיעוד Gradle למידע נוסף.
(אופציונלי) בניית קובץ .aar
כברירת מחדל, האפליקציה מורידה אוטומטית את קבצי .aar הדרושים. אבל אם אתה רוצה לבנות משלך, עבור ל- app/libs/build_aar/ הפעלת תיקיות ./build_aar.sh . סקריפט זה ימשוך את האופציות הנחוצות מ-TensorFlow Text ויבנה את ה-aar עבור מפעילי Select TF.
לאחר ההידור, נוצר קובץ חדש tftext_tflite_flex.aar . החלף את קובץ ה-aar בתיקייה app/libs/ ובנה מחדש את האפליקציה.
שים לב שאתה עדיין צריך לכלול את התקן tensorflow-lite aar בקובץ ה-gradle שלך.
גודל חלון ההקשר
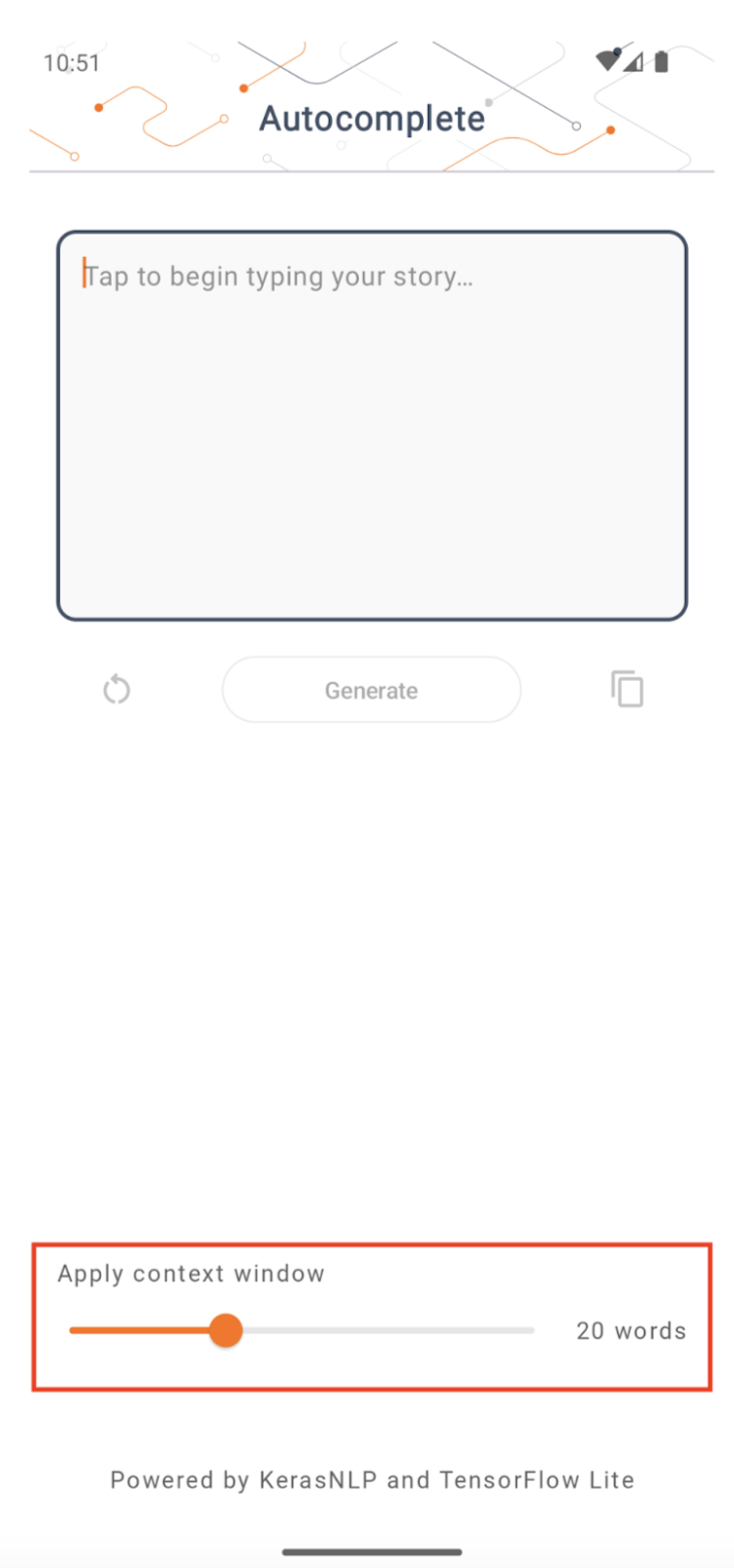
לאפליקציה יש פרמטר ניתן לשינוי 'גודל חלון ההקשר', אשר נחוץ כי ל-LLM כיום יש בדרך כלל גודל הקשר קבוע שמגביל כמה מילים/אסימונים ניתן להזין למודל בתור 'הנחיה' (שים לב ש'מילה' אינה בהכרח שווה ערך ל'אסימון' במקרה זה, עקב שיטות אסימון שונות). מספר זה חשוב כי:
- אם מגדירים אותו קטן מדי, למודל לא יהיה מספיק הקשר כדי ליצור פלט משמעותי
- אם מגדירים אותו גדול מדי, לדגם לא יהיה מספיק מקום לעבוד איתו (מכיוון שרצף הפלט כולל את ההנחיה)
אתה יכול להתנסות עם זה, אבל הגדרה של ~50% מאורך רצף הפלט היא התחלה טובה.
בטיחות ואחריות בינה מלאכותית
כפי שצוין בהכרזה המקורית של OpenAI GPT-2 , ישנם אזהרות ומגבלות בולטות עם דגם GPT-2. למעשה, ל-LLM כיום יש בדרך כלל כמה אתגרים ידועים כמו הזיות, הוגנות והטיה; הסיבה לכך היא שהמודלים הללו מאומנים על נתונים מהעולם האמיתי, מה שגורם להם לשקף בעיות בעולם האמיתי.
מעבד קוד זה נוצר רק כדי להדגים כיצד ליצור אפליקציה המופעלת על ידי LLMs עם כלי TensorFlow. הדגם המיוצר בקוד מעבד זה מיועד למטרות חינוכיות בלבד ואינו מיועד לשימוש בייצור.
שימוש בייצור LLM מצריך בחירה מתחשבת של מערכי הדרכה ואמצעי בטיחות מקיפים. פונקציונליות אחת כזו המוצעת באפליקציית אנדרואיד זו היא מסנן ניבולי פה, שדוחה קלט של משתמשים רעים או פלטי דגם. אם תתגלה שפה לא הולמת, האפליקציה תדחה בתמורה את הפעולה הזו. למידע נוסף על AI אחראי בהקשר של LLMs, הקפד לצפות במפגש הטכני של פיתוח בטוח ואחראי עם מודלים של שפה גנרטיבית ב-Google I/O 2023 ולבדוק את ערכת הכלים של AI אחראי .